Big data википедия: Что такое Big data: собрали всё самое важное о больших данных
Статья Wikipedia «Big Data» #управление контентом #СЭД #ECMJ
Тема больших данных является популярной уже достаточно
долгое время, оставляя гораздо больше вопросов, чем ответов. Не обошла стороной
она и нас. Сравнив статьи, посвященные большим данным в Википедии на русском и
английском языках, мы решили дополнить русскоязычную версию некоторой
информацией из ее англоязычной «сестры», предварительно представив переведенный
материал на суд сообщества ECM-Journal.
В данной статье мы публикуем перевод материала, посвященного вопросам
технологии и архитектуры. Далее последует материал по критике концепции больших
данных и практике использования.
Определение
Большие данные (англ. Big Data) – это
общий термин для обозначения процесса сбора данных таких объемов и
многообразия, при которых их обработка с применением традиционных инструментов становится
проблематичной. Трудности возникают при осуществлении захвата, сбора, хранения,
поиска, совместного использования, передачи, анализа и визуализации данных. Тенденция
Тенденция
бОльших объемов данных возникла благодаря возможности получения дополнительной
информации в результате анализа отдельного большого набора связанных данных (в
противовес анализу небольших наборов данных с таким же совокупным объемом).[1]
Ученые регулярно сталкиваются с ограничениями, связанными
с большими наборами данных во многих областях, включая метеорологию, геномику,[2] коннектомику, сложное
моделирование физической среды,[3] исследования в
области биологии и окружающей среды.[4] Эти ограничения
также касаются функции поиска в интернете, финансовой и бизнес-информатики.
Наборы данных увеличиваются в объемах частично ввиду их постоянного сбора посредством
мобильных приложений, воздушных (антенных) высокочувствительных технологий
(дистанционное считывание), лог-файлов, камер, микрофонов, радиочастотных
идентификаторов (RFID), и
беспроводных сенсорных сетей.[5][6][7] Начиная с 80-х
годов XX века мировой объем хранения информации на душу населения удваивается
каждые 40 месяцев;[8] по состоянию на
2012 год каждый день создавалось по 2. 5 экзабайт (2.5×1018 байт) данных.[9]
5 экзабайт (2.5×1018 байт) данных.[9]
Крупным предприятиям предстоит решить, кто возьмет в свои
руки инициативы по управлению большими данными, которыми уже переполнены целые
организации.[10]
Сложно работать с большими данными, применяя главным
образом системы по управлению реляционными базами данных, desktop-статистику
и пакеты программ для визуализации, когда вместо этого необходимо использовать
«массово-параллельное программное обеспечение, функционирующее на десятках,
сотнях, или даже тысячах серверов».[11]
То, что принято считать «большими данными» различается в
зависимости от возможностей компании, управляющей набором данных, а также от
возможностей приложений, применяемых для обработки и анализа. «Для большинства
организаций первое столкновение с сотнями гигабайт данных может вызвать
необходимость пересмотра средств управления данными. Но для других компаний
«критическим» может стать объем в десятки или сотни терабайт». [12]
[12]
Архитектура
В 2004 году компания Google опубликовала документацию по модели
распределенных вычислений MapReduce. В MapReduce представлена параллельная
модель обработки данных. На Map-шаге происходит предварительная обработка
входных данных. Для этого один из компьютеров (называемый главным узлом –
master node) получает входные данные задачи, разделяет их на части и передает
другим компьютерам (рабочим узлам – worker node) для предварительной обработки.
На Reduce-шаге происходит свертка предварительно обработанных данных. Главный
узел получает ответы от рабочих узлов и на их основе формирует результат –
решение задачи, которая формулировалась изначально. Данная модель была
настолько успешна[13],
что многие хотели продублировать ее алгоритм. Поэтому, проект компании Apache с
открытым исходным кодом, получивший название Hadoop[14],
взял ее на вооружение.
Методология управления корпоративной информацией MIKE2. 0 – открытый подход
0 – открытый подход
к управлению информацией, который в статье «Big Data Solution Offering»[15]
признает необходимость модернизации решений для управления большими данными в
связи с возросшей частотой их применения. Методология рассматривает управление
большими данными через призму полезных преобразований их источников, сложности взаимосвязей,
и трудностей, связанных с удалением (или изменением) отдельных записей.[16]
Последние исследования показывают, что использование
многослойной архитектуры является одним из вариантов работы с большими данными.
Распределенная параллельная архитектура осуществляет передачу данных на множество
блоков обработки, а параллельные блоки обработки предоставляют данные гораздо
быстрее путем увеличения скоростей обработки. Этот тип архитектуры вводит
данные в параллельную систему управления базой данных (СУБД), в которой
применяются модели MapReduce и Hadoop. Данный тип моделей направлен на то,
чтобы при помощи frontend-сервера приложений сделать
вычислительные возможности прозрачными для конечного пользователя. [17]
[17]
Технологии
Для оперативной обработки огромных объемов данных необходимы
исключительные технологии. В отчете McKinsey 2011 года[18]
предполагается, что подходящие для этого технологии включают A/B тестирование, краудсорсинг, синтез и интеграцию данных, генетические алгоритмы,
машинное обучение, обработку
естественного языка, обработку сигнала, симулирование, анализ на основе
временных рядов и визуализацию.
Многомерные большие данные могут также быть представлены тензорами, которые наиболее
эффективно обрабатываются с помощью тензорного вычисления[19]. Дополнительные
технологии, применяемые по отношению к большим данным, включают
массово-параллельную обработку (MPP) баз
данных, поисковых
приложений, системы распределенных вычислений для data-mining, распределенные системы файлов, распределенные базы данных,
облачная инфраструктура (приложения, хранилищные и вычислительные ресурсы), а
также интернет.
Некоторые, но не все реляционные
базы данных с MPP имеют
возможность хранения и управления петабайтами данных. Подразумевается
возможность загружать, отслеживать, поддерживать и оптимизировать использование
больших таблиц данных в системе управления реляционной базой данных (RDBMS).[20]
Программа Анализа
Топологических Данных Управления Перспективных Исследований и Разработок (DARPA) Министерства Обороны США занимается
поиском основной структуры больших наборов данных, и, в 2008 году данная технология
вышла на открытый рынок с основанием компании под названием Ayasdi.[21]
Специалисты, занимающиеся аналитикой больших данных,
обычно с недоверием относятся к более медленной системе совместного хранения,[22] предпочитая ей систему хранения с прямым
подключением (direct-attached storage (DAS)) в ее различных
формах от твердотельной памяти (solid state drive (SSD)) до высокомощного диска SATA, размещенного внутри
параллельных узлов обработки. Общее впечатление от архитектур совместного
Общее впечатление от архитектур совместного
хранения: Сети
хранения данных (SAN) и Сетевого хранилища данных (NAS) –
заключается в их относительной медлительности, сложности и высокой стоимости.
Данные свойства не согласуются с системами аналитики больших данных, которые
выигрывают за счет показателей системы, инфраструктуры и низкой стоимости.
Получение информации в режиме реального времени является
одной из определяющих характеристик аналитики больших данных. Задержка, таким
образом, исключается везде, где это возможно и тогда, когда это возможно.
Данные в памяти – это хорошо, данные на вращающемся диске на другом конце оптоволоконного соединения
сети хранения данных (SAN) – нет. Стоимость SAN в масштабе, необходимом для
аналитических приложений, гораздо выше, чем стоимость других способов хранения.
В области аналитики больших данных совместное хранение
имеет как свои достоинства, так и недостатки, но аналитики больших данных по
состоянию на 2011 год не отдавали ему своего предпочтения.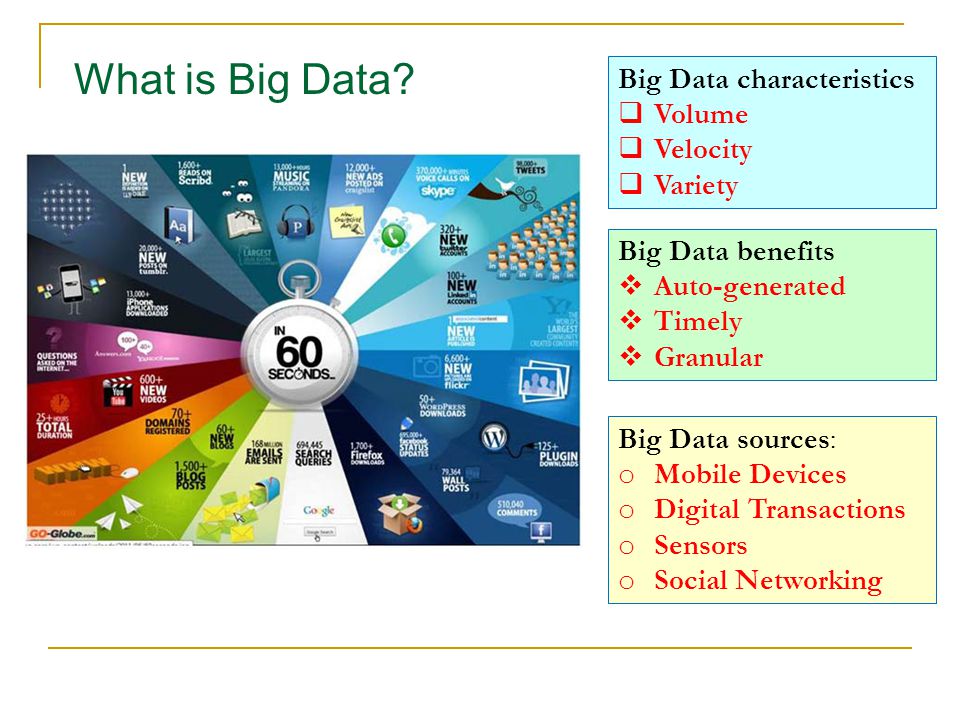 [23]
[23]
Источник: Wikipedia
Принципы работы с большими данными, парадигма MapReduce / Хабр
Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
История вопроса и определение термина
Термин Big Data появился сравнительно недавно. Google Trends показывает начало активного роста употребления словосочетания начиная с 2011 года (ссылка):
При этом уже сейчас термин не использует только ленивый. Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
Особенно часто не по делу термин используют маркетологи. Так что же такое Big Data на самом деле? Раз уж я решил системно изложить и осветить вопрос – необходимо определиться с понятием.
В своей практике я встречался с разными определениями:
· Big Data – это когда данных больше, чем 100Гб (500Гб, 1ТБ, кому что нравится)
· Big Data – это такие данные, которые невозможно обрабатывать в Excel
· Big Data – это такие данные, которые невозможно обработать на одном компьютере
И даже такие:
· Вig Data – это вообще любые данные.
· Big Data не существует, ее придумали маркетологи.
В этом цикле статей я буду придерживаться определения с wikipedia:
Большие данные (англ. big data) — серия подходов, инструментов и методов обработки структурированных и неструктурированных данных огромных объёмов и значительного многообразия для получения воспринимаемых человеком результатов, эффективных в условиях непрерывного прироста, распределения по многочисленным узлам вычислительной сети, сформировавшихся в конце 2000-х годов, альтернативных традиционным системам управления базами данных и решениям класса Business Intelligence.
Таким образом под Big Data я буду понимать не какой-то конкретный объём данных и даже не сами данные, а методы их обработки, которые позволяют распредёлено обрабатывать информацию. Эти методы можно применить как к огромным массивам данных (таким как содержание всех страниц в интернете), так и к маленьким (таким как содержимое этой статьи).
Приведу несколько примеров того, что может быть источником данных, для которых необходимы методы работы с большими данными:
· Логи поведения пользователей в интернете
· GPS-сигналы от автомобилей для транспортной компании
· Данные, снимаемые с датчиков в большом адронном коллайдере
· Оцифрованные книги в Российской Государственной Библиотеке
· Информация о транзакциях всех клиентов банка
· Информация о всех покупках в крупной ритейл сети и т.д.
Количество источников данных стремительно растёт, а значит технологии их обработки становятся всё более востребованными.
Принципы работы с большими данными
Исходя из определения Big Data, можно сформулировать основные принципы работы с такими данными:
1. Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
Горизонтальная масштабируемость. Поскольку данных может быть сколь угодно много – любая система, которая подразумевает обработку больших данных, должна быть расширяемой. В 2 раза вырос объём данных – в 2 раза увеличили количество железа в кластере и всё продолжило работать.
2. Отказоустойчивость. Принцип горизонтальной масштабируемости подразумевает, что машин в кластере может быть много. Например, Hadoop-кластер Yahoo имеет более 42000 машин (по этой ссылке можно посмотреть размеры кластера в разных организациях). Это означает, что часть этих машин будет гарантированно выходить из строя. Методы работы с большими данными должны учитывать возможность таких сбоев и переживать их без каких-либо значимых последствий.
3. Локальность данных. В больших распределённых системах данные распределены по большому количеству машин. Если данные физически находятся на одном сервере, а обрабатываются на другом – расходы на передачу данных могут превысить расходы на саму обработку. Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Поэтому одним из важнейших принципов проектирования BigData-решений является принцип локальности данных – по возможности обрабатываем данные на той же машине, на которой их храним.
Все современные средства работы с большими данными так или иначе следуют этим трём принципам. Для того, чтобы им следовать – необходимо придумывать какие-то методы, способы и парадигмы разработки средств разработки данных. Один из самых классических методов я разберу в сегодняшней статье.
MapReduce
Про MapReduce на хабре уже писали (раз, два, три), но раз уж цикл статей претендует на системное изложение вопросов Big Data – без MapReduce в первой статье не обойтись J
MapReduce – это модель распределенной обработки данных, предложенная компанией Google для обработки больших объёмов данных на компьютерных кластерах. MapReduce неплохо иллюстрируется следующей картинкой (взято по ссылке):
MapReduce предполагает, что данные организованы в виде некоторых записей. Обработка данных происходит в 3 стадии:
1. Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Стадия Map. На этой стадии данные предобрабатываются при помощи функции map(), которую определяет пользователь. Работа этой стадии заключается в предобработке и фильтрации данных. Работа очень похожа на операцию map в функциональных языках программирования – пользовательская функция применяется к каждой входной записи.
Функция map() примененная к одной входной записи и выдаёт множество пар ключ-значение. Множество – т.е. может выдать только одну запись, может не выдать ничего, а может выдать несколько пар ключ-значение. Что будет находится в ключе и в значении – решать пользователю, но ключ – очень важная вещь, так как данные с одним ключом в будущем попадут в один экземпляр функции reduce.
2. Стадия Shuffle. Проходит незаметно для пользователя. В этой стадии вывод функции map «разбирается по корзинам» – каждая корзина соответствует одному ключу вывода стадии map. В дальнейшем эти корзины послужат входом для reduce.
3. Стадия Reduce. Каждая «корзина» со значениями, сформированная на стадии shuffle, попадает на вход функции reduce().
Функция reduce задаётся пользователем и вычисляет финальный результат для отдельной «корзины». Множество всех значений, возвращённых функцией reduce(), является финальным результатом MapReduce-задачи.
Несколько дополнительных фактов про MapReduce:
1) Все запуски функции map работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
2) Все запуски функции reduce работают независимо и могут работать параллельно, в том числе на разных машинах кластера.
3) Shuffle внутри себя представляет параллельную сортировку, поэтому также может работать на разных машинах кластера. Пункты 1-3 позволяют выполнить принцип горизонтальной масштабируемости.
4) Функция map, как правило, применяется на той же машине, на которой хранятся данные – это позволяет снизить передачу данных по сети (принцип локальности данных).
5) MapReduce – это всегда полное сканирование данных, никаких индексов нет. Это означает, что MapReduce плохо применим, когда ответ требуется очень быстро.
Примеры задач, эффективно решаемых при помощи MapReduce
Word Count
Начнём с классической задачи – Word Count. Задача формулируется следующим образом: имеется большой корпус документов. Задача – для каждого слова, хотя бы один раз встречающегося в корпусе, посчитать суммарное количество раз, которое оно встретилось в корпусе.
Решение:
Раз имеем большой корпус документов – пусть один документ будет одной входной записью для MapRreduce–задачи. В MapReduce мы можем только задавать пользовательские функции, что мы и сделаем (будем использовать python-like псевдокод):
Функция map превращает входной документ в набор пар (слово, 1), shuffle прозрачно для нас превращает это в пары (слово, [1,1,1,1,1,1]), reduce суммирует эти единички, возвращая финальный ответ для слова.
Обработка логов рекламной системы
Второй пример взят из реальной практики Data-Centric Alliance.
Задача: имеется csv-лог рекламной системы вида:
<user_id>,<country>,<city>,<campaign_id>,<creative_id>,<payment></p>
11111,RU,Moscow,2,4,0. 3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
 3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
3
22222,RU,Voronezh,2,3,0.2
13413,UA,Kiev,4,11,0.7
…
Необходимо рассчитать среднюю стоимость показа рекламы по городам России.
Решение:
Функция map проверяет, нужна ли нам данная запись – и если нужна, оставляет только нужную информацию (город и размер платежа). Функция reduce вычисляет финальный ответ по городу, имея список всех платежей в этом городе.
Резюме
В статье мы рассмотрели несколько вводных моментов про большие данные:
· Что такое Big Data и откуда берётся;
· Каким основным принципам следуют все средства и парадигмы работы с большими данными;
· Рассмотрели парадигму MapReduce и разобрали несколько задач, в которой она может быть применена.
Первая статья была больше теоретической, во второй статье мы перейдем к практике, рассмотрим Hadoop – одну из самых известных технологий для работы с большими данными и покажем, как запускать MapReduce-задачи на Hadoop.
В последующих статьях цикла мы рассмотрим более сложные задачи, решаемые при помощи MapReduce, расскажем об ограничениях MapReduce и о том, какими инструментами и техниками можно обходить эти ограничения.
Спасибо за внимание, готовы ответить на ваши вопросы.
Youtube-Канал автора об анализе данных
Ссылки на другие части цикла:
Часть 2: Hadoop
Часть 3: Приемы и стратегии разработки MapReduce-приложений
Часть 4: Hbase
Бота научили обновлять устаревшую информацию в Википедии
Источник: Christine Daniloff/MIT
В МТИ разработали систему, способную автоматически обнаруживать в Википедии устаревшие фактические сведения — цифры, даты, имена, географические названия и т. п. и заменять их на свежие. Сейчас такие правки вносятся вручную волонтерами.
Систему обучили на размеченном наборе данных, содержащем пары сообщений трех типов, — согласующиеся, несогласующиеся и нейтральные (содержащие недостаточно сведений, чтобы отнести пару к одному из первых двух типов). С помощью такого бота редактору достаточно однократно внести в специальный интерфейс обновленные сведения о событии, а система сама найдет все его упоминания в Википедии и изменит нужным образом соответствующие предложения с соблюдением правил грамматики.
С помощью такого бота редактору достаточно однократно внести в специальный интерфейс обновленные сведения о событии, а система сама найдет все его упоминания в Википедии и изменит нужным образом соответствующие предложения с соблюдением правил грамматики.
По словам разработчиков, систему можно использовать и для других задач, связанных с автоматическим созданием текста, а кроме того, она позволяет уменьшать предвзятость средств проверки фактов и выявления фейковых новостей. Некоторые из таких инструментов обучают на наборах данных с аналогичными парами высказываний, но кроме того, они реагируют на определенные словосочетания-маркеры, выдающие ложное высказывание. Если таким маркерам назначен приоритет, проверка факта по авторитетному источнику не выполняется. Исследователи добавили словосочетания-маркеры в согласующиеся пары высказываний учебного набора и обучили на нем популярный классификатор фейковых новостей, в результате чего частота его ошибок уменьшилась на 13%.
Поделитесь материалом с коллегами и друзьями
Викиданные:Скачивание базы данных — Wikidata
Викиданные позволяют скопировать имеющиеся данные всем желающим.
Существует несколько методов доступа к получению данных от Викиданных, которые не требуют скачивания всей базы данных.
Дампы
Существует несколько различных типов дампов данных. Обратите внимание, что дампы JSON и RDF считаются «стабильными интерфейсами», в то время как XML-дампы такими не являются. Изменения в форматах данных, используемых стабильными интерфейсами, подчиняются Stable Interface Policy.
Дампы в формате JSON (рекомендованный формат)
Дампы в формате JSON, включающие все сущности Викиданных, перечисленные на странице https://dumps.wikimedia.org/wikidatawiki/entities/.
Объекты в массиве необязательно находятся в каком-либо определённом порядке, например, Q2 необязательно следует за Q1.
Дампы создаются еженедельно.
Рекомендуется использовать именно этот формат. См. документацию о структуре JSON с информацией о представлении сведений из Викиданных.
Каждая сущность (элемент или свойство) занимает в JSON отдельную строку, поэтому файл можно читать построчно, каждую строку можно декодировать как отдельный объект.
Обратите внимание, что файлы используют параллельное сжатие, из-за чего некоторые декомпрессоры не могут надёжно распаковать файлы. Если вы используете Windows, вы можете использовать, например, Bzip2.
JsonDumpReader — PHP-библиотека для чтения дампов.
Дампы в формате RDF
Классические RDF-дампы в формате Turtle находятся по ссылке https://dumps.wikimedia.org/wikidatawiki/entities/. Отображение описано здесь.
Во-вторых, предоставляются так называемые truthy дампы. Они используют формат nt. Они находятся в том же формате, что и полные дампы, но ограничены прямыми, правдивыми утверждениями. Поэтому они не содержат метаданных, таких как квалификатор и ссылки.
Полные дампы содержат всю информацию о сущностях Викиданных, кроме порядка (утверждений, синонимов), так как в RDF такая информация не указывается. Упрощённые дампы кодируют утверждения без квалификаторов в отдельные RDF-триплеты, опуская источники.
Дампы пространства имён Викиданных Lexeme в форматах Turtle и NTriples представлены там же с окончанием lexemes.
For details on the RDF dump format please see the page RDF Dump Format.
Частичные дампы в формате RDF
WDumper — сторонний инструмент для создания настраиваемых дампов Викиданных в формате RDF. Возможна фильтрация сущностей и утверждений.
Дампы в формате XML
Дампы базы в формате XML можно найти здесь.
Предупреждение: Формат данных JSON, включаемых в дампы XML, может меняться без объявления и быть несовместимым между версиями. Его следует рассматривать как непрозрачные бинарные данные. Настоятельно рекомендуется использовать вместо этого дампы JSON или RDF, использующие канонические представления данных!
Можно скачать и инкрементные дампы (небольшие дампы с изменениями за последние 24 часа), они позволяют не скачивать каждый раз полный дамп базы данных. Эти дампы значительно меньше, чем полные дампы базы данных
Они доступны здесь.
Старые дампы JSON и RDF
Старые дампы в форматах RDF и JSON можно найти в Internet Archive (Q461):
Модель данных
Модель данных описана по ссылке. Она описывает фундаментальные блоки данных проекта.
Она описывает фундаментальные блоки данных проекта.
Схема базы данных
Обзор схемы БД находится здесь. (Это не схема данных Викиданных.)
Лицензия
Копии базы данных можно использовать в личных или коммерческих целях, для создания резервной копии или для использования на локальном компьютере без подключения к интернету. Все структурированные данные из основного пространства имён и пространств имён Property, Lexeme и EntitySchema доступны под лицензией Creative Commons CC0. Текст в остальных пространствах имён доступен под лицензией Creative Commons Attribution/Share-Alike; также могут накладываться дополнительные условия. Объекты мультимедиа и другое содержимое доступны под иными лицензиями, указанными на их страницах описания.
See also
Гибкая методология разработки — wiki студи Клондайк
Гибкая методология разработки (англ. Agile software development, agile-методы) — серия подходов к разработке программного обеспечения, ориентированных на использование интерактивной разработки, динамическое формирование требований и обеспечение их реализации в результате постоянного взаимодействия внутри самоорганизующихся рабочих групп, состоящих из специалистов различного профиля. Существует несколько методик, относящихся к классу гибких методологий разработки, в частности экстремальное программирование, DSDM, Scrum, FDD.
Существует несколько методик, относящихся к классу гибких методологий разработки, в частности экстремальное программирование, DSDM, Scrum, FDD.
Экстремальное программирование
Одна из гибких методологий разработки программного обеспечения. Авторы методологии — Кент Бек, Уорд Каннингем, Мартин Фаулер и другие.
Основные приёмы XP
- Короткий цикл обратной связи (Fine-scale feedback)
- Разработка через тестирование (Test-driven development)
- Игра в планирование (Planning game)
- Заказчик всегда рядом (Whole team, Onsite customer)
- Парное программирование (Pair programming)
- Непрерывная интеграция (Continuous integration)
- Рефакторинг (Design improvement, Refactoring)
- Частые небольшие релизы (Small releases)
- Простота (Simple design)
- Метафора системы (System metaphor)
- Коллективное владение кодом (Collective code ownership) или выбранными шаблонами проектирования (Collective patterns ownership)
- Стандарт кодирования (Coding standard or Coding conventions)
- 40-часовая рабочая неделя (Sustainable pace, Forty-hour week)
DSDM
Метод разработки динамических систем (Dynamic Systems Development Method, DSDM) — это главным образом методика разработки программного обеспечения, основанная на концепции быстрой разработки приложений (Rapid Application Development, RAD). В 2007 году DSDM стал основным подходом к управлению проектом и разработки приложений[источник не указан 635 дней].
В 2007 году DSDM стал основным подходом к управлению проектом и разработки приложений[источник не указан 635 дней].
Принципы
Существует 9 принципов, состоящих из 4 основных и 5 начальных точек.
- Вовлечение пользователя — это основа ведения эффективного проекта, где разработчики делят с пользователями рабочее пространство и поэтому принимаемые решения будут более точными.
- Команда должна быть уполномочена принимать важные для проекта решения без согласования с начальством.
- Частая поставка версий результата, с учётом такого правила, что «поставить что-то хорошее раньше — это всегда лучше, чем поставить всё идеально сделанное в конце». Анализ поставок версий с предыдущей итерации учитывается на последующей.
- Главный критерий — как можно более быстрая поставка программного обеспечения, которое удовлетворяет текущим потребностям рынка. Но в то же время поставка продукта, который удовлетворяет потребностям рынка, менее важна, чем решение критических проблем в функционале продукта.
- Разработка — итеративная и инкрементная. Она основывается на обратной связи с пользователем, чтобы достичь оптимального с экономической точки зрения решения.
- Любые изменения во время разработки — обратимы.
- Требования устанавливаются на высоком уровне прежде, чем начнётся проект.
- Тестирование интегрировано в жизненный цикл разработки.
- Взаимодействие и сотрудничество между всеми участниками необходимо для его эффективности.

Scrum
Scrum (от англ. scrum «толкучка») — методология управления проектами, активно применяющаяся при разработке информационных систем для гибкой разработки программного обеспечения. Scrum чётко делает акцент на качественном контроле процесса разработки.
FDD
Feature driven development (FDD, функционально-ориентированная разработка) — итеративная методология разработки программного обеспечения, одна из гибких методологий разработки (agile). FDD представляет собой попытку объединить наиболее признанные в индустрии разработки программного обеспечения методики, принимающие за основу важную для заказчика функциональность (свойства) разрабатываемого программного обеспечения.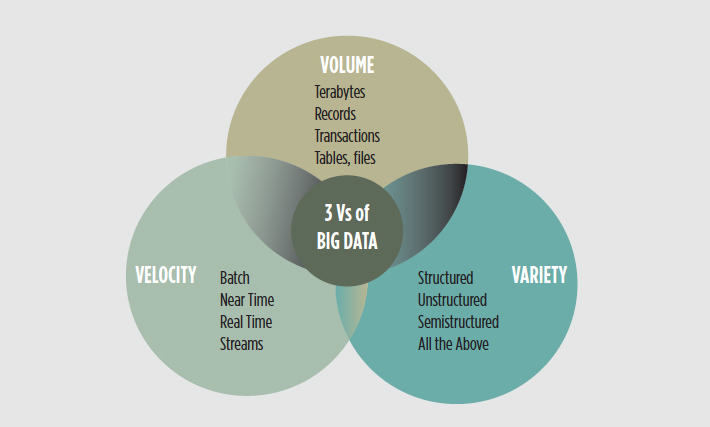 Используемое в FDD понятие функции или свойства (англ. feature) системы достаточно близко к понятию прецедента использования, используемому в RUP, существенное отличие — это дополнительное ограничение: «каждая функция должна допускать реализацию не более, чем за две недели». То есть если сценарий использования достаточно мал, его можно считать функцией. Если же велик, то его надо разбить на несколько относительно независимых функций.
Используемое в FDD понятие функции или свойства (англ. feature) системы достаточно близко к понятию прецедента использования, используемому в RUP, существенное отличие — это дополнительное ограничение: «каждая функция должна допускать реализацию не более, чем за две недели». То есть если сценарий использования достаточно мал, его можно считать функцией. Если же велик, то его надо разбить на несколько относительно независимых функций.
интеллектуального анализа данных вебканалы с помощью сети и MSSQL
SQL Server надстроек интеллектуального анализа данных для .
Надстройки интеллектуального анализа данных SQL Server для Office SQL Server Data Mining Add-Ins for Office. 05/08/2018 .
Get Price
Средства интеллектуального анализа данных (Analysis .
Сведения о средствах интеллектуального анализа данных в SQL Server Analysis Services, включая мастер .
Get Price
Пошаговое руководство по диаграмме сети зависимостей .
Предупреждение. Выделение зависимых узлов и другие параметры контекстного меню, которые были доступны в предыдущих версиях надстройки, не работают в Office 2013.
Get Price
Методы интеллектуального анализа данных Статья в
Jul 04, 2015 Базы данных sql строго регламентируют структуру и жестко придерживаются схемы, что упрощает запросы к ним и анализ+ данных с известным форматом и структурой.
Get PriceAuthor: Светлана Сергеевна Певченко
Надстройки интеллектуального анализа данных для .
Для использования подо.ой «связки», вам должен быть доступен MS SQL Server 2008 в одной из версий, поддерживающих инструменты DataMining (Enterprise, Developer или c некоторыми ограничениями — Standard), MS Office 2007 в версии Professional или более старшей.
Get Price4/5
sql-server — Доступ к службам анализа SQL Server удаленно .
2 unreachable SQL Server для группы компьютеров; 4 Выполнять задачи администратора (например, создавать базу данных, добавлять поддержку диаграмм) в SQL Server, когда он не подключен к домену
Get Price
НОУ ИНТУИТ Интеллектуальный анализ данных средствами
Курс посвящен использованию технологии интеллектуального анализа данных \(Data Mining\) и ее .
Get Price
Packt: принципы обработки и анализа данных Microsoft
Прочтите электронную книгу «Принципы обработки и анализа данных» (PDF) от издательства Packt, чтобы изучить статистические методы и теорию анализа больших данных.
Get Price
НОУ ИНТУИТ Интеллектуальный анализ данных
Курс посвящен использованию технологии интеллектуального анализа данных \(Data Mining\) и ее .
Get Price
Интеллектуальный анализ данных в системах поддержки .
PowerPlay обеспечивает многомерный просмотр данных с нисходящим и уровневым анализом, работу с различными видами дисплеев (таблицами, двумерными и
Get Price
sql-server — Доступ к службам анализа SQL Server удаленно .
2 unreachable SQL Server для группы компьютеров; 4 Выполнять задачи администратора (например, создавать базу данных, добавлять поддержку диаграмм) в SQL Server, когда он не подключен к домену
Get Price
4.3 Системы интеллектуального анализа данных.
4.3 Системы интеллектуального анализа данных. Извлечение знаний из данных. ч.2, Сайт .
Извлечение знаний из данных. ч.2, Сайт .
Get Price
Технологии интеллектуального анализа данных
Многомерный анализ может быть реализован средствами анализа данных офисных приложений и распределенными olap-системами. Исходные и
Get Price
mysql — Как упростить схему для набора данных с .
В настоящее время у нас есть набор данных mysql, который был запущен около 10 лет назад, который объединяет журнал данных и накапливает миллионы строк каждый месяц. Люди, которые разработали нашу систему.
Get Price
Специализация Анализ данных и интеллектуальные
2. Методы анализа «больших данных» (Big Data Analysis), майнинг данных (Data Mining) и визуализация данных (Data Visualization). 3. Машинное обучение (Machine Learning). 4. Анализ формальных понятий (Formal Concept Analysis). 5.
Get Price
sql-server — SQL Server — уникальность идентификатора .
4 Отслеживание использования объекта с помощью SQL Auditing; 2 SQL Server — как работают транзакции и журнал транзакций (упрощено) 4 аудит конкретных событий базы данных
Get Price
Ускоряйте процесс анализа данных с помощью GPU
Ускоряйте процесс анализа данных с помощью gpu nvidia и искусственного интеллекта на любых системах, начиная от дата-центров и заканчивая десктопами и облаком.
Get Price
Руководство разработчика по интеллектуальному анализу .
Аналитика Аналитика Получите такие преимущества, как сбор, хранение, обработка, анализ и визуализация данных любого типа и объема и с любой скоростью.
Get Price
Средства организации баз данных и работы с ними —
Расширенная аналитика в базе данных (Анализ операционных данных с помощью служб R Services в режиме реального времени и с требуемым масштабом непосредственно в базе данных SQL Server, устранив .
Get Price
Data mining — Википедия
Введение. Методы data mining (или, что то же самое, knowledge discovery in data, сокращённо KDD) лежат на стыке баз данных, статистики и искусственного интеллекта.. Исторический экскурс. Область data mining началась с семинара, проведённого .
Get Price
Технологии анализа данных в сети Интернет
Курс ориентирован на изучение методов и технологий, используемых при сборе и анализе данных в сети Интернет, а также на получение практических навыков разработки программных решений для автоматизации данных задач .
Get Price
Пакет дополнительных компонентов Microsoft® SQL
Языковая служба Transact-SQL в SQL Server является компонентом на базе платформы .NET Framework и предоставляет службы проверки, анализа и технологии IntelliSense для Transact-SQL для SQL Server 2014, SQL Server 2012, SQL Server 2008 R2, SQL .
Get Price
Download Microsoft® SQL Server® 2012 SP1 PowerPivot for .
Download Microsoft® SQL Server® 2012 SP1 PowerPivot for Microsoft Excel® 2010 from Official Microsoft Download Center. . отчеты, текстовые файлы и веб-каналы данных. . и определить сложные вычисления с помощью привычных и интуитивно .
Get Price
4.3 Системы интеллектуального анализа данных.
4.3 Системы интеллектуального анализа данных. Извлечение знаний из данных. ч.2, Сайт .
Get Price
Применение программного комплекса интеллектуального .
В статье рассматривается программный комплекс интеллектуального анализа данных .
Get Price
Технологии анализа данных в сети Интернет
Курс ориентирован на изучение методов и технологий, используемых при сборе и анализе данных в сети Интернет, а также на получение практических навыков разработки программных решений для автоматизации данных задач .
Get Price
mysql — Как упростить схему для набора данных с .
В настоящее время у нас есть набор данных mysql, который был запущен около 10 лет назад, который объединяет журнал данных и накапливает миллионы строк каждый месяц. Люди, которые разработали нашу систему.
Get Price
Интеллектуальная обработка данных и хранилищ данных в
Сложная интеграция данных и задачи управления изменением данных лучше решаются с помощью классической архитектуры хранилищ данных, с базой данных Analysis Services в виде ядра выполнения .
Get Price
Специализация Анализ данных и интеллектуальные
2. Методы анализа «больших данных» (Big Data Analysis), майнинг данных (Data Mining) и визуализация данных (Data Visualization). 3. Машинное обучение (Machine Learning). 4. Анализ формальных понятий (Formal Concept Analysis). 5.
Get Price
Диссертация на тему «Модели информационного обмена и .
Власов, Александр Борисович. Модели информационного обмена и методы формирования обобщенных технико-экономических показателей предприятий в системе поддержки управленческих решений: дис. кандидат технических .
кандидат технических .
Get Price
Ускоряйте процесс анализа данных с помощью GPU
Ускоряйте процесс анализа данных с помощью gpu nvidia и искусственного интеллекта на любых системах, начиная от дата-центров и заканчивая десктопами и облаком.
Get Price
Общие принципы анализа данных
Если вы производите обработку данных на компьютере (например, с помощью пакета spss), то более или менее подро.ая логическая схема анализа будет включать в
Get Price[PDF]
Сеть как источник данных для анализа сетевого
Обзор сети с помощью Netflow 10.1.8.3 172.168.134.2 Internet Flow Information Packets SOURCE ADDRESS 10.1.8.3 DESTINATION ADDRESS 172.168.134.2 SOURCE PORT 47321 DESTINATION PORT 443 INTERFACE Gi0/0/0 IP TOS 0x00 IP PROTOCOL 6 NEXT HOP 172.168.25.1 TCP FLAGS 0x1A SOURCE SGT 100: : APPLICATION NAME NBAR SECURE-HTTP Switches Routers
Get Price
Защита информации в сети Интернет
Начиная с 1999 года Интернет становится мощным средством обеспечения розничного торгового оборота, а это требует защиты данных кредитных карт и других электронных платежных средств.
Get Price
Пакет дополнительных компонентов Microsoft® SQL Server .
Пакет дополнительных компонентов Microsoft SQL Server 2014 с пакетом о.овления 2 (SP2) — это набор автономных пакетов, расширяющих возможности Microsoft SQL Server.
Get Price
Официальный сайт лейбла 100PRO
Пресс-релиз. Саша Шкалей & MonoSoul — Оставаться Молодыми. Компания 100PRO представляет дуэт «Саша Шкалей и MonoSoul», который основан в Санкт-Петербурге.
23 апреля в Новосибирске состоится концерт группы Bad Balance в кабаре-кафе «Бродячая Собака». В программе выступления прозвучат Ваши любимые хиты со всех альбомов Bad B. (Городская Тоска, Светлая Музыка, Город Джунглей, Питер — Я Твой!, Города и др.). …
Вера — совместная работа двух рэп групп: Перелом и Bad Balance. Музыкантов сплотила идея создать рэп композицию, которая могла бы дать веру в дружбу между Россией и Украиной. Известные рэп музыканты двух стран через свою музыку показывают всему миру, что для истинного творчества нет границ и национальностей.
Музыкантов сплотила идея создать рэп композицию, которая могла бы дать веру в дружбу между Россией и Украиной. Известные рэп музыканты двух стран через свою музыку показывают всему миру, что для истинного творчества нет границ и национальностей.
Представляем видео с фестиваля Rap Music 2020, который прошел 12 декабря в клубе «Правда». Видео снято и смонтировано командой Алены Парфеновой. Живой звук.
ШЕFF представляет клип «Мы говорим» к альбому «Новая Школа». В клипе снялась семья Валовых. Текст: ШЕFF, King Artur, Lil Sheff; музыка: Girich; режиссер: Влад Валов, Татьяна Валова.
- Поздравляем победителей фестиваля Rap Music 2020, который прошел 12 декабря.
- Гран-При — TRU Clan / Москва
- 1 место — LP42 / Новокузнецк
- 2 место — Шторм / Москва
- 3 место — ФАНК100 / Ногинск
- Лучший МС — R1fmabes #3ТИПА / Калуга
Рецензия на альбом Вуду «REволюционика» от независимого музыкального критика — Марка Томашевского.
Bad Balance представляет клип «Не верю» из будущего альбома.
4 января все вместе празднуем Новый год с группой Bad Balance в клубе Lookin Rooms. Состоится большой концерт, будет много гостей, сюрпризов и подарков. Билеты от 900 руб по ссылке
Indigo, Jahn, Slavon совместно с ШЕFFом представляют клип Страны. В клипе рэп исполнители рассказывают о местах на планете, которые хотели бы посетить. Сингл вошел в альбом Indigo, Jahn, Slavon — Хип-хоп из будущего. Музыка: Ole-G, текст: Indigo, Jahn, Slavon, ШЕFF, оператор: Владимир Дрожжин, режиссер: Влад Валов.
У рэп исполнителя лейбла 100PRO Синего из группы БасотА NiggaZ случилось несчастье: сгорел дом. В этом доме он не только жил со своей женой и малолетним ребёнком, но и вёл школу брейк-данса, принимал гостей из мира хип-хопа. Дом был творческой базой и единственным источником дохода для Синего и его семьи. После ночного пожара творческая база сгорела. Синий в отчаянии. Его семья осталась без средств к существованию и жилья. Рэп артист просит о помощи.
Дом был творческой базой и единственным источником дохода для Синего и его семьи. После ночного пожара творческая база сгорела. Синий в отчаянии. Его семья осталась без средств к существованию и жилья. Рэп артист просит о помощи.
«Легенда» на RTVI — программа о неординарных личностях, чьи имена вошли в историю. Гости студии — актеры, музыканты, продюсеры, журналисты, звезды спорта и политики. В этом выпуске — музыкант Влад Валов (ШЕFF). Он рассказал, как зарождалась хип-хоп культура в России, легко ли было парням с улицы пробиться в шоу-бизнесе и каким образом они научили всех слушать рэп на русском.
Представляем всеобщему вниманию 10 участников фестиваля Rap Musi 2020, который пройдет 12 декабря в клубе «Правда», начало в 18:00.
Футбольно-музыкальный турнир «Арт-футбол 2020» состоится в манеже «Спартак» в Сокольниках 3 и 4 ноября 2020 года при поддержке Департамента спорта города Москвы. В первый день турнира между собой будут состязаться восемь артистических московских команд. Среди них команда рэп артистов «Налетчики», команда звезд эстрады «Старко», команда участников проекта Comedy Club, команда Цирка братьев Запашных, блогеров и театральных артистов.
В первый день турнира между собой будут состязаться восемь артистических московских команд. Среди них команда рэп артистов «Налетчики», команда звезд эстрады «Старко», команда участников проекта Comedy Club, команда Цирка братьев Запашных, блогеров и театральных артистов.
Компания 100PRO представляет клип Indigo, Jahn, Slavon — Танцы. На этот раз клип посвящен танцам. Трек получился по-настоящему заводным и танцевальным, на него был снят красочный танцевальный клип, в котором приняли участие танцоры со всего мира. С первых же нот хочется танцевать!
Выбери 10 лучших для участия в фестивале Rap Music 2020, который пройдет 12 декабря в клубе»Правда». Вступайте в нашу Группу в ВК, следите за новостями, делайте репосты и поддержите достойные рэп-коллективы своими голосами.
ШЕFF тветил на вопросы интернет изданию A Starting Point об альбоме «Новая Школа», фестивале Rap Music, любимых книгах, сигарах, виски, спорте, badbalanceradio. ru и не только… читать
ru и не только… читать
Стала известна дата и место проведения фестиваля Rap Music 2020. А именно, 12 декабря / суббота / клуб «Правда» / м. Савеловская, ул. Правды 24 стр.3. / старт в 18:00. Ждите инфо по гостям и группам участникам до конца октября! Билеты здесь.
Рецензия на альбом ШЕFFа «Новая Школа» от независимого музыкального критика.
Новинка от Popovi4 и Denny Presston. Грязные биты выраженные в классическом стиле настоящего хип-хопа, техничный речитатив и тонны первоклассных запилов, все это Boom bap tape. Именно так должна звучать классическая рэп музыка в 2020 году. Слушайте на всех площадках с 23.10.
Big Data: что это такое и почему это важно
История больших данных
Термин «большие данные» относится к данным, которые настолько большие, быстрые или сложные, что их сложно или невозможно обработать традиционными методами. Акт доступа и хранения больших объемов информации для аналитики существует уже давно. Но концепция больших данных набрала обороты в начале 2000-х, когда отраслевой аналитик Дуг Лэйни сформулировал ныне распространенное определение больших данных как три V:
Акт доступа и хранения больших объемов информации для аналитики существует уже давно. Но концепция больших данных набрала обороты в начале 2000-х, когда отраслевой аналитик Дуг Лэйни сформулировал ныне распространенное определение больших данных как три V:
Том : Организации собирают данные из различных источников, включая бизнес-транзакции, интеллектуальные (IoT) устройства, промышленное оборудование, видео, социальные сети и многое другое.В прошлом его хранение было проблемой, но более дешевое хранилище на таких платформах, как озера данных и Hadoop, облегчило бремя.
Скорость : С ростом Интернета вещей потоки данных на предприятиях с беспрецедентной скоростью, и их необходимо обрабатывать своевременно. RFID-метки, датчики и интеллектуальные счетчики вызывают необходимость иметь дело с этими потоками данных в режиме, близком к реальному.
Разнообразие : Данные поступают во всех типах форматов — от структурированных числовых данных в традиционных базах данных до неструктурированных текстовых документов, электронных писем, видео, аудио, данных биржевых котировок и финансовых транзакций.
В SAS мы рассматриваем два дополнительных аспекта, когда дело касается больших данных:
Вариативность:
Помимо увеличения скорости и разнообразия данных, потоки данных непредсказуемы — часто меняются и сильно различаются. Это сложно, но предприятиям необходимо знать, когда в социальных сетях что-то меняется, и как управлять ежедневными, сезонными и вызванными событиями пиковыми нагрузками данных.
Верность:
Под достоверностью понимается качество данных.Поскольку данные поступают из множества разных источников, сложно связывать, сопоставлять, очищать и преобразовывать данные между системами. Компаниям необходимо соединить и соотнести отношения, иерархии и множественные связи данных. В противном случае их данные могут быстро выйти из-под контроля.
Определение и значение больших данных
Большие данные — это фраза, которая используется для обозначения огромного объема как структурированных, так и неструктурированных данных, который настолько велик, что его трудно обработать с использованием традиционных баз данных и программных средств. В большинстве корпоративных сценариев объем данных слишком велик, перемещается слишком быстро или превышает текущую мощность обработки.
В большинстве корпоративных сценариев объем данных слишком велик, перемещается слишком быстро или превышает текущую мощность обработки.
Интеллектуальные решения
Big Data может помочь компаниям улучшить операции и принимать более быстрые и разумные решения. Данные собираются из ряда источников, включая электронную почту, мобильные устройства, приложения, базы данных, серверы и другие средства. Эти данные, когда они собираются, форматируются, обрабатываются, хранятся и затем анализируются, могут помочь компании получить полезную информацию для увеличения доходов, привлечения или удержания клиентов и улучшения операций.
Большие данные — это объем или технология?
Хотя может показаться, что этот термин относится к объему данных, это не всегда так. Термин «большие данные», особенно когда он используется поставщиками, может относиться к технологии (которая включает инструменты и процессы), которая требуется организации для обработки больших объемов данных и средств хранения. Считается, что этот термин появился в компаниях, занимающихся поиском в Интернете, которым нужно было запрашивать очень большие распределенные агрегаты слабо структурированных данных.
Считается, что этот термин появился в компаниях, занимающихся поиском в Интернете, которым нужно было запрашивать очень большие распределенные агрегаты слабо структурированных данных.
Пример
Примером больших данных могут быть петабайты (1024 терабайта) или эксабайты (1024 петабайта) данных, состоящих из миллиардов или триллионов записей миллионов людей из разных источников (например, Интернет, продажи, контакт-центр клиентов, социальные сети, мобильные устройства). данные и так далее). Данные обычно представляют собой слабо структурированные данные, которые часто бывают неполными и недоступными.
Наборы бизнес-данных
При работе с большими наборами данных организации сталкиваются с трудностями в возможности создавать большие данные, манипулировать ими и управлять ими.Большие данные представляют собой особую проблему для бизнес-аналитики, поскольку стандартные инструменты и процедуры не предназначены для поиска и анализа массивных наборов данных.
Рекомендуем к прочтению: См. Соответствующую фразу «Аналитика больших данных».
Что такое определение науки о данных
Что такое наука о данных?
Наука о данных — это область исследования, которая сочетает в себе опыт в предметной области, навыки программирования, а также знания математики и статистики для извлечения значимой информации из данных.Специалисты в области науки о данных применяют алгоритмы машинного обучения к числам, тексту, изображениям, видео, аудио и т. Д. Для создания систем искусственного интеллекта (ИИ) для выполнения задач, которые обычно требуют человеческого интеллекта. В свою очередь, эти системы генерируют идеи, которые аналитики и бизнес-пользователи могут преобразовать в реальную ценность для бизнеса.
Почему важна наука о данных?
Все больше и больше компаний осознают важность науки о данных, искусственного интеллекта и машинного обучения.Независимо от отрасли или размера организациям, которые хотят оставаться конкурентоспособными в эпоху больших данных, необходимо эффективно разрабатывать и внедрять возможности науки о данных, иначе они рискнут остаться позади.
Data Science + DataRobot
Наращивание усилий в области науки о данных затруднено даже для компаний с почти неограниченными ресурсами. Платформа автоматизированного машинного обучения DataRobot демократизирует науку о данных и искусственный интеллект, позволяя аналитикам, бизнес-пользователям и другим техническим специалистам становиться гражданскими специалистами по данным и инженерами в области искусственного интеллекта, а также повышает продуктивность специалистов по данным.Он автоматизирует повторяющиеся задачи моделирования, которые когда-то занимали большую часть времени и умственных способностей специалистов по данным. DataRobot устраняет разрыв между специалистами по обработке данных и остальной частью организации, делая машинное обучение на предприятии более доступным, чем когда-либо.
Ведущий эксперт в области науки о данных. Доступно любому
Доступно любому
Определение больших данных
Что такое большие данные?
Под большими данными понимаются большие и разнообразные наборы информации, которые растут с постоянно увеличивающейся скоростью.Он включает в себя объем информации, скорость или скорость, с которой она создается и собирается, а также разнообразие или объем охватываемых точек данных (известных как «три v» больших данных). Большие данные часто возникают в результате интеллектуального анализа данных и поступают в разных форматах.
Ключевые выводы
- Большие данные — это огромное количество разнообразной информации, которая поступает во все возрастающих объемах и со все большей скоростью.
- Большие данные могут быть структурированными (часто числовыми, легко форматируемыми и сохраняемыми) или неструктурированными (более свободной формой, менее поддающимися количественной оценке).
- Практически каждый отдел компании может использовать результаты анализа больших данных, но обработка их беспорядка и шума может создать проблемы.
- Большие данные могут быть собраны из общедоступных комментариев в социальных сетях и на веб-сайтах, добровольно собираемых из личной электроники и приложений, с помощью анкет, покупок продуктов и электронных проверок.
- Большие данные чаще всего хранятся в компьютерных базах данных и анализируются с помощью программного обеспечения, специально разработанного для обработки больших и сложных наборов данных.

Как работают большие данные
Большие данные можно разделить на неструктурированные и структурированные. Структурированные данные состоят из информации, уже управляемой организацией в базах данных и электронных таблицах; это часто числовой характер. Неструктурированные данные — это неорганизованная информация, не подпадающая под заданную модель или формат. Он включает данные, собранные из источников в социальных сетях, которые помогают учреждениям собирать информацию о потребностях клиентов.
Большие данные могут быть собраны из общедоступных комментариев в социальных сетях и на веб-сайтах, добровольно собираемых из личной электроники и приложений, с помощью анкет, покупок продуктов и электронных проверок.Наличие датчиков и других входов в интеллектуальных устройствах позволяет собирать данные в широком спектре ситуаций и обстоятельств.
Большие данные чаще всего хранятся в компьютерных базах данных и анализируются с помощью программного обеспечения, специально разработанного для обработки больших и сложных наборов данных. Многие компании, предлагающие программное обеспечение как услугу (SaaS), специализируются на управлении такими сложными данными.
Использование больших данных
Аналитики данных изучают взаимосвязь между различными типами данных, такими как демографические данные и история покупок, чтобы определить, существует ли корреляция.Такие оценки могут выполняться внутри компании или за ее пределами третьей стороной, которая занимается обработкой больших данных в удобоваримых форматах. Компании часто используют оценку больших данных такими экспертами, чтобы превратить их в полезную информацию.
Компании часто используют оценку больших данных такими экспертами, чтобы превратить их в полезную информацию.
Многие компании, такие как Alphabet и Facebook, используют большие данные для получения дохода от рекламы, размещая таргетированную рекламу для пользователей в социальных сетях и тех, кто просматривает Интернет.
Практически каждый отдел компании может использовать результаты анализа данных, от человеческих ресурсов и технологий до маркетинга и продаж.Цель больших данных — увеличить скорость вывода продуктов на рынок, сократить количество времени и ресурсов, необходимых для принятия на рынок, целевой аудитории и обеспечения удовлетворенности клиентов.
Преимущества и недостатки больших данных
Увеличение объема доступных данных представляет как возможности, так и проблемы. В целом, наличие большего количества данных о клиентах (и потенциальных клиентах) должно позволить компаниям лучше адаптировать продукты и маркетинговые усилия для достижения максимального уровня удовлетворенности и повторного ведения бизнеса. Компаниям, которые собирают большие объемы данных, предоставляется возможность проводить более глубокий и обширный анализ на благо всех заинтересованных сторон.
Компаниям, которые собирают большие объемы данных, предоставляется возможность проводить более глубокий и обширный анализ на благо всех заинтересованных сторон.
При таком количестве персональных данных, которые доступны сегодня о физических лицах, крайне важно, чтобы компании предприняли шаги для защиты этих данных; тема, которая стала жаркой дискуссией в сегодняшнем онлайн-мире, особенно в связи с множеством утечек данных, с которыми компании столкнулись за последние несколько лет.
Хотя лучший анализ — это положительно, большие данные также могут создавать перегрузку и шум, снижая их полезность.Компании должны обрабатывать большие объемы данных и определять, какие данные представляют собой сигналы по сравнению с шумом. Решающим фактором становится определение того, что делает данные актуальными.
Кроме того, природа и формат данных могут потребовать особой обработки, прежде чем они будут приняты. Структурированные данные, состоящие из числовых значений, можно легко хранить и сортировать. Для неструктурированных данных, таких как электронные письма, видео и текстовые документы, могут потребоваться более сложные методы, прежде чем они станут полезными.
Для неструктурированных данных, таких как электронные письма, видео и текстовые документы, могут потребоваться более сложные методы, прежде чем они станут полезными.
БОЛЬШИЕ ДАННЫЕ | Определение
в кембриджском словаре английского языка
Полученный в результате « большой данные » предлагает статистическую мощность, необходимую для определения того, какие обучающие действия помогают каким учащимся в каких случаях.
Херст — ведущий эксперт в области пользовательских интерфейсов для поисковых систем и big data аналитики.Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Эти примеры взяты из корпусов и из источников в Интернете.Любые мнения в примерах не отражают мнение редакторов Cambridge Dictionary, Cambridge University Press или ее лицензиаров.
Еще примеры
Меньше примеров
Personal помог популяризировать концепцию малых данных, которую он определяет как больших данных в интересах отдельных лиц. Из
Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Ее продукты решают проблемы, которые иногда называются big data .Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Электронная наука включает в себя то, что часто называют big data , которая произвела революцию в науке. ..
..
Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Это большая data компания, которая использует данные о местоположении для обеспечения превосходного таргетинга рекламы на мобильных устройствах.Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Огромный объем сенсорных данных в дополнение к историческим данным создает большой данные в производстве.Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Big данных Размеры — постоянно меняющаяся цель, от нескольких десятков терабайт до многих петабайт данных в одном наборе данных. Из
Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Эти качества несовместимы с системами аналитики big data , которые преуспевают за счет производительности системы, стандартной инфраструктуры и низкой стоимости.Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Облако используется для обеспечения масштабируемого способа потоковой передачи игрового контента и анализа больших данных . Из
Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Это делает ее одной из пяти крупнейших в мире крупных организаций, занимающихся обработкой данных, и владельцев крупнейших в мире наборов данных о потреблении медиа.Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Рост числа больших данных привел к тому, что многие компании, занимающиеся традиционными хранилищами данных, обновили свои продукты и технологии. Из
Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Таким образом, есть некоторое совпадение с big data , международным развитием и участием сообщества.Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
big data наборы используются для прогнозной аналитики, что позволяет компании оптимизировать операции, прогнозируя привычки клиентов. Из
Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
В ходе обсуждения было изучено влияние big data , развитие технологий и развивающиеся конкурентные преимущества, которые дает аналитика.Из
Википедия
Этот пример взят из Википедии и может быть повторно использован по лицензии CC BY-SA.
Hadoop Вики
Hadoop Вики
Apache Hadoop
Hadoop — это среда распределенной обработки с открытым исходным кодом, основанная на языке программирования Java, для хранения и обработки больших объемов структурированных / неструктурированных данных в кластерах стандартного оборудования. Это платформа больших данных с огромной вычислительной мощностью и способностью обрабатывать неограниченное количество одновременных заданий.
Это платформа больших данных с огромной вычислительной мощностью и способностью обрабатывать неограниченное количество одновременных заданий.
Свинья Apache
Apache Pig — это компонент hadoop, который обеспечивает абстракцию над MapReduce, чтобы программисты могли анализировать большие объемы данных с помощью процедурного языка Pig Latin. Все скрипты Pig Latin преобразуются в задания Hadoop MapReduce внутри Pig Engine.Apache Pig может выполнять задания также в Apache Spark или Apache Tez.
Ссылки Apache Pig Wiki
Улей Apache
Apache Hive — это хранилище данных, подобное инфраструктуре, построенной на основе Hadoop для запроса данных, суммирования данных и анализа данных.
Он предоставляет SQL-подобный интерфейс для выполнения заданий MapReduce через Hive Query Language (HiveQL).Все запросы Hive разделяются службой Hive на простые задания MapReduce, а затем выполняются в кластере Hadoop.
Ссылки Apache Hive Wiki
Apache HBase
HBase — это распределенная база данных NoSQL с открытым исходным кодом, ориентированная на столбцы, для доступа чтения / записи в режиме реального времени к большим наборам данных, построенных на основе HDFS.
Это горизонтально масштабируемая база данных, обеспечивающая низкую задержку, что позволяет быстрее просматривать даже большие таблицы.HBase хорошо работает с разреженными наборами данных и предоставляет функции Google Big Table для Hadoop.
Apache HBase Wiki Ссылки
Apache Sqoop
Sqoop получил свое название от двух различных и известных технологий SQL и Hadoop, то есть «Sq.» из SQL и «уп» из Hadoop.
Sqoop — это инструмент, который в основном используется для массовой передачи данных, поэтому данные из различных реляционных баз данных, хранилищ данных или даже из хранилищ данных NoSQL можно легко импортировать / экспортировать. На основе архитектуры на основе коннекторов другие инструменты также могут быть подключены к Sqoop, и Sqoop также может быть очень легко подключен к другим инструментам, таким как плагины.
На основе архитектуры на основе коннекторов другие инструменты также могут быть подключены к Sqoop, и Sqoop также может быть очень легко подключен к другим инструментам, таким как плагины.
Например, Sqoop можно подключить к Apache Oozie, инструменту управления рабочим процессом, а задачи импорта / экспорта можно автоматизировать.
Ссылки Apache Sqoop Wiki
Apache Flume
Flume — это инструмент приема данных, используемый для отправки потоковых данных, таких как файлы журналов, события и т. Д.из разных источников в HDFS.
Это эффективный и надежный распределенный инструмент для сбора, агрегирования и передачи данных с нескольких веб-серверов в централизованное хранилище данных.
Ссылки на Apache Flume Wiki
Apache Oozie
Oozie — это веб-приложение на основе Java, используемое для планирования заданий Hadoop.
Разработчики Hadoop могут выполнять серию заданий по заданному расписанию, организовав их в упорядоченный конвейер в распределенной среде. Oozie тесно связан с другими компонентами Hadoop, такими как Pig, Hive и Sqoop, и поэтому может поддерживать выполнение различных заданий Hadoop.
Oozie тесно связан с другими компонентами Hadoop, такими как Pig, Hive и Sqoop, и поэтому может поддерживать выполнение различных заданий Hadoop.
Ссылки Apache Oozie Wiki
Большие данные
Под большими данными понимаются большие и сложные наборы данных (структурированные и неструктурированные), которые невозможно вычислить и обработать с помощью традиционных приложений.
Большие данные характеризуются тремя важными буквами V — объемом, скоростью и разнообразием:
- Объем больших данных может быть измерен в единицах или нескольких мегабайтах, гигабайтах, терабайтах или петабайтах
- Разнообразие — большие данные могут существовать в различных форматах файлов, в хранилищах баз данных SQL, данных датчиков, данных социальных сетей или данных в любой другой форме.
- Под скоростью больших данных понимается скорость, с которой данные могут быть проанализированы для получения значимой коммерческой выгоды.

Datanode
DataNode — это машина, на которой фактические данные находятся в кластере hadoop.
Данные в файле реплицируются на несколько узлов данных в зависимости от коэффициента репликации для достижения надежности в случае сбоя.DataNode в архитектуре Hadoop называется подчиненным компьютером.
Кластер Hadoop
Hadoop Cluster — это особая форма компьютерного кластера, предназначенная для хранения и анализа (структурированных и неструктурированных данных), работающая на программном обеспечении распределенной обработки с открытым исходным кодом Hadoop.
В отличие от обычного компьютерного кластера, содержащего высокопроизводительные серверы, кластер hadoop состоит из недорогих обычных компьютеров.Кластер hadoop состоит из NameNode, DataNode, Job Tracker и Task Tracker.
Общий Hadoop
Это неотъемлемый компонент экосистемы hadoop, который состоит из общих библиотек и базовых утилит для поддержки других компонентов hadoop — HDFS, MapReduce и YARN.
HDFS
Распределенная файловая система Hadoop (HDFS) является основным компонентом хранилища в структуре Hadoop.HDFS — это масштабируемая файловая система на основе Java, которая надежно хранит большие наборы структурированных или неструктурированных данных.
Ссылки на Hadoop HDFS Wiki
MapReduce
MapReduce — это парадигма программирования на основе Java для обработки больших объемов данных, хранящихся в HDFS или любых других файловых системах хранения.
MapReduce — это сердце инфраструктуры Apache Hadoop, которое обеспечивает масштабируемость для тысяч кластеров Hadoop.Каждое задание MapReduce выполняет две отдельные задачи, как следует из названия, — одну задачу Map и одну задачу Reduce.
Задание карты принимает набор данных, обрабатывает его на уровне узла и генерирует выходные данные (другой набор данных).
Задание сокращения принимает выходные данные задания карты в качестве входных и объединяет их в меньший набор кортежей (сокращает большой набор данных в меньший) на основе преобразований и бизнес-логики.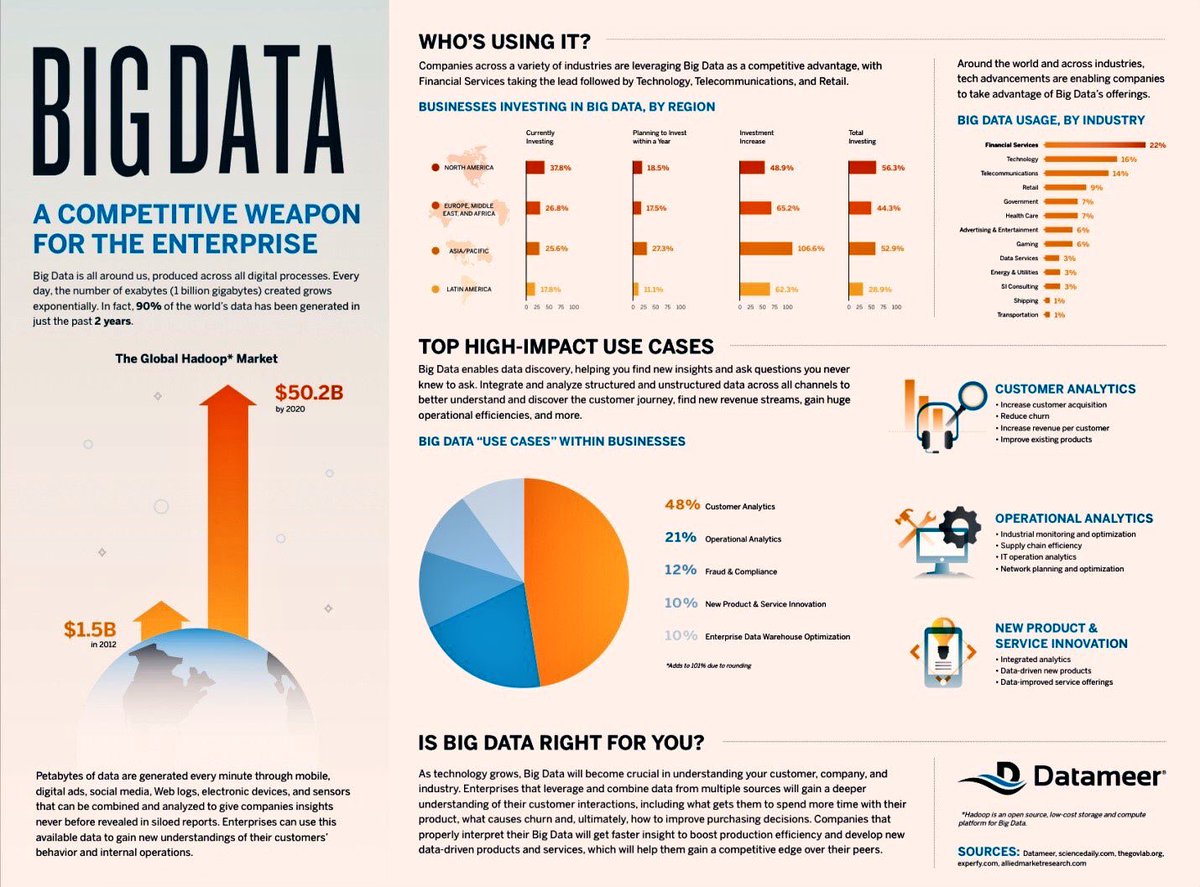
Ссылки на MapReduce Wiki
ПРЯЖА
Еще один согласователь ресурсов (YARN) — это технология управления кластером в Hadoop 2.0.
Основная функциональность YARN заключается в том, что он разделяет мониторинг или планирование заданий и управление ресурсами на два отдельных демона, имея единого глобального диспетчера ресурсов.
YARN позволяет использовать Hadoop для операционных приложений, которые не могут дождаться завершения пакетных заданий.
YARN делает экосистему hadoop более устойчивой и предоставляет вычислительную среду с открытым исходным кодом, которую легко масштабировать в будущем.
Раннее прогнозирование кассовых сборов фильмов на основе данных из Википедии
Abstract
Использование «больших данных», генерируемых обществом, для доступа к информации о коллективных состояниях разума в человеческих обществах стало новой парадигмой в развивающейся области вычислительной социальной науки. Естественным применением этого было бы предсказание реакции общества на новый продукт в смысле популярности и скорости принятия. Однако преодоление разрыва между «мониторингом в реальном времени» и «ранним прогнозированием» остается большой проблемой. Здесь мы сообщаем об усилиях по созданию минималистичной модели прогнозирования финансового успеха фильмов на основе данных коллективной активности онлайн-пользователей. Мы показываем, что популярность фильма можно предсказать задолго до его выпуска, измерив и проанализировав уровень активности редакторов и зрителей соответствующей записи о фильме в Википедии, известной онлайн-энциклопедии.
Естественным применением этого было бы предсказание реакции общества на новый продукт в смысле популярности и скорости принятия. Однако преодоление разрыва между «мониторингом в реальном времени» и «ранним прогнозированием» остается большой проблемой. Здесь мы сообщаем об усилиях по созданию минималистичной модели прогнозирования финансового успеха фильмов на основе данных коллективной активности онлайн-пользователей. Мы показываем, что популярность фильма можно предсказать задолго до его выпуска, измерив и проанализировав уровень активности редакторов и зрителей соответствующей записи о фильме в Википедии, известной онлайн-энциклопедии.
Образец цитирования: Местьян М., Яссери Т., Кертес Дж. (2013) Раннее предсказание успеха кассовых сборов фильмов на основе больших данных в Википедии. PLoS ONE 8 (8):
e71226.
https://doi.org/10.1371/journal.pone.0071226
Редактор: Аттила Сольноки, Венгерская академия наук, Венгрия
Поступила: 5 ноября 2012 г . ; Принята к печати: 28 июня 2013 г .; Опубликовано: 21 августа 2013 г.
; Принята к печати: 28 июня 2013 г .; Опубликовано: 21 августа 2013 г.
Авторские права: © 2013 Mestyán et al.Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Финансирование: Частичная финансовая поддержка от проекта FET-Open для ICTeCollective 7-й рамочной программы ЕС. 238597 и Академией Финляндии, программой Финского центра передового опыта, проект № 129670 и TEKES (FiDiPro) выражают признательность.Финансирующие организации не играли никакой роли в дизайне исследования, сборе и анализе данных, принятии решения о публикации или подготовке рукописи.
Конкурирующие интересы: Авторы заявили, что никаких конкурирующих интересов не существует.
Введение
Жизнь в современном цифровом мире, наряду со всеми преимуществами, также имеет свои побочные эффекты и побочные продукты. Наша повседневная жизнь в настоящее время оставляет цифровой след всей нашей деятельности в недавно разработанной среде, основанной на информационных и коммуникационных технологиях.Наши социальные связи через различные цифровые каналы, финансовая деятельность в рамках электронной коммерции, физические местоположения, зарегистрированные операторами мобильной связи и т. Д., Отслеживаются и записываются. В дополнение к такому пассивному сбору данных об онлайн-активности мы также активно делимся информацией о наших чувствах, эмоциональном настроении, мнениях и взглядах через так называемый Web 2.0. или пользовательский контент в социальных сетях. Помимо предоставления нам новых ответов на классические вопросы об индивидуальных и социальных аспектах человеческой жизни с научной точки зрения, точный анализ этого огромного количества данных может иметь практическое применение для прогнозирования, отслеживания и преодоления множества различных типов событий. , от простых повседневных дел до массовых кризисов в глобальном масштабе.
Наша повседневная жизнь в настоящее время оставляет цифровой след всей нашей деятельности в недавно разработанной среде, основанной на информационных и коммуникационных технологиях.Наши социальные связи через различные цифровые каналы, финансовая деятельность в рамках электронной коммерции, физические местоположения, зарегистрированные операторами мобильной связи и т. Д., Отслеживаются и записываются. В дополнение к такому пассивному сбору данных об онлайн-активности мы также активно делимся информацией о наших чувствах, эмоциональном настроении, мнениях и взглядах через так называемый Web 2.0. или пользовательский контент в социальных сетях. Помимо предоставления нам новых ответов на классические вопросы об индивидуальных и социальных аспектах человеческой жизни с научной точки зрения, точный анализ этого огромного количества данных может иметь практическое применение для прогнозирования, отслеживания и преодоления множества различных типов событий. , от простых повседневных дел до массовых кризисов в глобальном масштабе. Например, Sakaki et al. разработали систему оповещения, основанную на твитах (сообщениях в службе микроблогов Twitter), которая позволяет обнаруживать землетрясения практически в реальном времени [1]. Они развивают свою систему обнаружения, чтобы обнаруживать радугу в небе и пробки в городах [2]. Практический смысл их работы заключается в том, что система оповещения может работать настолько быстро, что предупреждающее сообщение может приходить в определенные регионы быстрее, чем волны землетрясения. Боллен и др. проанализировали настроение твитов и на основании своих исследований смогли предсказать ежедневные изменения в значениях промышленного индекса Доу-Джонса с точностью до 87.6% [3]. Saavedra et al. исследовали взаимосвязь между содержанием сообщений трейдеров и динамикой рынка. Они показывают, что существует положительная корреляция между использованием «связок» положительных и отрицательных слов с общими финансовыми показателями агентов [4]. Другой пример — использование Twitter для прогнозирования результатов выборов [5], однако с его предвзятостью и ограничениями [6], [7].
Например, Sakaki et al. разработали систему оповещения, основанную на твитах (сообщениях в службе микроблогов Twitter), которая позволяет обнаруживать землетрясения практически в реальном времени [1]. Они развивают свою систему обнаружения, чтобы обнаруживать радугу в небе и пробки в городах [2]. Практический смысл их работы заключается в том, что система оповещения может работать настолько быстро, что предупреждающее сообщение может приходить в определенные регионы быстрее, чем волны землетрясения. Боллен и др. проанализировали настроение твитов и на основании своих исследований смогли предсказать ежедневные изменения в значениях промышленного индекса Доу-Джонса с точностью до 87.6% [3]. Saavedra et al. исследовали взаимосвязь между содержанием сообщений трейдеров и динамикой рынка. Они показывают, что существует положительная корреляция между использованием «связок» положительных и отрицательных слов с общими финансовыми показателями агентов [4]. Другой пример — использование Twitter для прогнозирования результатов выборов [5], однако с его предвзятостью и ограничениями [6], [7]. Появились интересные исследования, посвященные использованию индикаторов социальных сетей для прогнозирования научного воздействия исследовательских статей, например.g., краткосрочное использование Интернета (количество загрузок с веб-сайта предварительной печати «arXiv») [8] и упоминания в Twitter [9]. В недавней работе показано, что упоминания в Twitter и загрузки arXiv следуют двум различным временным паттернам активности, однако объем упоминаний в Twitter статистически коррелирует с загрузками arXiv и ранними цитированиями [10]. Preis et al. обнаружили корреляцию между еженедельными объемами транзакций «компаний S&P 500» и недельными объемами поиска в Google соответствующих названий компаний [11].Анализируя поисковые запросы информации о предшествующих и последующих годах, можно увидеть «поразительную» корреляцию между ВВП страны и предрасположенностью ее жителей смотреть вперед [12]. На основе журналов поиска Google Ginsberg et al. оценили распространение гриппа в США [13]. Существуют и другие примеры использования потоков социальных сетей для прогнозирования популярности новостей с точки зрения количества пользовательских комментариев [14], [15] или количества посетителей новостей [16].
Появились интересные исследования, посвященные использованию индикаторов социальных сетей для прогнозирования научного воздействия исследовательских статей, например.g., краткосрочное использование Интернета (количество загрузок с веб-сайта предварительной печати «arXiv») [8] и упоминания в Twitter [9]. В недавней работе показано, что упоминания в Twitter и загрузки arXiv следуют двум различным временным паттернам активности, однако объем упоминаний в Twitter статистически коррелирует с загрузками arXiv и ранними цитированиями [10]. Preis et al. обнаружили корреляцию между еженедельными объемами транзакций «компаний S&P 500» и недельными объемами поиска в Google соответствующих названий компаний [11].Анализируя поисковые запросы информации о предшествующих и последующих годах, можно увидеть «поразительную» корреляцию между ВВП страны и предрасположенностью ее жителей смотреть вперед [12]. На основе журналов поиска Google Ginsberg et al. оценили распространение гриппа в США [13]. Существуют и другие примеры использования потоков социальных сетей для прогнозирования популярности новостей с точки зрения количества пользовательских комментариев [14], [15] или количества посетителей новостей [16]. Полный обзор литературы см. В [17].
Полный обзор литературы см. В [17].
Статистический анализ рынков кинофильмов привел к любопытным результатам, таким как наблюдение доказательств закона Парето для дохода от фильмов [18], [19] наряду с логнормальным распределением валового дохода на кинотеатр и бимодальным распределением количество кинотеатров, в которых показывают фильм [20]. Анализируя исторические данные о 70-летнем существовании американского кинорынка, Сринивасан утверждал, что фильмы с более высоким уровнем новизны (присвоенным на основе ключевых слов из базы данных Internet Movie Database) приносят больший доход [21].Несмотря на большие усилия, предпринимаемые с использованием различных подходов, прогнозирование финансового успеха фильма остается сложной открытой проблемой. Например, Шарда и Делен обучили нейронную сеть обрабатывать предварительные данные, такие как переменные качества и популярности, и классифицировать фильмы по девяти категориям в соответствии с их ожидаемым доходом, от «провала» до «блокбастера». Для тестовых выборок нейронная сеть правильно классифицирует только 36,9% фильмов, в то время как 75,2% фильмов находятся не более чем в одной категории от правильных [22].Джоши и др. построили многомерную модель линейной регрессии, которая объединила метаданные с текстовыми функциями из предварительных критических обзоров, чтобы предсказать доход с коэффициентом детерминации [23]. Поскольку прогнозы, основанные на классических факторах качества, не могут достичь уровня точности, достаточно высокого для практического применения, использование пользовательских данных для прогнозирования успеха фильма становится очень заманчивым подходом. Ishii et al. представляют собой математическую основу для распространения популярности в обществе [24].Их модель, которая принимает рекламный бюджет в качестве входного параметра и генерирует динамическую переменную популярности, проверяется по количеству сообщений в блогах о конкретных фильмах в японской блогосфере. Другими словами, они рассматривают уровень активности блогеров как репрезентативный параметр социальной популярности.
Для тестовых выборок нейронная сеть правильно классифицирует только 36,9% фильмов, в то время как 75,2% фильмов находятся не более чем в одной категории от правильных [22].Джоши и др. построили многомерную модель линейной регрессии, которая объединила метаданные с текстовыми функциями из предварительных критических обзоров, чтобы предсказать доход с коэффициентом детерминации [23]. Поскольку прогнозы, основанные на классических факторах качества, не могут достичь уровня точности, достаточно высокого для практического применения, использование пользовательских данных для прогнозирования успеха фильма становится очень заманчивым подходом. Ishii et al. представляют собой математическую основу для распространения популярности в обществе [24].Их модель, которая принимает рекламный бюджет в качестве входного параметра и генерирует динамическую переменную популярности, проверяется по количеству сообщений в блогах о конкретных фильмах в японской блогосфере. Другими словами, они рассматривают уровень активности блогеров как репрезентативный параметр социальной популярности. В более ранней работе [25] количественная модель, основанная на механизме распространения «молвы», была представлена для оценки качества фильмов на основе «агрегированных данных о потреблении».Однако, анализируя настроения в блогах о фильмах, Мишне и Глэнсс подчеркивают, что корреляция между настроениями перед выпуском и продажами не находится на адекватном уровне для построения прогнозной модели [26]. В очень интересном подходе Асур и Хуберман создали систему прогнозирования доходов от фильмов на основе количества упоминаний в Twitter [27]. Они достигают скорректированного коэффициента детерминации 0,97 в ночь перед выпуском фильма для выручки за первые выходные из 24 фильмов.Однако в более поздней работе Wong et al. показывают, что твиты не обязательно отражают финансовый успех фильмов [28]. Они рассматривают выборку из 34 фильмов и сравнивают твиты о фильмах с оценками, написанными пользователями веб-сайтов с обзорами фильмов. Они утверждают, что прогнозы, основанные на социальных сетях, могут иметь высокую точность, но низкую отзывчивость.
В более ранней работе [25] количественная модель, основанная на механизме распространения «молвы», была представлена для оценки качества фильмов на основе «агрегированных данных о потреблении».Однако, анализируя настроения в блогах о фильмах, Мишне и Глэнсс подчеркивают, что корреляция между настроениями перед выпуском и продажами не находится на адекватном уровне для построения прогнозной модели [26]. В очень интересном подходе Асур и Хуберман создали систему прогнозирования доходов от фильмов на основе количества упоминаний в Twitter [27]. Они достигают скорректированного коэффициента детерминации 0,97 в ночь перед выпуском фильма для выручки за первые выходные из 24 фильмов.Однако в более поздней работе Wong et al. показывают, что твиты не обязательно отражают финансовый успех фильмов [28]. Они рассматривают выборку из 34 фильмов и сравнивают твиты о фильмах с оценками, написанными пользователями веб-сайтов с обзорами фильмов. Они утверждают, что прогнозы, основанные на социальных сетях, могут иметь высокую точность, но низкую отзывчивость.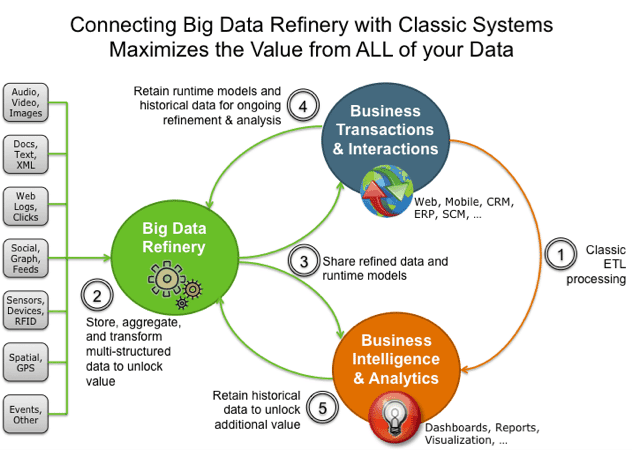 Юн и Глор показали, что центральная роль фильма в сетевом представлении его присутствия в сети коррелирует с его финансовым успехом [29].Используя довольно новый подход, Oghina et al. использовали потоки активности Twitter и YouTube для прогнозирования оценок в базе данных Internet Movie Database (IMDb), которая является одной из самых популярных онлайн-баз данных фильмов [30].
Юн и Глор показали, что центральная роль фильма в сетевом представлении его присутствия в сети коррелирует с его финансовым успехом [29].Используя довольно новый подход, Oghina et al. использовали потоки активности Twitter и YouTube для прогнозирования оценок в базе данных Internet Movie Database (IMDb), которая является одной из самых популярных онлайн-баз данных фильмов [30].
Википедия, как преобладающий пример пользовательских медиа, интенсивно изучалась с разных точек зрения. Его размер и рост [31] — [33], тематический охват и известность статей [34] — [36], конфликты и редакционные войны между пользователями [37] — [41], редакционные шаблоны [42] и лингвистические особенности [43] ] являются лишь несколькими примерами исследовательских тем, связанных с Википедией.Нам известны два всеобъемлющих обзора [44], [45] и краткое практическое руководство по некоторым из самых последних исследований Википедии [46].
Хотя влияние внешних событий на деятельность редакторов Википедии [47], [48] и количество просмотров страниц [49], [50] были подробно изучены, использование Википедии как источника информации для обнаружения и прогнозирования События в реальном мире были ограничены работой Osborne et al. [51], в котором они использовали просмотры страниц Википедии для тонкой фильтрации результатов своего алгоритма для основанного на Twitter «обнаружения первой истории» и совсем недавней работы Georgescu et al., в котором правки Википедии представлены как генераторы «новостных лент и графиков для конкретных объектов» [52]. И, наконец, в интересной работе, опубликованной позже первой редакции текущей рукописи, Моат и др. сообщил о прогностической силе данных Википедии о финансовых колебаниях [53].
[51], в котором они использовали просмотры страниц Википедии для тонкой фильтрации результатов своего алгоритма для основанного на Twitter «обнаружения первой истории» и совсем недавней работы Georgescu et al., в котором правки Википедии представлены как генераторы «новостных лент и графиков для конкретных объектов» [52]. И, наконец, в интересной работе, опубликованной позже первой редакции текущей рукописи, Моат и др. сообщил о прогностической силе данных Википедии о финансовых колебаниях [53].
В данной работе мы учитываем как уровень активности редакторов, так и количество просмотров страниц читателями, чтобы оценить популярность фильма. Мы определяем различные прогнозирующие переменные и применяем модель линейной регрессии для прогнозирования кассовых сборов за первые выходные для набора из 312 фильмов, выпущенных в США в 2010 году.Наш анализ не только превосходит предыдущие работы благодаря гораздо большему количеству фильмов, которые мы исследовали, но и улучшает состояние дел, давая разумные прогнозы уже за месяц до даты выхода фильма. Наконец, наш статистический подход, свободный от анализа на основе какого-либо языка, например анализа настроений, можно легко обобщить на неанглоязычные кинорынки или даже на другие виды продукции.
Наконец, наш статистический подход, свободный от анализа на основе какого-либо языка, например анализа настроений, можно легко обобщить на неанглоязычные кинорынки или даже на другие виды продукции.
Результаты
По данным Box Office Mojo, в 2010 году в США было показано 535 фильмов (см. Раздел «Методы»).Мы смогли отследить соответствующую страницу в Википедии для 312 из них. Более пристальный взгляд на историю этих 312 статей показывает, что многие из них созданы намного раньше даты выхода фильма (рис. 1 (A)). Это позволяет нам заранее следить за популярностью фильма. Чтобы оценить популярность, мы использовали четыре показателя активности; : Количество просмотров страницы статьи,: Количество пользователей , количество редакторов, внесших вклад в статью,: Количество правок , сделанных редакторами-людьми над статьей, и: Совместная строгость (или просто строгость [54]) последовательности редактирования статьи.Чтобы иметь согласованные временные рамки, мы установили время выхода фильма как. Подробнее см. В разделе «Методы». Примеры ежедневного приращения количества просмотров и количества пользователей показаны на рисунке S1. Ежедневные приращения обеих переменных повышаются и снижаются в день выпуска аналогично наблюдениям Ishii et al. [24]. В дополнение к этому важным параметром для прогнозирования доходов от фильмов является количество кинотеатров , в которых демонстрируется фильм, который включен в наш набор параметров.Полный набор данных, включая финансовые данные, а также записи об активности в Википедии, доступен через набор данных S1. Чтобы получить общее представление о выборке, используйте гистограммы накопленных значений 4 параметров активности с момента первого редактирования статьи до 7 дней после выпуска, а также кассовые сборы за первые выходные и количество кинотеатров, показывающих фильм. изображены на рис. 1 (Б – Е). Ясно, что доходы в выборке имеют бимодальное распределение (рис. 1 (B)). Это согласуется с [20], где авторы сообщают, что распределение общего дохода выборки из 5 222 фильмов, выпущенных в период с 1999 по 2008 гг.
Подробнее см. В разделе «Методы». Примеры ежедневного приращения количества просмотров и количества пользователей показаны на рисунке S1. Ежедневные приращения обеих переменных повышаются и снижаются в день выпуска аналогично наблюдениям Ishii et al. [24]. В дополнение к этому важным параметром для прогнозирования доходов от фильмов является количество кинотеатров , в которых демонстрируется фильм, который включен в наш набор параметров.Полный набор данных, включая финансовые данные, а также записи об активности в Википедии, доступен через набор данных S1. Чтобы получить общее представление о выборке, используйте гистограммы накопленных значений 4 параметров активности с момента первого редактирования статьи до 7 дней после выпуска, а также кассовые сборы за первые выходные и количество кинотеатров, показывающих фильм. изображены на рис. 1 (Б – Е). Ясно, что доходы в выборке имеют бимодальное распределение (рис. 1 (B)). Это согласуется с [20], где авторы сообщают, что распределение общего дохода выборки из 5 222 фильмов, выпущенных в период с 1999 по 2008 гг. По кинотеатрам в США, демонстрирует бимодальный характер и было получено с помощью суперпозиции два логнормальных распределения.Это также показывает, что освещение в Википедии не ограничивается финансово успешными фильмами. Значительная активность в статьях в Википедии (рис. 1 (D – G)) указывает на богатство данных. Однако, прежде чем строить регрессионную модель, в первую очередь следует изучить корреляцию между параметрами активности и кассовыми сборами.
По кинотеатрам в США, демонстрирует бимодальный характер и было получено с помощью суперпозиции два логнормальных распределения.Это также показывает, что освещение в Википедии не ограничивается финансово успешными фильмами. Значительная активность в статьях в Википедии (рис. 1 (D – G)) указывает на богатство данных. Однако, прежде чем строить регрессионную модель, в первую очередь следует изучить корреляцию между параметрами активности и кассовыми сборами.
Коэффициент корреляции Пирсона между накопленным значением -й прогностической переменной с момента создания статьи до времени до выхода фильма и кассовым доходом рассчитывается как (1) с указанием среднего значения по всей выборке.Временные корреляции показаны на рис. 2. Для всех предикторов, основанных на активности, коэффициент корреляции постепенно увеличивается по мере приближения времени к дню выпуска, а примерно в день выпуска корреляция внезапно возрастает. Обратите внимание, что это показывает самую высокую корреляцию с доходом до выхода фильмов.
Рисунок 2. Временная эволюция корреляции Пирсона кассовых сборов с различными предикторами.
Сокращения,,, и обозначают количество просмотров , , количество пользователей , , строгость , , количество редакций , и количество кинотеатров , , соответственно.Время измеряется во времени фильма. Врезка : увеличенный фрагмент основной панели, показывающий корреляцию Пирсона в день выпуска. Пунктирная горизонтальная линия показывает соотношение для количества кинотеатров .
https://doi.org/10.1371/journal.pone.0071226.g002
Мы строим многомерную модель линейной регрессии для прогнозирования кассовых сборов. Общая форма модели регрессии во время до выпуска, основанная на наборе переменных-предикторов, имеет вид (2) где s — изменяющиеся во времени параметры модели линейной регрессии, является константой и представляет собой шумовой член.Мы наполняем модель различными комбинациями переменных-предикторов и характеризуем качество различных наборов, вычисляя коэффициент детерминации. Коэффициент детерминации рассчитывается с использованием 10-кратной перекрестной проверки (см. Раздел «Методы»). Временная эволюция показана для различных наборов предсказателей на рис. 3. В то время как модель, использующуюся в реальных рыночных прогнозах, можно рассматривать как эталон уровня техники, модель, основанная исключительно на данных, предсказывает примерно так же.Комбинации и оценка значительно выше контрольного показателя, что указывает на актуальность показателей активности для прогнозирования. Среди всех рассмотренных наборов (здесь не показаны) самый высокий коэффициент детерминации, который достигает 0,77 примерно за месяц до выхода фильма.
Коэффициент детерминации рассчитывается с использованием 10-кратной перекрестной проверки (см. Раздел «Методы»). Временная эволюция показана для различных наборов предсказателей на рис. 3. В то время как модель, использующуюся в реальных рыночных прогнозах, можно рассматривать как эталон уровня техники, модель, основанная исключительно на данных, предсказывает примерно так же.Комбинации и оценка значительно выше контрольного показателя, что указывает на актуальность показателей активности для прогнозирования. Среди всех рассмотренных наборов (здесь не показаны) самый высокий коэффициент детерминации, который достигает 0,77 примерно за месяц до выхода фильма.
Обсуждение
Результаты, представленные выше, ясно показывают, как простое использование данных, созданных пользователями, в социальной среде, такой как Википедия, может улучшить нашу способность предсказывать коллективную реакцию общества на культурный продукт.Хотя эти результаты могут иметь практическое применение в маркетинговых целях, особенно в сочетании с другими источниками информации, наша главная цель — продемонстрировать степень участия представителей общественности в платформах для совместной работы. Представленный подход можно легко обобщить на другие области, в которых анализ общественного мнения дает ценную информацию, например, финансовые решения, формирование политики и управление. Мы считаем, что Википедия и аналогичные платформы массового сотрудничества могут служить альтернативными ресурсами для потоков в социальных сетях с более высоким уровнем профессионализма и более глубоким вовлечением пользователей.Поскольку представленные здесь методы не зависят от языка среды, их можно легко распространить на другие языки и местные рынки.
Представленный подход можно легко обобщить на другие области, в которых анализ общественного мнения дает ценную информацию, например, финансовые решения, формирование политики и управление. Мы считаем, что Википедия и аналогичные платформы массового сотрудничества могут служить альтернативными ресурсами для потоков в социальных сетях с более высоким уровнем профессионализма и более глубоким вовлечением пользователей.Поскольку представленные здесь методы не зависят от языка среды, их можно легко распространить на другие языки и местные рынки.
Стоит упомянуть, что для поддержки нашей прогнозной модели мы попробовали несколько других показателей активности, которые потенциально могут быть прогнозными параметрами, например, промежуток времени между созданием статьи и временем выпуска и длиной статьи. Однако эти количества не показали значительной корреляции с кассовыми сборами и, следовательно, были исключены из модели.
Мы также сравниваем прогнозную модель, основанную на показателях активности в Википедии, с результатами модели на основе Twitter, представленной в исследовании Асура и Хубермана в 2010 году [27]. Асур и Хуберман используют выборку из 24 фильмов для обучения и тестирования своей модели. Таким же подходом мы обучаем и тестируем нашу модель, ориентируясь на тот же набор фильмов. В нашей модели Википедии срок действия достигается за несколько дней до выпуска, в то время как для модели Twitter. Однако результаты исследования Twitter ограничиваются ночью перед выпуском, в то время как анализ, представленный здесь, позволяет делать прогнозы с разумной точностью () уже за месяц до выпуска (см. Рис.4). Также следует иметь в виду, что модель Википедии не требует какого-либо сложного контент-анализа, а полагается только на статистические измерения уровня активности. Прогнозирующая сила модели на основе Википедии, несмотря на ее простоту по сравнению с Twitter, может быть объяснена тем фактом, что многие редакторы Википедии являются преданными последователями киноиндустрии, которые собирают информацию и редактируют связанные статьи значительно раньше даты выпуска. тогда как «массовое» производство твитов происходит только очень близко к моменту выпуска, в основном вызванным маркетинговыми кампаниями.
Асур и Хуберман используют выборку из 24 фильмов для обучения и тестирования своей модели. Таким же подходом мы обучаем и тестируем нашу модель, ориентируясь на тот же набор фильмов. В нашей модели Википедии срок действия достигается за несколько дней до выпуска, в то время как для модели Twitter. Однако результаты исследования Twitter ограничиваются ночью перед выпуском, в то время как анализ, представленный здесь, позволяет делать прогнозы с разумной точностью () уже за месяц до выпуска (см. Рис.4). Также следует иметь в виду, что модель Википедии не требует какого-либо сложного контент-анализа, а полагается только на статистические измерения уровня активности. Прогнозирующая сила модели на основе Википедии, несмотря на ее простоту по сравнению с Twitter, может быть объяснена тем фактом, что многие редакторы Википедии являются преданными последователями киноиндустрии, которые собирают информацию и редактируют связанные статьи значительно раньше даты выпуска. тогда как «массовое» производство твитов происходит только очень близко к моменту выпуска, в основном вызванным маркетинговыми кампаниями.
Рисунок 4. Сравнение результатов с прогнозом на основе Twitter в работе Асура и Хубермана [27].
Одна и та же выборка из 24 фильмов рассматривается как обучающая и тестовая. Коэффициент детерминации, полученный с помощью метода на основе Twitter, составляет 0,98 в ночь выпуска (день 0 по времени фильма).
https://doi.org/10.1371/journal.pone.0071226.g004
Рис. 5 показывает фактический доход фильмов в выборке по сравнению с прогнозируемым доходом в днях.Очевидно, что для более удачных фильмов прогноз более точен. Когда рассматриваются менее удачные фильмы, отклонения от диагональной линии, обозначающей идеальный прогноз, увеличиваются. Вот некоторые примеры фильмов, кассовые сборы которых были точно предсказаны: Железный человек 2 , Алиса в стране чудес , История игрушек 3 , Начало , Битва титанов и Остров Шаттла . Однако модель не смогла дать точных прогнозов для менее успешных фильмов, например. г., Never Let Me Go , Царство животных , Девушка в поезде , Убийца внутри меня и Лотерея . Это систематическое различие в точности можно объяснить количеством данных, доступных для каждого класса фильмов. Очевидно, что модель работает более точно, когда фильм более популярен и объем связанных данных больше. Рассматривая зеленые квадраты, которые представляют фильмы в выборке, предсказанной моделью Twitter, можно понять, что большинство фильмов, предсказанных методом Twitter, относятся к числу успешных, поэтому применимость модели Twitter к фильмам со средним и низким уровнем популярности остается открытым вопросом.
г., Never Let Me Go , Царство животных , Девушка в поезде , Убийца внутри меня и Лотерея . Это систематическое различие в точности можно объяснить количеством данных, доступных для каждого класса фильмов. Очевидно, что модель работает более точно, когда фильм более популярен и объем связанных данных больше. Рассматривая зеленые квадраты, которые представляют фильмы в выборке, предсказанной моделью Twitter, можно понять, что большинство фильмов, предсказанных методом Twitter, относятся к числу успешных, поэтому применимость модели Twitter к фильмам со средним и низким уровнем популярности остается открытым вопросом.
Рисунок 5. Доходы от кассовых сборов за первые выходные в США по сравнению с прогнозируемым значением по модели Википедии в днях.
Зеленые точки представляют меньшую выборку из 24 фильмов, часто используемых в исследованиях Twitter и Википедии, а черные точки — это фильмы из выборки из 312 фильмов 2010 года. Обратите внимание, что отрицательные прогнозируемые доходы для некоторых из очень непопулярных фильмов не могут быть показаны в логарифмической шкале.
https://doi.org/10.1371/journal.pone.0071226.g005
Хотя мы пытались сохранить нашу модель как можно более простой и основанной только на нескольких переменных, можно было бы повысить эффективность прогнозирования, применив более сложные статистические методы, такие как нейронные сети, для более подробных параметров, связанных с контентом; e.г., мера противоречия статьи [38].
Методы
В этом исследовании мы рассматриваем выборку из 312 фильмов, которые были выпущены в США в 2010 году. Полный набор данных, включая финансовые данные, а также записи о деятельности Википедии, доступен через набор данных S1. Чтобы получить этот набор данных, сначала из Box Office Mojo (http://boxofficemojo.com) берется список фильмов 2010 года, распространяемых в США, вместе с соответствующими финансовыми данными (535 фильмов). Финансовые данные включают кассовые сборы за первые выходные и количество кинотеатров, показывающих фильм.
Чтобы найти соответствующие статьи в Википедии, мы используем систему категорий Википедии. Статьи Википедии делятся пользователями на одну или несколько категорий. Мы сопоставляем названия фильмов в базе данных Mojo с названиями страниц Википедии в категориях фильмов 2009 года и фильмов 2010 года. Включение категории фильмов 2009 года необходимо из-за фильмов, которые были выпущены в 2010 году в США, но которые могли уже выйти на международный рынок в течение 2009 года и, следовательно, были отнесены к категории фильмов 2009 года в Википедии.Чтобы добиться наилучшего совпадения названий, в них были убраны знаки препинания и постфиксы. Википедия использует последнее для сохранения уникальности каждого названия, например, в случае с Аватаром (фильм 2009 г.) и Аватаром (вычисления). В результате описанного выше процесса сопоставления была получена выборка, состоящая из финансовых данных и соответствующей страницы Википедии для 312 фильмов.
Статьи Википедии делятся пользователями на одну или несколько категорий. Мы сопоставляем названия фильмов в базе данных Mojo с названиями страниц Википедии в категориях фильмов 2009 года и фильмов 2010 года. Включение категории фильмов 2009 года необходимо из-за фильмов, которые были выпущены в 2010 году в США, но которые могли уже выйти на международный рынок в течение 2009 года и, следовательно, были отнесены к категории фильмов 2009 года в Википедии.Чтобы добиться наилучшего совпадения названий, в них были убраны знаки препинания и постфиксы. Википедия использует последнее для сохранения уникальности каждого названия, например, в случае с Аватаром (фильм 2009 г.) и Аватаром (вычисления). В результате описанного выше процесса сопоставления была получена выборка, состоящая из финансовых данных и соответствующей страницы Википедии для 312 фильмов.
Для удобства мы вводим времени фильма , общую координату времени для фильмов в рамках нашего исследования.По определению, время фильма измеряется с момента его выхода в США. Все временные переменные измеряются во времени фильма. На протяжении всего исследования мы рассматриваем накопленные значения параметров с момента создания статьи до времени прогнозирования для каждого показателя активности. Четыре показателя активности определены следующим образом:
Все временные переменные измеряются во времени фильма. На протяжении всего исследования мы рассматриваем накопленные значения параметров с момента создания статьи до времени прогнозирования для каждого показателя активности. Четыре показателя активности определены следующим образом:
Количество пользователей ,: количество различных пользователей-людей, которые внесли вклад в страницу.
Кол-во правок ,: количество изменений, внесенных пользователями-людьми в статью.
Совместная строгость ,: аналогично количеству правок; однако он считает несколько последующих правок одним и тем же пользователем за одно редактирование [54]. Это позволяет избежать подсчета нескольких правок, сделанных одним и тем же пользователем за короткий период, например, для исправления ошибок в их предыдущем вкладе.
Схематическая иллюстрация этих показателей активности представлена на рис. 6. Эти три переменные вычисляются с использованием баз данных истории страниц Wikimedia Toolserver (http: //toolserver. wikimedia.org), которые регистрируют информацию обо всех изменениях, внесенных на страницы Википедии. Чтобы гарантировать, что указанные выше переменные учитывают исключительно человеческую деятельность, вклад ботов исключен из расчетов. Боты — это автоматизированные скрипты, которые облегчают автоматические задачи, такие как проверка орфографии. Вклады, сделанные ботами, регистрируются так же, как и изменения, сделанные людьми; однако их можно отличить от человеческой деятельности, отметив специальную запись в базе данных Wikimedia Toolserver, которая называется флагом бота .
wikimedia.org), которые регистрируют информацию обо всех изменениях, внесенных на страницы Википедии. Чтобы гарантировать, что указанные выше переменные учитывают исключительно человеческую деятельность, вклад ботов исключен из расчетов. Боты — это автоматизированные скрипты, которые облегчают автоматические задачи, такие как проверка орфографии. Вклады, сделанные ботами, регистрируются так же, как и изменения, сделанные людьми; однако их можно отличить от человеческой деятельности, отметив специальную запись в базе данных Wikimedia Toolserver, которая называется флагом бота .
Рисунок 6. Иллюстрация различных переменных, характеризующих активность редакторов Википедии над статьей.
Каждая отметка на оси означает изменение страницы. Различные стили галочки относятся к разным пользователям.
https://doi.org/10.1371/journal.pone.0071226.g006
Количество просмотров ,: количество просмотров данной страницы с момента ее создания до настоящего времени. Эти данные извлекаются из раздела статистики просмотров страниц сайта Wikimedia Downloads (http: // dumps.wikimedia.org/other/pagecounts-raw) через веб-интерфейс «Статистика трафика статей Википедии» (http://stats.grok.se). Wikimedia Downloads считает просмотры только с декабря 2007 г., а данные о количестве просмотров за июль 2008 г. повреждены. Поэтому подсчитать точное общее количество просмотров до момента прогноза для всех рассматриваемых страниц невозможно. Мы подсчитали количество обращений к странице за несколько дней до релиза, что, согласно рис. 1 (A), является достаточно ранним. Еще одна проблема возникает из-за переименования статей, при котором количество посещений страницы разбивается на подмножества в соответствии с различными заголовками, которыми страница обладает на протяжении всей ее истории.Чтобы справиться с этой проблемой, мы проследили журналы «перемещений заголовков» в истории статей, чтобы отследить и объединить все обращения страницы. Обратите внимание, что в наборе данных есть записи о запросах страниц Википедии для несуществующих страниц, что дает нам индикатор общественного интереса к фильму еще до создания его статьи в Википедии, и поэтому мы не исключили такие записи из данные.
Эти данные извлекаются из раздела статистики просмотров страниц сайта Wikimedia Downloads (http: // dumps.wikimedia.org/other/pagecounts-raw) через веб-интерфейс «Статистика трафика статей Википедии» (http://stats.grok.se). Wikimedia Downloads считает просмотры только с декабря 2007 г., а данные о количестве просмотров за июль 2008 г. повреждены. Поэтому подсчитать точное общее количество просмотров до момента прогноза для всех рассматриваемых страниц невозможно. Мы подсчитали количество обращений к странице за несколько дней до релиза, что, согласно рис. 1 (A), является достаточно ранним. Еще одна проблема возникает из-за переименования статей, при котором количество посещений страницы разбивается на подмножества в соответствии с различными заголовками, которыми страница обладает на протяжении всей ее истории.Чтобы справиться с этой проблемой, мы проследили журналы «перемещений заголовков» в истории статей, чтобы отследить и объединить все обращения страницы. Обратите внимание, что в наборе данных есть записи о запросах страниц Википедии для несуществующих страниц, что дает нам индикатор общественного интереса к фильму еще до создания его статьи в Википедии, и поэтому мы не исключили такие записи из данные.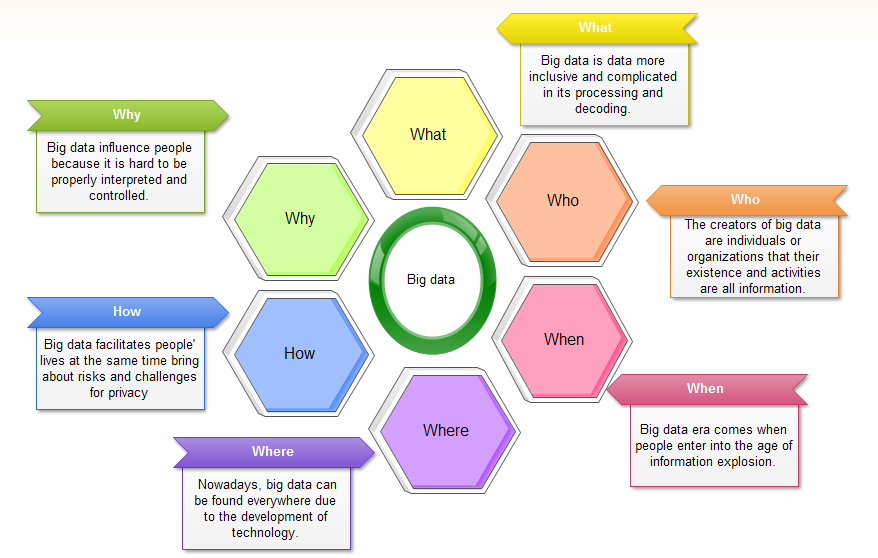 Количество кинотеатров : количество кинотеатров, в которых показывают фильм в первые выходные после его выхода.
Количество кинотеатров : количество кинотеатров, в которых показывают фильм в первые выходные после его выхода.
Для расчета коэффициента детерминации мы проводим 10-кратную перекрестную проверку, сначала случайным образом разделив нашу выборку фильмов 2010 года на 10 подмножеств. На следующем этапе модель обучается объединению 9 подмножеств и тестируется на оставшемся 10-м подмножестве. Это повторяется для всех 10 перестановок подмножеств, и коэффициент детерминации для модели получается как среднее значение по перестановкам.
Благодарности
Мы благодарим Wikimedia Deutschland e.V. за предоставление доступа к своим базам данных на Wikimedia Toolserver и IMDb, Inc. за доступ к базе данных Box Office Mojo. Мы также благодарим анонимных рецензентов PLoS ONE за полезные комментарии.
Вклад авторов
Задумал и спроектировал эксперименты: TY JK. Проведенные эксперименты: ММ. Проанализированы данные: ММ. Написал статью: MM TY.
Ссылки
- 1.
Сакаки Т., Окадзаки М., Мацуо Ю. (2010) Землетрясение потрясает пользователей Twitter: обнаружение событий в реальном времени с помощью социальных датчиков.В кн .: Материалы 19-й международной конференции во всемирной паутине. Нью-Йорк, Нью-Йорк, США: ACM, WWW ’10, стр. 851–860. - 2.
Окадзаки М., Мацуо И. (2011) Семантический Twitter: анализ твитов для уведомления о событиях в реальном времени. В: Бреслин Дж, Бург Т., Ким Х.Г., Рафтери Т., Шмидт Дж. Х., редакторы, Последние тенденции и разработки в социальном программном обеспечении, Springer, том 6045 из Лекционные заметки по компьютерным наукам . С. 63–74. - 3.
Боллен Дж, Мао Х, Цзэн Х (2011). Настроение в Твиттере предсказывает фондовый рынок.Журнал вычислительной науки 2: 1–8. - 4.
Сааведра С., Дач Дж., Уззи Б. (2011) Отслеживание понимания трейдерами рынка с использованием данных электронной связи. PLoS ONE 6: e26705. - 5.
Тумасян А. , Спренгер Т.О., Сандер П.Г., Велпе И.М. (2010) Предсказание выборов с помощью Twitter: что 140 символов говорят о политических настроениях. В: Материалы четвертой Международной конференции AAAI по блогам и социальным сетям. С. 178–185. - 6.
Гайо-Авелло Д., Мелаксас П., Мустафарадж Э. (2011) Ограничения электоральных прогнозов с использованием Twitter.В: Материалы пятой международной конференции AAAI по блогам и социальным сетям. С. 490–493. - 7.
Gayo-Avello D (2012) «Я хотел прогнозировать выборы с помощью Twitter, и все, что я получил, это паршивая газета» — сбалансированный опрос о прогнозировании выборов с использованием данных Twitter. припринт; arXiv: 12046441. - 8.
Brody T, Harnad S, Carr L (2006) Более ранняя статистика использования Интернета как предикторы последующего воздействия цитирования. Журнал Американского общества информационных наук и технологий 57: 1060–1072. - 9.
Eysenbach G (2011) Могут ли твиты предсказывать цитирование? показатели социального воздействия на основе Twitter и корреляция с традиционными показателями научного воздействия. J Med Internet Res 13: e123. - 10.
Шуай X, Пепе А., Боллен Дж. (2012) Как научное сообщество реагирует на недавно представленные препринты: загрузка статей, упоминания в Twitter и цитирование. PLoS ONE 7: e47523. - 11.
Прейс Т., Райт Д., Стэнли Х.Э. (2010) Сложная динамика нашей экономической жизни в разных масштабах: выводы из данных запросов поисковых систем.Философские труды Королевского общества A 368: 5707–5719. - 12.
Прейс Т., Моат Х.С., Стэнли Х.Э., епископ С.Р. (2012) Количественная оценка преимущества ожидания. Sci Rep 2: 350 - 13.
Гинзберг Дж., Мохебби М.Х., Патель Р.С., Браммер Л., Смолинский М.С. и др. (2009) Выявление эпидемий инуензы с использованием данных запросов поисковых систем. Природа 457: 1012–1014. - 14.
Цагкиас Э., де Рийке М., Веркамп В. (2009) Прогнозирование количества комментариев к новостным сообщениям в Интернете.В: 18-я конференция ACM по управлению информацией и знаниями (CIKM 2009). ACM, Гонконг: ACM, стр. 1765–1768. - 15.
Tsagkias E, Weerkamp W, de Rijke M (2010) Комментарии к новостям: изучение, моделирование и онлайн-прогнозирование. В: 32-я Европейская конференция по поиску информации (ECIR 2010). Springer, Springer, стр. 109–203. - 16.
Castillo C, El-Haddad M, Pfeffer J, Stempeck M (2013) Характеристика жизненного цикла новостных онлайн-историй с использованием реакций в социальных сетях.припринт; arXiv 13043010. - 17.
Цагкиас М. (2012) Социальные сети майнинга: отслеживание контента и прогнозирование поведения. Кандидат наук. дипломная работа, Амстердамский университет. - 18.
Sinha S, Raghavendra S (2004) Голливудские блокбастеры и длиннохвостые распределения: эмпирическое исследование популярности фильмов. Eur Phys J B 42: 293–296. - 19.
Sinha S, Pan RK (2005) Блокбастеры, бомбы и спящие: распределение доходов от фильмов. В: Chatterjee A, Yarlagadda S, Chakrabarti BK, редакторы, Econophysics of Wealth Distribution, Springer Milan, New Economic Windows. С. 43–47. - 20.
Пан Р.К., Синха С. (2010) Статистические законы популярности: универсальные свойства динамики боксов кинофильмов. Новый журнал физики 12: 115004. - 21.
Sreenivasan S (2013) Количественный анализ эволюции новизны в кино с помощью краудсорсинговых ключевых слов. припринт; arXiv 13040786. - 22.
Шарда Р., Делен Д. (2006) Прогнозирование успеха кинофильмов с помощью нейронных сетей. Экспертные системы с приложениями 30: 243–254. - 23.
Джоши М., Дас Д., Гимпель К., Смит Н. (2010) Обзоры фильмов и доходы: эксперимент в регрессии текста. В: Proceedings of NAACL-HLT 2010, Short Papers Track. - 24.
Исии А., Аракаки Х., Мацуда Н., Умемура С., Урушидани Т. и др. (2012) Феномен «удара»: математическая модель взаимодействия динамики человека как случайного процесса. Новый журнал физики 14: 063018. - 25.
Идальго К.А., Кастро А., Родригес-Сикерт С. (2006) Эффект социальных взаимодействий в жизненном цикле первичного потребления кинофильмов. Новый журнал физики 8: 52 - 26.
Mishne G, Glance N (2006) Прогнозирование продаж фильмов на основе настроений Blogger. В: Материалы весеннего симпозиума AAAI 2006 г. по вычислительным подходам к анализу веб-журналов (AAAI-CAAW). С. 155–158. - 27.
Асур С., Хуберман Б.А. (2010) Предсказание будущего с помощью социальных сетей. В: Материалы Международной конференции IEEE / WIC / ACM 2010 года по веб-аналитике и технологии интеллектуальных агентов. С. 492–499. - 28.Вонг FMF, Сен С., Чианг М. (2012) Почему просмотр фильмов в Твиттере не расскажет всей истории? В: Материалы семинара ACM 2012 г., посвященного семинарам в социальных сетях. Нью-Йорк, штат Нью-Йорк, США: ACM, WOSN ’12, стр. 61–66.
- 29.
Yun Q, Gloor PA (2012) Интернет отражает ценность в реальном мире, сравнивая оценку фирмы с ее положением в сети. MIT Sloan Research Paper No 4973-12 Доступен в SSRN: http: // ssrncom / abstract = 2157278, по состоянию на 7 июля 2013 г. - 30.Огина А., Брейс М., Цагкиас Э., де Рийке М. (2012) Прогнозирование рейтингов фильмов IMDB с помощью социальных сетей. В: ECIR 2012: 34-я Европейская конференция по поиску информации. Springer-Verlag, Барселона, Испания: Springer-Verlag, стр. 503–507.
- 31.
Восс Дж. (2005) Измерение Википедии. В: Международная конференция Международного общества наукометрии и информетрики: 10-е, Стокгольм (Швеция), 24–28 июля 2005 г. - 32.
Алмейда РБ, Мозафари Б., Чо Дж. (2007) Об эволюции Википедии.В: Материалы Международной конференции по блогам и социальным сетям. ICWSM’07. - 33.
Сух Б., Конвертино Г., Чи Э., Пиролли П. (2009). Сингулярность не рядом: замедление роста Википедии. В: Материалы 5-го Международного симпозиума по вики-сайтам и открытому сотрудничеству, Нью-Йорк, Нью-Йорк, США: ACM, WikiSym ’09, стр. 8. 1–8: 10. - 34.
Холлоуэй Т., Божичевич М., Бёрнер К. (2007) Анализ и визуализация смыслового освещения Википедии и ее авторов. Сложность 12: 30–40. - 35.
Halavais A, Lackaff D (2008) Анализ тематического освещения Википедии. Журнал компьютерных коммуникаций 13: 429–440. - 36.
Тараборелли Д., Чампалья Г. (2010) За гранью известности. коллективное обсуждение включения контента в Википедию. В: Семинар по самоадаптирующимся и самоорганизующимся системам (SASOW), Четвертая международная конференция IEEE 2010 г. С. 122–125. - 37.
Sumi R, Yasseri T, Rung A, Kornai A, Kertész J (2011) Характеристика и предсказание войн редактирования Википедии.В: Труды ACM WebSci’11, Кобленц, Германия. С. 1–3. - 38.
Sumi R, Yasseri T, Rung A, Kornai A, Kertész J (2011) Редактировать войны в Википедии. В: Конфиденциальность, безопасность, риски и доверие (PASSAT), Третья международная конференция IEEE 2011 г. и Третья международная конференция IEEE 2011 г. по социальным вычислениям (SocialCom). С. 724–727. - 39.
Яссери Т., Суми Р., Рунг А. , Корнаи А., Кертес Дж. (2012) Динамика конфликтов в Википедии. PloS ONE 7: e38869. - 40.Яссери Т., Спёрри А., Грэм М., Кертес Дж. (2014) Наиболее противоречивые темы в Википедии: многоязычный и географический анализ. В: Фичман П., Хара Н., редакторы, Global Wikipedia: Международные и межкультурные проблемы в онлайн-сотрудничестве. Scarecrow Press.
- 41.
Торок Дж., Иньигес Дж., Яссери Т., Сан-Мигель М., Каски К. и др. (2013) Мнения, разногласия и консенсус: моделирование социальной динамики в среде сотрудничества. Phys Rev Lett 110: 088701. - 42.Яссери Т., Суми Р., Кертес Дж. (2012) Циркадные модели редакционной деятельности Википедии: демографический анализ. PLoS ONE 7: e30091.
- 43.
Яссери Т., Корнаи А., Кертес Дж. (2012) Практический подход к сложности языка: тематическое исследование из Википедии. PLoS ONE 7: e48386. - 44.
Нильсен Ф.А. (2011). Исследования и инструменты Википедии: обзор и комментарии. Доступно по адресу: http://www2. imm.dtu.dk/pubdb/views/edoc_download.php/6012/pdf/imm6012.pdf, по состоянию на 7 июля 2013 г. - 45.
Жюльен Н (2012). Что мы знаем о Википедии: обзор литературы, анализирующей проект (ы). Доступно на SSRN: http://ssrn.com/abstract=2053597, дата обращения 7 июля 2013 г. - 46.
Яссери Т., Кертес Дж. (2013) Создание ценности в совместной среде. Журнал статистической физики 151: 414–439. - 47.
Киган Б., Гергл Д., Подрядчик Н.С. (2011) Горячий выход из вики: динамика, практики и структуры в Википедии, посвященной катастрофам тохоку.В: Int Sym Wikis. С. 105–113. - 48.
Раткевич Дж., Фортунато С., Фламмини А., Менцер Ф., Веспиньяни А. (2010) Характеристика и моделирование динамики онлайн-популярности. Phys Rev Lett 105: 158701. - 49.
Spoerri A (2007) Что популярно в Википедии и почему? Первый понедельник 12:4. - 50.
Spoerri A (2007) Визуализация перекрытия между 100 наиболее посещаемыми страницами Википедии с сентября 2006 года по январь 2007 года. Первый понедельник 12: 4. - 51.
Osborne M, Petrović S, McCreadie R, Macdonald C, Ounis I (2012) Бибер, больше нет: обнаружение первой истории с использованием Twitter и Wikipedia. В: Материалы семинара по доступу к информации с учетом времени. TAIA’12. - 52.
Георгеску М., Канхабуа Н., Краузе Д., Нейдл В., Сирсдорфер С. (2013) Извлечение информации о событиях из обновлений статей в Википедии. В: Сердюков П., Браславский П., Кузнецов О Сергей, Кампс Дж., Рюгер С. и др., Редакторы, Достижения в области информационного поиска, Springer Berlin Heidelberg, том 7814 из Lecture Notes in Computer Science .С. 254–266. - 53.
Moat HS, Curme C, Avakian A, Kenett DY, Stanley HE, et al. (2013) Количественная оценка моделей использования Википедии до движения фондового рынка. Sci Rep 3: 1801. - 54.
Киммонс Р. (2011) Понимание сотрудничества в Википедии. Первый понедельник 16:12.

 , Спренгер Т.О., Сандер П.Г., Велпе И.М. (2010) Предсказание выборов с помощью Twitter: что 140 символов говорят о политических настроениях. В: Материалы четвертой Международной конференции AAAI по блогам и социальным сетям. С. 178–185.
, Спренгер Т.О., Сандер П.Г., Велпе И.М. (2010) Предсказание выборов с помощью Twitter: что 140 символов говорят о политических настроениях. В: Материалы четвертой Международной конференции AAAI по блогам и социальным сетям. С. 178–185. J Med Internet Res 13: e123.
J Med Internet Res 13: e123. ACM, Гонконг: ACM, стр. 1765–1768.
ACM, Гонконг: ACM, стр. 1765–1768. С. 43–47.
С. 43–47. Новый журнал физики 8: 52
Новый журнал физики 8: 52
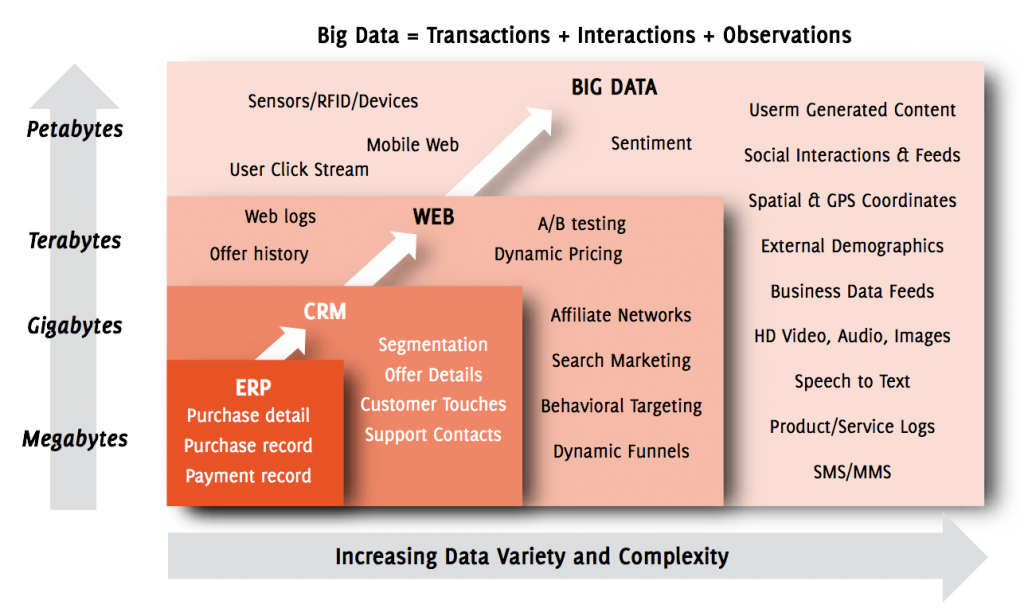 Сложность 12: 30–40.
Сложность 12: 30–40.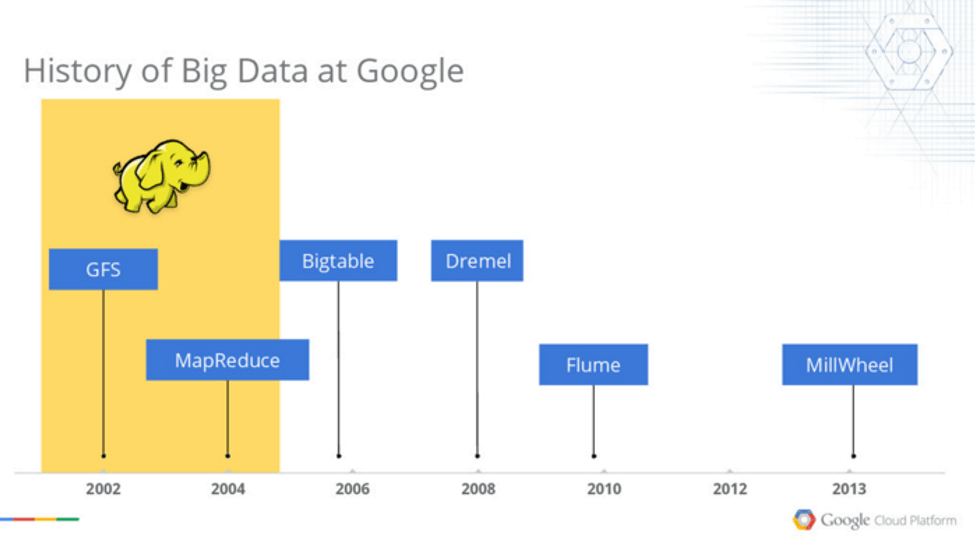 , Корнаи А., Кертес Дж. (2012) Динамика конфликтов в Википедии. PloS ONE 7: e38869.
, Корнаи А., Кертес Дж. (2012) Динамика конфликтов в Википедии. PloS ONE 7: e38869. imm.dtu.dk/pubdb/views/edoc_download.php/6012/pdf/imm6012.pdf, по состоянию на 7 июля 2013 г.
imm.dtu.dk/pubdb/views/edoc_download.php/6012/pdf/imm6012.pdf, по состоянию на 7 июля 2013 г. Первый понедельник 12: 4.
Первый понедельник 12: 4. .