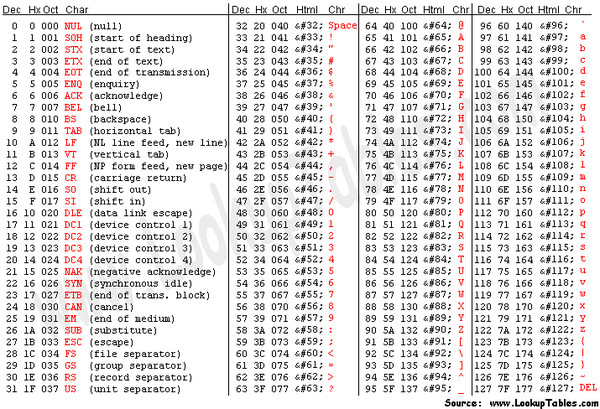
Дана кодировка unicode определите количество символов в сообщении если: дана кодировка unicode. определите количество символов в сообщении, если информационный объем
1) 1,
…
2, 3 — початковий рівень;
) 4, 5, 6 — середній рівень;
3) 7, 8, 9 — достатній рівень.
4) 10, 11, 12 — високий рівень
помогите, пожалуйста
100 баллов!!!!! Помогите
Помогите с заданием!
Вобщем, мой учитель знал то что я недавно начал интересоватся вирусологией, он мне дал заданние что-бы я удалил кое-какой вирус и
…
дал мне ноут на котором он запустил свой-же вирус который он сделал на делфи, суть вируса такова, он постоянно показывает рекламные баннеры и открывает разные странные сайты, и каждый раз когда я пробую удалить его через панель управления то у меня открывается редактор реестра который прекращает удаление вируса.
Формальный исполнитель Черепашка умеет перемещаться по экрану, оставляя за собой след в виде линии, и знает несколько команд:
Вперёд n (где n — целое
…
число) — вызывает передвижение Черепашки на n шагов в направлении движения — в том направлении, куда развёрнуты её голова и корпус.
Направо m (где m — целое число) — вызывает изменение направления движения Черепашки на m градусов по часовой стрелке.
Повтори k [<Команда1> <Команда2> … <Командаn>] — повторяет последовательность команд в скобках k раз.
Определи, какая фигура появится на экране после выполнения Черепашкой следующего алгоритма:
Повтори 6 [Вперёд 5 Направо 120].
дана кодировка unicode. определите количество символов в сообщении,если информационный объем
Срочно!! Помогите, пожалуйста!!
Имеется рюкзак грузоподъемностью P и N предметов. Сi — стоимость предмета, Pi — его вес. Требуется запихать в рюкзак как можно большую стоимость. p,n&
…
lt;=60
Нужен полный алгоритм на с++ или Pascal.
ПОМОГИТЕ Определить, есть ли в последовательности из n целых случайных чисел от 1 до 100, число, равное k. Если есть, вывести на экран номер, под кото
…
рым оно встречается впервые, а если нет – вывести слово «Нет».
Определить, есть ли в последовательности из n целых случайных чисел от 1 до 100, число, равное k. Если есть, вывести на экран номер, под которым оно в
…
стречается впервые, а если нет – вывести слово «Нет». помогите!!
помогите!!
sin2ß — tgß – cos2ß tgß срочноооооо
ДАЮ 25 БАЛЛОВ ЗА РЕШЕНИЕ ЗАДАЧИ НА ЯЗЫКЕ С++!!!!!!!!!!!
Дан массив a из n целых чисел. Требуется вывести второй, четвертый и т.д., т.е. элементы, стоя
…
щие под четными номерами.
Формат входных данных
На первой строке входного файла записано натуральное число n (n≤100) — число элементов в массиве.
На следующей строке через пробел записаны целые числа ai (∣∣ai∣∣≤103) — элементы массива.
Формат выходных данных
Требуется в одной строке через пробел вывести все числа, стоящие на четных местах.
входные данные
4
100 20 4 318
10
42 7 59 7 212 47 777 66 89 6
выходные данные
20 318
7 7 47 66 6
РЕШИТЕ ЗАДАЧУ НА С++ ДАЮ 20 БАЛЛОВ!!!!!!!
Дан массив a из n натуральных чисел. Требуется вывести все элементы массива, являющиеся двузначными числами.
…
Формат входных данных
На первой строке входного файла записано натуральное число n (n≤100) — число элементов в массиве.
На следующей строке через пробел записаны натуральные числа ai (ai≤103) — элементы массива.
Формат выходных данных
Требуется в одной строке через пробел вывести все числа, являющиеся двузначными, в том же порядке, в каком они расположены во входном файле.
входные данные
4
100 20 4 318
10
42 7 59 7 212 47 777 66 89 6
выходные данные
20
42 59 47 66 89
ДАЮ 20 БАЛЛОВ ЗА РЕШЕНИЕ ЗАДАЧИ ПО С++!!!!!!!!!!!!
Дан массив a из n целых чисел. Требуется вывести только элементы, оканчивающиеся нулем.
Формат вход
…
ных данных
На первой строке входного файла записано натуральное число n (n≤100) — число элементов в массиве.
На следующей строке через пробел записаны целые числа ai (∣∣ai∣∣≤103) — элементы массива.
Формат выходных данных
Требуется в одной строке через пробел вывести все числа, оканчивающиеся нулем, в том же порядке, в каком они расположены во входном файле.
входные данные
4
100 -20 4 318
10
-42 70 59 76 21 47 77 66 89 60
выходные данные
100 -20
70 60
РЕШИТЕ ЗАДАЧУ НА ЯЗЫКЕ С++ ДАЮ 25 БАЛЛОВ!!!!!!!!
Дан массив a из n целых чисел. Требуется вывести только элементы с четными значениями.
Формат входных
…
данных
На первой строке входного файла записано натуральное число n (n≤100) — число элементов в массиве.
На следующей строке через пробел записаны целые числа ai (∣∣ai∣∣≤103) — элементы массива.
Формат выходных данных
Требуется в одной строке через пробел вывести все четные числа, в том же порядке, в каком они расположены во входном файле.
входные данные
4
100 -20 4 318
10
-42 70 59 76 21 47 77 66 89 60
выходные данные
100 -20 4 318
-42 70 76 66 60
РЕШИТЕ СРОЧНО ЗАДАЧИ ПО С++!!!!!!!!!!!
Дан массив a из n целых чисел. Требуется вывести только неотрицательные числа.
Формат входных данных
На первой
…
строке входного файла записано натуральное число n (n≤100) — число элементов в массиве.
На следующей строке через пробел записаны целые числа ai (∣∣ai∣∣≤103) — элементы массива.
Формат выходных данных
Требуется в одной строке через пробел вывести все неотрицательные числа в том же порядке, в каком они расположены во входном файле.
входные данные
3
5 -3 0
выходные данные
5 0
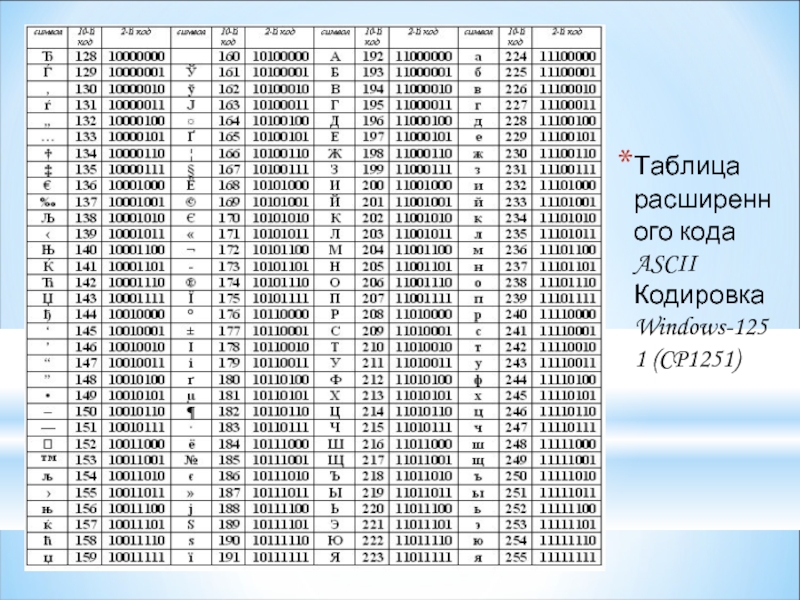
Информационный объём фрагмента текста (8 класс) Информатика и ИКТ
Вам известно, что информационный объём I сообщения равен произведению количества К символов в сообщении на информационный вес i символа алфавита: I =К • i.
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
- 8 битов (1 байт)- восьмиразрядная кодировка;
- 16 битов (2 байта) — шестнадцатиразрядная кодировка.
Информационным объёмом фрагмента текста будем называть количество битов, байтов или производных единиц (килобайтов, мегабайтов и т. д.), необходимых для записи этого фрагмента заранее оговорённым способом двоичного кодирования.
Задача 1.
Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Жан-Жака Руссо:
Тысячи путей ведут к заблуждению, к истине — только один.
Решение:
В данном тексте 57 символов (с учётом знаков препинания и пробелов). Каждый символ кодируется одним байтом. Следовательно, информационный объём всего текста — 57 байтов.
Ответ: 57 байтов.
Задача 2.
В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём слова из 24 символов в этой кодировке.
Определите информационный объём слова из 24 символов в этой кодировке.
Решение:
I = 24 • 2 = 48 (байтов).
Ответ: 48 байтов.
Задача 3.
Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 8-битовом коде, в 16-битовую кодировку Unicode. При этом информационное сообщение увеличилось на 2048 байтов. Каков был информационный объём сообщения до перекодировки?
Решение:
Информационный вес каждого символа в 16-битовой кодировке в два раза больше информационного веса символа в 8-битовой кодировке. Поэтому при перекодировании исходного блока информации из 8-битовой кодировки в 16-битовую его информационный объём должен был увеличиться вдвое, другими словами, на величину, равную исходному информационному объёму. Следовательно, информационный объём сообщения до перекодировки составлял 2048 байтов = 2 Кб.
Ответ: 2 Кб.
Задача 4.
Выразите в мегабайтах объём текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считайте, что при записи использовался алфавит мощностью 256 символов.
Считайте, что при записи использовался алфавит мощностью 256 символов.
Решение:
Информационный вес символа алфавита мощностью 256 равен восьми битам (одному байту). Количество символов во всём словаре равно 7 40 • 80 • 60 = 3 552 000. Следовательно, объём этого текста в байтах равен 3 552 000 байтов = 3 468,75 Кбайт ≈ 3,39 Мбайт.
Ответ: 3,39 Мбайт.
Самое главное:
- В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
- 8 битов (1 байт) — восьмиразрядная кодировка;
- 16 битов (2 байта) — шестнадцатиразрядная кодировка.
- Информационный объём фрагмента текста — это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования.
Вопросы и задания:
- Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Алексея Толстого:
Не ошибается тот, кто ничего не делает, хотя это и есть его основная ошибка.
1) 512 битов 2) 608 битов 3) 8 Кбайт 4) 123 байта
(Всего символов в высказывании — 76. Поскольку на один символ отводится 1 байт, то объем высказывания равен 76 (байт) = 608 (бит). Правильный ответ: 2) - Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующей фразы А. С. Пушкина в кодировке Unicode:
Привычка свыше нам дана: Замена счастию она.
1) 44 бита 2) 704 бита 3) 44 байта 4) 704 байта
(Всего символов во фразе — 44. Поскольку на один символ отводится 2 байта, то объем высказывания равен 88 (байт) = 704 (бит). Правильный ответ: 2) - В текстовом режиме экран монитора компьютера обычно разбивается на 25 строк по 80 символов в строке. Определите объём текста, занимающего весь экран монитора, в кодировке Unicode.
(Решение:
В кодировке Unicode каждый символ кодируется 2 байтами. На экран влезает 25 • 80 = 2000 символов. Соответственно, объем текста равен 2000 • 2 = 4000 (байт) ≈ 3,9 (Кбайт)
Ответ: 4000 байт) - Сообщение занимает 6 страниц по 40 строк, в каждой строке записано по 60 символов. Информационный объём всего сообщения равен 28 800 байтам. Сколько двоичных разрядов было использовано на кодирование одного символа?
(Решение:
Сообщение состоит из 6 • 40 • 20 = 14400 символов. Поскольку объем этого текста составляет 28800 байт, то на один символ отводилось 2 байта, т.е. 16-разрядный двоичный код. Текст записан в кодировке Unicode.
Ответ: 16 разрядов) - Сообщение, информационный объём которого равен 5 Кбайт, занимает 4 страницы по 32 строки, в каждой из которых записано по 40 символов. Сколько символов в алфавите языка, на котором записано это сообщение?
(Решение:
I = 5 Кбайт
K = 4 • 32 • 40
N = ?N = 2i; I = K • i
i = I/K, i = (5 • 210 • 23)/(22 • 25 • 23 • 5), i = 23 = 8
N = 28 = 256
Ответ: 256 символов в алфавите)

 Информационный объём всего сообщения равен 28 800 байтам. Сколько двоичных разрядов было использовано на кодирование одного символа?
Информационный объём всего сообщения равен 28 800 байтам. Сколько двоичных разрядов было использовано на кодирование одного символа?Содержание
Задачи по информатике — Информатика
Статья, набранная на компьютере, содержит 16 страниц, на каждой странице 30 строк, в каждой строке 32 символа. Определите информационный объём статьи в одной из кодировок Unicode, в которой каждый символ кодируется 16 битами.
Определите информационный объём статьи в одной из кодировок Unicode, в которой каждый символ кодируется 16 битами.
1) 24 Кбайт 2) 30 Кбайт 3) 480 байт 4) 240 байт
Решение:
Найдем общее количество символов на одной странице, для этого умножим количество строк на странице на количество символов в строке — 30 * 32 = 960 символов.
Найдем общее количество символов во всем тексте, для этого умножим количество страниц на количество символов на одной странице — 16 * 960 = 15360 символов.
Так как каждый символ кодируется 16 битами, а 16 бит = 2 байта, то весь текст займет 15360 * 2 байта = 30720 байта. Как видим, из предложенных вариантов ответа в байтах полученного нами нет, поэтому переведем полученный результат в килобайты. Для этого разделим 30720 на 1024: 30720 / 1024 = 30Кбайт.
Правильный ответ 2) 30Кбайт.
Статья, набранная на компьютере, содержит 8 страниц, на каждой странице 40 строк, в каждой строке 64 символа. В одном из представлений Unicode каждый символ кодируется 16 битами. Определите информационный объём статьи в этом варианте представления Unicode.
В одном из представлений Unicode каждый символ кодируется 16 битами. Определите информационный объём статьи в этом варианте представления Unicode.
1) 320 байт 2) 35 Кбайт 3) 640 байт 4) 40 Кбайт
Решение:
Аналогично предыдущей задаче найдем количество символов на одной странице — 40 * 64 = 2560.
Общее количество символов в статье — 2560 * 8 = 20480 символов.
Каждый символ кодируется 16 битами или 2 байтами (1 байт = 8 бит). Значит вся статья займет 20480 * 2 байта = 40960 байт.
Полученного результата в вариантах ответа нет, поэтому переведем полученное значение в килобайты, разделив его на 1024: 40960 / 1024 = 40Кбайт.
Правильный ответ 4) 40 Кбайт.
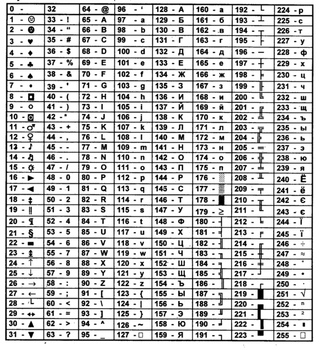
В кодировке КОИ-8 каждый символ кодируется одним байтом. Определите количество символов в сообщении, если информационный объем сообщения в этой кодировке равен 160 бит.
1) 10 2) 16 3) 20 4) 160
Решение:
Так как каждый символ кодируется одним байтом, а один байт равен 8 битам, то чтобы узнать количество символов, нужно разделить информационный объем сообщения на количество памяти, занимаемое одним символом:
160 / 8 = 20 символов.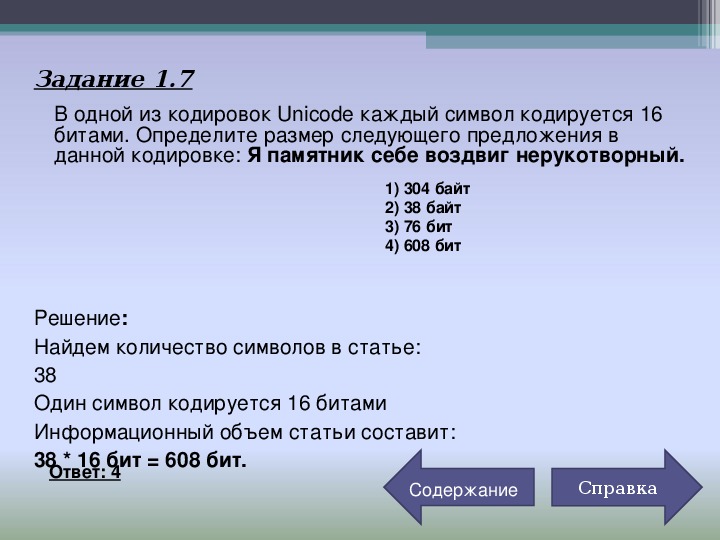
Правильный ответ 3) 20.
В одной из кодировок Unicode каждый символ кодируется 16 битами. Определите размер следующего предложения в данной кодировке.
Я к вам пишу – чего же боле? Что я могу ещё сказать?
1) 52 байт 2) 832 бит 3) 416 байт 4)104 бит
Решение:
Для начала посчитаем количество символов в предложении. Именно символов, не букв! То есть знак пробела, знак вопроса мы тоже считаем. В итоге у нас получается 52 символа. Из условия известно, что каждый символ кодируется 16 битами. Значит, чтобы найти информационный объем всего предложения, мы должны умножить 52 на 16.
52 * 16 = 832 бита.
Среди вариантов ответа есть найденный нами. Правильный ответ 2.
В одной из кодировок Unicode каждый символ кодируется 16 битами. Определите информационный объем следующего предложения в данной кодировке.
Я памятник себе воздвиг нерукотворный.
1) 76 бит 2) 608 бит 3) 38 байт 4) 544 бит
Принцип решения подобного класса задач остается прежним — посчитать количество символов и умножить полученное число на информационный объем одного символа. В условии сказано, что каждый символ кодируется 16 битам (рекомендую ознакомиться со статьей кодирование текста для понимания принципов хранения текста в памяти компьютера). Итак, считаем количество символов в строке. Напомню очередной раз, что пробелы, знаки препинания — это тоже символы и их тоже надо считать. В предложении 38 символов. Умножив 38 символов на 16 бит получим 608 бит. В предложенных вариантах такой встречается, значит правильный ответ — 2
В условии сказано, что каждый символ кодируется 16 битам (рекомендую ознакомиться со статьей кодирование текста для понимания принципов хранения текста в памяти компьютера). Итак, считаем количество символов в строке. Напомню очередной раз, что пробелы, знаки препинания — это тоже символы и их тоже надо считать. В предложении 38 символов. Умножив 38 символов на 16 бит получим 608 бит. В предложенных вариантах такой встречается, значит правильный ответ — 2
Задача 1.
Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Жан-Жака Руссо:
Тысячи путей ведут к заблуждению, к истине — только один.
Решение:
В данном тексте 57 символов (с учётом знаков препинания и пробелов). Каждый символ кодируется одним байтом. Следовательно, информационный объём всего текста — 57 байтов.
Ответ: 57 байтов.
Задача 2.
В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём слова из 24 символов в этой кодировке.
Решение:
I = 24 • 2 = 48 (байтов).
Ответ: 48 байтов.
Задача 3.
Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 8-битовом коде, в 16-битовую кодировку Unicode. При этом информационное сообщение увеличилось на 2048 байтов. Каков был информационный объём сообщения до перекодировки?
Решение:
Информационный вес каждого символа в 16-битовой кодировке в два раза больше информационного веса символа в 8-битовой кодировке. Поэтому при перекодировании исходного блока информации из 8-битовой кодировки в 16-битовую его информационный объём должен был увеличиться вдвое, другими словами, на величину, равную исходному информационному объёму. Следовательно, информационный объём сообщения до перекодировки составлял 2048 байтов = 2 Кб.
Ответ: 2 Кб.
Задача 4.
Выразите в мегабайтах объём текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считайте, что при записи использовался алфавит мощностью 256 символов.
Считайте, что при записи использовался алфавит мощностью 256 символов.
Решение:
Информационный вес символа алфавита мощностью 256 равен восьми битам (одному байту). Количество символов во всём словаре равно 7 40 • 80 • 60 = 3 552 000. Следовательно, объём этого текста в байтах равен 3 552 000 байтов = 3 468,75 Кбайт ≈ 3,39 Мбайт.
Ответ: 3,39 Мбайт.
Самое главное:
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
Информационный объём фрагмента текста — это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования.
Вопросы и задания:
Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Алексея Толстого:
Не ошибается тот, кто ничего не делает, хотя это и есть его основная ошибка.
1) 512 битов 2) 608 битов 3) 8 Кбайт 4) 123 байта
(Всего символов в высказывании — 76. Поскольку на один символ отводится 1 байт, то объем высказывания равен 76 (байт) = 608 (бит). Правильный ответ: 2)Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующей фразы А. С. Пушкина в кодировке Unicode:
Привычка свыше нам дана: Замена счастию она.
1) 44 бита 2) 704 бита 3) 44 байта 4) 704 байта
(Всего символов во фразе — 44. Поскольку на один символ отводится 2 байта, то объем высказывания равен 88 (байт) = 704 (бит). Правильный ответ: 2)В текстовом режиме экран монитора компьютера обычно разбивается на 25 строк по 80 символов в строке. Определите объём текста, занимающего весь экран монитора, в кодировке Unicode.
(Решение:
В кодировке Unicode каждый символ кодируется 2 байтами. На экран влезает 25 • 80 = 2000 символов. Соответственно, объем текста равен 2000 • 2 = 4000 (байт) ≈ 3,9 (Кбайт)
Ответ: 4000 байт)Сообщение занимает 6 страниц по 40 строк, в каждой строке записано по 60 символов.
Информационный объём всего сообщения равен 28 800 байтам. Сколько двоичных разрядов было использовано на кодирование одного символа?
(Решение:
Сообщение состоит из 6 • 40 • 20 = 14400 символов. Поскольку объем этого текста составляет 28800 байт, то на один символ отводилось 2 байта, т.е. 16-разрядный двоичный код. Текст записан в кодировке Unicode.
Ответ: 16 разрядов)Сообщение, информационный объём которого равен 5 Кбайт, занимает 4 страницы по 32 строки, в каждой из которых записано по 40 символов. Сколько символов в алфавите языка, на котором записано это сообщение?
(Решение:
I = 5 Кбайт
K = 4 • 32 • 40
N = ?N = 2i; I = K • i
i = I/K, i = (5 • 210 • 23)/(22 • 25 • 23 • 5), i = 23 = 8
N = 28 = 256
Ответ: 256 символов в алфавите)

 Информационный объём всего сообщения равен 28 800 байтам. Сколько двоичных разрядов было использовано на кодирование одного символа?
Информационный объём всего сообщения равен 28 800 байтам. Сколько двоичных разрядов было использовано на кодирование одного символа?Рассчетные задачи по теме:
Задача 1
В кодировке Unicode на каждый символ отводится 2 байта. Определите информационный объем слова из двадцати четырех символов в этой кодировке.
Определите информационный объем слова из двадцати четырех символов в этой кодировке.
Решение:
Объем равен 24*2байта = 48 байт = 48* 8 бит = 384 бита
Задача 2
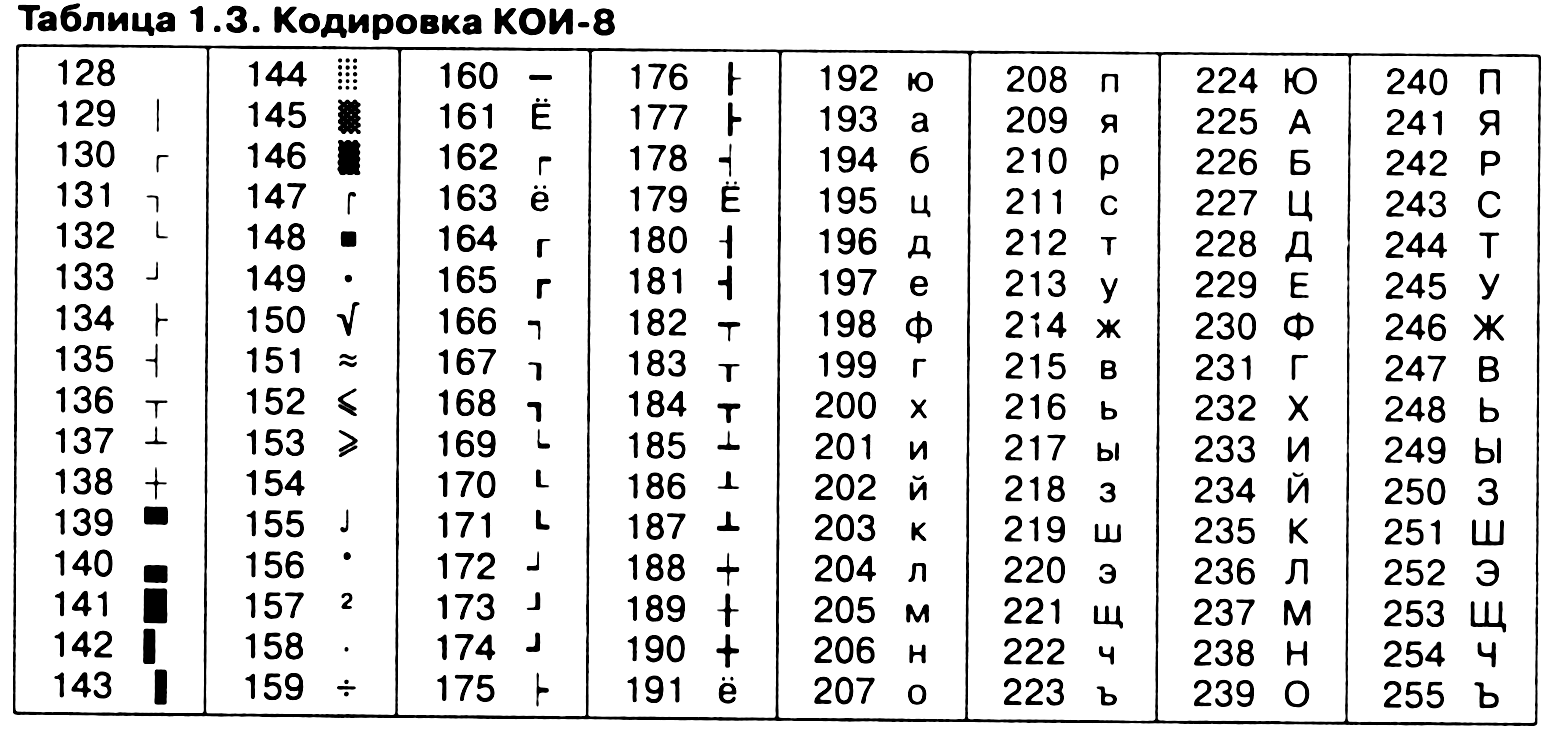
Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 16-битном коде Unicode, в 8-битную кодировку КОИ-8. При этом информационное сообщение уменьшилось на 480 бит. Какова длина сообщения в символах?
Решение:
Количество символов в сообщении n. Значит в 16-битном коде — Unicode объём будет равен 16*n бит, а в 8-битной кодировке КОИ-8 8*n бит. Получим уравнение из условия задачи
16*n = 8*n + 480, 8*n = 480, n = 60.
Длина сообщения будет состоять из 60 символов.
. Считая,что каждый символ кодируется одним байтом, определите, чему равен информационный объем следующего высказывания Рене Декарта:
Я мыслю, следовательно, существую.
28 бит
272 бита
32 Кбайта
34 бита
Решение: 34 символа, на 1 символ 1 байт, т. е. 34*1=34 байта = 272 бита
2. В кодировке Unicode на каждый символ отводится два байта. Определите информационныйобъем слова из двадцати четырех символов в этой кодировке.
384 бита
192 бита
256 бит
48 бит
Решение: 24 символа на каждый 2 байта, 24*2= 48 байт = 384 бита
7. Информационный объем сообщения равен 40960 бит. Чему равен объем этого сообщения в Кбайтах?
5
8
32
12
Решение: 40960/8=5120 / 1024 = 5 Кбайт
8. Символы кодируются 8 битами. Сколько Кбайт памяти потребуется для сохранения 160 страниц текста, содержащего в среднем 192 символа на каждой странице?
Символы кодируются 8 битами. Сколько Кбайт памяти потребуется для сохранения 160 страниц текста, содержащего в среднем 192 символа на каждой странице?
10
20
30
40
Решение: 8 * 160*192 = 245760 / 8 = 30720 / 1024 = 30
9. Объем сообщения равен 11 Кбайт. Сообщение содержит 5632 символа. Каков объем, занимаемый одним символом?
16 байт
1 байт
2 бита
2 байта
Решение: 11 Кбайт = 11264 байта = 90112 бит/5632 = 16 бит на символ = 2 байта
10. Статья, набранная на компьютере, содержит 8 страниц, на каждой странице 40 строк, в каждой строке 64 символа. В одном из представлений Unicode каждый символ кодируется 16 битами. Определите информационный объём статьи в этом варианте представления Unicode.
320 байт
35 Кбайт
640 байт
40 Кбайт
Решение: 8*40*64*16 = 327680 бит = 40960 байт = 40 Кбайт
11. Рассказ, набранный на компьютере, содержит 4 страницы, на каждой странице 48 строк, в каждой строке 64 символа. Определите информационный объём рассказа в кодировке КОИ-8, в которой каждый символ кодируется 8 битами.
12 Кбайт
12000 байт
20 Кбайт
24 Кбайт
Решение: 4*48*64*8 = 98304 бит = 12288 байт = 12 Кбайт
Разбор задания +теория — Сайт учителя информатики Гимальдинова Фидаэля Руфаиловича
Справка
Количество символов в алфавите (мощность алфавита)
находится по формуле N=2I, где I –
информационный вес одного символа (в битах).
Информационный объем сообщения (текста) определяется по
формуле Т = К·I, где К — количество
символов в сообщении (тексте), I –
информационный вес одного символа (в битах)
Задачи
1.
Информационное сообщение объемом 450 бит состоит из 150
символов. Каков информационный вес каждого символа этого сообщения?
1)5 бит; | 2) 30 бит; | 3) 3 бита; | 4) 3 байта. |
2.
Информационное сообщение объемом 3 Кбайта содержит 6144
символа. Сколько символов содержит алфавит, при помощи которого было записано
это сообщение?
3.
Учитывая, что каждый символ кодируется 16-ю битами,
оцените информационный объем следующей пушкинской фразы в кодировке Unicode:
Привычка свыше нам дана: Замена счастию она.
1)44 бита; | 2) 704 бита; | 3) 44 байта; | 4) 794 байта. |

4.
В кодировке КОИ-8 каждый символ кодируется одним байтом. Определите
количество символов в сообщении, если информационный объем сообщения в этой кодировке
равен 160 бит.
1)10; | 2) 16; | 3) 20; | 4) 160. |
5.
В кодировке КОИ-8 каждый символ кодируется восемью битами.
Сколько символов содержит сообщение объемом 0,5 Кбайта?.
1)8192; | 2) 1024; | 3) 512; | 4) 256. |
6.
Сочинение по литературе написано на 5 страницах, на
каждой странице 32 строки по 48 символов. Использовалась кодировка Unicode, где
один символ кодируется 2 байтами. Каков информационный объем всего сочинения в Кбайтах?
1)15; | 2) 24; | 3) 48; | 4) 56. |

7.
Реферат, набранный на компьютере, содержит 16 страниц, на
каждой странице 50 строк, в каждой строке 64 символа. Для кодирования символов
используется кодировка Unicode, при которой
каждый символ кодируется 16 битами. Определите информационный объем реферата.
1)320 байт; | 2) 100 Кбайт; | 3) 128 Кбайт; | 4) 1 Мбайт. |
8.
Реферат учащегося по истории имеет объем 110 Кбайт.
Каждая его страница содержит 40 строк по 64 символа. При этом в кодировке один
символ кодируется 16 битами. Сколько страниц в реферате?
1)25; | 2) 18; | 3) 20; | 4) 22. |
9.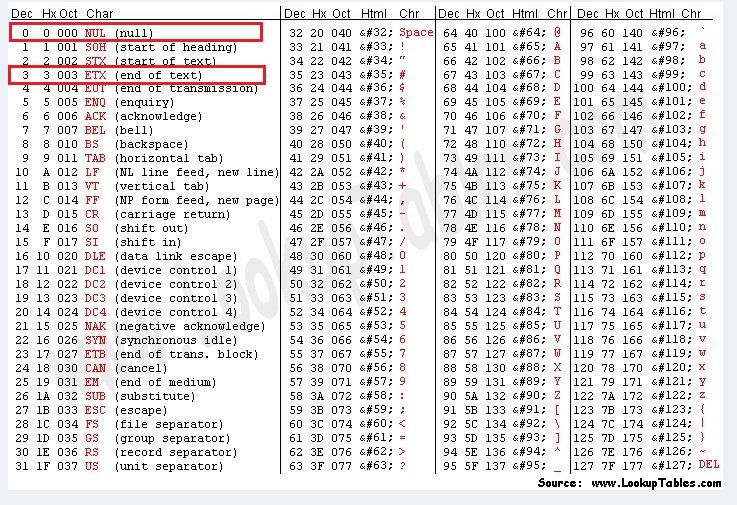
Автоматическое устройство осуществило перекодировку
информационного сообщения на русском языке, первоначально записанного в
16-битном коде Unicode, в 8-битную кодировку КОИ-8. При этом информационное сообщение
уменьшилось на 160 бит. Какова длина сообщения в символах?
1)2; | 2) 18; | 3) 20; | 4) 22. |
10.
Текстовый документ, состоящий из 3072 символов, хранился
в 8-битной кодировке КОИ-8. Этот документ был преобразован в 16-битную
кодировку Unicode. Укажите, какое дополнительное количество Кбайт потребуется
для хранения документа. В ответе запишите только число.
11.
В марафоне участвуют 12 спортсменов. Специальное
устройство регистрирует прохождение финиша, записывая его номер с
использованием минимально возможного количества бит, одинакового для каждого
бегуна. Каков информационный объем сообщения, записанного устройством, после
того как финиш пересекли 8 спортсменов?
1)6 байт; | 2) 32 бита; | 3) 3 байта; | 4) 48 бит. |

ОГЭ 9 класс А1. Кодирование текстовой информации
= =
Задание 1 1. Статья, набранная на компьютере, содержит 32 страницы, на каждой странице 40 строк, в каждой строке 48 символов. Определите размер статьи в кодировке КОИ-8, в которой каждый символ кодируется
Подробнее
БОЛЬШОЙ СБОРНИК ТЕМАТИЧЕСКИХ ЗАДАНИЙ
Д. М. Ушаков ИНФОРМАТИКА БОЛЬШОЙ СБОРНИК ТЕМАТИЧЕСКИХ ЗАДАНИЙ для подготовки к основному государственному экзамену Москва АСТ УДК 373:002 ББК 32.81я721 У93 У93 Ушаков, Денис Михайлович. Информатика : большой
Информатика : большой
Подробнее
Алфавитный подход к измерению информации:
Алфавитный подход к измерению информации: Каждый символ некоторого сообщения имеет определённый информационный вес несёт фиксированное количество информации. Все символы одного алфавита имеют один и тот
Подробнее
Информация и еѐ кодирование
1 Информация и еѐ кодирование Разбор заданий из демонстрационных тестов А1 Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения из пушкинских строк: Певец
Подробнее
B7 (повышенный уровень, время 3 мин)
B7 (повышенный уровень, время мин) Тема: Определение скорости передачи информации при заданной пропускной способности канала. Что нужно знать: «физический» аналог задачи: лимонад лимонад сколько лимонада
Подробнее
B10 (повышенный уровень, время 3 мин)
B1 (повышенный уровень, время 3 мин) Тема: Определение скорости передачи информации при заданной пропускной способности канала. Что нужно знать: «физический» аналог задачи: лимонад лимонад сколько лимонада
Что нужно знать: «физический» аналог задачи: лимонад лимонад сколько лимонада
Подробнее
B10 (повышенный уровень, время 4 мин)
B10 (повышенный уровень, время 4 мин) Тема: Определение скорости передачи информации при заданной пропускной способности канала. Что нужно знать: «физический» аналог задачи: лимонад лимонад сколько лимонада
Подробнее
Задание 3. Информационное моделирование
Задание. Информационное моделирование (базовый уровень, время мин) Задания для самостоятельного решения: ) На схеме нарисованы дороги между пятью городами,,,, и указаны протяжённости дорог. Определите,
Подробнее
B10 (повышенный уровень, время 4 мин)
B10 (повышенный уровень, время 4 мин) Тема: Определение скорости передачи информации при заданной пропускной способности канала. Что нужно знать: «физический» аналог задачи: лимонад лимонад сколько лимонада
Что нужно знать: «физический» аналог задачи: лимонад лимонад сколько лимонада
Подробнее
ВАРИАНТ 1. ВАРИАНТ 2.
ВАРИАНТ 1. 1. Текстовое сообщение, закодированное в формате ASCII перекодировали в Unicode. На сколько изменился информационный объем сообщения, если до этого оно занимало в памяти компьютера 512 бит?
Подробнее
13 (повышенный уровень, время 3 мин)
13 (повышенный уровень, время 3 мин) Тема: Вычисление информационного объема сообщения. Что нужно знать: с помощью K бит можно закодировать K Q = 2 различных вариантов (чисел) таблица степеней двойки,
Подробнее
А11 (повышенный уровень, время 3 мин)
А11 (повышенный уровень, время 3 мин) Тема: Вычисление информационного объема сообщения. Что нужно знать: с помощью K бит можно закодировать K Q различных вариантов (чисел) таблица степеней двойки, она
Подробнее
1) 120 Кбайт 2) 480 байт 3) 960 байт 4) 60 Кбайт
Задания 1. Количественные параметры информационных объектов 1. Статья, набранная на компьютере, содержит 32 страницы, на каждой странице 40 строк, в каждой строке 48 символов. Определите размер статьи
Количественные параметры информационных объектов 1. Статья, набранная на компьютере, содержит 32 страницы, на каждой странице 40 строк, в каждой строке 48 символов. Определите размер статьи
Подробнее
Количество информации
Количество информации 1.1. Алфавит племени Мульти состоит из 8 букв. Какое количество информации несет одна буква этого алфавита? 1.2. Сообщение, записанное буквами из 64-символьного алфавита, содержит
Подробнее
Раздел 1. «Характеристика программы»
Раздел 1. «Характеристика программы» 1.1. Цель реализации программы Совершенствование профессиональных компетенций слушателей в области предметных знаний по информатике на продвинутом уровне. Совершенствуемые
Подробнее
ИНФОРМАЦИЯ. ИЗМЕРЕНИЕ ИНФОРМАЦИИ
ИНФОРМАЦИЯ. ИЗМЕРЕНИЕ ИНФОРМАЦИИ 7 класс, 2017-2018 учебный год Повторение Информация это сведения об объектах и явлениях окружающей среды. Информатика наука о способах хранения, обработки и передачи информации
Информатика наука о способах хранения, обработки и передачи информации
Подробнее
Задания B1 по информатике
Задания B1 по информатике 1. Некоторое сигнальное устройство за одну секунду передает один из трех сигналов. Сколько различных сообщений длиной в пять секунд можно передать при помощи этого устройства?
Подробнее
КОНТРОЛЬНО-ИЗМЕРИТЕЛЬНЫЕ МАТЕРИАЛЫ
Муниципальное бюджетное общеобразовательное учреждение «Средняя общеобразовательная школа 1» Приложение 2 к ОП СОО КОНТРОЛЬНО-ИЗМЕРИТЕЛЬНЫЕ МАТЕРИАЛЫ по текущей аттестации предмет: Информатика и ИКТ. 10
Подробнее
Кодирование информации
Кодирование информации Текст Алфавит => кодировочная таблица Мощность алфавита = количество символов Объем памяти на один символ = количество бит, обеспечивающее необходимое количество вариантов (2 b )
Подробнее
Информация и еѐ кодирование
1 Информация и еѐ кодирование Разбор заданий из демонстрационных тестов А1 Считая, что каждый символ кодируется одним байтом, оцените информационный объем следующего предложения из пушкинских строк: Певец
Подробнее
А15 (повышенный уровень, время 2 мин)
А15 (повышенный уровень, время мин) Тема: Кодирование и обработка графической информации. Что нужно знать: графическая информация может храниться в растровом и векторном форматах векторное изображение
Что нужно знать: графическая информация может храниться в растровом и векторном форматах векторное изображение
Подробнее
Информатика 9 класс. Модуль 1
Информатика 9 класс. Модуль 1 Задание 1 К свойствам информации не относится 1) полнота 2) ценность 3) доступность 4) универсальность Задание 2 Выберете типы информации, обрабатываемые компьютером Выберите
Подробнее
ЗАДАНИЯ — 1. Нумерация разделов по ЕГЭ-2013 ИНФОРМАЦИЯ. А8, А11, В1, В10 СИСТЕМЫ СЧИСЛЕНИЯ. А1, А9, В4, В8 АЛГЕБРА ЛОГИКИ.
ГОСУДАРСТВЕННОЕ БЮДЖЕТНОЕ ОБЩЕОБРАЗОВАТЕЛЬНОЕ УЧРЕЖДЕНИЕ ГИМНАЗИЯ 116 ПРИМОРСКОГО РАЙОНА САНКТ-ПЕТЕРБУРГА ЗАДАНИЯ — 1 ИНФОРМАЦИЯ. А8, А11, В1, В10 СИСТЕМЫ СЧИСЛЕНИЯ. А1, А9, В4, В8 АЛГЕБРА ЛОГИКИ. А3,
Подробнее
«Избранные вопросы по информатике»
Государственное бюджетное общеобразовательное учреждение города Москвы «Школа 1450 «Олимп» Программа принята педагогическим советом Протокол 1 от августа 2017 г. «Утверждаю» И.о директора ГБОУ Школа 1450
«Утверждаю» И.о директора ГБОУ Школа 1450
Подробнее
ТЕМАТИЧЕСКИЕ ТРЕНИРОВОЧНЫЕ ЗАДАНИЯ
ЭФФЕКТИВНАЯ ПОДГОТОВКА К ОГЭ 2020 Е. М. Зорина, М. В. Зорин ИНФОРМАТИКА ТЕМАТИЧЕСКИЕ ТРЕНИРОВОЧНЫЕ ЗАДАНИЯ МОСКВА 2019 ГАРАНТИЯ КАЧЕСТВА ОГЭ!** ОЛУЧ ОГЭ! НА БАЛЛ ВЫСШИЙ ППОЛУЧИ ОЛУЧИ ВЫСШИЙ БАЛЛ НА ОГЭ!
Подробнее
Домашние работы 8 классДЗ №1 Единицы измерения информации
ДЗ №2 Определение количества информации
ДЗ №3 Устройства ввода-вывода
ДЗ №4 Файлы и файловая система
Пр.р.2.3 Определение разрешающей способности мыши в Windows
ДЗ №6 Передача информации в компьютерных сетяхРешить задачи.
| ||||

 Какой объем информации оно несет?
Какой объем информации оно несет? Электронное устройство
Электронное устройство Каков
Каков Каждая страница содержит 30 строк по 70 символов в строке. Какой объем информации содержат 5 страниц текста?
Каждая страница содержит 30 строк по 70 символов в строке. Какой объем информации содержат 5 страниц текста? Во сколько раз количество информации во втором тексте больше, чем в первом?
Во сколько раз количество информации во втором тексте больше, чем в первом? Какова мощность алфавита?
Какова мощность алфавита? Сколько символов содержит алфавит, при помощи которого было записано это сообщение?
Сколько символов содержит алфавит, при помощи которого было записано это сообщение? Результатом одного измерения является целое число от 0 до 100 процентов, которое записывается при помощи минимально возможного количества бит. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений.
Результатом одного измерения является целое число от 0 до 100 процентов, которое записывается при помощи минимально возможного количества бит. Станция сделала 80 измерений. Определите информационный объем результатов наблюдений. При регистрации участника для записи его номера система использует минимально возможное количество бит, одинаковое для каждого участника. Каков объем информации в битах, записанный устройством после регистрации 60 участников?
При регистрации участника для записи его номера система использует минимально возможное количество бит, одинаковое для каждого участника. Каков объем информации в битах, записанный устройством после регистрации 60 участников? Сколько символов содержат алфавиты, с помощью которых записаны сообщения, если известно, что размер каждого алфавита не превышает 32 символов и на каждый символ приходится целое число битов?
Сколько символов содержат алфавиты, с помощью которых записаны сообщения, если известно, что размер каждого алфавита не превышает 32 символов и на каждый символ приходится целое число битов? ..
..
 Определите, сколько символов содержал переданный текст, если известно, что он был представлен в 16-битной кодировке Unicode.
Определите, сколько символов содержал переданный текст, если известно, что он был представлен в 16-битной кодировке Unicode.Бесплатный детектор символов Unicode для текстовых сообщений
Как использовать детектор символов Юникода
С помощью этого простого инструмента вы можете мгновенно идентифицировать символы GSM и символы Unicode в текстовых сообщениях. Символы в кодировке GSM будут серыми, а специальные символы Unicode будут выделены красным.
Символы в кодировке GSM будут серыми, а специальные символы Unicode будут выделены красным.
- Шаг № 1: Скопируйте и вставьте текстовое сообщение в пустое поле. Символы будут автоматически отображаться в поле результатов.
- Шаг № 2: Определите различные символы в вашем SMS-сообщении.Символы GSM будут отображаться серым цветом, символы Unicode — красным, а escape-символы — оранжевым.
- Шаг № 3: Инструмент также вычисляет количество символов в тексте и количество частей разделенного сообщения, что позволяет вам контролировать конкатенацию.
Почему следует использовать детектор символов Юникода
Как вы, вероятно, уже знаете, текстовые сообщения ограничены 160 символами, если они все из набора символов GSM.Однако, если ваш текст содержит символы Unicode, он будет ограничен 70 символами вместо 160.
Конечно, сообщения длиной более 70 символов по-прежнему могут быть отправлены, но они станут составными. Это означает, что SMS-сообщение длиной 160 символов будет разделено на три текстовых сообщения, если они содержат символы Unicode. Это может быть очень неприятно. Еще более неприятно, когда телефон вашего клиента выходит из строя из-за символьных строк Unicode (на самом деле это случалось несколько раз).
Это означает, что SMS-сообщение длиной 160 символов будет разделено на три текстовых сообщения, если они содержат символы Unicode. Это может быть очень неприятно. Еще более неприятно, когда телефон вашего клиента выходит из строя из-за символьных строк Unicode (на самом деле это случалось несколько раз).
Используя детектор символов Unicode, вы можете идентифицировать и заменять символы, которые не являются частью 7-битной кодировки GSM, чтобы избежать разделения текстовых сообщений на несколько сегментов.
Почему мы создали этот инструмент
Символы Unicode не только разбивают текст, но иногда они вообще не отображаются или выглядят как страшные □ □ □. Чтобы обеспечить правильную передачу информации на шлюз SMS, текстовые сообщения должны быть правильно закодированы. Проблема в том, что многие символы крайне сложно закодировать, и потому что стандарт GSM 3.38 кодировку практически невозможно поддерживать, многие провайдеры решили вообще отказаться от нее.
Мы создали инструмент для обнаружения символов Unicode, чтобы помочь нашим клиентам избежать перечисленных выше проблем и гарантировать, что ваши сообщения будут доставлены должным образом.
Преимущества использования детектора символов Unicode
Вот основные преимущества использования нашего инструмента обнаружения символов Unicode:
- Определение символов GSM и Unicode в ваших текстовых сообщениях.
- Определите количество символов и частей в тексте.
- Определите, будет ли текст сегментирован на основе количества символов Unicode.
- Удалите символы Unicode и замените их символами GSM.
- Предварительный просмотр ваших текстовых сообщений перед их отправкой клиентам.
- Управляет разделением текстового сообщения, если оно содержит Unicode.
Почему текстовые сообщения, содержащие Unicode, сегментированы?
Когда вы пытаетесь отправить текстовое сообщение с символами, выходящими за рамки набора символов GSM, вы должны использовать Unicode, который присваивает уникальный код каждому символу, не входящему в стандартную кодировку.Поскольку для описания символа Unicode используется несколько символов GSM, вы сможете отправлять текстовые сообщения только длиной 35–70 символов.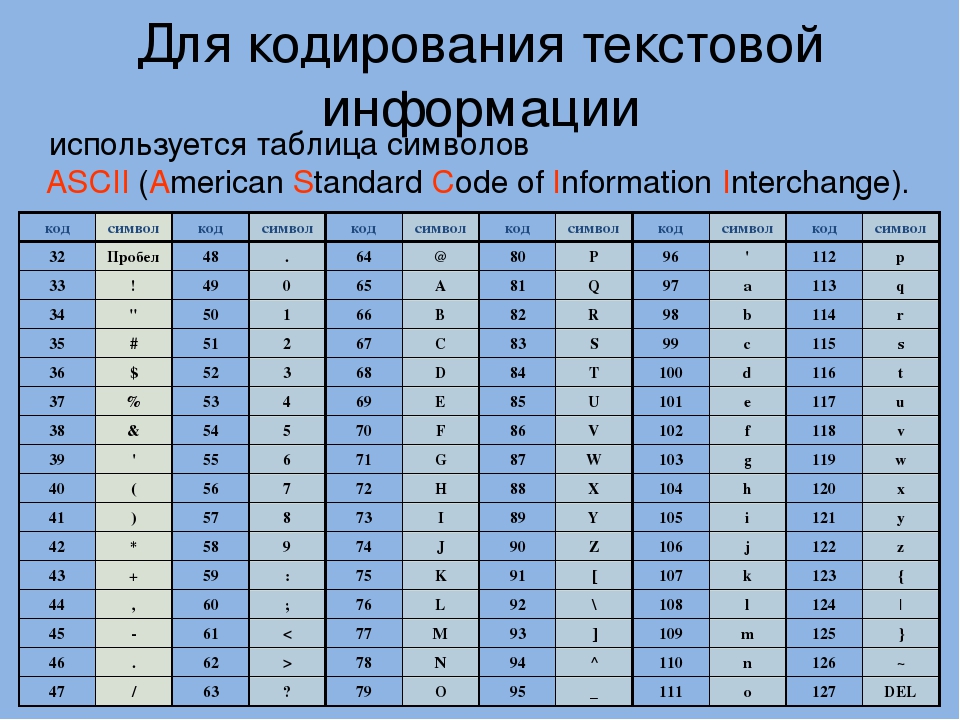
Могу ли я избежать сегментации текстовых сообщений и по-прежнему использовать Unicode?
Чтобы избежать сегментации SMS и преобразовать символы Unicode только в латинские, вы можете использовать наш транслитератор текста.
GSM описывает протоколы для сотовых сетей второго поколения и мобильных устройств. В настоящее время это стандарт мобильной связи, занимающий более 90% рынка.Следовательно, все сообщения, отправляемые на такие устройства, должны соответствовать стандартной кодировке GSM.
Если текстовое сообщение содержит символы, отличные от GSM, оно будет ограничено 70 символами . Единственное решение, позволяющее избежать разделения ваших текстов, — это проверить символы Unicode и заменить их их эквивалентами в кодировке GSM (если такой эквивалент существует).
Какие символы входят в кодировку GSM?
Стандартный набор символов GSM содержит буквы английского алфавита, цифры и некоторые специальные символы, включая несколько греческих.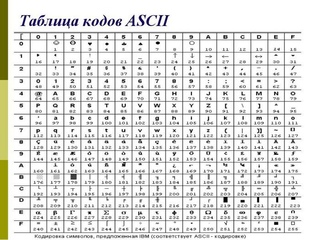
Список символов GSM: здесь
Какие символы входят в кодировку Unicode?
Список символов Юникода содержит символы кириллицы, китайского, арабского, корейского и хангыльского алфавитов. Он также содержит несколько специальных символов (например, смайлики, эмодзи и кандзи).
Список символов Unicode: здесь
Как решить проблемы с кодировкой Unicode
Кодировка
прозрачна для большинства пользователей.
Он даже стал настолько прозрачным с момента зарождения гениального формата Unicode UTF-8, что даже разработчик может потеряться в случае несовместимости.
РЕЗЮМЕ
1. Что такое кодирование?
⇒ Расшифровка кодировок на конкретном примере
2. Формат UTF-8
⇒ Сосредоточьтесь на формате Unicode UTF-8, который теоретически устраняет любые проблемы с кодировкой
3. Постоянные проблемы с кодировкой
⇒ Почему, несмотря на формат Unicode, проблемы с кодировкой остаются актуальными?
4. Определение кодировки файла
Определение кодировки файла
⇒ Мы предлагаем стандартные инструменты для простого определения кодировки текста
5.Расширенное упражнение VBA
⇒ Способ создания файлов Unicode в VBA со спецификацией
или без нее
Не стесняйтесь оставлять комментарии и запросы о поддержке по конкретной проблеме с кодировкой.
Строка хранится в памяти не как строка, а как 0 и 1 в двоичном формате.
Для нас наиболее читаемым представлением этого двоичного кода является шестнадцатеричный код, в котором каждый байт представляет отдельный символ в ASCII или в расширенном ASCII.
Пример :
Следующая строка закодирована кодом «Windows-1252»:
«L’exp é rience est le nom que chacun donne à ses erreurs.”Oscar Wilde
В шестнадцатеричном коде это представлено, как показано ниже:
| 22 4C 27 65 78 70 E9 72 69 65 6E 63 65 20 65 73 | “L’exp é rience es |
| 74 20 6C 65 20 6E 6F 6D 20 71 75 65 20 63 68 61 | t le nom que cha |
| 63 75 6E 20 64 6F 6E 6E 65 20 E0 20 73 65 73 20 | cun donne à ses |
| 65 72 72 65 75 72 73 2E 22 20 4F 73 63 61 72 20 | ошибок. ”Оскар ”Оскар |
| 57 69 6C 64 65 | Уайлд |
7-й символ « é » сохраняется в памяти с использованием следующего шестнадцатеричного значения: « E9 ».
В таблице символов Windows-1252 код « E9 » соответствует французскому символу « é »:
| Окна-1252 (CP1252) | ||||||||||||||||
| x0 | х1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | xA | xB | xC | xD | xE | xF | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | БЕЛ | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | НАК | SYN | ETB | CAN | EM | ПОД | ESC | ФС | GS | RS | США |
| 2x | СП | ! | “ | # | $ | % | и | ‘ | ( | ) | * | + | , | – | . | _ |
| 6x | ` | a | б | c | d | e | f | г | ч | и | j | к | л | кв.м. | n | o |
| 7x | с. | q | r | с | т | u | v | Вт | х | y | z | { | | | } | ~ | DEL |
| 8x | € | ‚ | ƒ | „ | … | † | ‡ | ˆ | ‰ | Š | ‹ | Œ | Ž | |||
| 9x | ‘ | ‘ | “ | ” | • | – | – | ˜ | ™ | š | › | œ | ž | Ÿ | ||
| Топор | НБСП | ¡ | ¢ | £ | ¤ | ¥ | ¦ | § | ¨ | © | ª | « | ¬ | ® | ¯ | |
| Bx | ° | ± | ² | ³ | ´ | µ | ¶ | · | ¸ | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
| Сх | À | Á | Â | Ã | Ä | Å | Æ | Ç | È | É | Ê | Ë | Ì | Í | Î | Ï |
| Dx | Ð | Ñ | Ò | Ó | Ô | Õ | Ö | × | Ø | Ù | Ú | Û | Ü | Ý | Þ | ß |
| Пример | до | á | â | г | ä | å | æ | ç | и | é | ê | ë | м | – | до | • |
| Fx | ð | — | шт | — | ô | х | ö | ÷ | ø | ù | ú | û | ü | ý | þ | ÿ |
Тем не менее, если вы войдете в окно MS-DOS, шестнадцатеричный код «E9» не будет отображаться правильно!
Действительно, французское окно MS-DOS покажет следующее:
Cd \ temp
Типовой тест. txt
txt
«L’exp Ú rience est le nom que chacun donne Ó ses erreurs». Оскар Уайльд
Это просто потому, что MS-DOS по умолчанию считает, что тексты (на французском компьютере) кодируются с использованием страницы 850 ниже:
| стр. 850 (ДОС латинский-1) | ||||||||||||||||
| x0 | х1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | xA | xB | xC | xD | xE | xF | |
| 0x | NUL | SOH | STX | ETX | EOT | ENQ | ACK | БЕЛ | BS | HT | LF | VT | FF | CR | SO | SI |
| 1x | DLE | DC1 | DC2 | DC3 | DC4 | НАК | SYN | ETB | CAN | EM | ПОД | ESC | ФС | GS | RS | США |
| 2x | СП | ! | “ | # | $ | % | и | ‘ | ( | ) | * | + | , | – | . | _ |
| 6x | ` | a | б | c | d | e | f | г | ч | и | j | к | л | кв.м. | n | o |
| 7x | с. | q | r | с | т | u | v | Вт | х | y | z | { | | | } | ~ | DEL |
| 8x | Ç | ü | é | â | ä | до | å | ç | ê | ë | и | • | до | м | Ä | Å |
| 9x | É | æ | Æ | ô | ö | шт | û | ù | ÿ | Ö | Ü | ø | £ | Ø | × | ƒ |
| Топор | á | – | — | ú | — | Ñ | ª | º | ¿ | ® | ¬ | ½ | ¼ | ¡ | « | » |
| Bx | ░ | ▒ | ▓ | │ | ┤ | Á | Â | À | © | ╣ | ║ | ╗ | ╝ | ¢ | ¥ | ┐ |
| Сх | └ | ┴ | ┬ | ├ | ─ | ┼ | г | Ã | ╚ | ╔ | ╩ | ╦ | ╠ | = | ╬ | ¤ |
| Dx | ð | Ð | Ê | Ë | È | № | Í | Î | Ï | ┘ | ┌ | █ | ¦ | Ì | ▀ | |
Пример. | Ó | ß | Ô | Ò | х | Õ | µ | þ | Þ | Ú | Û | Ù | ý | Ý | ¯ | ´ |
| Fx | SHY | ± | ‗ | ¾ | ¶ | § | ÷ | ¸ | ° | ¨ | · | ¹ | ³ | ² | ■ | НБСП |
Шестнадцатеричный код « E9 » соответствует символу « Ú » из списка символов на странице 850 и не соответствует символу « é », как мы могли ожидать.
Таким образом, понятно, что текстовый файл на самом деле является закодированным сообщением (не зашифрованным сообщением), которое должно быть декодировано с использованием точной таблицы перевода.
Таким образом, сложность двоякая:
— Вы должны тщательно выбирать, в зависимости от целевого приложения, кодировку для использования при сохранении текста.
— Когда пришло время отображать текст, необходимо определить используемую кодировку.
В блоге INVIVOO используется кодировка UTF-8. Но если бы вам было интересно принудительно использовать кодировку ISO-8859-7 в Internet Explorer с помощью меню «Вид => Кодировка => Больше => Греческий (ISO)», то следующие символы windows-1252 будут отображаться неправильно.
| x0 | х1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | xA | xB | xC | xD | xE | xF | |
| Fx | ð | — | шт | — | ô | х | ö | ÷ | ø | ù | ú | û | ü | ý | þ | ÿ |
Используя ISO-8859-7, вышеуказанные символы будут отображаться как следующие символы:
| x0 | х1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | xA | xB | xC | xD | xE | xF | |
| Факс | Γ ° | Γ ± | Γ² | Γ³ | Γ΄ | Γ΅ | ΓΆ | Г · | ΓΈ | ΓΉ | ΓΊ | Γ » | ΓΌ | Γ½ | ΓΎ | ΓΏ |
Мы видим, что ожидаемые западные символы теперь отображаются плохо и что есть 2 символа вместо одного.
Это связано с тем, что в кодировке Unicode UTF-8 западные специальные символы имеют двухбайтовую кодировку . И потому, что кодировка ISO-8859-7 (греческий) считает, что каждый из этих двух байтов сам по себе является символом в своей таблице сопоставления.
Обратите внимание, что количество существующих кодировок довольно велико. У каждого из них есть веская причина, чтобы узнать историю кодирования. После интернационализации, последовавшей за развитием Интернета, управление кодированием становилось все более и более сложным из-за многоязычной среды.
К счастью, , стандарт Unicode успешно справился с задачей собрать все символы из каждой кодировки в одну-единственную таблицу символов: список символов Unicode.
Формат Unicode родился из желания унифицировать множество существующих кодировок. Множественность кодов была необходима, потому что системы всегда считали, что один байт соответствует одному символу. Однако в байте можно закодировать только 256 символов.Поэтому некоторым языкам требовался собственный расширенный код ASCII. Французское « é », например, совершенно бесполезно для греков, которым также необходимо кодировать целый собственный алфавит.
Однако в байте можно закодировать только 256 символов.Поэтому некоторым языкам требовался собственный расширенный код ASCII. Французское « é », например, совершенно бесполезно для греков, которым также необходимо кодировать целый собственный алфавит.
Решение Unicode состоит в том, чтобы избавиться от ограничения одного байта, чтобы иметь почти бесконечное количество возможных символов. Азиатские символы могут быть закодированы, например, 4 байтами.
К сожалению, существует несколько версий формата Unicode в зависимости от того, является ли количество байтов на символ фиксированным или динамическим, и в зависимости от порядка чтения байтов.
Мы представим только формат UTF-8, потому что он имеет тенденцию доминировать из-за его эффективности с точки зрения размера памяти и из-за его обратной совместимости с ASCII. Действительно, ничто не отличает старый файл ASCII от файла UTF-8. Только при использовании специальных символов файл UTF-8 будет отличаться от ASCII.
Специальные символы в UTF-8 хранятся в шестнадцатеричном формате от 2 до 4 байтов. Он кодируется просто с учетом карты символов UTF-8. Почему-то все так же просто, как раньше : «код» всегда представляет собой отдельный символ в отображении символов.
Если приложение не может прочитать UTF-8 или если оно принудительно используется в расширенном ASCII (как в нашем предыдущем примере с принудительным использованием ISO-8859-7 в Internet Explorer), то приложение будет читать каждый байт как один отдельный символ. Однако все специальные символы Западной Европы кодируются 2 байтами в UTF-8.
=> Именно по этой причине подчеркнутые символы отображаются двумя символами вместо одного, когда кодировка определена неправильно.
Теперь вы знаете почти все о UTF-8:
— Имеет обратную совместимость с ASCII
— Специальные символы хранятся в 2–4 байтах
— Как и любая кодировка, приложение, которое «считывает» шестнадцатеричный код, должно использовать правильную кодировку
Вы знаете только «почти все», потому что в Unicode есть особая функция, которая по-прежнему вызывает некоторые проблемы совместимости: BOM (Byte Mark Order). Об этом мы поговорим в следующей части.
Об этом мы поговорим в следующей части.
После этого необходимого представления кодировки текста мы, наконец, переходим к сути этой статьи, задав следующий вопрос:
Если UTF-8 содержит все символы и может заменить все коды, почему мы все еще сталкиваемся с проблемами кодирования ???
1. Изменение требует времени
Основная причина в том, что старые системы не обязательно развивались одновременно с революцией Unicode. Таким образом, могут быть некоторые базы данных, приложения или пакеты, которые могли быть запрограммированы на получение определенной кодировки, и достаточно часто они могли ожидать одного байта на символ.
2. Специфика Microsoft Windows
Microsoft взяла на себя смелость создать свои собственные таблицы символов, производные от таблиц ISO-8859-x. Более того, невозможно узнать, использует ли текст таблицу ISO или таблицу Windows, потому что обе они соответствуют просто последовательности байтов.
Эта свобода, полученная Microsoft, была бы меньшей проблемой, если бы приложения Windows использовали UTF-8 по умолчанию, но это не так. Пока нет специальных символов за пределами таблицы Windows-1252, большинство приложений Windows не кодируют тексты с использованием UTF-8.
Таким образом, отправка текстового файла Windows на сервер Linux или собственное приложение может легко ввести в заблуждение.
3. Символьные шрифты
Поскольку Unicode может кодировать все возможные символы, он стал кошмаром для художников, создающих шрифты, потому что перерисовка каждого символа — огромная задача. И они делают это не для того, чтобы сосредоточиться на интересующем их языке. Кроме того, стандарт Unicode может добавлять новые символы в таблицу, а существующие шрифты становятся неполными!
В результате для экзотических языков может потребоваться работа с определенными шрифтами.
Однако шрифты влияют только на отображение конечных пользователей и никоим образом не могут нарушить обработку или хранение ваших строк в базе данных.
3. Спецификация (метка порядка байтов)
Знак порядка байтов представляет собой последовательность непечатаемых байтов Unicode, помещенных в начало текста Unicode для облегчения его интерпретации. Этот знак порядка байтов не является ни стандартным, ни обязательным, но он упрощает совместимым приложениям определение подтипа формата Unicode и направление чтения байтов.
Это часто вызывает проблемы совместимости, потому что не все приложения знают, как обрабатывать «BOM». Для несовместимых приложений эта последовательность байтов считается некоторыми обычными символами в расширенном ASCII. В случае, если файл UTF-8 ошибочно распознан как файл Windows-1252, мы увидим 3 странных символа в самом начале файла: ï »¿.
Символы ï »¿соответствуют шестнадцатеричной строке EF BB BF, которая представляет собой код, указывающий совместимым приложениям, что файл является файлом Unicode в формате UTF-8.
Еще одна проблема спецификации — путаница, которую она может вызвать у пользователя. EF BB BF соответствует некоторым непечатаемым символам в UTF-8. Таким образом, в текстовом редакторе Unicode трудно узнать, была ли применена спецификация или нет, поскольку она невидима и необязательна в файле UTF-8. Многие пользователи, скорее всего, не знают, что такое BOM и как это может привести к сбою несовместимых приложений.
EF BB BF соответствует некоторым непечатаемым символам в UTF-8. Таким образом, в текстовом редакторе Unicode трудно узнать, была ли применена спецификация или нет, поскольку она невидима и необязательна в файле UTF-8. Многие пользователи, скорее всего, не знают, что такое BOM и как это может привести к сбою несовместимых приложений.
И другие существующие дополнительные спецификации возможны для указания форматов Unicode, различных UTF-8 и общих элементов, которые могут быть совместимы.
Поскольку спецификация невидима для пользователя, путаница очевидна и неизбежна.
Однако , в разделе ниже, мы предоставим вам стандартные инструменты, чтобы вы могли быстро определить, является ли ваш файл таким, каким вы его ожидаете.
Независимо от происхождения файла, созданного автоматически, отправленного поставщиком данных или созданного вручную, может быть полезно проверить с абсолютной уверенностью его формат и показать возможную спецификацию тегов.
Если у вас нет доступа к расширенным (и обычно платным) текстовым редакторам, вы можете легко сделать это с помощью стандартных шестнадцатеричных редакторов в Windows и Linux.
В Windows:
— Ключевые окна + R
— Командная оболочка powershell
— Cd \ temp
— Fhx test.txt
В Linux:
cd / home / test /
file -bi test.txt
=> Linux «попытается» показать формат файла, но если вы хотите увидеть тег BOM, необходимо ввести следующее :
xxd test.txt
Если в самом начале файла есть тег спецификации, то это текст в формате Unicode:
UTF-8 = EF BB BF
UTF-16 Big Endian = FE FF
UTF-16 Little Endian = FF FE
UTF-32 Big Endian = 00 00 FE FF
UTF-32 Little Endian = FF FE 00 00
Прежде всего, помните, что отсутствие тега BOM не означает, что файл не является файлом Unicode.
Действительно, наоборот, может потребоваться его удаление для увеличения совместимости с вашими приложениями.
В следующей части мы увидим, как удалить спецификацию в VBA, чтобы избежать сбоев последующих приложений.
Когда вы создаете файл Unicode с использованием макросов VBA, предназначенных для чувствительных к формату приложений, вы, вероятно, столкнетесь с некоторыми трудностями при освоении спецификации.
Для начала вы можете использовать команды, предложенные в предыдущем разделе, для проверки ваших выходных файлов.
Чтобы создавать файлы UTF-8 в удобное для вас время — с отметкой порядка байтов или без нее — вам необходимо знать следующие ограничения VBA :
1. Команда Print # 1 не сохраняется в UTF-8, вы потеряете свои символы Unicode.
Пример :
Откройте «c: \ Temp \ test.txt» для вывода как # 1
Print # 1, « Линия 1: особый символ Юникода: Ж = D0 96 ”
2. Команда SavetoFile из объекта «ADODB.Stream» всегда создает спецификацию «EF BB BF» для файлов UTF-8! Не ищите слишком много: нет возможности написать UTF-8 без спецификации, но мы предоставим вам решение .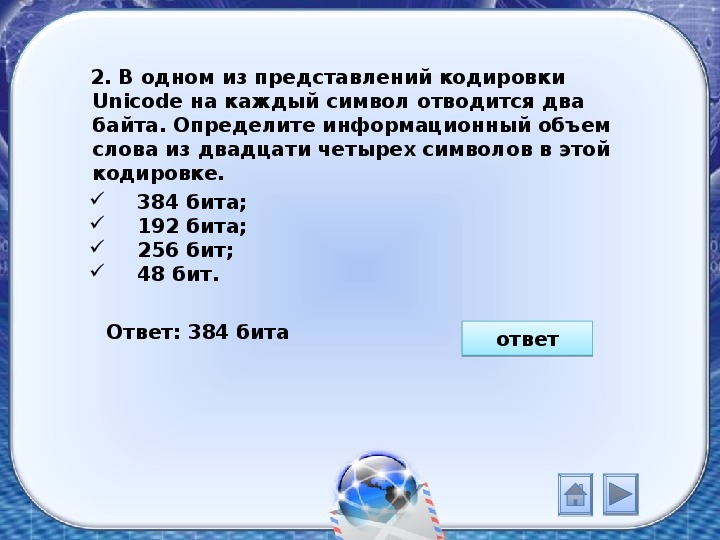
Знание этих двух ограничений сэкономит вам много времени на исследования.
Ниже приведен пример кода, который позволяет создать два файла: один со спецификацией «EF BB BF» и другой без спецификации.
Sub Create_UTF8 ()
Dim lStreamUTF8BOM, lStreamBinaireSansBOM как объект
Установить lStreamUTF8BOM = CreateObject («ADODB.Stream»)
Установить lStreamBinaireSansBOM = CreateObject («ADODB.Stream»)
‘Мы создаем главный поток
lStreamUTF8BOM.Type = 2‘ 2 = Type Texte
lStreamUTF8BOM.Mode = 3 ‘3 = Mode Read and Write
lStreamUTF8BOM.Charset =« UTF-8 »‘ Unicode UTF-8 format with BOM
lStreamUTF8BOM.Open
lStreamUTF8BOM.WriteText «Линия 1: особый символ Юникода: Ж = D0 96» и vbCrLf
lStreamUTF8BOM.WriteText «Линия 2» и vbCrLf
‘сохранение как UTF-8 с BOM
lStreamUTF8BOM.SaveToFile« c: \ Temp \ UTF8withBOM.txt », 2‘ 2 = перезаписать
‘сохранение как UTF-8 без спецификации
lStreamBinaireSansBOM. Type = 1‘ 1 = двоичный поток
Type = 1‘ 1 = двоичный поток
lStreamBinaireSansBOM.Mode = 3 ‘3 = Mode Read and Write
lStreamBinaireSansBOM.Open
lStreamUTF8BOM.Position = 3
lStreamUTF8BOM.CopyTo lStreamBinaireSansBOM
lStreamBinaireSansBOM.SaveToFile «c: \ Temp \ UTF8withoutBOM.txt», 2 ‘2 = перезаписать
lStreamBinaireSansBOM.Flush
lStreamBinaireSansBOM.Close
lStreamUTFlose8BOM.Flush lStreamUTFlose8BOM.Flush
Концевой переводник
Чтобы проверить результаты, вы можете открыть файлы в C: \ TEMP \ с помощью Powershell и команды fhx, как показано в предыдущем разделе.
Мы показали вам, как работает кодирование и что принесла революция UTF-8.
Однако несовместимость кодирования может сохраняться между приложениями, поэтому мы предложили вам некоторые инструменты для проверки формата ваших файлов, а также для просмотра невидимой метки порядка байтов. Кроме того, теперь вы знаете, как создавать некоторые файлы UTF-8 с или без спецификации через VBA.
Теперь у вас есть все инструменты, которые помогут диагностировать возможные проблемы с кодировкой, и вы можете сделать это, используя только некоторые стандартные инструменты!
Кодировка символов сейчас
ASCII и UTF-8 — две современные системы кодирования текста.Оба они описаны в этом видео с участием Кейтлин Мерри.
Два стандарта кодировки символов определяют, как символы декодируются из единиц и нулей в текст, который вы видите на экране прямо сейчас, и в различные языки, просматриваемые каждый день в Интернете. Эти два стандарта кодирования — ASCII и Unicode.
ASCII
Американский стандартный код для обмена информацией (ASCII) был разработан для создания международного стандарта кодирования латинского алфавита.В 1963 году был принят ASCII, чтобы информация могла интерпретироваться между компьютерами; представляющие нижние и верхние буквы, цифры, символы и некоторые команды. Поскольку ASCII кодируется с использованием единиц и нулей, система счисления с основанием 2, он использует семь битов. Семь битов позволяют
Семь битов позволяют 2 в степени 7 = 128 возможных комбинаций цифр для кодирования символа. Таким образом, ASCII обеспечил возможность кодирования 128 важных символов:
Как работает кодирование ASCII
- Вы уже знаете, как преобразовать денари и двоичные числа
- Теперь вам нужно преобразовать буквы в двоичные числа
- Каждому символу соответствует десятичное число (например, A → 65)
- ASCII использует 7 битов
- Мы используем первые 7 столбцов таблицы преобразования для создать 128 различных чисел (от 0 до 127)
Например, 1000001 дает нам число 65 ( 64 + 1 ), которое соответствует букве «А».Вот как ‘HELLO’ закодировано в ASCII в двоичном формате:
| Латинский символ | ASCII | ||
|---|---|---|---|
| H | 1001000 | ||
| E | 1000101 100138 | ||
| L | 1001100 | ||
| O | 1001111 |
Давайте применим эту теорию на практике:
- Откройте Блокнот или любой другой текстовый редактор, который вы предпочитаете
- Введите сообщение и сохраните его, e. грамм. «Данные прекрасны»
- Посмотрите размер файла — у меня 18 байт
- Теперь добавьте еще одно слово, например ‘data is SO beautiful’
- Если вы снова посмотрите на размер файла, вы увидите, что он изменился — мой файл теперь на 3 байта больше (SO [SPACE]: ‘S’, ‘O’ и пробел)
 грамм. «Данные прекрасны»
грамм. «Данные прекрасны»Unicode и UTF-8
Поскольку ASCII кодирует символы в 7-битном формате, переход к 8-битной вычислительной технологии означал, что нужно было использовать один дополнительный бит. С помощью этой дополнительной цифры Extended ASCII закодирует до 256 символов.Однако возникшая проблема заключалась в том, что страны, которые использовали разные языки, делали разные вещи с этой дополнительной возможностью кодирования. Многие страны добавляли свои собственные дополнительные символы, а разные числа представляли разные символы на разных языках. В Японии даже было создано несколько систем кодирования японского языка в зависимости от оборудования, и все эти методы были несовместимы друг с другом. Поэтому, когда сообщение было отправлено с одного компьютера на другой, полученное сообщение могло стать искаженным и нечитаемым; японские системы кодирования символов были настолько сложными, что даже когда сообщение отправлялось с одного типа японского компьютера на другой, происходило нечто, называемое «моджибаке»: проблема несовместимых систем кодирования стала более актуальной с изобретением всемирной паутины, поскольку люди делились цифровыми документами по всему миру, используя несколько языков.Для решения этой проблемы консорциум Unicode установил универсальную систему кодирования под названием Unicode . Unicode кодирует более 100000 символов, охватывая все символы, которые вы найдете в большинстве языков. Unicode присваивает каждому символу определенное число, а не двоичную цифру. Но с этим были некоторые проблемы, например:
Поэтому, когда сообщение было отправлено с одного компьютера на другой, полученное сообщение могло стать искаженным и нечитаемым; японские системы кодирования символов были настолько сложными, что даже когда сообщение отправлялось с одного типа японского компьютера на другой, происходило нечто, называемое «моджибаке»: проблема несовместимых систем кодирования стала более актуальной с изобретением всемирной паутины, поскольку люди делились цифровыми документами по всему миру, используя несколько языков.Для решения этой проблемы консорциум Unicode установил универсальную систему кодирования под названием Unicode . Unicode кодирует более 100000 символов, охватывая все символы, которые вы найдете в большинстве языков. Unicode присваивает каждому символу определенное число, а не двоичную цифру. Но с этим были некоторые проблемы, например:
- Для кодирования 100000 символов потребуется около 32 двоичных цифр. Unicode использует ASCII для английского языка, поэтому A по-прежнему 65. Однако в 32-битной кодировке двоичное представление буквы A будет 000000000000000000000000000000000001000001. Это тратит много ценного пространства!
- Многие старые компьютеры интерпретируют восемь нулей подряд (ноль) как конец строки символов. Таким образом, эти компьютеры не отправляли символы, идущие после восьми нулей подряд (они не отправляли бы A, если бы оно было представлено как 000000000000000000000000000000000001000001).
 Однако в 32-битной кодировке двоичное представление буквы A будет 000000000000000000000000000000000001000001. Это тратит много ценного пространства!
Однако в 32-битной кодировке двоичное представление буквы A будет 000000000000000000000000000000000001000001. Это тратит много ценного пространства! Метод кодирования Unicode UTF-8 решает следующие проблемы:
— До номера символа 128 используется обычное значение ASCII (например, A — 01000001)
— Для любого символа, превышающего 128, UTF-8 разделяет код на два байта и добавление «110» в начало первого байта, чтобы показать, что это начальный байт, и «10» в начале второго байта, чтобы показать, что он следует за первым байтом.Итак, для каждого символа после числа 128 у вас есть два байта:
[110xxxxx] [10xxxxxx]
И вы просто заполняете двоичное число между ними:
[11000101] [10000101] (это число 325 → 00101000101)
Это работает для первых 2048 символов.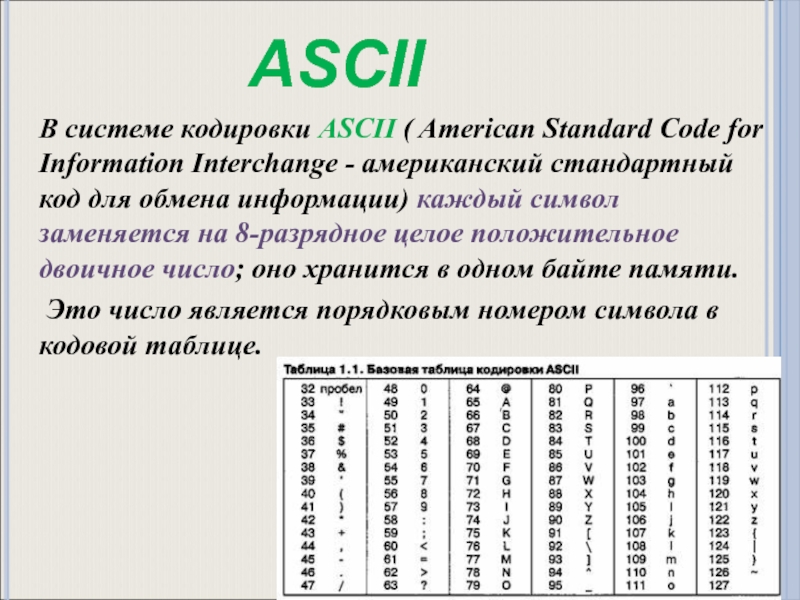 Для других символов в начале первого байта добавляется еще одна «1», а также используется третий байт:
Для других символов в начале первого байта добавляется еще одна «1», а также используется третий байт:
[1110xxxx] [10xxxxxx] [10xxxxxx]
Это дает вам 16 пробелов для двоичного кода.Таким образом, UTF-8 увеличивается до четырех байтов:
[11110xxx] [10xxxxxx] [10xxxxxx] [10xxxxxx]
. Таким образом, UTF-8 избегает проблем, упомянутых выше, а также требует индекса и он позволяет вам декодировать символы из двоичной формы в обратном направлении (т.е. он обратно совместим).
Мероприятия в классе
Есть много интересных занятий для обучения кодированию символов. Ниже мы включили два упражнения, которые вы можете попробовать в своем классе. Какие главные советы вы можете дать по обучению кодировке символов? Делитесь ими в комментариях!
- Перевод секретных сообщений : опубликуйте короткое секретное сообщение в ASCII разделе комментариев, а также переводите или отвечайте на сообщения ASCII других участников
- Двоичные браслеты : создавайте браслеты, используя разноцветные бусины для представления единиц и нулей и написания инициал или имя в ASCII
Что такое UTF-8? — Twilio
UTF-8 — это стандарт кодировки символов переменной ширины, который использует от одного до четырех восьмибитных байтов для представления всех допустимых кодовых точек Unicode. 21), более чем достаточно для покрытия текущих 1112 064 кодовых точек Unicode.
21), более чем достаточно для покрытия текущих 1112 064 кодовых точек Unicode.
Вместо символов на самом деле правильнее ссылаться на кодовых точек при обсуждении систем кодирования. Кодовые точки позволяют абстрагироваться от символа термина и являются элементарной единицей хранения информации при кодировании. Большинство кодовых точек представляют собой один символ, но некоторые представляют такую информацию, как форматирование.
UTF-8 — это стандарт кодирования «переменной ширины».Это означает, что он кодирует каждую кодовую точку с разным количеством байтов, от одного до четырех. В целях экономии места часто используемые кодовые точки представлены меньшим количеством байтов, чем редко появляющиеся кодовые точки.
Обратная совместимость с ASCII
UTF-8 использует один байт для представления кодовых точек от 0 до 127. Эти первые 128 кодовых точек Unicode взаимно однозначно соответствуют отображению символов ASCII, поэтому символы ASCII также являются допустимыми символами UTF-8.
Как работает UTF-8: пример
Первый байт UTF-8 указывает, сколько байтов будет следовать за ним.Затем биты кодовой точки «распределяются» по следующим байтам. Лучше всего это пояснить на примере:
Unicode присваивает французскую букву é кодовой точке U + 00E9. Это 11101001 в двоичном формате; он не является частью набора символов ASCII. UTF-8 представляет это восьмибитное число с использованием двух байтов.
Старшие биты обоих байтов содержат метаданные. Первый байт начинается с 110 . Единицы указывают, что это двухбайтовая последовательность, а 0 указывает, что за ней последуют биты кодовой точки.Второй байт начинается с 10, чтобы указать, что это продолжение последовательности UTF-8.
Это оставляет 11 «слотов» для битов кодовой точки. Помните, что для кодовой точки U + 00E9 требуется всего восемь бит. UTF-8 дополняет ведущие биты тремя 0 , чтобы полностью «заполнить» оставшиеся пробелы.
Результирующее представление UTF-8 для é (U + 00E9): 1100001110101001 .
Как Twilio обрабатывает символы UTF-8?
UTF-8 является доминирующей кодировкой во всемирной паутине, поэтому ваш код, скорее всего, закодирован по этому стандарту.
Для SMS-сообщений Twilio использует самый компактный из доступных методов кодирования. Twilio по умолчанию использует GSM-7 и возвращается к UCS-2, если ваше сообщение содержит символы, отличные от GSM-7. Использование стандартов кодирования GSM-7 и UCS-2 может повлиять на количество сегментов, необходимых для отправки вашего сообщения.
Twilio Copilot Smart Encoding автоматически определяет символы Юникода, которые легко пропустить, такие как умные кавычки (〞) или длинное тире (-), и заменяет их аналогичным символом. Благодаря этому количество сегментов сообщения и цены будут как можно более низкими.
Не беспокойтесь, если ваша строка в кодировке UTF-8 «Ooh làlà» будет доставлена по SMS — Программируемое SMS-сообщение Twilio поможет вам.
Основы Unicode — Документация ICU
Содержание
- Введение в Unicode
- Традиционные наборы символов и Unicode
- Глифы и символы
- Обзор Unicode
- Формы и схемы кодирования символов для Unicode
- Обзор UTF-16
- Обзор UTF-32
- Обзор SCSU
- Другие кодировки Unicode
- Программирование с использованием UTF
- Сериализованные форматы
- Стандарт Unicode — отраслевой стандарт
Обзор UTF-8
Введение в Unicode
стандарт, который точно определяет набор символов, а также небольшое количество кодировок для него.Это позволяет вам эффективно обрабатывать текст на любом языке. Это позволяет одному исполняемому файлу приложения работать для глобальной аудитории. ICU, как Java ™, Microsoft® Windows NT ™, Windows ™ 2000 и другие современные системы, предоставляет решения для интернационализации на основе Unicode.
Эта глава предназначена как введение в кодовые страницы в целом и Unicode в частности. Для получения дополнительной информации см .:
Для получения дополнительной информации см .:
Веб-сайт консорциума Unicode
Что такое Unicode?
IBM® Globalization
Перейдите к онлайн-демонстрациям ICU, чтобы увидеть, как серверное приложение на основе Unicode может обрабатывать текст на многих языках и во многих кодировках.
Традиционные наборы символов и Unicode
Представление данных в текстовом формате на компьютере — это вопрос определения набора символов и присвоения каждому из них числа и битового представления. В основе этой базовой идеи лежат три взаимосвязанных концепции:
Набор символов или репертуар — это неупорядоченный набор символов, который может быть представлен числовыми значениями.
Набор кодированных символов отображает символы из набора символов или репертуара в числовые значения.
Схема кодирования символов определяет представление числовых значений из одного или нескольких наборов кодированных символов в битах и байтах.
Для простых кодировок, таких как ASCII, последние две концепции в основном одинаковы: ASCII присваивает 128 символов и управляющие коды последовательным числам от 0 до 127. Эти символы и управляющие коды кодируются как простые двоичные целые числа без знака. Следовательно, ASCII — это и набор кодированных символов, и схема кодирования символов.
ASCII кодирует только 128 символов, 33 из которых являются управляющими кодами, а не графическими отображаемыми символами. Он был разработан для представления текста на английском языке для американской пользовательской базы и поэтому недостаточен для представления текста практически на любом языке, кроме американского английского. Фактически, большинство традиционных кодировок ограничивалось одним или несколькими языками и скриптами.
ASCII предлагал естественный способ его расширения: разработанный в 1960-х годах для работы в системах с 7-битными байтами, в то время как большинство компьютеров и интернет-протоколов с 1970-х годов использовали 8-битные байты, дополнительный бит позволял другим 128-байтовым значениям представлять больше символы. Были разработаны различные кодировки, поддерживающие разные языки. Некоторые из них были основаны на ASCII, другие — нет.
Были разработаны различные кодировки, поддерживающие разные языки. Некоторые из них были основаны на ASCII, другие — нет.
Для таких языков, как японский, необходимо кодировать значительно больше 256 символов. Различные схемы кодирования позволяют представлять большие наборы символов с тысячами или десятками тысяч символов. Большинство этих кодировок по-прежнему основаны на байтах, что означает, что для многих символов требуется два или более байта дискового пространства. Должен быть разработан процесс для интерпретации некоторых байтовых значений.
Различные наборы символов и схемы кодирования были разработаны независимо, охватывают только один или несколько языков каждый и несовместимы. Это делает очень трудным для одной системы обрабатывать текст на более чем одном языке одновременно, и особенно трудным делать это таким образом, чтобы обеспечить взаимодействие между различными системами.
Как правило, минимальное требование для интероперабельного обмена текстовыми данными состоит в том, что кодировка (набор символов и схема кодирования) должна быть правильно указана в документе и в протоколе.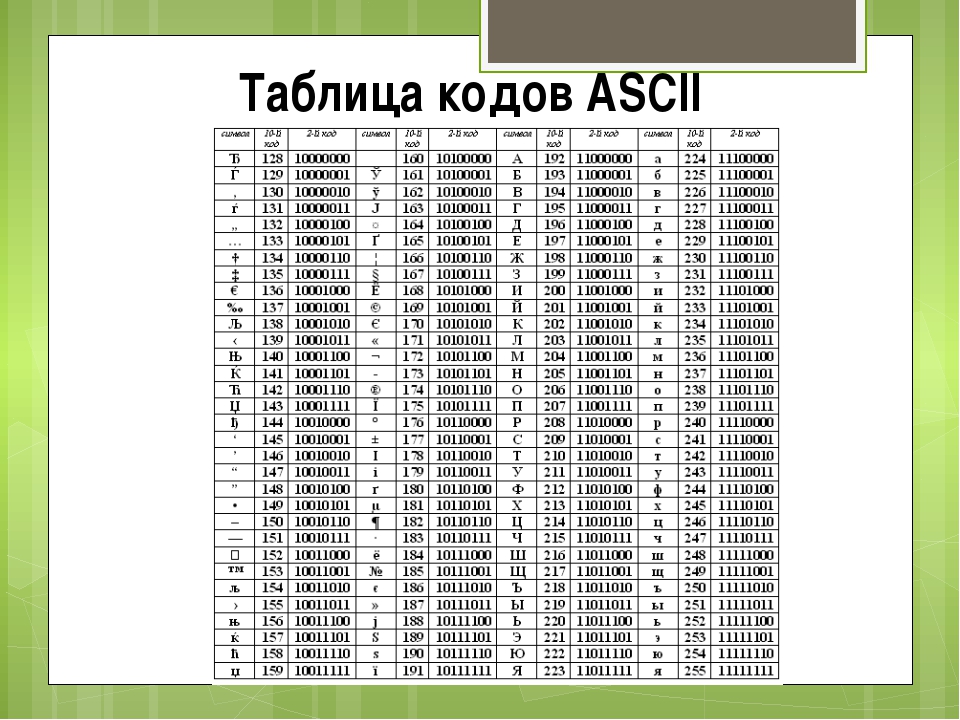 Например, электронная почта / SMTP и HTML / HTTP предоставляют средства для указания «кодировки», как это называется в стандартах Интернета. Однако очень часто кодировка не указывается, указывается неверно или отправитель и получатель расходятся во мнениях относительно ее реализации.
Например, электронная почта / SMTP и HTML / HTTP предоставляют средства для указания «кодировки», как это называется в стандартах Интернета. Однако очень часто кодировка не указывается, указывается неверно или отправитель и получатель расходятся во мнениях относительно ее реализации.
Схема кодирования ISO 2022 была создана для хранения текста на многих разных языках. Он позволяет встраивать другие кодировки, сначала объявляя их, а затем переключаясь между ними. Полная поддержка всех функций и возможных кодировок с ISO 2022 требует сложной обработки и необходимости поддерживать множество кодировок.Для восточноазиатских языков были разработаны подмножества, охватывающие только один язык или несколько одновременно, но с ними гораздо легче справиться. ISO 2022 плохо подходит для использования во внутренней обработке. Он предназначен для обмена данными.
Глифы и символы
Программистам часто нужно различать символы и глифы. Символ — это наименьшая смысловая единица в системе письма. Это абстрактное понятие, такое как буква А или восклицательный знак. Глиф — это визуальное представление одного или нескольких символов, которое часто зависит от соседних символов.
Это абстрактное понятие, такое как буква А или восклицательный знак. Глиф — это визуальное представление одного или нескольких символов, которое часто зависит от соседних символов.
Не всегда существует взаимно однозначное соответствие между символами и глифами. Во многих языках (арабский является ярким примером) внешний вид символа сильно зависит от окружающих символов. Стандартный печатный арабский язык имеет до четырех различных печатных изображений (глифов) для каждой буквы алфавита. Во многих языках две или более буквы могут объединяться в один глиф (называемый лигатурой), или один символ может отображаться с несколькими глифами.
Несмотря на различные визуальные варианты конкретной буквы, она по-прежнему сохраняет свою идентичность.Например, арабская буква хе обычно используется в четырех различных визуальных представлениях. Какую бы из них ни использовали, она по-прежнему сохраняет свою идентичность как буква хе. Юникод кодирует именно эту идентичность, а не визуальное представление. Это также сокращает количество требуемых независимых значений символов.
Это также сокращает количество требуемых независимых значений символов.
Обзор Unicode
Unicode был разработан как набор символов с одним кодом, который поддерживает все языки мира. Первая версия Unicode использовала 16-битные числа, что позволяло кодировать 65 536 символов без сложных многобайтовых схем.С включением большего количества символов и в соответствии с потребностями реализации многих различных платформ, Unicode был расширен, чтобы разрешить более одного миллиона символов. Было добавлено несколько других схем кодирования. Это внесло больше сложности в стандарт Unicode, но гораздо меньше, чем управление большим количеством различных кодировок.
Начиная с Unicode 2.0 (опубликованного в 1996 г.), стандарт Unicode начал назначать числа от 0 до 10ffff 16 , что требует 21 бит, но не использует их полностью.Этого места более чем достаточно для всех письменных языков мира. Первоначальный репертуар охватывал все основные языки, обычно используемые в вычислительной технике.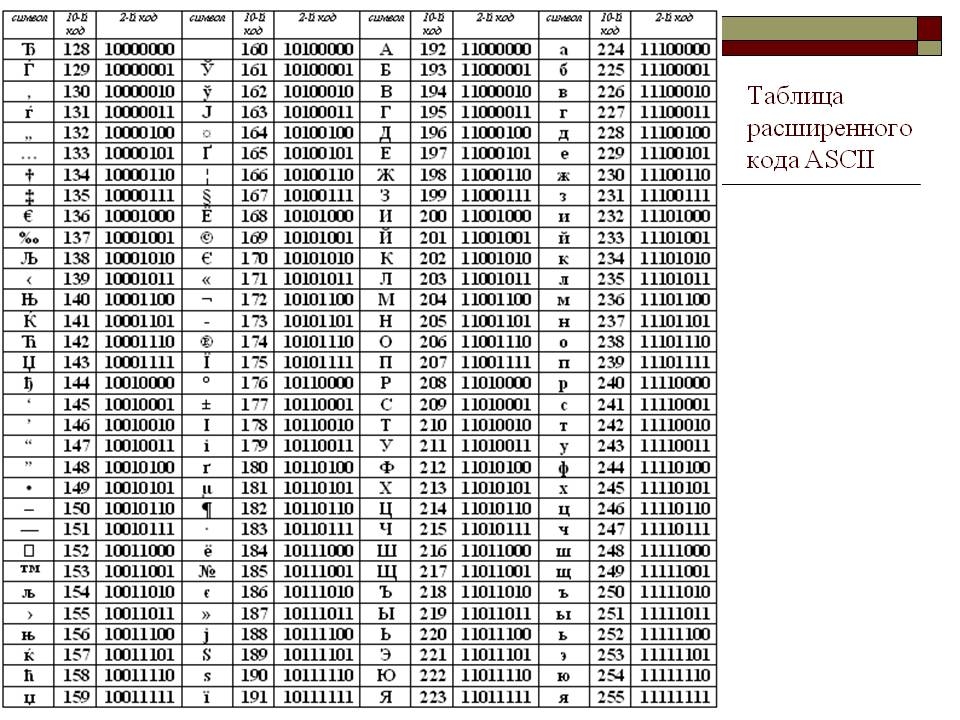 Unicode продолжает расти, и он включает больше скриптов.
Unicode продолжает расти, и он включает больше скриптов.
Дизайн Unicode несколько отличается от традиционных наборов символов и схем кодирования:
Его репертуар позволяет пользователям эффективно включать текст почти на всех языках в один документ.
Его можно закодировать побайтовым способом с одним или несколькими байтами на символ, но в схеме кодирования по умолчанию используются 16-битные блоки, которые позволяют намного упростить обработку всех распространенных символов.
Многие символы, такие как буквы с диакритическими знаками и умляуты, можно комбинировать с помощью базового символа и модификаторов ударения или умляута. Такое объединение уменьшает количество различных символов, которые необходимо кодировать отдельно. «Предварительно составленные» варианты символов, существовавшие в то время в общих наборах символов, были включены для совместимости.
Персонажи и их использование четко определены и описаны.
В то время как традиционные наборы символов обычно предоставляют только имя или изображение символа, его номер и байтовую кодировку, Unicode имеет обширную базу данных свойств, доступных для загрузки.Он также определяет ряд процессов и алгоритмов для работы со многими аспектами обработки текста, чтобы сделать его более совместимым.
 В то время как традиционные наборы символов обычно предоставляют только имя или изображение символа, его номер и байтовую кодировку, Unicode имеет обширную базу данных свойств, доступных для загрузки.Он также определяет ряд процессов и алгоритмов для работы со многими аспектами обработки текста, чтобы сделать его более совместимым.
В то время как традиционные наборы символов обычно предоставляют только имя или изображение символа, его номер и байтовую кодировку, Unicode имеет обширную базу данных свойств, доступных для загрузки.Он также определяет ряд процессов и алгоритмов для работы со многими аспектами обработки текста, чтобы сделать его более совместимым.Раннее включение всех символов из часто используемых наборов символов делает Unicode полезной «точкой поворота» для преобразования между традиционными наборами символов и позволяет обрабатывать текст, не относящийся к Unicode, сначала конвертируя в Unicode, обрабатывая текст, и преобразовать его обратно в исходную кодировку без потери данных.
Первые 128 значений кодовой точки Unicode назначаются тем же символам, что и в US-ASCII.Например, один и тот же номер присваивается одному и тому же персонажу. То же самое верно для первых 256 значений кодовых точек Unicode по сравнению с ISO 8859-1 (Latin-1), который сам является прямым надмножеством US-ASCII.
 Это упрощает адаптацию многих приложений к Unicode, поскольку номера для многих синтаксически важных символов одинаковы.
Это упрощает адаптацию многих приложений к Unicode, поскольку номера для многих синтаксически важных символов одинаковы. Формы и схемы кодирования символов для Unicode
Unicode присваивает символам номера от 0 до 10FFFF 16 , оставляя достаточно места для однозначного кодирования каждого обычного символа.Такой номер символа называется «кодовой точкой».
Кодовые точки Unicode — это просто неотрицательные целые числа в определенном диапазоне. У них нет неявного двоичного представления или ширины 21 или 32 бита. Для форм кодирования определены двоичное представление и ширина единицы.
Для внутренней обработки стандарт определяет три формы кодирования, а для хранения файлов и протоколов некоторые из этих форм кодирования имеют схемы кодирования, которые различаются порядком байтов.Разница между формой кодирования и схемой кодирования заключается в том, что форма кодирования отображает коды набора символов в значения, которые соответствуют внутренним типам данных (например, сокращение в C), тогда как схема кодирования сопоставляется с битами и байтами. Для традиционных кодировок они одинаковы, поскольку формы кодирования уже отображаются в байтах.
Для традиционных кодировок они одинаковы, поскольку формы кодирования уже отображаются в байтах.
Различные формы кодировки Unicode оптимизированы для множества различных целей:
UTF-16, форма кодирования по умолчанию, отображает точку кода символа в одно или два 16-битных целых числа.
UTF-8 — это байтовая кодировка, обеспечивающая обратную совместимость с основанными на ASCII, байтовыми API и протоколами. Символ хранится в 1, 2, 3 или 4 байтах.
UTF-32 — это простейшая, но наиболее требовательная к памяти форма кодирования: в ней используется одно 32-битное целое число на каждый символ Unicode.
SCSU — это схема кодирования, которая обеспечивает простое сжатие текста Unicode. Он предназначен только для ввода и вывода, а не для внутреннего использования.
ICU внутренне использует UTF-16. ICU 2.0 полностью поддерживает дополнительные символы (с кодовыми точками 10000 16 ..10FFFF 16 ).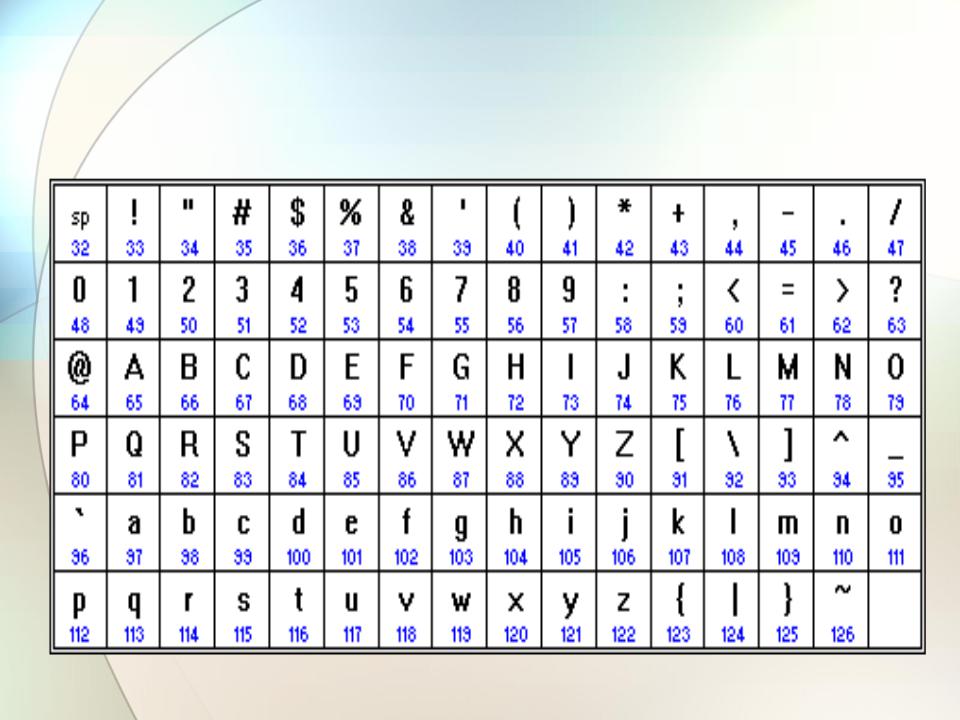 Более старые версии ICU обеспечивали только частичную поддержку дополнительных символов.
Более старые версии ICU обеспечивали только частичную поддержку дополнительных символов.
Для ввода / вывода схемы кодирования символов определяют байтовую сериализацию текста. UTF-8 сам по себе является и формой кодирования, и схемой кодирования, потому что он основан на байтах. Для каждого из UTF-16 и UTF-32 определены два варианта: один, который сериализует кодовые единицы в порядке байтов с прямым порядком байтов (наиболее значимый байт первым), и другой, который сериализует единицы кода в порядке байтов с прямым порядком байтов ( младший байт первым).Соответствующие схемы кодирования называются UTF-16BE, UTF-16LE, UTF-32BE и UTF-32LE.
Имена «UTF-16» и «UTF-32» неоднозначны. В зависимости от контекста они относятся либо к формам кодирования символов, в которых обрабатываются 16/32-битные слова и естественным образом хранятся в порядке байтов платформы, либо они относятся к зарегистрированным IANA именам кодировок, то есть к схемам кодирования символов или сериализации байтов.
 Помимо простой байтовой сериализации, наборы символов с этими именами также используют необязательные метки порядка байтов (см. Сериализованные форматы ниже).
Помимо простой байтовой сериализации, наборы символов с этими именами также используют необязательные метки порядка байтов (см. Сериализованные форматы ниже).Обзор UTF-16
Стандартная форма кодирования стандарта Unicode использует 16-битные кодовые единицы. Значения кодовых точек для наиболее распространенных символов находятся в диапазоне от 0 до FFFF 16 и кодируются только одной 16-битной единицей того же значения. Кодовые точки от 10000 16 до 10FFFF 16 кодируются двумя кодовыми единицами, которые часто называют «суррогатами», и они называются «суррогатной парой», когда вместе они правильно кодируют один символ Unicode.Первый суррогат в паре должен находиться в диапазоне от D800 16 до DBFF 16 , а второй должен находиться в диапазоне от DC00 16 до DFFF 16 . Каждая кодовая точка Unicode имеет только одну возможную кодировку UTF-16 либо с одной кодовой единицей, которая не является суррогатом, либо с правильной парой суррогатов. Значения кодовой точки от D800 16 до DFFF 16 зарезервированы только для этого механизма и никогда не будут сами по себе присвоены никаким символам.
Значения кодовой точки от D800 16 до DFFF 16 зарезервированы только для этого механизма и никогда не будут сами по себе присвоены никаким символам.
Наиболее часто используемые символы имеют кодовые точки ниже FFFF 16 , но Unicode 3.1 назначает более 40 000 дополнительных символов, которые используют суррогатные пары в UTF-16.
Обратите внимание, что сравнение строк UTF-16 лексически на основе их 16-битных кодовых единиц не приводит к тому же порядку, что и сравнение кодовых точек. Обычно это не проблема, поскольку затрагиваются только редко используемые символы. Большинство процессов не полагаются на одни и те же результаты при таких сравнениях. При необходимости можно выполнить простую модификацию сравнения строк, которая по-прежнему позволяет проводить эффективные сравнения на основе кодовых единиц и делает их совместимыми со сравнениями кодовых точек.Для этого в ICU есть API-функции C и C ++.
Обзор UTF-8
Чтобы удовлетворить требованиям побайтовых систем на основе ASCII, стандарт Unicode определяет UTF-8.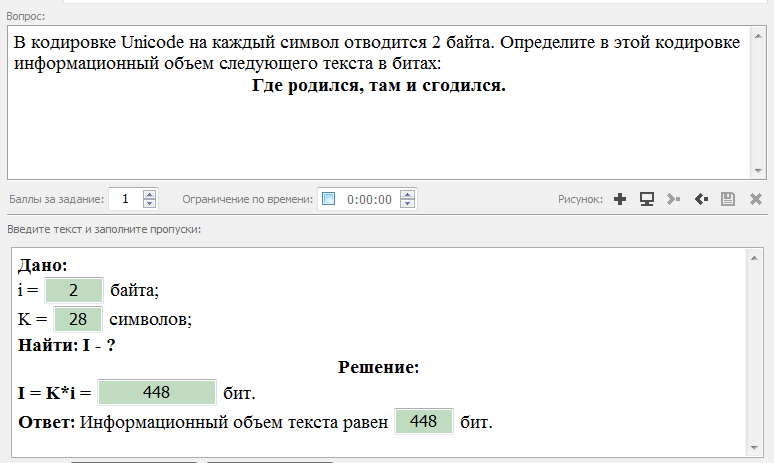 UTF-8 — это байтовая кодировка переменной длины, которая сохраняет прозрачность ASCII.
UTF-8 — это байтовая кодировка переменной длины, которая сохраняет прозрачность ASCII.
UTF-8 поддерживает прозрачность для всех значений кода ASCII (0..127). Эти значения не появляются ни в одном байте преобразованного результата, за исключением прямого представления значений ASCII. Таким образом, текст ASCII также является текстом UTF-8.
Характеристики UTF-8 включают:
Кодовые точки Unicode от 0 до 7F 16 каждая кодируется одним байтом с одинаковым значением. Следовательно, символы ASCII занимают на 50% меньше места в кодировке UTF-8, чем в UTF-16.
Все остальные кодовые точки кодируются многобайтовыми последовательностями, причем первый байт (ведущий байт) указывает количество следующих за ним байтов (конечные байты). Это приводит к очень эффективному синтаксическому анализу. Старшие байты находятся в диапазоне от c0 16 до fd 16 , конечные байты находятся в диапазоне от 80 16 до bf 16 .
Значения байтов fe 16 и FF 16 никогда не используются.UTF-8 относительно компактен и экономичен в использовании байтов, необходимых для кодирования текста в европейских сценариях, но для восточноазиатского текста использует на 50% больше места, чем UTF-16. Кодовые точки до 7FF 16 занимают два байта, кодовые точки до FFFF 16 занимают три (на 50% больше памяти, чем UTF-16), а все остальные четыре.
Двоичное сравнение строк UTF-8 на основе их байтов приводит к тому же порядку, что и сравнение значений кодовой точки.
 Значения байтов fe 16 и FF 16 никогда не используются.
Значения байтов fe 16 и FF 16 никогда не используются.Обзор UTF-32
В кодировке UTF-32 всегда используется одно 32-битное целое число для каждой кодовой точки Unicode. Это приводит к очень простому кодированию.
Недостатком является потребление памяти: поскольку значения кодовой точки используют только 21 бит, одна треть памяти всегда не используется, а поскольку наиболее часто используемые символы имеют значения кодовой точки до FFFF 16 , они занимают только один 16-битный блок в UTF-16 (на 50% меньше) и до трех байтов в UTF-8 (на 25% меньше).
UTF-32 в основном используется в API, которые определены с одним и тем же типом данных как для кодовых точек, так и для кодовых единиц. Современные версии стандартной библиотеки C, поддерживающие Unicode, используют 32-битный wchar_t с семантикой UTF-32.
Обзор SCSU
SCSU (Стандартная схема сжатия для Unicode) предназначена для уменьшения размера текста Unicode для ввода и вывода. Это простое сжатие, преобразующее текст в поток байтов. Обычно он использует один байт на символ в маленьких скриптах и два байта на символ в больших восточноазиатских скриптах.
Обычно он короче любого из UTF. Однако SCSU сохраняет состояние, что делает его непригодным для внутренней обработки. Он также использует все возможные байтовые значения, что может потребовать дополнительной обработки для таких протоколов, как SMTP (электронная почта).
См. Также https://www.unicode.org/reports/tr6/.
Другие кодировки Unicode
Другие кодировки Unicode со временем разрабатывались для различных целей. Большинство из них реализовано в ICU, см. Source / data / mappings / convrtrs.txt
Большинство из них реализовано в ICU, см. Source / data / mappings / convrtrs.txt
BOCU-1: двоично-упорядоченное сжатие Unicode Кодирование Unicode, которое примерно так же компактно, как SCSU, но имеет гораздо меньшее количество состояний. В отличие от SCSU, он сохраняет порядок кодовых точек и может использоваться в 8-битных электронных письмах без кодирования передачи. BOCU-1 не , а не сохраняет символы ASCII в ASCII-читаемой форме. См. Техническое примечание Unicode №6.
UTF-7: предназначен для 7-битных писем; простой и не очень компактный. Поскольку почтовые системы были 8-битными безопасными в течение нескольких лет, UTF-7 больше не нужен и не рекомендуется.Большинство символов ASCII читаются, другие закодированы в base64. См. RFC 2152.
IMAP-mailbox-name: вариант UTF-7, который подходит для выражения строк Unicode как символов ASCII для имен файлов Unix. Имя «IMAP-mailbox-name» специфично для ICU! См.
RFC 2060 ПРОТОКОЛ ДОСТУПА К ИНТЕРНЕТ-СООБЩЕНИЯМ — ВЕРСИЯ 4rev1, раздел 5.1.3. Международное соглашение об именах почтовых ящиков.UTF-EBCDIC: дружественная к EBCDIC кодировка, похожая на UTF-8.См. Технический отчет по Unicode №16. Начиная с ICU 2.6, UTF-EBCDIC не реализован в ICU.
CESU-8: схема кодирования совместимости для UTF-16: 8-бит Несовместимый вариант UTF-8, который сохраняет порядок строк в 16-битном Unicode (UTF-16) вместо порядка кодовых точек. Не для открытого обмена. См. Технический отчет по Unicode № 26.
 RFC 2060 ПРОТОКОЛ ДОСТУПА К ИНТЕРНЕТ-СООБЩЕНИЯМ — ВЕРСИЯ 4rev1, раздел 5.1.3. Международное соглашение об именах почтовых ящиков.
RFC 2060 ПРОТОКОЛ ДОСТУПА К ИНТЕРНЕТ-СООБЩЕНИЯМ — ВЕРСИЯ 4rev1, раздел 5.1.3. Международное соглашение об именах почтовых ящиков.Программирование с использованием UTF
Программирование с использованием любого из UTF намного проще, чем с традиционными многобайтовыми кодировками символов, хотя UTF-8 и UTF-16 также являются кодировками переменной ширины.
В каждой форме кодирования Unicode значения кодовых единиц для одиночных элементов (кодовых единиц, которые только кодируют символы), ведущих единиц и конечных единиц не связаны. Это имеет решающее значение для реализации. Ниже перечислены эти последствия:
Это имеет решающее значение для реализации. Ниже перечислены эти последствия:
Определяет количество единиц для одной кодовой точки с использованием ведущей единицы. Это особенно важно для UTF-8, где на символ может быть до 4 байтов.
Определяет границы.Если пользователи ICU получают произвольный доступ к тексту, вы всегда можете определить ближайшие границы кодовой точки с помощью небольшого количества машинных инструкций.
Не имеет перекрытий. Если пользователи ICU ищут строку A в строке B, вы никогда не получите ложное совпадение по кодовым точкам. Пользователям не нужно преобразовывать в кодовые точки для поиска строк. Ложные совпадения никогда не встречаются, поскольку конец одной последовательности никогда не совпадает с началом другой последовательности. Перекрытие — одна из самых больших проблем с распространенными многобайтовыми кодировками, такими как Shift-JIS.Все UTF избегают этой проблемы.
Использует простую итерацию.
Получить следующую или предыдущую кодовую точку несложно и требуется лишь небольшое количество машинных инструкций.Может использовать кодировку UTF-16, которая фактически полностью симметрична. Пользователи ICU могут определить по любой отдельной кодовой единице, является ли она первой, последней или единственной для кодовой точки. Перемещение (итерация) текста UTF-16 в любом направлении выполняется одинаково быстро и эффективно.
Использует медленную индексацию по кодовым точкам.Эта процедура индексации является недостатком всех кодировок переменной ширины. За исключением UTF-32, неэффективно найти границы кодовой единицы, соответствующие n-й кодовой точке, или найти смещение кодовой точки, содержащее n-ю кодовую единицу. Оба включают сканирование от начала текста или от последней известной границы. ICU, как и большинство распространенных API, всегда индексирует по единицам кода. Он считает единицы кода, а не точки кода.
 Получить следующую или предыдущую кодовую точку несложно и требуется лишь небольшое количество машинных инструкций.
Получить следующую или предыдущую кодовую точку несложно и требуется лишь небольшое количество машинных инструкций. Преобразование между различными UTF выполняется очень быстро. В отличие от преобразования в устаревшие кодировки, такие как Latin-2, преобразование между UTF не требует просмотра таблиц.
В отличие от преобразования в устаревшие кодировки, такие как Latin-2, преобразование между UTF не требует просмотра таблиц.
ICU предоставляет два основных определения типа данных для Unicode. UChar32 — это 32-битный тип кодовых точек, используемый для одиночных символов Юникода. Он может быть подписанным или неподписанным. Это то же самое, что wchar_t , если его ширина составляет 32 бита. UChar — это 16-разрядное целое число без знака для кодовых единиц UTF-16. Это базовый тип для строк ( UChar * ), и он такой же, как wchar_t , если его ширина составляет 16 бит.
Некоторые высокоуровневые API-интерфейсы, особенно используемые для форматирования, используют символы, близкие к представлению глифа.Такие «пользовательские символы» также называются «графемами» или «кластерами графем» и требуют строк, чтобы можно было включать комбинирующие последовательности.
Сериализованные форматы
В файлах, входных, выходных и сетевых протоколах текст должен сопровождаться спецификацией схемы кодировки символов, чтобы клиент мог правильно его интерпретировать. (В Интернет-протоколах это называется «кодировкой».) Однако спецификация схемы кодирования не требуется, если текст используется только в рамках одной платформы, протокола или приложения, где в остальном ясно, какова кодировка.(Язык и направленность текста обычно должны быть указаны для включения проверки орфографии, преобразования текста в речь и т. Д.)
(В Интернет-протоколах это называется «кодировкой».) Однако спецификация схемы кодирования не требуется, если текст используется только в рамках одной платформы, протокола или приложения, где в остальном ясно, какова кодировка.(Язык и направленность текста обычно должны быть указаны для включения проверки орфографии, преобразования текста в речь и т. Д.)
Обсуждение спецификаций кодирования в этом разделе относится к стандартным Интернет-протоколам, в которых используются строки имен кодировки. Другие протоколы могут использовать идентификаторы числового кодирования и назначать этим идентификаторам семантику, отличную от интернет-протоколов.
Обычно спецификация кодирования выполняется в зависимости от протокола и формата документа.Однако стандарт Unicode предлагает механизм маркировки текстовых файлов «подписью» для случаев, когда протоколы не идентифицируют схемы кодирования символов.
Символ ZERO WIDTH NO-BREAK SPACE (FEFF 16 ) можно использовать в качестве подписи, добавив его к файлу или потоку. Альтернативная функция U + FEFF в качестве символа управления форматом была скопирована в U + 2060 WORD JOINER, а U + FEFF следует использовать только для подписей Unicode.
Альтернативная функция U + FEFF в качестве символа управления форматом была скопирована в U + 2060 WORD JOINER, а U + FEFF следует использовать только для подписей Unicode.
Различные схемы кодирования символов генерируют разные последовательности байтов для U + FEFF:
UTF-8: EF BB BF
UTF-16BE: FE FF
UTF-16LE: FF FE
UTF-32BE: 00 00 FE FF
UTF-32LE: FF FE 00 00
SCSU: 0E FE FF
BOCU-1: FB EE 28
UTF-7: 2B 2F 76 (38 39 2B 2F) - UTF-EBCDIC: DD 73 66 73
ICU обеспечивает функцию ucnv_detectUnicode signature для обнаружения подписи Unicode.
Для CESU-8 нет отдельной подписи от подписи для UTF-8. UTF-8 и CESU-8 кодируют U + FEFF и фактически все кодовые точки BMP с одинаковыми байтами. Возможность ошибочной идентификации одного как другого является одной из причин, по которой CESU-8 следует использовать только в ограниченных, закрытых, конкретных средах.
В UTF-16 и UTF-32, где подпись также различает порядок байтов с прямым и обратным порядком байтов, она также называется меткой порядка байтов (BOM). Подпись работает для UTF-16, поскольку кодовая точка, имеющая кодировку с заменой байтов, FFFE 16 , никогда не будет допустимым символом Unicode.(Это «несимвольный» код.) В интернет-протоколах, если используется спецификация кодирования «UTF-16» или «UTF-32», ожидается наличие байтовой последовательности подписи (BOM), которая определяет порядок байтов, что не относится к именам схемы кодирования / кодировки с «BE» или «LE».
Если указано, что текст должен быть закодирован в кодировке UTF-16 или UTF-32 и не начинается с спецификации, тогда он должен интерпретироваться как UTF-16BE или UTF-32BE соответственно.
Подпись не является частью содержимого и должна быть удалена при обработке.Например, слепое соединение двух файлов даст неверный результат.
Если подпись была обнаружена, то «символ» подписи U + FEFF должен быть удален из потока Unicode после преобразования .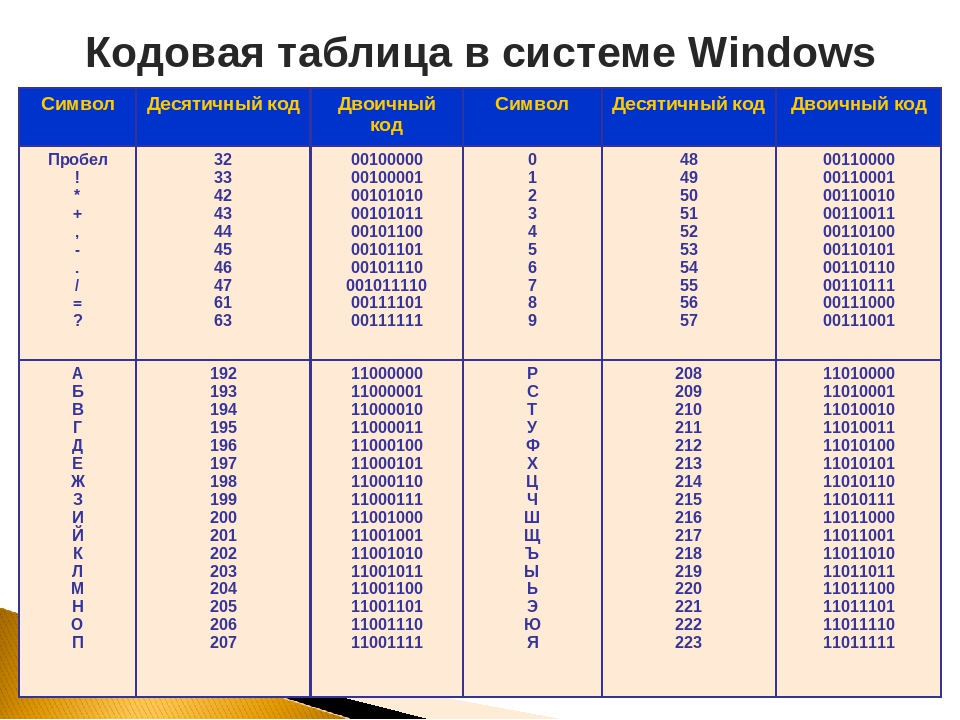 Удаление байтов подписи перед преобразованием может привести к сбою преобразования для кодировок с отслеживанием состояния, таких как BOCU-1 и UTF-7.
Удаление байтов подписи перед преобразованием может привести к сбою преобразования для кодировок с отслеживанием состояния, таких как BOCU-1 и UTF-7.
Распознавать подпись или нет, зависит от протокола или приложения.
Если протокол определяет имя набора символов, то поток байтов должен интерпретироваться в соответствии с тем, как это имя определено.Только имена «UTF-16» и «UTF-32» включают распознавание меток порядка байтов, характерных для них (и преобразователи ICU для этих имен делают это автоматически). Ни один из других наборов символов Unicode не определен для включения какой-либо обработки подписи / спецификации.
Если имя кодировки не указано, например, для текстовых файлов в большинстве файловых систем, то приложения обычно должны полагаться на эвристику для определения кодировки файла. Многие форматы документов содержат встроенное или неявное объявление кодировки, но для простых текстовых файлов разумно использовать подписи Unicode в качестве простой и надежной эвристики.
Это особенно часто встречается в системах Windows. Однако некоторые инструменты для обработки текстовых файлов (например, многие инструменты командной строки Unix) не подготовлены для подписей Unicode.
 Это особенно часто встречается в системах Windows. Однако некоторые инструменты для обработки текстовых файлов (например, многие инструменты командной строки Unix) не подготовлены для подписей Unicode.
Это особенно часто встречается в системах Windows. Однако некоторые инструменты для обработки текстовых файлов (например, многие инструменты командной строки Unix) не подготовлены для подписей Unicode.Стандарт Unicode является отраслевым стандартом
Стандарт Unicode является отраслевым стандартом и аналогичен ISO 10646-1. Примерно в 1993 году эти два стандарта были объединены в один и тот же стандарт набора символов. Оба стандарта имеют одинаковый репертуар символов и одинаковые формы и схемы кодирования.
Одно отличие заключалось в том, что стандарт ISO определял значения кодовой точки от 0 до 7FFFFFFF 16 , а не только до 10FFFF 16 . Рабочая группа ISO решила добавить поправку к стандарту. Поправка устраняет это различие, объявляя, что никаким символам никогда не будут назначены кодовые точки выше 10FFFF 16 . Основная причина решения рабочей группы ISO - совместимость между UTF. UTF-16 не может кодировать какие-либо кодовые точки выше этого предела.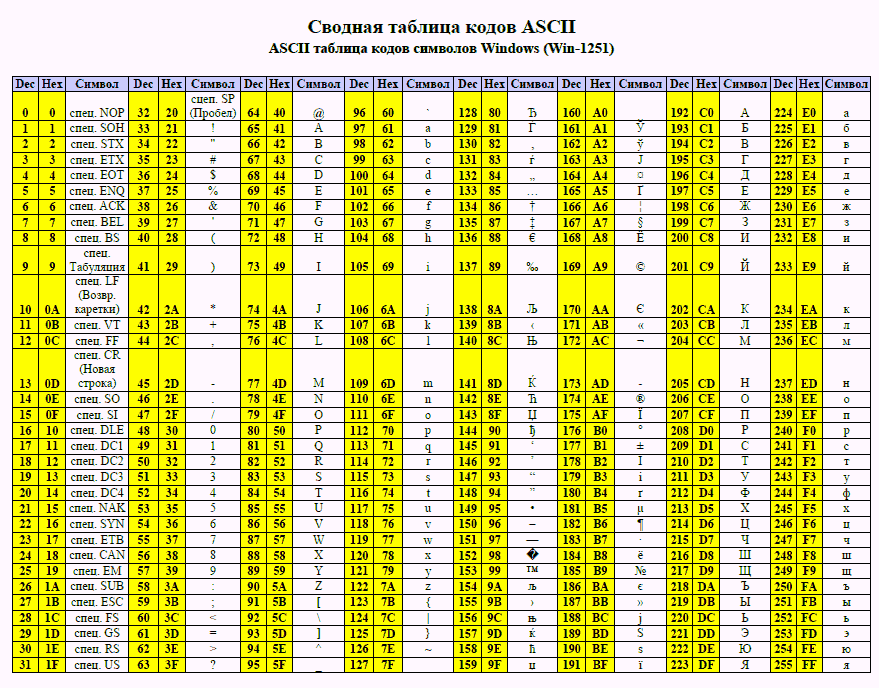
Это означает, что пространство кодовых точек для Unicode и ISO 10646 теперь одинаково! Эти изменения в ISO 10646 были внесены недавно и должны быть внесены в редакцию ISO 10646: 2003, которая также объединяет все части стандарта в одну.
Первое, большее пространство кода является причиной того, почему определение ISO для UTF-8 определяет последовательности из пяти и шести байтов для покрытия всего этого диапазона.
Еще одно отличие состоит в том, что стандарт ISO определяет формы кодирования «UCS-4» и «UCS-2».UCS-4 - это, по сути, UTF-32 с теоретическим верхним пределом 7FFFFFFF 16 , используя 31 бит из 32. Однако на практике комитет ISO согласился с тем, что символы выше 10FFFF не будут кодироваться, поэтому по существу нет разницы между формами. «4» означает «четырехбайтовая форма».
UCS-2 - это подмножество UTF-16, которое ограничено кодовыми точками от 0 до FFFF, за исключением суррогатных кодовых точек. Таким образом, он не может представлять символы с кодовыми точками выше FFFF (называемые дополнительными символами).
Преобразование между UCS-2 и UTF-16 не требуется. Разница только в трактовке суррогатов.
Стандарты различаются по типу информации, которую они предоставляют: стандарт Unicode предоставляет больше свойств символов и описывает алгоритмы и т. Д., В то время как стандарт ISO определяет коллекции, подмножества и т.п.
Стандарты синхронизируются, и соответствующие комитеты работают вместе, чтобы добавлять новые символы и назначать значения кодовых точек.
К началу
© 2016 и более поздние версии: Unicode, Inc. и другие. Лицензия и условия использования: http://www.unicode.org/copyright.html
Введение в Unicode и UTF-8
Unicode - это отраслевой стандарт последовательного кодирования письменного текста .
Существует множество наборов символов, которые используются компьютерами, но Unicode является первым в своем роде, нацеленным на поддержку каждого письменного языка на Земле (и за его пределами!).
Его цель - предоставить уникальный номер для идентификации каждого символа для каждого языка на любой платформе.
Unicode отображает каждый символ в определенный код, называемый кодовой точкой . Кодовая точка принимает форму U + , в диапазоне от U + 0000 до U + 10FFFF .
Пример кода выглядит так: U + 004F . Его значение зависит от используемой кодировки символов.
Unicode определяет различных кодировок символов , наиболее часто используемые из которых - UTF-8, UTF-16 и UTF-32.
UTF-8 определенно является самой популярной кодировкой в семействе Unicode, особенно в Интернете. Этот документ написан, например, в UTF-8.
В настоящее время реализовано более 135 000 различных символов с пространством для более чем 1,1 миллиона.
Скрипты
Все символы, поддерживаемые Unicode, сгруппированы в разделы, называемые сценариями .
Для каждого набора символов существует сценарий:
- Латиница (содержит все символы ASCII + все остальные символы западного мира)
- Корейский
- Старовенгерский
- Еврейский
- Греческий
- Армянский
- … и так далее!
Полный список определен в стандарте ISO 15924.
Подробнее о скриптах: https://en.wikipedia.org/wiki/Script_(Unicode)
Самолеты
Помимо скриптов, есть еще один способ организации символов Unicode: самолетов .
Вместо того, чтобы группировать их по типу, он проверяет значение кодовой точки:
| Самолет | Диапазон |
|---|---|
| 0 | U + 0000 - U + FFFF |
| 1 | U + 10000 - U + 1FFFF |
| 2 | U + 20000 - U + 2FFFF |
| … | … |
| 14 | U + E0000 - U + EFFFF |
| 15 | U + F0000 - U + FFFFF |
| 16 | U + 100000 - U + 10FFFF |
Всего 17 самолетов.
Первый - особенный, он называется Basic Multilingual Plane или BMP и содержит большинство современных символов и символов из латинского, кириллического и греческого алфавитов.
Остальные 16 планов называются астральными планами . Стоит отметить, что самолеты с 3 по 13 в настоящее время пустуют.
Кодовые точки, содержащиеся в астральных планах, называются астральными кодовыми точками .
Астральные кодовые точки - это все точки выше U + 10000 .
Кодовые единицы
кодовых точек хранятся внутри как кодовых единиц . Единица кода - это битовое представление символа, длина которого зависит от кодировки
.
UTF-32 использует 32-битную кодовую единицу.
UTF-8 использует 8-битную кодовую единицу, а UTF-16 использует 16-битную кодовую единицу. Если для кодовой точки требуется больший размер, она будет представлена двумя (или более в UTF-8) кодовыми единицами.
Графемы
Графема - это символ, который представляет собой единицу системы письма.По сути, это ваша идея персонажа и того, как он должен выглядеть.
Символы
Глиф - это графическое представление графемы: то, как она визуально отображается на экране, фактический вид на дисплее.
Последовательности
Unicode позволяет комбинировать разные символы для формирования графемы.
Например, это случай символов с диакритическими знаками: буква é может быть выражена с помощью комбинации буквы e ( U + 0065 ) и символа Юникода с именем «COMBINING ACUTE ACCENT» ( U + 0301 ):
"U + 0065U + 0301" ➡️ "é"
U + 0301 в этом случае - это то, что описывается как объединяющая метка , один символ, который применяется к предыдущему, чтобы сформировать другую графему.
Нормализация
Символы иногда могут быть представлены с использованием различных комбинаций кодовых точек.
Например, это случай символов с диакритическими знаками: буква é может быть выражена как U + 00E9 , а также как комбинация e ( U + 0065 ) и символа Юникода с именем «COMBINING ACUTE ACCENT» ( U + 0301 ):
U + 00E9 ➡️ "é"
U + 0065U + 0301 ➡️ "é"
Процесс нормализации анализирует строку на предмет неоднозначности такого рода и генерирует строку с каноническим представлением любого символа.
Без нормализации абсолютно одинаковые для глаза строки будут считаться разными, потому что их внутреннее представление изменяется:
смайлики
Emojis - это символы астрального плана Unicode, и они позволяют отображать изображения на экране без реальных изображений, только глифы шрифта.
Например, символ 🐶 кодируется как U + 1F436 .
Первые 128 символов
Первые 128 символов Unicode совпадают с набором символов ASCII.
Первые 32 символа, U + 0000 - U + 001F (0-31) называются контрольными кодами .
Они унаследовали от прошлого, и большинство из них уже устарели. Они использовались для телетайпов, которые существовали до факсов.
Символы от U + 0020 (32) до U + 007E (126) содержат цифры, буквы и некоторые символы:
| Юникод | код ASCII | Глиф |
|---|---|---|
| U + 0020 | 32 | (пробел) |
| U + 0021 | 33 | ! |
| U + 0022 | 34 | “ |
| U + 0023 | 35 | # |
| U + 0024 | 36 | $ |
| U + 0025 | 37 | % |
| U + 0026 | 38 | и |
| U + 0027 | 39 | ‘ |
| U + 0028 | 40 | ( |
| U + 0029 | 41 | ) |
| U + 002A | 42 | * |
| U + 002B | 43 | + |
| U + 002C | 44 | , |
| U + 002D | 45 | – |
| U + 002E | 46 | . |
| U + 002F | 47 | / |
| U + 0030 | 48 | 0 |
| U + 0031 | 49 | 1 |
| U + 0032 | 50 | 2 |
| U + 0033 | 51 | 3 |
| U + 0034 | 52 | 4 |
| U + 0035 | 53 | 5 |
| U + 0036 | 54 | 6 |
| U + 0037 | 55 | 7 |
| U + 0038 | 56 | 8 |
| U + 0039 | 57 | 9 |
| U + 003A | 58 | : |
| U + 003B | 59 | ; |
| U + 003C | 60 | < |
| U + 003D | 61 | = |
| U + 003E | 62 | > |
| U + 003F | 63 | ? |
| U + 0040 | 64 | @ |
| U + 0041 | 65 | А |
| U + 0042 | 66 | B |
| U + 0043 | 67 | С |
| U + 0044 | 68 | D |
| U + 0045 | 69 | E |
| U + 0046 | 70 | F |
| U + 0047 | 71 | G |
| U + 0048 | 72 | H |
| U + 0049 | 73 | I |
| U + 004A | 74 | Дж |
| U + 004B | 75 | К |
| U + 004C | 76 | л |
| U + 004D | 77 | M |
| U + 004E | 78 | N |
| U + 004F | 79 | O |
| U + 0050 | 80 | П |
| U + 0051 | 81 | Q |
| U + 0052 | 82 | R |
| U + 0053 | 83 | S |
| U + 0054 | 84 | Т |
| U + 0055 | 85 | U |
| U + 0056 | 86 | В |
| U + 0057 | 87 | Вт |
| U + 0058 | 88 | Х |
| U + 0059 | 89 | Y |
| U + 005A | 90 | Z |
| U + 005B | 91 | [ |
| U + 005C | 92 | |
| U + 005D | 93 | ] |
| U + 005E | 94 | ^ |
| U + 005F | 95 | _ |
| U + 0060 | 96 | ` |
| U + 0061 | 97 | a |
| U + 0062 | 98 | б |
| U + 0063 | 99 | c |
| U + 0064 | 100 | d |
| U + 0065 | 101 | e |
| U + 0066 | 102 | f |
| U + 0067 | 103 | г |
| U + 0068 | 104 | ч |
| U + 0069 | 105 | и |
| U + 006A | 106 | j |
| U + 006B | 107 | к |
| U + 006C | 108 | л |
| U + 006D | 109 | кв.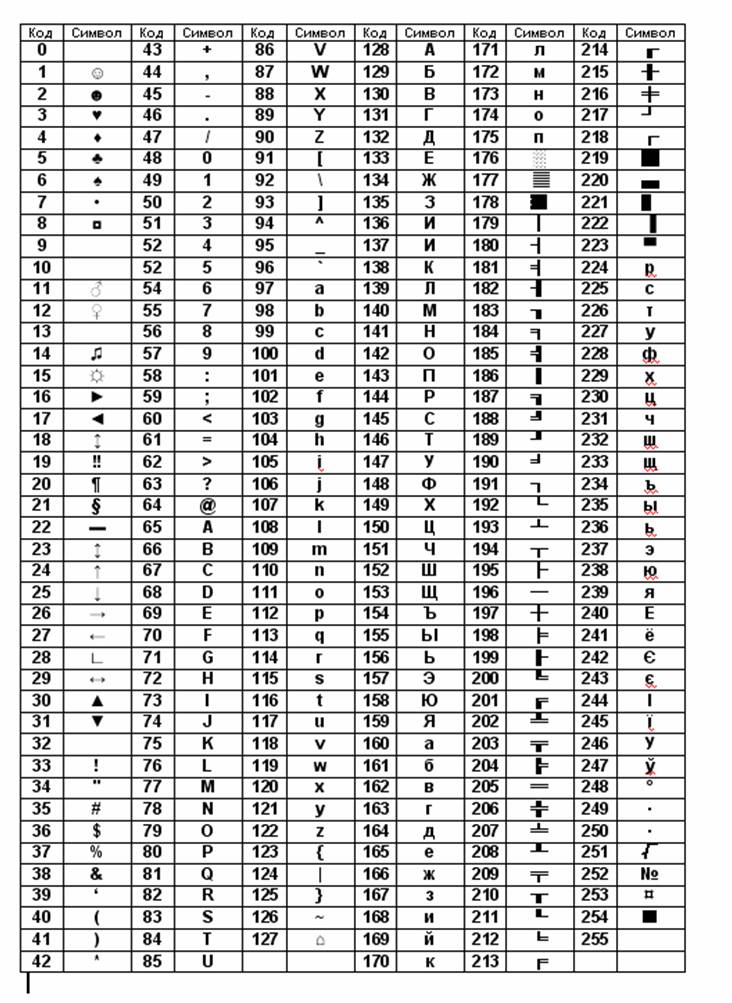 м. м. |
| U + 006E | 110 | n |
| U + 006F | 111 | o |
| U + 0070 | 112 | с. |
| U + 0071 | 113 | q |
| U + 0072 | 114 | r |
| U + 0073 | 115 | с |
| U + 0074 | 116 | т |
| U + 0075 | 117 | u |
| U + 0076 | 118 | v |
| U + 0077 | 119 | Вт |
| U + 0078 | 120 | х |
| U + 0079 | 121 | y |
| U + 007A | 122 | z |
| U + 007B | 123 | { |
| U + 007C | 124 | |
| U + 007D | 125 | } |
| U + 007E | 126 | ~ |
- Номера идут от
U + 0030доU + 0039 - Заглавные буквы идут от
U + 0041доU + 005A - Строчные буквы идут от
U + 0061доU + 007A
U + 007F (127) - символ удаления.
Все, что будет дальше, выходит за рамки ASCII и является частью исключительно Unicode.
Вы можете найти весь список в Википедии: https://en.wikipedia.org/wiki/List_of_Unicode_characters
Кодировки Unicode
UTF-8
UTF-8 - это кодировка символов переменной ширины, которая может кодировать каждый символ, охватываемый Unicode, используя от 1 до 4 8-битных байтов.
Первоначально он был разработан Кеном Томпсоном и Робом Пайком в 1992 году.Эти имена знакомы тем, кто хоть сколько-нибудь интересуется языком программирования Go, поскольку они тоже были двумя из первых создателей этого языка.
Рекомендуется W3C в качестве кодировки по умолчанию в файлах HTML, и статистика показывает, что по состоянию на апрель 2018 года она используется на 91,3% всех веб-страниц.
На момент своего появления ASCII была самой популярной кодировкой символов в западном мире. В ASCII всем буквам, цифрам и символам был присвоен номер, и это число. Будучи установленным на 8 бит, он мог отображать не более 255 символов, и этого было достаточно.
Будучи установленным на 8 бит, он мог отображать не более 255 символов, и этого было достаточно.
UTF-8 был разработан для обратной совместимости с ASCII. Это было очень важно для его принятия, поскольку ASCII был намного старше (1963 г.) и широко распространен, а переход на UTF-8 произошел почти прозрачно.
Первые 128 символов UTF-8 точно соответствуют ASCII. Почему 128? Поскольку ASCII использует 7-битную кодировку, которая допускает до 128 комбинаций. Почему 7 бит? Сейчас мы принимаем 8 бит как должное, но в те времена, когда был задуман ASCII, были популярны и 7-битные системы.
100% совместимость с ASCII делает UTF-8 также очень эффективным, поскольку наиболее часто используемые символы в западных языках кодируются только 1 байтом.
Вот карта использования байтов:
| Количество байтов | Начало | Конец |
|---|---|---|
| 1 | U + 0000 | U + 007F |
| 2 | U + 0080 | U + 07FF |
| 3 | U + 0800 | U + FFFF |
| 4 | U + 10000 | U + 10FFFF |
Помните, что в ASCII символы были закодированы как числа? Если буква A в ASCII была представлена числом 65 , то с использованием UTF-8 она закодирована как U + 0041 .
Почему не U + 0065 спросите вы? Потому что в юникоде используется шестнадцатеричное основание, а вместо 10 у вас есть U + 000A и так далее (в основном, у вас есть набор из 16 цифр вместо 10)
Посмотрите это видео, которое блестяще объясняет совместимость UTF-8 и ASCII.
UTF-16
UTF-16 - еще одна очень популярная кодировка Unicode. Например, так Java внутренне представляет любой символ. Это также одна из двух кодировок, используемых JavaScript для внутренних целей, наряду с UCS-2 .Он также используется многими другими системами, например Windows.
UTF-16 - это система кодирования переменной длины, такая как UTF-8, но использует 2 байта (16 бит) как минимум для любого представления символа. Таким образом, он обратно несовместим со стандартом ASCII.
Кодовые точки в базовой многоязычной плоскости (BMP) хранятся в 2 байтах. Кодовые точки в астральных планах хранятся в 4 байтах.
UTF-32
UTF-8 использует минимум 1 байт, UTF-16 использует минимум 2 байта.
UTF-32 всегда использует 4 байта без оптимизации использования пространства и, как таковой, расходует много пропускной способности.
Это ограничение ускоряет работу, потому что вам нужно меньше проверять, так как вы можете принять 4 байта для всех символов.
Он не так популярен, как UTF-8 и UTF-16, но у него есть свои приложения.
Больше руководств по js:
- Чего следует избегать в JavaScript (плохие части)
- Отсрочки и обещания в JavaScript (+ Ember.js пример)
- Как загружать файлы на сервер с помощью JavaScript
- Стиль кодирования JavaScript
- Введение в массивы JavaScript
- Введение в язык программирования JavaScript
- Полное руководство по ECMAScript 2015-2019
- Понимание обещаний JavaScript
- Лексическая структура JavaScript
- Типы JavaScript
- Переменные JavaScript
- Список примеров идей для веб-приложений
- Введение в функциональное программирование с помощью JavaScript
- Современный асинхронный JavaScript с Async и ожиданием
- Циклы и область действия JavaScript
- Структура данных JavaScript карты
- Заданная структура данных JavaScript
- Руководство по шаблонным литералам JavaScript
- Дорожная карта для изучения JavaScript
- Выражений JavaScript
- Откройте для себя таймеры JavaScript
- Объяснение событий JavaScript
- Циклы JavaScript
- Написание циклов JavaScript с использованием карты, фильтрации, сокращения и поиска
- Цикл событий JavaScript
- Функции JavaScript
- Глоссарий JavaScript
- Объяснение закрытий JavaScript
- Учебное пособие по функциям стрелок в JavaScript
- Руководство по регулярным выражениям JavaScript
- Как проверить, содержит ли строка подстроку в JavaScript
- Как удалить элемент из массива в JavaScript
- Как глубоко клонировать объект JavaScript
- Введение в Unicode и UTF-8
- Unicode в JavaScript
- Как сделать первую букву строки заглавной в JavaScript
- Как отформатировать число как денежное значение в JavaScript
- Как преобразовать строку в число в JavaScript
- это в JavaScript
- Как получить текущую метку времени в JavaScript
- Строгий режим JavaScript
- Выражения функции немедленного вызова JavaScript (IIFE)
- Как перенаправить на другую веб-страницу с помощью JavaScript
- Как удалить свойство из объекта JavaScript
- Как добавить элемент в массив в JavaScript
- Как проверить, не определено ли свойство объекта JavaScript
- Введение в модули ES
- Введение в CommonJS
- Асинхронное программирование JavaScript и обратные вызовы
- Как заменить все вхождения строки в JavaScript
- Краткое справочное руководство по синтаксису современного JavaScript
- Как обрезать ведущий ноль в числе в JavaScript
- Как проверить объект JavaScript
- Полное руководство по датам JavaScript
- Момент. js учебник
- Точка с запятой в JavaScript
- Арифметические операторы JavaScript
- Объект JavaScript Math
- Генерация случайных и уникальных строк в JavaScript
- Как заставить ваши функции JavaScript "спать"
- Прототипное наследование JavaScript
- Исключения JavaScript
- Как использовать классы JavaScript
- Поваренная книга JavaScript
- Цитаты в JavaScript
- Как проверить адрес электронной почты в JavaScript
- Как получить уникальные свойства набора объектов в массиве JavaScript
- Как проверить, начинается ли строка с другой в JavaScript
- Как создать многострочную строку в JavaScript
- Руководство ES6
- Как получить текущий URL в JavaScript
- Руководство ES2016
- Как инициализировать новый массив значениями в JavaScript
- Руководство ES2017
- Руководство ES2018
- Как использовать Async и Await с массивом. prototype.map ()
- Асинхронный и код синхронизации
- Как сгенерировать случайное число между двумя числами в JavaScript
- Учебное пособие по HTML Canvas API
- Как получить индекс итерации в цикле for-of в JavaScript
- Что такое одностраничное приложение?
- Введение в WebAssembly
- Введение в JSON
- Руководство JSONP
- Стоит ли использовать или изучать jQuery в 2020 году?
- Как скрыть элемент DOM с помощью простого JavaScript
- Как объединить два объекта в JavaScript
- Как очистить массив JavaScript
- Как закодировать URL-адрес с помощью JavaScript
- Как установить значения параметров по умолчанию в JavaScript
- Как отсортировать массив объектов по значению свойства в JavaScript
- Как подсчитать количество свойств в объекте JavaScript
- call () и apply () в JavaScript
- Введение в PeerJS, библиотеку WebRTC
- Работа с объектами и массивами с помощью Rest и Spread
- Разрушение объектов и массивов в JavaScript
- Полное руководство по отладке JavaScript
- Руководство по TypeScript
- Динамический выбор метода объекта в JavaScript
- Передача undefined в JavaScript Выражения немедленного вызова функций
- Свободно типизированные языки против строго типизированных языков
- Как стилизовать элементы DOM с помощью JavaScript
- Приведение в JavaScript
- Учебное пособие по генераторам JavaScript
- Размер папки node_modules не является проблемой. Это привилегия
- Как устранить непредвиденную ошибку идентификатора при импорте модулей в JavaScript
- Как перечислить все методы объекта в JavaScript
- Метод String replace ()
- Метод String search ()
- Как я запускаю небольшие фрагменты кода JavaScript
- Руководство ES2019
- Метод String charAt ()
- Метод String charCodeAt ()
- Метод String codePointAt ()
- Метод String concat ()
- Метод String EndWith ()
- Строка включает метод ()
- Метод String indexOf ()
- Метод String lastIndexOf ()
- Метод String localeCompare ()
- Метод String match ()
- Метод String normalize ()
- Метод String padEnd ()
- Метод String padStart ()
- Метод String repeat ()
- Метод String slice ()
- Метод String split ()
- Метод String StartWith ()
- Метод String substring ()
- Метод String toLocaleLowerCase ()
- Метод String toLocaleUpperCase ()
- Метод String toLowerCase ()
- Метод String toString ()
- Метод String toUpperCase ()
- Метод String trim ()
- Метод String trimEnd ()
- Метод trimStart () String
- Мемоизация в JavaScript
- Метод String valueOf ()
- Ссылка на JavaScript: String
- Метод Number isInteger ()
- Метод Number isNaN ()
- Метод Number isSafeInteger ()
- Метод Number parseFloat ()
- Метод Number parseInt ()
- Метод Number toString ()
- Метод Number valueOf ()
- Метод Number toPrecision ()
- Метод Number toExponential ()
- Метод Number toLocaleString ()
- Метод Number toFixed ()
- Метод Number isFinite ()
- Ссылка на JavaScript: номер
- Дескрипторы свойств JavaScript
- Метод Object assign ()
- Метод создания объекта ()
- Метод Object defineProperties ()
- Метод Object defineProperty ()
- Метод записи объекта ()
- Метод Object freeze ()
- Метод объекта getOwnPropertyDescriptor ()
- Метод объекта getOwnPropertyDescriptors ()
- Метод объекта getOwnPropertyNames ()
- Метод объекта getOwnPropertySymbols ()
- Метод объекта getPrototypeOf ()
- Метод Object is ()
- Метод Object isExtensible ()
- Метод Object isFrozen ()
- Метод Object isSealed ()
- Метод Object keys ()
- Метод объекта preventExtensions ()
- Метод объектной печати ()
- Метод объекта setPrototypeOf ()
- Метод значений объекта ()
- Метод объекта hasOwnProperty ()
- Метод Object isPrototypeOf ()
- Метод объекта propertyIsEnumerable ()
- Метод объекта toLocaleString ()
- Метод объекта toString ()
- Метод объекта valueOf ()
- Ссылка на JavaScript: объект
- Оператор присваивания JavaScript
- Интернационализация JavaScript
- Тип JavaScript оператора
- Новый оператор JavaScript
- Операторы сравнения JavaScript
- Правила приоритета операторов JavaScript
- Экземпляр JavaScript оператора
- Операторы JavaScript
- Область действия JavaScript
- Преобразование типов JavaScript (приведение)
- Операторы равенства JavaScript
- Условное выражение if / else в JavaScript
- Условный переключатель JavaScript
- Оператор удаления JavaScript
- Параметры функции JavaScript
- Оператор распространения JavaScript
- Возвращаемые значения JavaScript
- Логические операторы JavaScript
- Тернарный оператор JavaScript
- Рекурсия JavaScript
- Свойства объекта JavaScript
- Объекты ошибок JavaScript
- Глобальный объект JavaScript
- Функция JavaScript filter ()
- Функция JavaScript map ()
- Функция JavaScript reduce ()
- Оператор in в JavaScript
- Операторы JavaScript
- Как получить значение свойства CSS в JavaScript
- Как добавить прослушиватель событий к нескольким элементам в JavaScript
- Поля частного класса JavaScript
- Как отсортировать массив по значению даты в JavaScript
- Поля открытого класса JavaScript
- Символы JavaScript
- Как использовать библиотеку JavaScript bcrypt
- Как переименовывать поля при использовании деструктуризации объекта
- Как проверять типы в JavaScript без использования TypeScript
- Как проверить, содержит ли массив JavaScript определенное значение
- При чем тут оператор двойного отрицания !! делать в JavaScript?
- Какой оператор равенства следует использовать при сравнении JavaScript? == против ===
- Стоит ли изучать JavaScript?
- Как вернуть результат асинхронной функции в JavaScript
- Как проверить, пустой ли объект в JavaScript
- Как выйти из цикла for в JavaScript
- Как добавить элемент в массив по определенному индексу в JavaScript
- Почему не следует изменять прототип объекта JavaScript
- В чем разница между использованием let и var в JavaScript?
- Ссылки, используемые для активации функций JavaScript
- Как соединить две строки в JavaScript
- Как соединить два массива в JavaScript
- Как проверить, является ли значение JavaScript массивом?
- Как получить последний элемент массива в JavaScript?
- Как отправлять данные в кодировке urlencop с помощью Axios
- Как узнать дату завтрашнего дня с помощью JavaScript
- Как получить вчерашнюю дату с помощью JavaScript
- Как получить название месяца из даты JavaScript
- Как проверить, совпадают ли две даты в один и тот же день в JavaScript
- Как проверить, относится ли дата к дню в прошлом в JavaScript
- Операторы с метками JavaScript
- Как дождаться выполнения 2 или более обещаний в JavaScript
- Как получить дни между двумя датами в JavaScript
- Как загрузить файл с помощью Fetch
- Как отформатировать дату в JavaScript
- Как перебирать свойства объекта в JavaScript
- Как рассчитать количество дней между двумя датами в JavaScript
- Как использовать ожидание верхнего уровня в модулях ES
- Динамический импорт JavaScript
- JavaScript Необязательная цепочка
- Как заменить пробел внутри строки в JavaScript
- Нулевое слияние JavaScript
- Как сгладить массив в JavaScript
- Это десятилетие в JavaScript
- Как отправить заголовок авторизации с помощью Axios
- Список ключевых и зарезервированных слов в JavaScript
- Как преобразовать массив в строку в JavaScript
- Как удалить все содержимое папок node_modules
- Как удалить дубликаты из массива JavaScript
- Let vs Const в JavaScript
- Один и тот же вызов POST API в различных библиотеках JavaScript
- Как получить первые n элементов в массиве в JS
- Как разделить массив на несколько равных частей в JS
- Как замедлить цикл в JavaScript
- Как загрузить изображение на холст HTML
- Как разрезать строку на слова в JavaScript
- Как разделить массив пополам в JavaScript
- Как написать текст на холсте HTML
- Как удалить последний символ строки в JavaScript
- Как удалить первый символ строки в JavaScript
- Как исправить ошибку TypeError: не удается назначить только для чтения свойство «exports» объекта «#
- Как создать всплывающее окно с намерением выхода
- Как проверить, является ли элемент потомком другого
- Как принудительно вводить учетные данные для каждого запроса Axios
- Как устранить ошибку "не функция" в JavaScript
- Гэтсби, как поменять фавикон
- Загрузка внешнего файла JS с помощью Gatsby
- Как определить темный режим с помощью JavaScript
- Посылка, как исправить ошибку `регенератор Время выполнения не определено`
- Как определить, используется ли Adblocker с JavaScript
- Деструктуризация объектов с типами в TypeScript
- The Deno Handbook: краткое введение в Deno 🦕
- Как получить последний сегмент пути или URL-адреса с помощью JavaScript
- Как перемешать элементы в массиве JavaScript
- Как проверить, существует ли ключ в объекте JavaScript
- Возбуждение событий и захват событий
- событие. stopPropagation против event.preventDefault () против return false в событиях DOM
- Примитивные типы и объекты в JavaScript
- Как узнать, к какому типу относится значение в JavaScript?
- Как вернуть несколько значений из функции в JavaScript
- Стрелочные функции и обычные функции в JavaScript
- Как мы можем получить доступ к значению свойства объекта?
- В чем разница между null и undefined в JavaScript?
- В чем разница между методом и функцией?
- Какими способами мы можем выйти из цикла в JavaScript?
- JavaScript для.петля
- Что такое деструктуризация объектов в JavaScript?
- Что такое подъем в JavaScript?
- Как заменять запятые на точки с помощью JavaScript
- Важность тайминга при работе с DOM
- Как перевернуть массив JavaScript
- Как проверить, является ли значение числом в JavaScript
- Как принять неограниченное количество параметров в функции JavaScript
- Объекты прокси JavaScript
- Делегирование событий в браузере с использованием ванильного JavaScript
- Супер-ключевое слово JavaScript
- Введение в XState
- Значения передаются в JavaScript по ссылке или по значению?
- Пользовательские события в JavaScript
- Пользовательские ошибки в JavaScript
- Пространства имен в JavaScript
- Любопытное использование запятых в JavaScript
- Цепочка вызовов методов в JavaScript
- Как справиться с отклонением обещаний
- Как поменять местами два элемента массива в JavaScript
- Как я исправил ошибку "cb. "применить не является функцией" ошибка при использовании Gitbook
- Как добавить элемент в начало массива в JavaScript
- Gatsby, исправьте ошибку «не удается найти модуль gatsby-cli / lib / reporter»
- Как получить индекс элемента в массиве JavaScript
- Как проверить пустой объект в JavaScript
- Как деструктурировать объект до существующих переменных в JavaScript
- Структура данных JavaScript массива
- Структура данных JavaScript стека
- Структуры данных JavaScript: очередь
- Структуры данных JavaScript: установить
- Структуры данных JavaScript: словари
- Структуры данных JavaScript: связанные списки
- JavaScript, как экспортировать функцию
- JavaScript, как экспортировать несколько функций
- JavaScript, как выйти из функции
- JavaScript, как найти символ в строке
- JavaScript, как фильтровать массив
- JavaScript, как расширить класс
- JavaScript, как найти дубликаты в массиве
- JavaScript, как заменить элемент массива
- JavaScript-алгоритмы: линейный поиск
- Алгоритмы JavaScript: двоичный поиск
- Алгоритмы JavaScript: сортировка выбора
- JavaScript-алгоритмов: Quicksort
- Алгоритмы JavaScript: сортировка слиянием
- JavaScript-алгоритмов: пузырьковая сортировка
- Дождитесь разрешения всех обещаний в JavaScript
 js учебник
js учебник prototype.map ()
prototype.map () Это привилегия
Это привилегия stopPropagation против event.preventDefault () против return false в событиях DOM
stopPropagation против event.preventDefault () против return false в событиях DOM "применить не является функцией" ошибка при использовании Gitbook
"применить не является функцией" ошибка при использовании GitbookSMS // Информация о кодировке символов SMS, поддержке языка и длине сообщений
Мир SMS-сообщений немного сложнее, чем кажется на первый взгляд. В этой статье объясняются некоторые из различных типов SMS-сообщений и возможные ограничения. Эти ограничения вызваны не ChMS Tithe.ly, а самими SMS-компаниями.
В этой статье объясняются некоторые из различных типов SMS-сообщений и возможные ограничения. Эти ограничения вызваны не ChMS Tithe.ly, а самими SMS-компаниями.
Мы создали таблицу, которая поможет вам определить, какие SMS-компании поддерживают различные типы сообщений, описанные ниже.
Обратите внимание, что информация, которую мы предоставляем, является только справочной. Результаты могут отличаться в зависимости от вашего оператора мобильной связи, языка и страны. Если вы планируете использовать другие языки или дополнительные символы, мы предлагаем вам связаться с интересующей вас SMS-компанией, чтобы узнать больше об их поддержке.
Кодировка символов
Различные SMS-компании имеют ограничения на то, какие символы вы можете отправлять в SMS-сообщении. Используемые символы также повлияют на тип отправляемого сообщения и, следовательно, могут повлиять на стоимость SMS-сообщения.
Набор символов GSM
GSM - это набор символов, используемый в мобильных телефонах на базе GSM и рассчитанный на большинство мобильных телефонов, доступных сегодня.
Символы включают латинский алфавит, цифры и другие символы на клавиатуре, например! @ # и так далее.~ €.
Подробную информацию о том, какие поставщики поддерживают эти расширенные символы, см. В таблице поставщиков.
Даже если провайдер SMS поддерживает эти символы, мы рекомендуем провести тест перед их использованием, поскольку результаты могут отличаться в зависимости от вашего оператора мобильной связи и страны. Например, знак валюты евро работает только в некоторых странах у некоторых операторов мобильной связи.
Unicode
Стандарт unicode позволяет выйти за рамки наборов символов GSM, чтобы поддерживать широкий диапазон языков и технических символов.
Например, если вы хотите отправить SMS-сообщение на японском языке, вы можете сделать это, но оно будет отправлено в формате Unicode.
Сообщения Unicode могут содержать только половину символов обычного текстового сообщения. Подробнее об этом ниже.
Поддержка Unicode ограничена в зависимости от вашей SMS-компании, оператора мобильной связи и страны. Обратитесь к таблице поставщиков, чтобы узнать, какие компании SMS поддерживают сообщения Unicode.
Обратитесь к таблице поставщиков, чтобы узнать, какие компании SMS поддерживают сообщения Unicode.
Важное примечание: Прежде чем выбирать SMS-компанию, мы рекомендуем вам связаться с SMS-компаниями, которые поддерживают сообщения Unicode, чтобы узнать больше об их поддержке символов для вашего языка и страны, в которую вы отправляете сообщения.
Длина сообщения
Длина сообщения, вычисленная в Tithe.ly ChMS, является ориентировочной. Если вы используете в своем сообщении динамические заполнители, это повлияет на его длину. Например,% firstname% состоит из 10 символов. Когда сообщение отправляется Бену, длина сообщения будет на 7 символов меньше, поскольку имя состоит всего из 3 символов.
Типичная длина SMS-сообщения составляет 160 символов, однако, если вы используете какие-либо символы из указанного выше набора символов GSM Extended , они считаются как 2 символа каждый.Это немного странно, но похоже, что все SMS-компании так поступают.
Когда вы отправляете SMS-сообщение, длина которого превышает 160 символов, SMS-компания преобразует SMS-сообщение в сообщение, состоящее из нескольких частей. Сообщения, состоящие из нескольких частей, могут содержать не более 153 символов в каждой части сообщения. Сообщение, состоящее из нескольких частей, фактически то же самое, что и отправка нескольких сообщений SMS, однако современные мобильные телефоны могут «сшивать» сообщения, состоящие из нескольких частей, обратно в одно цельное сообщение. Имейте в виду, что каждая часть сообщения в SMS-сообщении, состоящем из нескольких частей, стоит вам кредита SMS.
Если вы отправляете SMS-сообщение, содержащее один или несколько символов Юникода, длина сообщения уменьшается до 70 символов. Если вы превысите ограничение в 70 символов, оно будет отправлено как сообщение, состоящее из нескольких частей, и каждая часть сообщения будет сокращена до 67 символов.
Если SMS-компания не поддерживает составную часть, она просто отправит несколько SMS-сообщений, которые не будут «сшиты» обратно в одно сообщение.