Кэш 3 уровня что это: Зачем процессорам нужен кэш и чем отличаются уровни L1, L2, L3
Детальное исследование платформ с помощью тестового пакета RightMark Memory Analyzer
Часть 2: Платформы Intel Pentium 4
Мы продолжаем цикл низкоуровневого исследования важнейших характеристик платформ с помощью универсального тестового пакета RightMark Memory Analyzer. На этот раз мы представляем вашему вниманию результаты сравнительного тестирования платформ Intel Pentium 4, которое, как вы, наверное, догадываетесь, приурочено к выпуску нового 90-нм процессора Prescott. Это исследование позволит нам выявить важнейшие изменения, которые были внесены в микроархитектуру NetBurst с выпуском нового процессора. Для нашего тестирования мы выбрали три модели процессоров Intel Pentium 4 (Northwood, Gallatin и Prescott) с одной и той же частотой ядра (3,2 ГГц), что позволило провести их сравнительное тестирование в одинаковых условиях (одни и те же частота ядра, чипсет и тип памяти).
Конфигурации тестового стенда и ПО
Тестовый стенд:
- Процессоры:
- Intel Pentium 4 3,2 ГГц (ядро Northwood, FSB 800/HT, 512 КБ L2)
- Intel Pentium 4 Extreme Edition 3.
 2 ГГц (ядро Gallatin, FSB 800/HT, 512 КБ L2, 2 МБ L3)
2 ГГц (ядро Gallatin, FSB 800/HT, 512 КБ L2, 2 МБ L3) - Intel Pentium 4 3,2 ГГц (ядро Prescott, FSB 800/HT, 1 МБ L2)
- Материнская плата: ASUS P4C800 Deluxe (версия BIOS 1014) на чипсете Intel 875P
- Память: 2×512 МБ PC3200 DDR SDRAM DIMM TwinMOS (тайминги 2-2-2-5)
 2 ГГц (ядро Gallatin, FSB 800/HT, 512 КБ L2, 2 МБ L3)
2 ГГц (ядро Gallatin, FSB 800/HT, 512 КБ L2, 2 МБ L3)Системное ПО и драйверы устройств:
- Windows XP Professional SP1
- DirectX 9.0b
- Intel Chipset Installation Utility 5.0.2.1003
- ATI Catalyst 3.9
Реальная пропускная способность кэша данных/памяти
Начнем сравнительное тестирование платформ Intel Pentium 4 с оценки средней реальной пропускной способности кэша данных и памяти. Будем исследовать эту характеристику в двух режимах доступа используя для этой цели MMX- и SSE/SSE2-регистры. Для этого воспользуемся тестом Memory Bandwidth, выбрав настройки D-Cache/RAM Bandwidth, MMX Registers; SSE Registers; SSE2 Registers. Использование SSE/SSE2-регистров позволяет достичь больших значений реальной ПС кэша данных/памяти, причем результаты SSE и SSE2 оказываются идентичными. Приведем здесь общую картину реальной ПС в случае использования SSE-регистров.
Использование SSE/SSE2-регистров позволяет достичь больших значений реальной ПС кэша данных/памяти, причем результаты SSE и SSE2 оказываются идентичными. Приведем здесь общую картину реальной ПС в случае использования SSE-регистров.
Средняя реальная ПСП, Intel Pentium 4 Northwood
Средняя реальная ПСП, Intel Pentium 4 XE Gallatin
Средняя реальная ПСП, Intel Pentium 4 Prescott
На всех трех процессорах мы получили достаточно очевидную картину. Из нее четко видно наличие двух уровней кэша данных (L1 и L2), размеры которых соответствуют заявленным в документации (8/8/16 КБ L1, 512/512/1024 КБ L2 для Northwood/Gallatin/Prescott, соответственно). Действительно, объем обоих уровней кэша данных в новом 90нм процессоре Prescott был удвоен по сравнению с его предшественниками (Northwood и Gallatin). Pentium 4 XE, как и следовало ожидать, характеризуется наличием еще одного уровня кэша данных (L3) объемом 2 МБ. Во всех случаях интересно отметить некоторое снижение эффективной ПС кэша L2 на чтение при пересечении границы 256 КБ.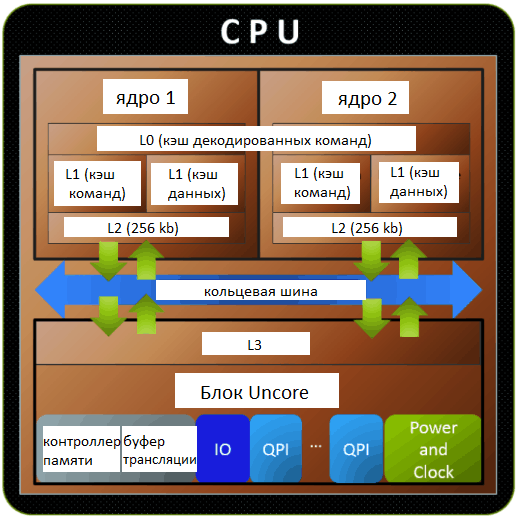 Причина этого, по всей видимости, связана с исчерпыванием D-TLB (который, как мы увидим дальше, на всех процессорах может содержать всего 64 записи, что в точности соответствует адресации 256 КБ виртуальной памяти). Наконец, последней особенностью полученных нами кривых можно считать наличие перегибов, четко соответствующих размерам L1, L2 (и L3) кэша данных, что говорит об инклюзивной организации последнего (как мы видели в предыдущем исследовании, эксклюзивный кэш данных процессоров семейства AMD K7/K8 проявляет себя в этом тесте принципиально иным образом).
Причина этого, по всей видимости, связана с исчерпыванием D-TLB (который, как мы увидим дальше, на всех процессорах может содержать всего 64 записи, что в точности соответствует адресации 256 КБ виртуальной памяти). Наконец, последней особенностью полученных нами кривых можно считать наличие перегибов, четко соответствующих размерам L1, L2 (и L3) кэша данных, что говорит об инклюзивной организации последнего (как мы видели в предыдущем исследовании, эксклюзивный кэш данных процессоров семейства AMD K7/K8 проявляет себя в этом тесте принципиально иным образом).
Приступим к рассмотрению самих значений средней реальной ПС L1, L2 (L3) кэша данных и памяти на исследуемых платформах.
| Уровень | Средняя реальная пропускная способность, байт/такт | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| L1, чтение, MMX L1, чтение, SSE L1, запись, MMX L1, запись, SSE | 7.83 15.  73 733.52 4.56 | 7.84 15.72 3.51 4.56 | 7.82 15.54 2.90 3.56 |
| L2, чтение, MMX L2, чтение, SSE L2, запись, MMX L2, запись, SSE | 4.25 8.50 3.54 4.55 | 4.25 8.50 3.54 4.55 | 4.55 8.38 2.90 3.54 |
| L3, чтение, MMX L3, чтение, SSE L3, запись, MMX L3, запись, SSE | — — — — | 2.13 3.31 2.30 2.42 | — — — — |
| RAM, чтение, MMX RAM, чтение, SSE RAM, запись, MMX RAM, запись, SSE | 1.21 (3915.8 МБ/с) 1.55 (5011.0 МБ/с) 0.47 (1533.3 МБ/с) 0.47 (1533.5 МБ/с) | 1.21 (3900.4 МБ/с) 1.53 (4959.2 МБ/с) 0.66 (2130.0 МБ/с) 0.66 (2122.9 МБ/с) | 1.55 (5003.9 МБ/с) 1.75 (5664.3 МБ/с) 0.63 (2029.6 МБ/с) 0.63 (2030.3 МБ/с) |
Как видно из этой таблицы, исследуемые процессоры семейства Intel Pentium 4 имеют и много общего, и ряд отличий. Так, эффективная ПС связки L1-регистры во всех случаях оказывается близкой к 8 байтам/такт (MMX) и 16 байтам/такт (SSE), что говорит о возможности пересылки всего одного значения из памяти (64- и 128-битного, соответственно) в MMX- и SSE/SSE2-регистры за один такт процессора. Напомним, что в процессорах семейства AMD K7/K8 мы видели противоположную картину: реальная ПС L1-LSU-registers достигала своего максимального значения (13-15 байт/такт) именно в случае MMX-регистров (пересылка двух значений за такт), в то время как эффективная ПС снижалась вдвое при переходе к SSE-регистрам (пересылка одного операнда за два такта процессора). Эффективность L1 на запись не претерпела каких-либо изменений при переходе от Northwood к Gallatin, а вот на Prescott она несколько упала (на 20-28%).
Так, эффективная ПС связки L1-регистры во всех случаях оказывается близкой к 8 байтам/такт (MMX) и 16 байтам/такт (SSE), что говорит о возможности пересылки всего одного значения из памяти (64- и 128-битного, соответственно) в MMX- и SSE/SSE2-регистры за один такт процессора. Напомним, что в процессорах семейства AMD K7/K8 мы видели противоположную картину: реальная ПС L1-LSU-registers достигала своего максимального значения (13-15 байт/такт) именно в случае MMX-регистров (пересылка двух значений за такт), в то время как эффективная ПС снижалась вдвое при переходе к SSE-регистрам (пересылка одного операнда за два такта процессора). Эффективность L1 на запись не претерпела каких-либо изменений при переходе от Northwood к Gallatin, а вот на Prescott она несколько упала (на 20-28%).
Кэша L2 работает на чтение одинаково эффективно как у Northwood, так и у Gallatin. А вот Prescott с его увеличенными объемами L1 и L2 привносит в эту картину некоторые отличия: эффективность чтения в MMX-регистры процессора чуть возросла (на 7%), а в SSE немножко упала (на 1%). Об эффективности влияния на запись этого уровня кэша можно сказать то же самое, что и об L1 кэше: переход к новой микроархитектуре Prescott привел к ее снижению на те же 20-28%.
Об эффективности влияния на запись этого уровня кэша можно сказать то же самое, что и об L1 кэше: переход к новой микроархитектуре Prescott привел к ее снижению на те же 20-28%.
Посмотрим, наконец, какие различия имеются в ряду исследуемых процессоров относительно операций доступа в оперативную память. Ее средняя реальная ПС на чтение оказывается очень близкой как на Northwood, так и на Gallatin, т.е. наличие третьего уровня кэша у последнего здесь никак не сказывается. В то же время, новый 90-нм процессор демонстрирует значительное улучшение этого параметра (на 13-27%), особенно при использовании MMX-регистров. Это наталкивает на мысль, что алгоритм Hardware Prefetch в новой микроархитектуре Prescott был несколько улучшен. Мы коснемся этого факта несколько позже, при изучении картины латентности доступа в оперативную память. Что касается реальной ПСП на запись, видно, что она возросла еще со времен Gallatin (в среднем, на 39% по сравнению с Northwood) и практически не изменилась при переходе к новой микроархитектуре (точнее, даже несколько упала, примерно на 5%).
Таким образом, новый процессор Prescott демонстрирует довольно смешанную картину. Из ключевых моментов можно отметить снижение эффективности обоих уровней кэша данных на запись и возросшую среднюю реальную пропускную способность памяти на чтение.
Максимальная реальная пропускная способность памяти
Как и прежде, попытаемся «выжать максимум» из подсистемы памяти, то есть — достичь максимальных значений реальной ПСП в операциях чтения и записи. Для этого будем использовать следующие доступные методы достижения максимальной действительной ПСП на чтение:
- Software Prefetch
- Block Prefetch 1
- Block Prefetch 2
- Чтение строк кэша (прямое/обратное)
И вот такие для оценки максимальной реальной ПСП на запись:
- Non-Temporal store
- Запись строк кэша (прямая/обратная)
Во всех случаях, где это возможно, будем использовать как MMX-, так и SSE/SSE2-регистры. Напомним, что методы Prefetch/Non-Temporal store реализованы в тесте Memory Bandwidth, а методы чтения/записи строк кэша в тесте D-Cache Bandwidth.
Для наглядности продемонстрируем кривые, полученные с использованием Software Prefetch и SSE-регистров процессора.
Максимальная реальная ПСП, Intel Pentium 4 Northwood
Максимальная реальная ПСП, Intel Pentium 4 XE Gallatin
Максимальная реальная ПСП, Intel Pentium 4 Prescott
| Режим доступа | Максимальная реальная ПСП на чтение, МБ/с | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| Чтение, MMX Чтение, SSE Чтение, MMX, SW Prefetch Чтение, SSE, SW Prefetch Чтение, MMX, Block Prefetch 1 Чтение, SSE, Block Prefetch 1 Чтение, MMX, Block Prefetch 2 Чтение, SSE, Block Prefetch 2 Чтение строк кэш, прямое Чтение строк кэш, обратное | 3915.8 (78.1 %) 5011.0 (100.0 %) 5345.3 (106.7 %) 5802.4 (115.8 %) 4332.2 (86.5 %) 4811.5 (96.0 %) 3716.2 (74.2 %) 4798.3 (95.8 %) 5943.0 (118.6 %) 5950.4 (118. 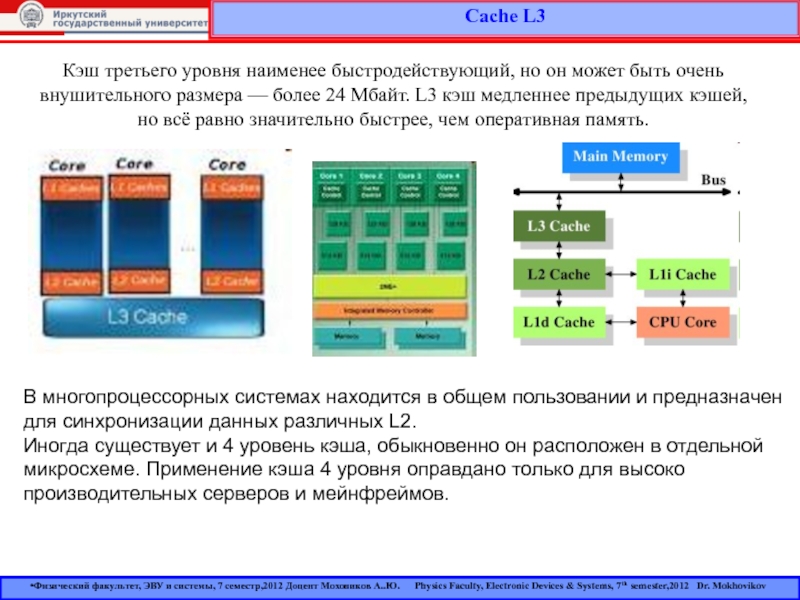 7 %) 7 %) | 3900.4 (78.6 %) 4959.2 (100.0 %) 5472.0 (110.3 %) 6124.1 (123.5 %) 4317.8 (87.1 %) 4725.8 (95.3 %) 3836.8 (77.4 %) 4787.1 (96.5 %) 5903.5 (119.0 %) 5904.0 (119.1 %) | 5003.9 (88.3 %) 5664.3 (100.0 %) 6484.1 (114.5 %) 6493.4 (114.6 %) 4700.5 (83.0 %) 5164.5 (91.2 %) 4952.5 (87.4 %) 5562.9 (98.2 %) 5762.2 (101.7 %) 5767.6 (101.8 %) |
Легко видеть, что в тестах максимальной действительной ПСП на чтение использование MMX как на Northwood, так и на Gallatin во всех случаях проигрывает SSE/SSE2 (результаты последних, как и ранее, идентичны). Использование Software Prefetch дает ощутимый выигрыш в скорости на всех трех типах процессоров. При этом на Gallatin и Prescott достигаются максимально возможные значения ПСП, равные 6124.1 МБ/с и 6493.4 МБ/с, соответственно. Достижение большей величины реальной ПСП на Gallatin по сравнению с Northwood, по-видимому, можно отнести к наличию у первого сравнительно большого дополнительного уровня кэша данных L3 объемом 2 МБ. Интересно, что эффективность чтения памяти в методе Software Prefetch как с помощью MMX-, так и SSE/SSE2-регистров на Prescott оказывается практически одинаковой, что говорит о весьма большом потенциале Software Prefetch в процессорах Prescott.
Интересно, что эффективность чтения памяти в методе Software Prefetch как с помощью MMX-, так и SSE/SSE2-регистров на Prescott оказывается практически одинаковой, что говорит о весьма большом потенциале Software Prefetch в процессорах Prescott.
Можно сказать, что Software Prefetch в новом поколении процессоров Prescott претерпел значительные улучшения, позволяющие достичь, фактически, 100% эффективности двухканальной памяти DDR на чтение. Что приятно, соответствующие моменты отражены и в документации Prescott. Так, отмечается, что в новой ревизии микроархитектуры NetBurst инструкции Software Prefetch могут инициировать не только загрузку данных с новой страницы памяти (чего не было в предыдущих реализациях Pentium 4), но и загрузку соответствующего дескриптора страницы в D-TLB. Вторым значимым улучшением является кэширование инструкций Software Prefetch Trace-кэшем процессора, позволяющее значительно снизить затраты на их исполнение.
Методы Block Prefetch являются специфичными для процессоров AMD, поэтому мы приводим их результаты исключительно для того, чтобы убедиться, что для рассматриваемого семейства Intel Pentium 4 они совершенно не годятся. Во всех случаях они не только не улучшают картину реальной ПСП, но даже ухудшают ее по сравнению со средними значениями реальной ПСП, полученными без применения каких-либо оптимизаций.
Во всех случаях они не только не улучшают картину реальной ПСП, но даже ухудшают ее по сравнению со средними значениями реальной ПСП, полученными без применения каких-либо оптимизаций.
Методы чтения строк кэш показывают весьма интересную картину. Они выдают довольно близкие значения на Northwood и Gallatin, которые примерно на 19% выше по сравнению со средней величиной реальной ПСП на чтение на этих процессорах. Кстати, значение 5950.4 МБ/с, достигаемое этими методами на Northwood, является для него абсолютным пределом, недостижимым при использовании Software Prefetch ввиду посредственной реализации последнего. В то же время, чтение строк кэш на Prescott дает довольно неожиданный результат, который оказывается немногим (не более чем на 2%) лучше, чем при обычном полном чтении данных с использованием SSE/SSE2-регистров.
| Режим доступа | Максимальная реальная ПСП на запись, МБ/с | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| Запись, MMX Запись, SSE Запись, MMX, Non-Temporal Запись, SSE, Non-Temporal Запись строк кэш, прямая Запись строк кэш, обратная | 1533.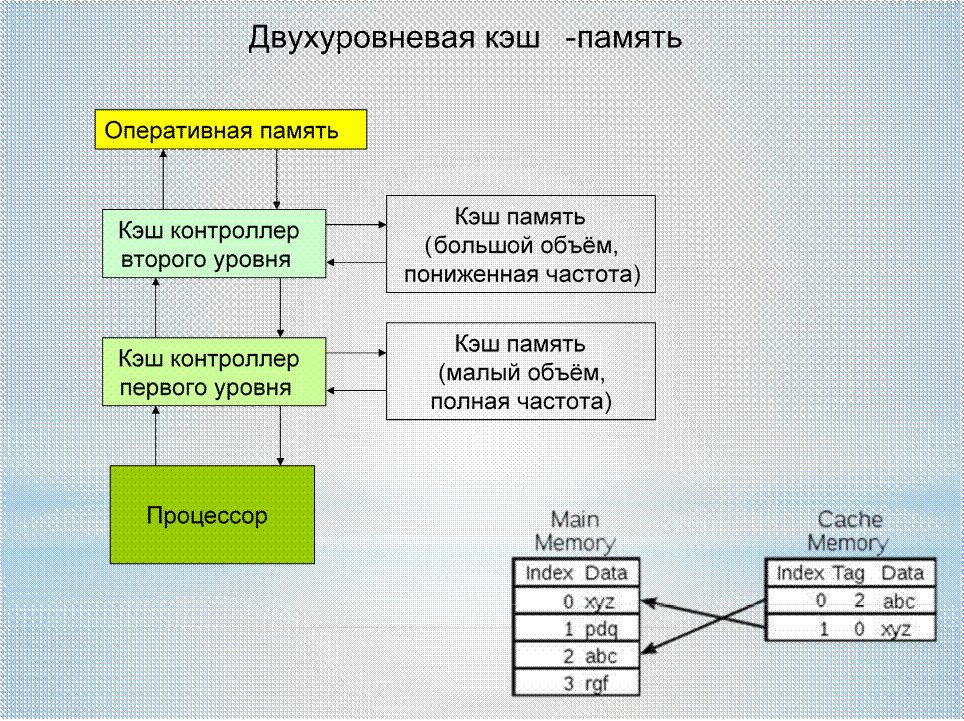 3 (100.0 %) 3 (100.0 %)1533.5 (100.0 %) 4290.5 (279.8 %) 4290.6 (279.8 %) 2541.5 (165.7 %) 2545.7 (166.0 %) | 2130.0 (100.3 %) 2122.9 (100.0 %) 4289.7 (202.1 %) 4290.0 (202.1 %) 2676.1 (126.1 %) 2676.2 (126.1 %) | 2029.6 (100.0 %) 2030.3 (100.0 %) 4290.3 (211.3 %) 4290.1 (211.3 %) 2997.0 (147.6 %) 2979.1 (146.7 %) |
Что касается максимальных значений реальной ПСП на запись, здесь все получается довольно четко. Во всех трех случаях максимальная величина реальной ПСП составляет 4290 МБ/с, что соответствует 67% от теоретически возможной максимальной ПСП двухканальной DDR. Она достигается при использовании метода прямого сохранения данных по протоколу объединения записи (write-combining). Наличие большего количества буферов сохранения и объединения записи у Prescott здесь никак себя не проявляет — видимо, предельная величина реальной ПСП жестко задается типом используемого чипсета, т.е. именно последний является лимитирующим фактором. Что касается метода записи строк кэша, то результат вновь оказывается довольно неожиданным. В то время как эффективность шины L2-RAM на чтение, как было показано, у Prescott несколько ниже (на 2-3%), чем у Northwood/Gallatin, ее эффективность на запись оказывается наивысшей именно у Prescott (на 12-17% выше). Тем не менее, значения реальной ПСП, достигаемые в этом методе, хотя и выше средних (на 26-66%, в зависимости от модели процессора), но весьма далеки от предельных значений, достигаемых в методе прямого сохранения данных (минуя кэш данных процессора).
Что касается метода записи строк кэша, то результат вновь оказывается довольно неожиданным. В то время как эффективность шины L2-RAM на чтение, как было показано, у Prescott несколько ниже (на 2-3%), чем у Northwood/Gallatin, ее эффективность на запись оказывается наивысшей именно у Prescott (на 12-17% выше). Тем не менее, значения реальной ПСП, достигаемые в этом методе, хотя и выше средних (на 26-66%, в зависимости от модели процессора), но весьма далеки от предельных значений, достигаемых в методе прямого сохранения данных (минуя кэш данных процессора).
Латентность кэша данных/памяти
Перейдем к изучению средней латентности уровней кэша данных и памяти, т.к. именно здесь нас ждут самые неожиданные открытия касательно новой микроархитектуры NetBurst 90-нм процессоров Prescott. Для получения общей картины воспользуемся тестом D-Cache Latency, выбрав пресет D-Cache/RAM Latency.
Средняя латентность, Intel Pentium 4 Northwood
Средняя латентность, Intel Pentium 4 XE Gallatin
Средняя латентность, Intel Pentium 4 Prescott
Общая картина латентности на всех трех «подопытных» на качественном уровне очевидна. На кривых можно четко выделить области, соответствующие латентности кэша L1 (размер блока до 8 КБ, Northwood/Gallatin и до 16 КБ включительно, Prescott) и L2 (размер блока до 512 КБ, Northwood/Gallatin и до 1 МБ, Prescott). Pentium 4 XE, как и следовало ожидать, и в этом тесте отлично проявляет свой кэш данных третьего уровня, при размере блока до 2 МБ включительно. Наличие перегибов на кривых в точках, строго соответствующих областям L1, L2 (L3) вновь подтверждает инклюзивную организацию уровней кэша данных в рассматриваемых процессорах, включая L3 процессора Pentium 4 XE. Заметим, что дублирование целых 512 КБ кэша L2 в двухмегабайтном кэше L3, что составляет 25% его объема, является весьма и весьма серьезной платой за простоту организации шины кэша (L1-L2 и L2-L3). Тогда, как известно, что AMD в своих процессорах семейства K7/K8 реализует более сложную, эксклюзивную организацию уровней L1-L2, исключая возможность «засорения» ненужными данными даже 6.25% (Opteron, Athlon 64), не говоря уж о 25% (Athlon XP/MP) кэша данных второго уровня.
На кривых можно четко выделить области, соответствующие латентности кэша L1 (размер блока до 8 КБ, Northwood/Gallatin и до 16 КБ включительно, Prescott) и L2 (размер блока до 512 КБ, Northwood/Gallatin и до 1 МБ, Prescott). Pentium 4 XE, как и следовало ожидать, и в этом тесте отлично проявляет свой кэш данных третьего уровня, при размере блока до 2 МБ включительно. Наличие перегибов на кривых в точках, строго соответствующих областям L1, L2 (L3) вновь подтверждает инклюзивную организацию уровней кэша данных в рассматриваемых процессорах, включая L3 процессора Pentium 4 XE. Заметим, что дублирование целых 512 КБ кэша L2 в двухмегабайтном кэше L3, что составляет 25% его объема, является весьма и весьма серьезной платой за простоту организации шины кэша (L1-L2 и L2-L3). Тогда, как известно, что AMD в своих процессорах семейства K7/K8 реализует более сложную, эксклюзивную организацию уровней L1-L2, исключая возможность «засорения» ненужными данными даже 6.25% (Opteron, Athlon 64), не говоря уж о 25% (Athlon XP/MP) кэша данных второго уровня.
Особенностью кривых латентности случайного доступа на всех трех типах Pentium 4 является ее плавное увеличение при размерах блока 256 КБ и выше. Напомним, что нечто похожее мы наблюдали и в нашем первом тесте средней реальной ПС кэша L2, и связано это с тем, что размер D-TLB у этого типа процессоров весьма небольшой и может обеспечивать эффективную адресацию лишь 256 КБ (64 страниц) виртуальной памяти. Столь небольшой размер D-TLB при относительно большом объеме кэша (1 МБ L2, Prescott и 2 МБ L3, Gallatin) можно считать существенным недостатком архитектуры NetBurst процессоров Pentium 4. Удивительно, что в новой ее ревизии (Prescott) инженеры Intel не позаботились об увеличении размера D-TLB или введения двухуровневой системы D-TLB, присущей процессорам семейства AMD K7/K8. В связи с этим, точная оценка латентности случайного доступа в L3 (Gallatin) и RAM оказывается затруднена; здесь и далее мы оперируем значениями, полученными при размерах блока 1 МБ (L3) и 4 МБ (RAM).
Перейдем к количественной оценке средней латентности различных уровней кэша/памяти при различных режимах доступа.
| Уровень, доступ | Средняя латентность, тактов | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| L1, прямой L1, обратный L1, случайный | 2.0 2.0 2.0 | 2.0 2.0 2.0 | 4.0 4.0 4.0 |
| L2, прямой L2, обратный L2, случайный | 18.5 18.5 18.5 | 18.5 18.5 18.5 | 28.5 28.5 28.5 |
| L3, прямой L3, обратный L3, случайный* | — — — | 35.5 35.5 61.0 | — — — |
| RAM, прямой RAM, обратный RAM, случайный** | 57.0 (17.6 нс) 57.0 (17.6 нс) 229.0 (71.0 нс) | 58.0 (18.0 нс) 58.0 (18.0 нс) 185.0 (57.0 нс) | 41.0 (12.7 нс) 41.0 (12.7 нс) 225.5 (69.8 нс) |
*Размер блока 1 МБ
**Размер блока 4 МБ
Как видно из этой таблицы, серьезных различий между Northwood и Gallatin в плане латентности не наблюдается.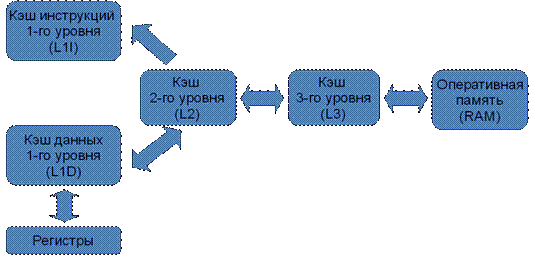 Латентность L1 во всех случаях доступа составляет ровно 2 такта, латентность L2 в среднем 18.5 тактов. Латентность кэша L3 процессора Pentium 4 XE при прямом и обратном доступе почти в два раза выше, чем латентность L2 она составляет 35.5 тактов (а при случайном доступе и того выше, 61 такт процессора, правда, с упомянутой выше оговоркой, что точное измерение последней не представляется возможным ввиду исчерпания D-TLB процессора). Наконец, латентность последнего уровня оперативной памяти характеризуется величинами 57-58 тактов (17.6-18.0 нс) при прямом/обратном доступе, что говорит о наличии хорошего алгоритма Hardware Prefetch, работающего в этих режимах обхода. Латентность случайного доступа в RAM (с той же оговоркой) существенно выше, она составляет 229 тактов (71.0 нс) на Northwood и 185 тактов (57.0 нс) на Gallatin. Меньшую величину латентности памяти на последнем можно отнести разве что к наличию кэша данных третьего уровня, объем которого позволяет покрыть до 50% обращений к памяти в рассматриваемом случае.
Латентность L1 во всех случаях доступа составляет ровно 2 такта, латентность L2 в среднем 18.5 тактов. Латентность кэша L3 процессора Pentium 4 XE при прямом и обратном доступе почти в два раза выше, чем латентность L2 она составляет 35.5 тактов (а при случайном доступе и того выше, 61 такт процессора, правда, с упомянутой выше оговоркой, что точное измерение последней не представляется возможным ввиду исчерпания D-TLB процессора). Наконец, латентность последнего уровня оперативной памяти характеризуется величинами 57-58 тактов (17.6-18.0 нс) при прямом/обратном доступе, что говорит о наличии хорошего алгоритма Hardware Prefetch, работающего в этих режимах обхода. Латентность случайного доступа в RAM (с той же оговоркой) существенно выше, она составляет 229 тактов (71.0 нс) на Northwood и 185 тактов (57.0 нс) на Gallatin. Меньшую величину латентности памяти на последнем можно отнести разве что к наличию кэша данных третьего уровня, объем которого позволяет покрыть до 50% обращений к памяти в рассматриваемом случае.
Самые неожиданные результаты, как вы, возможно, догадались, конечно же ждут нас в новой архитектуре Prescott. Итак, латентность L1 во всех случаях доступа возросла до 4(!) тактов (выше, чем во всех известных на сегодняшний день современных процессорах), латентность L2 до 28.5 тактов. Изменения, надо сказать, просто поразительные, и явно не в пользу нового 90-нм процессора. Хотя есть и одно утешение: алгоритм Hardware Prefetch, как мы уже предполагали, и вправду улучшен в новой архитектуре 90-нм процессора Pentium 4. Действительно, латентность прямого/обратного обхода памяти уменьшилась до 41 такта процессора (12.7 нс), т.е. почти на 39% по сравнению с предыдущими моделями Pentium 4. В то же время, латентность случайного доступа осталась на уровне Northwood она составляет 225.5 тактов процессора (69.8 нс).
Минимальная латентность L2/L3 кэша данных/памяти
Посмотрим теперь, каких минимальных значений латентности каждого из уровней (L2, L3, RAM) можно достичь на каждой из моделей процессоров Pentium 4. Для этого будем использовать метод разгрузки шины кэша процессора вставкой «пустых» операций. Приведем здесь кривые, полученные в тесте D-Cache Latency с пресетом Minimal L2 Cache Latency, Method 1.
Для этого будем использовать метод разгрузки шины кэша процессора вставкой «пустых» операций. Приведем здесь кривые, полученные в тесте D-Cache Latency с пресетом Minimal L2 Cache Latency, Method 1.
Минимальная латентность L2, Intel Pentium 4 Northwood
Минимальная латентность L2, Intel Pentium 4 XE Gallatin
Минимальная латентность L2, Intel Pentium 4 Prescott
С Northwood и Gallatin все в порядке при вставке уже 15 пустых операций (OR EAX, EDX, время исполнения которой 0.5 такта процессора) достигается минимальная величина латентности L2, равная 9 тактам. Картина на Prescott получается фантастической! Сколько ни вставляй таких пустых операций (время исполнения которых, что немаловажно, возросло в два раза оно составляет ровно один такт процессора), разгрузка шины не наблюдается, и минимальная латентность тоже. Тем не менее, все-таки можно наметить некий минимум, наблюдающийся при двух «NOP»-ах, который составляет 24 такта (все же немного меньше, чем средняя латентность). Серьезные изменения микроархитектуры NetBurst налицо, причем, в очередной раз далеко не в пользу Prescott. Остается только попытаться использовать другой метод разгрузки шины, специально разработанный для процессоров, которые могут осуществлять спекулятивную загрузку данных (которая в случае измерения латентности ни к чему хорошему, кроме штрафов, конечно не приведет). Взглянем на ее результаты на всех трех исследуемых процессорах.
Серьезные изменения микроархитектуры NetBurst налицо, причем, в очередной раз далеко не в пользу Prescott. Остается только попытаться использовать другой метод разгрузки шины, специально разработанный для процессоров, которые могут осуществлять спекулятивную загрузку данных (которая в случае измерения латентности ни к чему хорошему, кроме штрафов, конечно не приведет). Взглянем на ее результаты на всех трех исследуемых процессорах.
Минимальная латентность L2, метод 2, Intel Pentium 4 Northwood
Минимальная латентность L2, метод 2, Intel Pentium 4 XE Gallatin
Минимальная латентность L2, метод 2, Intel Pentium 4 Prescott
И снова Northwood и Gallatin ведут себя вполне адекватно. Минимальная латентность L2 9 тактов, как и положено, и наблюдается она при вставке 18 «NOP»-ов (что в точности соответствует 9 тактам процессора, как и положено в данной методике тестирования). Картина на Prescott, хотя и не принципиально, но иная. Минимум составляет 22 такта, и наблюдается он при 22 «NOP»-ах (а поскольку каждый из них отнимает 1 такт процессора, значит, 22 такта и получается). Так и запишем минимальная латентность L2 у Prescott 22 такта, и ничего больше не скажешь.
Так и запишем минимальная латентность L2 у Prescott 22 такта, и ничего больше не скажешь.
Поскольку у одного из наших «подопытных» есть кэш данных третьего уровня, почему бы нам не оценить минимальную латентность и этого уровня? Для этого возьмем за основу те же пресеты Minimal L2 Cache Latency (Method 1, 2), и увеличим размер блока до 1024 КБ.
Минимальная латентность L3 при прямом и обратном последовательном доступе достигается столь же легко, уже при вставке 20 «пустых» операций, и составляет 20 тактов процессора (некоторое ее снижение до 17 тактов при вставке 53-58 «NOP»-ов остается не очень понятным). Минимальная латентность случайного доступа в L3 намного больше (причина этого уже обсуждалась выше) в нашем тесте она составила 52.7 тактов, что все же меньше, чем ее среднее значение.
Оценим минимальную латентность последнего, общего для всех процессоров «уровня» оперативной памяти. Здесь имеются различия между рассматриваемыми типами процессоров, несмотря на то, что используется один и тот же чипсет и тип памяти.
Минимальная латентность RAM, Intel Pentium 4 Northwood
Минимальная латентность RAM, Intel Pentium 4 XE Gallatin
Минимальная латентность RAM, Intel Pentium 4 Prescott
Первые два типа процессоров вновь ведут себя аналогично. Достигаемое минимальное значение латентности памяти при прямом/обратном доступе составляет 27.3-27.6 тактов (8.4-8.5 нс). Минимальная латентность случайного доступа в память +почти на порядок выше 218 тактов (67.4 нс) на Northwood и 184 такта (57.0 нс) на Gallatin. На последнем она почти не отличается от средней величины (185 тактов). Prescott, как всегда, проявляет себя неожиданным образом. Во-первых, минимальная латентность при прямом/обратном обходе памяти составляет целых 36 тактов процессора (11.2 нс), что на 31% выше по сравнению с предыдущими моделями. Получается, что расхваленный нами Hardware Prefetch далеко не так хорош? По-видимому, все же нет, просто можно сказать, что он специально оптимизирован для «плотных» обращений к памяти, идущих подряд без каких-либо пропусков.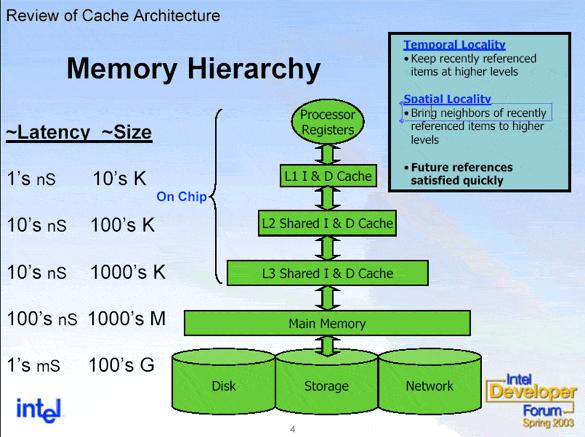 В то время как Hardware Prefetch на более ранних Pentium 4 любит такие пропуски, точнее вставки «пустых» операций между двумя соседними обращениями к памяти. Кроме того, возможно, что в Prescott что-то не так с процедурой разгрузки шины «пустыми» операциями. Хотя бы потому, что этим методом нельзя достичь минимальную латентность RAM при случайном доступе в нашем тесте она составляет 224 такта (69.3 нс), тогда как средняя величина 225.5 тактов, т.е. всего на 1.5 такта выше.
В то время как Hardware Prefetch на более ранних Pentium 4 любит такие пропуски, точнее вставки «пустых» операций между двумя соседними обращениями к памяти. Кроме того, возможно, что в Prescott что-то не так с процедурой разгрузки шины «пустыми» операциями. Хотя бы потому, что этим методом нельзя достичь минимальную латентность RAM при случайном доступе в нашем тесте она составляет 224 такта (69.3 нс), тогда как средняя величина 225.5 тактов, т.е. всего на 1.5 такта выше.
| Уровень, доступ | Минимальная латентность, тактов | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| L1, прямой L1, обратный L1, случайный | 2.0 2.0 2.0 | 2.0 2.0 2.0 | 4.0 4.0 4.0 |
| L2, прямой* L2, обратный* L2, случайный* | 9.0 (9.0) 9.0 (9.0) 9.0 (9.0) | 9.0 (9.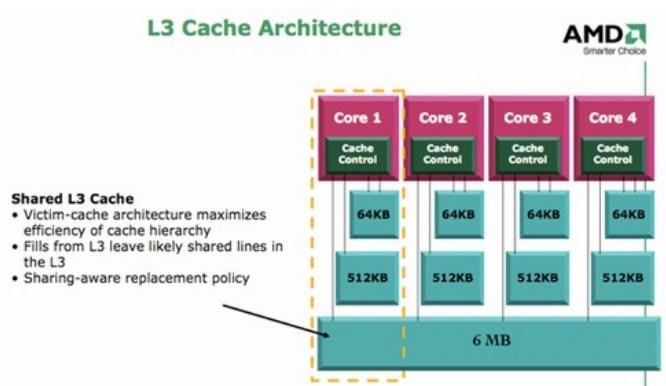 0) 0)9.0 (9.0) 9.0 (9.0) | 24.0 (22.0) 24.0 (22.0) 24.0 (22.0) |
| L3, прямой L3, обратный L3, случайный** | — — — | 20.0 20.0 52.7 | — — — |
| RAM, прямой RAM, обратный RAM, случайный*** | 27.4 (8.4 нс) 27.3 (8.4 нс) 218.0 (67.4 нс) | 27.6 (8.5 нс) 27.6 (8.5 нс) 184.0 (57.0 нс) | 36.0 (11.2 нс) 36.0 (11.2 нс) 224.0 (69.3 нс) |
* В скобках указаны значения, полученные методом 2.
** Размер блока 1 МБ
*** Размер блока 4 МБ
Ассоциативность кэша данных
Ассоциативность кэша данных не менее важная его характеристика, чем его объем или латентность. И здесь, как всегда, нас ждут интересные сюрпризы, причем на этот раз в большей степени даже от Northwood и Gallatin, нежели Prescott. Для получения качественной картины воспользуемся пресетом D-Cache Associativity в тесте D-Cache Latency.
Для получения качественной картины воспользуемся пресетом D-Cache Associativity в тесте D-Cache Latency.
Ассоциативность кэша, Intel Pentium 4 Northwood
Ассоциативность кэша, Intel Pentium 4 XE Gallatin
Ассоциативность кэша, Intel Pentium 4 Prescott
Результаты весьма интересные и трудно интерпретируемые (чего не скажешь об AMD K7/K8 там все выглядело замечательно!). Тем не менее, при большом желании у всех трех Pentium 4 можно выявить две области, особенно различимые по кривым случайного доступа. Первая из них это начальная точка, соответствующая L1 кэшу, который в нашем тесте получился одноассоциативным. Вторая область до 8 цепочек включительно, что соответствует заявленной ассоциативности кэша L2, равной восьми.
То, что ассоциативность L1 в нашем тесте получилась равной единице, является неожиданным результатом. Напомним, что RightMark Memory Analyzer измеряет ассоциативность путем считывания строк кэша с «нехороших» адресов памяти, имеющих смещения друг относительно друга 1 МБ и выше. Это означает, что кэш L1 у всех трех моделей Pentium 4 не может эффективно ассоциироваться более чем с одной из строк памяти, расположенных по таким адресам. Что позволяет нам с полным правом считать, что его реальная, или эффективная ассоциативность действительно равна единице. Причем этот результат нельзя считать недостатком метода, ибо заметим, что кэш L2 в этом же самом методе проявляет свою истинную ассоциативность (8-way set associative).
Это означает, что кэш L1 у всех трех моделей Pentium 4 не может эффективно ассоциироваться более чем с одной из строк памяти, расположенных по таким адресам. Что позволяет нам с полным правом считать, что его реальная, или эффективная ассоциативность действительно равна единице. Причем этот результат нельзя считать недостатком метода, ибо заметим, что кэш L2 в этом же самом методе проявляет свою истинную ассоциативность (8-way set associative).
Остается лишь отметить, что заявленную (именно такую, ибо по честному ее нельзя назвать «истинной» характеристикой) ассоциативность L1, равную четырем (Northwood, Gallatin) или восьми (Prescott) можно достичь, но в особых условиях доступа. А именно, L1 кэш процессоров проявляет свою заявленную ассоциативность только в пределах своего собственного объема (так, каждая строка L1 кэша процессора Prescott объемом 16 КБ способна ассоциироваться с восемью строками памяти, имеющими смещения друг относительно друга 16/8 = 2 КБ).
Реальная пропускная способность шины L1-L2 и L2-L3
Предмет гордости процессоров семейства Pentium 4 это наличие очень широкой, 256-битной шины обмена данными между L1 и L2 кэшем данных. Так почему нам не посмотреть, насколько эффективной она является в реальности, и не претерпела ли она изменений при модификациях архитектуры NetBurst? Для ответа на поставленный вопрос воспользуемся тестом D-Cache Bandwidth, выбрав пресет L1-L2 Cache Bus Bandwidth.
Реальная ПС шины L1-L2, Intel Pentium 4 Northwood
Реальная ПС шины L1-L2, Intel Pentium 4 XE Gallatin
Реальная ПС шины L1-L2, Intel Pentium 4 Prescott
Эффективность этой шины у Northwood и Gallatin на чтение действительно очень высока величина 31.89 байт/такт является нешуточной, т.к. составляет 99.6% от теоретического максимума. По этому показателю микроархитектуре NetBurst действительно есть чем похвастаться. В то же время, эффективность такой шины на запись куда ниже всего 5. 16 байт/такт, а это лишь 16% от теоретического максимума (можно даже предположить, что ее реальная ширина на запись всего 64 бита).
16 байт/такт, а это лишь 16% от теоретического максимума (можно даже предположить, что ее реальная ширина на запись всего 64 бита).
Но как всегда, нас не перестает удивлять новый, улучшенный 90-нм процессор Pentium 4 Prescott! Эффективность его шины L1-L2 упала почти в два раза по сравнению с предыдущими моделями до 16.76 байт/такт (эффективность 52.3%). Поскольку эта величина превышает 16.0 байт/такт, мы все же не можем говорить о том, что шина L1-L2 была «урезана» вдвое, до 128 бит. Нет, скорее имеет место некое умышленное замедление работы той же самой, 256-битной шины. К сожалению, специально разработанный тест прибытия данных (D-Cache Arrival), позволяющий оценивать различные тонкости организации шины данных, в данном случае оказывается бессмысленным за целых 4 такта латентности доступа в кэш L1 из кэша L2 вполне успеют прибыть все 64 байта данных (целая строка) даже в случае использования 128-битной шины. Резюмируя, можно сказать, что путем замедления латентности доступа в кэш L1 в два раза Intel хитро замаскировала и другие «тормоза» своего нового процессора Prescott, в частности, эффективную ПС шины L1-L2.
Что касается эффективной пропускной способности шины L1-L2 на запись, в новом Prescott она также несколько упала, но не столь кардинально, как ее ПС на чтение. Действительно, 4.92-4.97 байт/такт это всего на 4-5% меньше, чем в предыдущих моделях Pentium 4, и так же неэффективно. Как мы уже отмечали в нашей предыдущей статье, процессоры семейства AMD K7/K8, имеющие эксклюзивную организацию L1-L2, характеризуются куда более эффективными значениями ПС L1-L2 на запись строк кэша.
Поскольку в нашем распоряжении имеется процессор Pentium 4 XE с присутствующим в нем кэшем данных третьего уровня, почему бы нам не оценить эффективную ПС соответствующей шины, L2-L3? Для этого возьмем за основу тот же пресет L1-L2 Cache Bus Bandwidth и немного модифицируем параметры теста таким образом:
- Minimal Block Size = 1024KB;
- Maximal Block Size = 2048KB;
- Minimal Stride Size = 128 bytes (да-да, строки кэша из L2 в L3 и, далее, в RAM передаются именно так, в удвоенном объеме).
Полученный результат очень нагляден шина L2-L3 в процессоре Pentium 4 XE является 64-разрядной. Ее эффективность на чтение 6.05 байт/такт (75.6%), на запись в среднем 4.67 байт/такт (58.4%).
| Шина данных, режим доступа | Реальная пропускная способность, байт/такт | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| L1-L2, чтение (прямое) L1-L2, чтение (обратное) L1-L2, запись (прямая) L1-L2, запись (обратная) | 31.89 31.88 5.16 5.16 | 31.89 31.88 5.16 5.16 | 16.76 16.73 4.92 4.97 |
| L2-L3, чтение (прямое) L2-L3, чтение (обратное) L2-L3, запись (прямая) L2-L3, запись (обратная) | — — — — | 6.05 6.05 4.66 4.68 | — — — — |
Trace Cache, эффективность декодирования
Одним из наиболее занимательных элементов микроархитектуры Intel NetBurst является, конечно же, особый кэш инструкций процессора, называемый Trace Cache. Этот кэш хранит результат работы декодера инструкций в форме микроопераций (до 12000 uop включительно), а не индивидуальные байты, составляющие x86-инструкции, как это делается в традиционных моделях L1i кэша, и имеет ряд других преимуществ. Основным следствием такой особенности реализации кэша инструкций является наличие зависимости объема такого кэша от типа используемых инструкций. Для наглядности мы возьмем наиболее показательный пример, позволяющий достичь практически максимального эффективного объема Trace Cache, а также высокой скорости декодирования команд. С этой целью воспользуемся тестом I-Cache, выбрав пресет L1i Size / Decode Bandwidth, CMP Instructions 3.
Этот кэш хранит результат работы декодера инструкций в форме микроопераций (до 12000 uop включительно), а не индивидуальные байты, составляющие x86-инструкции, как это делается в традиционных моделях L1i кэша, и имеет ряд других преимуществ. Основным следствием такой особенности реализации кэша инструкций является наличие зависимости объема такого кэша от типа используемых инструкций. Для наглядности мы возьмем наиболее показательный пример, позволяющий достичь практически максимального эффективного объема Trace Cache, а также высокой скорости декодирования команд. С этой целью воспользуемся тестом I-Cache, выбрав пресет L1i Size / Decode Bandwidth, CMP Instructions 3.
Декодирование команд, Intel Pentium 4 Northwood
Декодирование команд, Intel Pentium 4 XE Gallatin
Декодирование команд, Intel Pentium 4 Prescott
Видно, что на всех трех моделях процессоров достигается значительный эффективный объем Trace Cache, составляющий 63 КБ (10. 5 тысяч микроопераций). При превышении этого объема четко прослеживается «подкачка» кода из унифицированного кэша L2, способного кэшировать как данные, так и код. Точно такой же характеристикой обладает кэш L3 процессора Pentium 4 XE. Легко заметить некоторое снижение скорости исполнения кода при размере блока кода 256 КБ и выше. Именно таким образом проявляет себя сравнительно малый объем TLB, на этот раз TLB инструкций (I-TLB), который, как мы увидим ниже, имеет такой же размер (64 записи, адресация 256 КБ виртуальной памяти). Наконец, инклюзивная организация уровней кэша проявляет себя и в этом случае, т.е. в случае кэширования кода вместо данных.
5 тысяч микроопераций). При превышении этого объема четко прослеживается «подкачка» кода из унифицированного кэша L2, способного кэшировать как данные, так и код. Точно такой же характеристикой обладает кэш L3 процессора Pentium 4 XE. Легко заметить некоторое снижение скорости исполнения кода при размере блока кода 256 КБ и выше. Именно таким образом проявляет себя сравнительно малый объем TLB, на этот раз TLB инструкций (I-TLB), который, как мы увидим ниже, имеет такой же размер (64 записи, адресация 256 КБ виртуальной памяти). Наконец, инклюзивная организация уровней кэша проявляет себя и в этом случае, т.е. в случае кэширования кода вместо данных.
Для более детального исследования характеристик Trace Cache и декодера процессоров рассматриваемого семейства мы провели ряд дополнительных тестов, использующих как независимые, так и зависимые ALU-операции. Результаты этих тестов для каждого из «подопытных» процессоров представлены в виде отдельных таблиц.
Эффективность декодирования, Pentium 4 Northwood
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP | 10. 0 (10.0) 0 (10.0) | 2.89 (2.89) | 0.99 (0.99) |
| SUB | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) |
| XOR | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| TEST | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| XOR/ADD | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) |
| CMP 1 | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) |
| CMP 2 | 44.0 (11.0) | 11.61 (2.90) | 3.98 (0.99) |
| CMP 3 | 63.0 (10.5) | 17.45 (2.91) | 5.62 (0.94) |
| CMP 4 | 63.0 (10.5) | 17.45 (2.91) | 5.62 (0.94) |
| CMP 5 | 63.0 (10.5) | 17.45 (2.91) | 5.62 (0.94) |
| CMP 6* | 32.0 (10.6) | 8.75 (1.46) | 5.52 (0.92) |
| Prefixed CMP 1 | 63.0 (7.9; 10.5**) | 23.21 (2.90) | 3.99 (0.50) |
| Prefixed CMP 2 | 63. 0 (7.9; 10.5**) 0 (7.9; 10.5**) | 23.21 (2.90) | 3.99 (0.50) |
| Prefixed CMP 3 | 63.0 (7.9; 10.5**) | 23.21 (2.90) | 3.99 (0.50) |
| Prefixed CMP 4* | 44.0 (11.0; 14.7**) | 11.69 (1.46) | 3.99 (0.50) |
| Зависимые | |||
| LEA | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| MOV | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| ADD | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| OR | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) |
| SHL | — | 0.75 (0.25) | 0.75 (0.25) |
| ROL | — | 0.75 (0.25) | 0.75 (0.25) |
* 2 микрооперации
** в предположении, что префиксы отбрасываются еще до помещения в Trace Cache
Эффективность декодирования, Pentium 4 XE Gallatin
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | ||
|---|---|---|---|---|
| Trace Cache | L2 Cache | L3 Cache | ||
| Независимые | ||||
| NOP | 10. 0 (10.0) 0 (10.0) | 2.89 (2.89) | 0.99 (0.99) | 0.99 (0.99) |
| SUB | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) | 1.99 (0.99) |
| XOR | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.99 (0.99) |
| TEST | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.99 (0.99) |
| XOR/ADD | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) | 1.99 (0.99) |
| CMP 1 | 22.0 (11.0) | 5.79 (2.89) | 1.99 (0.99) | 1.99 (0.99) |
| CMP 2 | 44.0 (11.0) | 11.62 (2.90) | 3.98 (0.99) | 2.64 (0.66) |
| CMP 3 | 63.0 (10.5) | 17.44 (2.91) | 5.62 (0.94) | 2.60 (0.43) |
| CMP 4 | 63.0 (10.5) | 17.44 (2.91) | 5.62 (0.94) | 2.60 (0.43) |
| CMP 5 | 63.0 (10.5) | 17.44 (2.91) | 5.62 (0.94) | 2.60 (0.43) |
| CMP 6* | 32. 0 (10.6) 0 (10.6) | 8.75 (1.46) | 5.53 (0.92) | 2.60 (0.43) |
| Prefixed CMP 1 | 63.0 (7.9; 10.5**) | 23.22 (2.90) | 4.00 (0.50) | 2.64 (0.33) |
| Prefixed CMP 2 | 63.0 (7.9; 10.5**) | 23.21 (2.90) | 4.00 (0.50) | 2.64 (0.33) |
| Prefixed CMP 3 | 63.0 (7.9; 10.5**) | 23.21 (2.90) | 4.00 (0.50) | 2.64 (0.33) |
| Prefixed CMP 4* | 44.0 (11.0; 14.7**) | 11.69 (1.46) | 3.99 (0.50) | 2.64 (0.33) |
| Зависимые | ||||
| LEA | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.98 (0.99) |
| MOV | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.98 (0.99) |
| ADD | 22.0 (11.0) | 3.98 (1.99) | 1.99 (0.99) | 1.98 (0.99) |
| OR | 22.0 (11.0) | 3.98 (1. 99) 99) | 1.99 (0.99) | 1.98 (0.99) |
| SHL | — | 0.75 (0.25) | 0.75 (0.25) | 0.75 (0.25) |
| ROL | — | 0.75 (0.25) | 0.75 (0.25) | 0.75 (0.25) |
* 2 микрооперации
** в предположении, что префиксы отбрасываются еще до помещения в Trace Cache
Как обычно, начнем с рассмотрения процессоров Pentium 4 нынешнего поколения Northwood и Gallatin, а затем перейдем к новому процессору Prescott. Тем более что первые два практически не отличаются друг от друга, а последний, как всегда, вносит определенную сумятицу.
Легко заметить, что объем Trace Cache во всех случаях, в пересчете на количество микроопераций, реально не превышает величину 11000 uop, что позволяет предположить наличие некоторого резерва в одну тысячу микроопераций, отводящегося под служебные нужды. Максимальная скорость исполнения простых команд из Trace Cache достигает 2.9 операций/такт. При этом видно, что она лимитируется именно исполнительным блоком процессора (предельная скорость работы которого 3 микрооперации/такт), а не скоростью «подкачки» инструкций из Trace Cache, в пересчете на размер x86 команд (скорость исполнения достигает 17.44 байт/такт и выше). По этому показателю процессоры семейства Pentium 4 выгодно отличаются от рассмотренных нами ранее AMD K7/K8, где скорость исполнения больших x86 команд лимитировалась именно скоростью «подкачки» инструкций из L1i в исполнительный блок процессора (не более 16 байт/такт).
При этом видно, что она лимитируется именно исполнительным блоком процессора (предельная скорость работы которого 3 микрооперации/такт), а не скоростью «подкачки» инструкций из Trace Cache, в пересчете на размер x86 команд (скорость исполнения достигает 17.44 байт/такт и выше). По этому показателю процессоры семейства Pentium 4 выгодно отличаются от рассмотренных нами ранее AMD K7/K8, где скорость исполнения больших x86 команд лимитировалась именно скоростью «подкачки» инструкций из L1i в исполнительный блок процессора (не более 16 байт/такт).
Среди независимых инструкций неожиданный результат наблюдается в случае XOR и TEST, предельная скорость исполнения которых оказывается равной всего двум операциям за такт процессора, в точности так же, как и зависимых LEA/MOV/ADD/OR. Причина этого кроется, по всей видимости, в возможности исполнения указанных инструкций только в одном из двух блоков FastALU. Действительно, как нетрудно видеть, «разбавка» команды XOR операцией ADD (XOR/ADD) приводит к увеличению скорости исполнения такого кода до предельного значения 2. 9 байт/такт.
9 байт/такт.
Отдельного внимания заслуживает код CMP 6, представляющий собой повторяющиеся инструкции CMP EAX, 0x7FFFFFFF. Такая операция, как видно по результатам нашего тестирования, представляет собой две микрооперации, в отличие от всех других рассмотренных случаев. В связи с этим, эффективная скорость ее исполнения, в пересчете на количество x86 операций в два раза ниже (1.46 байт/такт).
Не менее интересными и важными являются результаты тестирования кода, содержащего CMP-инструкции с двумя «бессмысленными» префиксами. Увеличение скорости его исполнения до 23.2 байт/такт, а также кажущееся уменьшение эффективного объема Trace Cache при декодировании таких операций позволяют предположить, что «бессмысленные» префиксы отсекаются еще декодером x86-инструкций до помещения соответствующей микрооперации в Trace Cache. В таком предположении эффективный объем Trace Cache оказывается не меньшим, чем при хранении CMP-инструкций (10.5 тысяч микроопераций). В то же время, использование кода Prefixed CMP 4 ([0xF3][0x67]CMP EAX, 0x7FFFFFFF) вносит определенные недоразумения в сделанное нами предположения. Действительно, если считать, что префиксы отсекаются еще до помещения в Trace Cache, а собственно 32-битная инструкция CMP разбивается на 2 микрооперации, эффективный объем Trace Cache получается равным 14.7 тысячам микроопераций, что больше заявленного значения в документации значения в 12 тысяч. Таким образом, реальное положение дел, по-видимому, обстоит намного сложнее, нежели в сделанном нами простом предположении.
Действительно, если считать, что префиксы отсекаются еще до помещения в Trace Cache, а собственно 32-битная инструкция CMP разбивается на 2 микрооперации, эффективный объем Trace Cache получается равным 14.7 тысячам микроопераций, что больше заявленного значения в документации значения в 12 тысяч. Таким образом, реальное положение дел, по-видимому, обстоит намного сложнее, нежели в сделанном нами простом предположении.
Что касается подкачки команд из унифицированного L2 кэша кода/данных, тут все сильно зависит от типа самих команд. А подкачиваются они, как можно заметить, с темпом примерно 1 инструкция/такт, независимо от того, сколько реально позволяет L2 кэш. И только инструкции типа Prefixed CMP, по каким-то причинам, закачиваются из L2 с меньшим темпом всего половина инструкции/такт. Как видно из второй таблицы, подкачка кода может идти и из третьего уровня кэша процессора Pentium 4 XE (Gallatin). В этом случае, похоже, скорость исполнения кода лимитируется уже скоростными показателями этого уровня кэша, ибо все упирается в некое загадочное значение 2.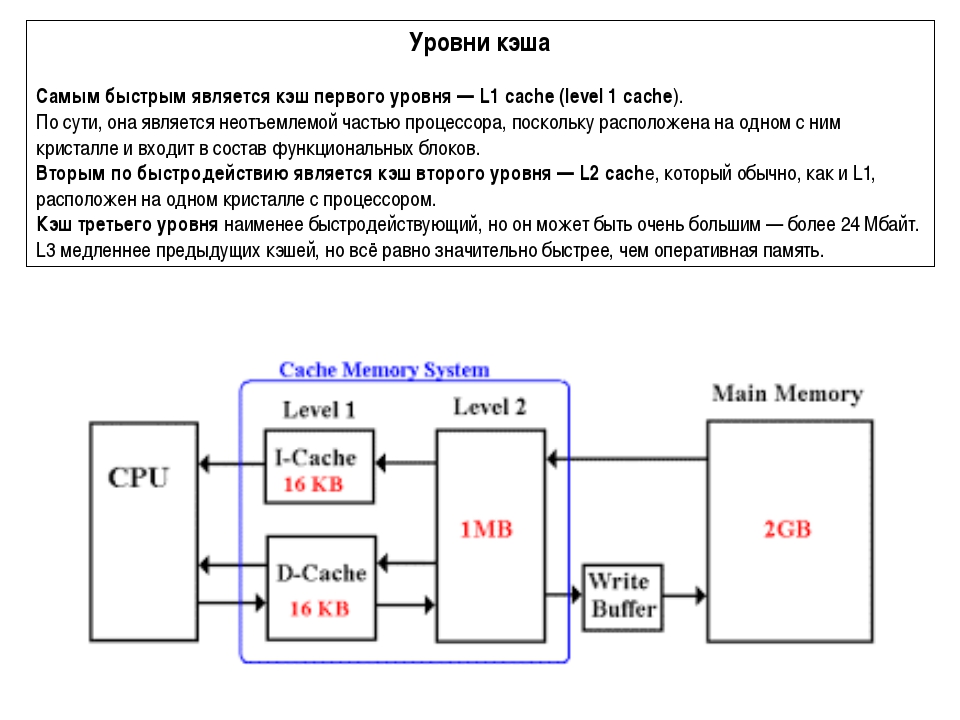 64 байт/такт (для инструкций размером 4-8 байт).
64 байт/такт (для инструкций размером 4-8 байт).
Эффективность декодирования, Pentium 4 Prescott
| Тип инструкций | Эффективный объем Trace Cache, КБ (Kuop) | Эффективность декодирования, байт/такт (инструкций/такт) | |
|---|---|---|---|
| Trace Cache | L2 Cache | ||
| Независимые | |||
| NOP | 10.0 (10.0) | 2.85 (2.85) | 0.99 (0.99) |
| SUB | 22.0 (11.0) | 5.70 (2.85) | 1.99 (0.99) |
| XOR | 22.0 (11.0) | 3.97 (1.98) | 1.99 (0.99) |
| TEST | 22.0 (11.0) | 3.97 (1.98) | 1.99 (0.99) |
| XOR/ADD | 22.0 (11.0) | 5.70 (2.85) | 1.99 (0.99) |
| CMP 1 | 22.0 (11.0) | 5.70 (2.85) | 1.99 (0.99) |
| CMP 2 | 44.0 (11.0) | 10.29 (2.57) | 3.98 (0.99) |
| CMP 3 | 63.0 (10. 5) 5) | 15.50 (2.58) | 4.25 (0.71) |
| CMP 4 | 63.0 (10.5) | 15.50 (2.58) | 4.25 (0.71) |
| CMP 5 | 63.0 (10.5) | 15.50 (2.58) | 4.25 (0.71) |
| CMP 6* | 32.0 (10.6) | 8.62 (1.44) | 4.25 (0.71) |
| Prefixed CMP 1 | 63.0 (7.9; 10.5**) | 20.66 (2.58) | 4.40 (0.55) |
| Prefixed CMP 2 | 63.0 (7.9; 10.5**) | 20.66 (2.58) | 4.40 (0.55) |
| Prefixed CMP 3 | 63.0 (7.9; 10.5**) | 20.66 (2.58) | 4.40 (0.55) |
| Prefixed CMP 4* | 44.0 (11.0; 14.7**) | 11.53 (1.44) | 4.40 (0.55) |
| Зависимые | |||
| LEA | — | 1.99 (0.99) | 1.99 (0.99) |
| MOV | — | 1.99 (0.99) | 1.99 (0.99) |
| ADD | — | 1.99 (0.99) | 1. 99 (0.99) 99 (0.99) |
| OR | — | 1.99 (0.99) | 1.99 (0.99) |
| SHL | — | 3.00 (1.00) | 3.00 (1.00) |
| ROL | — | 3.00 (1.00) | 3.00 (1.00) |
* 2 микрооперации
** в предположении, что префиксы отбрасываются еще до помещения в Trace Cache
Посмотрим теперь, какие сюрпризы нам приготовила новая, улучшенная архитектура NetBurst процессоров Pentium 4 Prescott. Что касается независимых операций, серьезных изменений не наблюдается. По крайней мере, Trace Cache остался в точности таким же. Уменьшилась лишь скорость исполнения команд (микроопераций), но это уже претензии к исполнительному блоку процессора (увеличенная длина конвейера, конечно же, в этом тесте проявляет себя незамедлительно). Падение производительности составляет от 1.7 (простейшие операции вроде NOP и SUB) до 12.4% (длинные CMP и Prefixed CMP). XOR и TEST здесь ведут себя аналогично для достижения пиковой скорости им необходима «разбавка» другими ALU-операциями. Значит, и организация ALU осталась более-менее такой же.
Значит, и организация ALU осталась более-менее такой же.
Без сюрпризов со стороны Prescott нам, конечно, не обойтись. На этот раз это обработка зависимых команд, вроде LEA/MOV/ADD/OR. Как видно из таблицы, они ведут себя одинаково и исполняются со скоростью всего-навсего 1 операция/такт (кстати, напомним, что то, что OR ведет себя именно так, мы выяснили еще в тесте минимальной латентности L2/RAM). Именно поэтому здесь мы даже не смогли оценить эффективную границу Trace Cache, ибо их скорость исполнения как из L1i, так и из L2 одинакова 2 байта/такт.
Но есть и приятный сюрприз это обещанное улучшение поддержки операций Shift и Rotate. В этом отношении заметен ощутимый прогресс латентность исполнения таких команд на Prescott уменьшилась до 1 такта, против 4 тактов у предыдущего поколения процессоров Pentium 4.
Вернемся к затронутому выше вопросу об отсечении префиксов, тем более что в RightMark Memory Analyzer есть специальный тест, позволяющий оценить эффективность декодирования/исполнения x86-команды NOP с произвольным количеством префиксов [0x66]. Для этого выберем пресет Prefixed NOP Decode Efficiency. Результаты теста на всех трех процессорах сведены в следующую таблицу.
Для этого выберем пресет Prefixed NOP Decode Efficiency. Результаты теста на всех трех процессорах сведены в следующую таблицу.
| Количество префиксов | Эффективность декодирования, байт/такт (инструкций/такт) | ||
|---|---|---|---|
| P4 Northwood | P4XE Gallatin | P4 Prescott | |
| 0 | 2.89 (2.89) | 2.89 (2.89) | 2.84 (2.84) |
| 1 | 5.78 (2.89) | 5.75 (2.88) | 5.68 (2.84) |
| 2 | 8.59 (2.86) | 8.59 (2.86) | 8.52 (2.84) |
| 3 | 11.44 (2.86) | 11.41 (2.85) | 11.34 (2.84) |
| 4 | 14.25 (2.85) | 14.25 (2.85) | 14.09 (2.82) |
| 5 | 17.11 (2.85) | 17.10 (2.85) | 16.89 (2.82) |
| 6 | 19.73 (2.82) | 19.75 (2.82) | 19.51 (2.79) |
| 7 | 22.57 (2.82) | 22.55 (2.82) | 22.30 (2.79) |
| 8 | 25. 20 (2.80) 20 (2.80) | 25.18 (2.80) | 24.87 (2.76) |
| 9 | 27.94 (2.79) | 27.92 (2.79) | 27.54 (2.75) |
| 10 | 30.88 (2.81) | 30.88 (2.81) | 30.76 (2.80) |
| 11 | 33.39 (2.78) | 33.39 (2.78) | 33.24 (2.77) |
| 12 | 36.02 (2.77) | 36.00 (2.77) | 35.86 (2.76) |
| 13 | 38.38 (2.74) | 38.38 (2.74) | 38.18 (2.73) |
| 14 | 41.06 (2.74) | 41.07 (2.74) | 40.85 (2.72) |
Получается очевидная картина. При увеличении количества «бессмысленных» префиксов на всех трех процессорах наблюдается линейный рост скорости исполнения такой x86-команды, в результате чего достигаются воистину фантастические скорости выполнения, в пересчете на количество байт до 41 байт/такт. В то же время, если пересчитать полученные значения на реальное количество исполняемых операций (NOP), мы получим типичные значения скорости исполнения команды NOP (2. 7-2.9 операций/такт, значения в скобках), лишь незначительно уменьшающиеся при увеличении количества префиксов. А это означает, что декодер NetBurst, по всей видимости, действительно умеет отделять бессмысленные префиксы еще на стадии генерирования микроопераций, непосредственно перед помещением последних в Trace Cache процессора.
7-2.9 операций/такт, значения в скобках), лишь незначительно уменьшающиеся при увеличении количества префиксов. А это означает, что декодер NetBurst, по всей видимости, действительно умеет отделять бессмысленные префиксы еще на стадии генерирования микроопераций, непосредственно перед помещением последних в Trace Cache процессора.
Напоследок нам остается оценить ассоциативность кэша L1 инструкций (Trace Cache) и кэша L2 при исполнении кода из последнего. Для этого используем пресет I-Cache Associativity.
Ассоциативность кэша инструкций, Intel Pentium 4 Northwood
Ассоциативность кэша инструкций, Intel Pentium 4 XE Gallatin
Ассоциативность кэша инструкций, Intel Pentium 4 Prescott
Northwood и Prescott дают довольно четкую картину, по которой можно судить, что ассоциативность Trace Cache равна единице, в то время как объединенный L2 кэш инструкций/данных имеет ассоциативность, равную восьми (именно такое значение было получено нами ранее при исследовании ассоциативности кэша данных). Картина на Gallatin оказывается несколько более размытой ввиду наличия дополнительного уровня кэша, ассоциативность которого, по крайней мере, не превышает ассоциативность L2 кэша.
Картина на Gallatin оказывается несколько более размытой ввиду наличия дополнительного уровня кэша, ассоциативность которого, по крайней мере, не превышает ассоциативность L2 кэша.
Характеристики D-TLB
О D-TLB мы уже говорили довольно много, настало время наконец исследовать его характеристики специализированным тестом (D-TLB). Для начала оценим его размер, который, согласно неоднократно сделанным выводам, должен составлять всего 64 записи. Используем с этой целью пресет D-TLB Size.
Размер D-TLB, Intel Pentium 4 Northwood
Размер D-TLB, Intel Pentium 4 XE Gallatin
Размер D-TLB, Intel Pentium 4 Prescott
Наше предположение относительно размера и структуры D-TLB подтверждается для всех трех процессоров: он одноуровневый, и размер этого единственного уровня D-TLB равен 64 записям (дескрипторам страниц памяти). Что является более потрясающим фактом, так это то, насколько же дорого обходится (с точки зрения количества тактов процессора) промах D-TLB. Действительно, латентность доступа в L1 кэш в условиях промаха D-TLB составляет порядка 57 тактов (Northwood, Gallatin) и 60-67 тактов на Prescott. Аналогичная картина на процессорах семейства AMD K7/K8, даже в случае промаха L2 D-TLB, куда лучше латентность доступа в L1 в этих условиях не превышает 30-36 тактов процессора.
Действительно, латентность доступа в L1 кэш в условиях промаха D-TLB составляет порядка 57 тактов (Northwood, Gallatin) и 60-67 тактов на Prescott. Аналогичная картина на процессорах семейства AMD K7/K8, даже в случае промаха L2 D-TLB, куда лучше латентность доступа в L1 в этих условиях не превышает 30-36 тактов процессора.
Попытаемся теперь оценить ассоциативность D-TLB. Для этого используем пресет D-TLB Associativity, 32 Entries.
Ассоциативность D-TLB, Intel Pentium 4 Northwood
Ассоциативность D-TLB, Intel Pentium 4 XE Gallatin
Ассоциативность D-TLB, Intel Pentium 4 Prescott
Интерпретация результатов предельно проста во всех трех моделях процессоров Pentium 4 первый и единственный уровень D-TLB является полноассоциативным.
Характеристики I-TLB
Измерим характеристики TLB инструкций по аналогии с тем, как мы тестировали D-TLB. Вопрос о размере I-TLB также уже частично затрагивался в разделе, посвященном тестированию Trace Cache, где мы увидели, что эффективность декодирования несколько снижается при превышении величины размера блока кода 256 КБ. Это позволило нам предположить, что I-TLB в процессорах семейства Pentium 4 также содержит всего 64 записи для адресации 4-килобайтовых страниц виртуальной памяти. Проверим это предположение с помощью теста I-TLB, пресет I-TLB Size.
Это позволило нам предположить, что I-TLB в процессорах семейства Pentium 4 также содержит всего 64 записи для адресации 4-килобайтовых страниц виртуальной памяти. Проверим это предположение с помощью теста I-TLB, пресет I-TLB Size.
Размер I-TLB, Intel Pentium 4 Northwood
Размер I-TLB, Intel Pentium 4 XE Gallatin
Размер I-TLB, Intel Pentium 4 Prescott
Итак, размер I-TLB у всех трех процессоров действительно соответствует 64 записям дескрипторов страниц (256 КБ) виртуальной памяти. Промах I-TLB обходится не менее серьезно, чем D-TLB латентность исполнения кода, соответствующего «прыжкам» по страницам виртуальной памяти, возрастает примерно на порядок (до 36 тактов, Northwood/Gallatin и 44 тактов, Prescott) при выходе за границы объема I-TLB.
Нам остается определить ассоциативность I-TLB, воспользовавшись пресетом I-TLB Associativity, 32 Entries.
Ассоциативность I-TLB, Intel Pentium 4 Northwood
Ассоциативность I-TLB, Intel Pentium 4 XE Gallatin
Ассоциативность I-TLB, Intel Pentium 4 Prescott
Результат нашего последнего теста показывает, что I-TLB, как и D-TLB в рассматриваемых процессорах, является полностью ассоциативным. В заключение отметим, что со структурной точки зрения ни D-TLB, ни I-TLB не претерпели каких-либо изменений при переходе к новой микроархитектуре NetBurst, реализованной в 90-нм процессорах Pentium 4 Prescott.
В заключение отметим, что со структурной точки зрения ни D-TLB, ни I-TLB не претерпели каких-либо изменений при переходе к новой микроархитектуре NetBurst, реализованной в 90-нм процессорах Pentium 4 Prescott.
Заключение
Настало время подвести итог. Надо сказать, что новая микроархитектура Prescott произвела на нас весьма неоднозначное впечатление. С одной стороны это улучшенная поддержка Hardware и Software Prefetch, позволяющая достичь больших значений максимальной действительной пропускной способности памяти. Тем не менее, похоже, что на этом положительные моменты новой микроархитектуры заканчиваются. Нет, конечно, есть ряд других приятных моментов снижение латентности исполнения инструкций Shift и Rotate с четырех до одного такта, ну и, конечно, введение нового набора SIMD-инструкций SSE3, которые мы подробно рассмотрим в отдельной статье. А в остальном остается сплошное разочарование. Увеличение латентности доступа в L1/L2 кэш, снижение эффективной пропускной способности шины между этими уровнями кэша почти в два раза, увеличение латентности исполнения ряда инструкций можно ли назвать такие моменты «улучшениями» микроархитектуры NetBurst? Скорее, нет, имеет место умышленное сдерживание ее потенциала. Например, для того, чтобы будущие процессоры Pentium 4 с ядром Tejas выглядели на фоне Prescott значительно лучше. Ведь с выпуском последних Intel наверняка уберет все эти сдерживающие моменты, и будет демонстрировать всем свое новое «чудо техники». Впрочем, настанет время, и мы обязательно доберемся до низкоуровневого тестирования и Tejas, вскрывая тем самым все ключевые изменения микроархитектуры NetBurst, в точности так же, как мы поступили в этой статье с Prescott.
Например, для того, чтобы будущие процессоры Pentium 4 с ядром Tejas выглядели на фоне Prescott значительно лучше. Ведь с выпуском последних Intel наверняка уберет все эти сдерживающие моменты, и будет демонстрировать всем свое новое «чудо техники». Впрочем, настанет время, и мы обязательно доберемся до низкоуровневого тестирования и Tejas, вскрывая тем самым все ключевые изменения микроархитектуры NetBurst, в точности так же, как мы поступили в этой статье с Prescott.
Приложение 1: Влияние технологии Hyper-Threading
В предлагаемом вашему вниманию небольшом приложении мы попытались оценить, сказывается ли наличие/отсутствие технологии Hyper-Threading (точнее, ее включение или отключение в BIOS) на величины каких-либо низкоуровневых параметров платформ Intel Pentium 4, и если да, то как именно. Поводом к этому исследованию явились обнаруженные экспериментально различия в значениях дескрипторов кэша/TLB, выдаваемых функцией CPUID (EAX = 2) процессоров семейства Intel Pentium 4.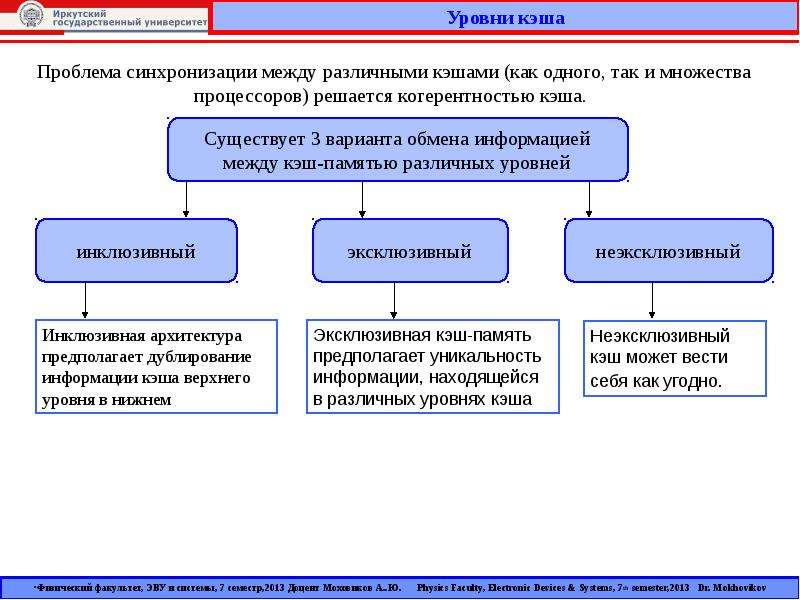 Собственно, различия были обнаружены лишь в одном дескрипторе, отвечающем за размер I-TLB.
Собственно, различия были обнаружены лишь в одном дескрипторе, отвечающем за размер I-TLB.
| Модель процессора | Значение | Описание |
|---|---|---|
| P4 Northwood 2.4 ГГц, без Hyper-Threading | 50h | Instruction TLB: 4K, 2M or 4M pages, fully associative, 64 entries |
| P4 Northwood 3.06 ГГц, с Hyper-Threading | 51h | Instruction TLB: 4K, 2M or 4M pages, fully associative, 128 entries |
Мы решили проверить, так ли это на самом деле, для чего запустили реализованный в RMMA v2.5 тест I-TLB (пресет I-TLB Size). Результаты теста на Northwood и Prescott оказались одинаковыми ниже мы приводим картинки, полученные на последнем.
Размер I-TLB, Intel Pentium 4 Prescott, HT on
Размер I-TLB, Intel Pentium 4 Prescott, HT off
Что ж, размер I-TLB при включении технологии Hyper-Threading действительно уменьшается вдвое, но его промах в обоих случаях обходится процессору одинаково (латентность возрастает на порядок).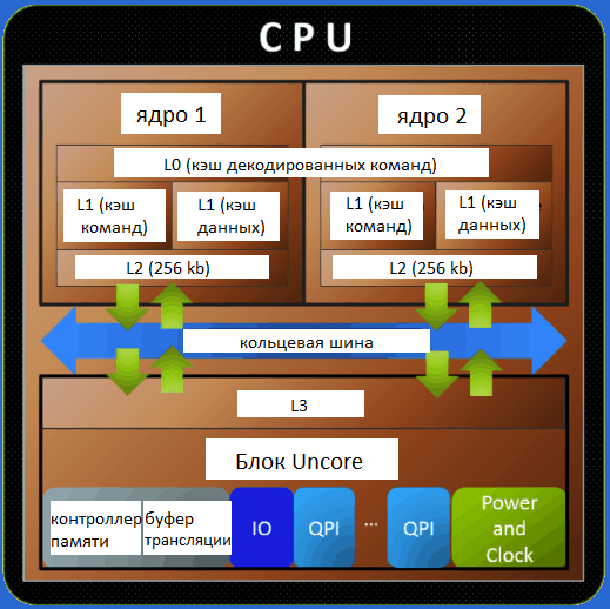 Таким образом, можно сказать, что включение Hyper-Threading как бы приводит к разделению этого буфера на две части каждому логическому процессору достается своя половина. В связи с чем, используя терминологию Intel, I-TLB можно отнести к «разделяемому» (partitioned) типу ресурсов процессора. Таковыми, согласно документации Intel, является большинство различных буферов, реализованных в микроархитектуре NetBurst в качестве примера приводятся буферы очередей микроопераций (находящиеся после Trace Cache), переименованных регистров (естественно, каждому логическому процессору необходим как бы отдельный набор регистров), буфер переупорядочивания микроопераций (reorder buffer), а также буферы загрузки-сохранения данных (load-store buffers). Интересно, что I-TLB, разделение которого видно невооруженным глазом, никак не упоминается. Разделение таких буферов, как отмечает Intel, призвано минимизировать простои одного логического процессора в случае, если второй логический процессор «застрял» в результате какого-либо промаха (промаха кэша, неправильно предсказанного ветвления, зависимости инструкций и т.
Таким образом, можно сказать, что включение Hyper-Threading как бы приводит к разделению этого буфера на две части каждому логическому процессору достается своя половина. В связи с чем, используя терминологию Intel, I-TLB можно отнести к «разделяемому» (partitioned) типу ресурсов процессора. Таковыми, согласно документации Intel, является большинство различных буферов, реализованных в микроархитектуре NetBurst в качестве примера приводятся буферы очередей микроопераций (находящиеся после Trace Cache), переименованных регистров (естественно, каждому логическому процессору необходим как бы отдельный набор регистров), буфер переупорядочивания микроопераций (reorder buffer), а также буферы загрузки-сохранения данных (load-store buffers). Интересно, что I-TLB, разделение которого видно невооруженным глазом, никак не упоминается. Разделение таких буферов, как отмечает Intel, призвано минимизировать простои одного логического процессора в случае, если второй логический процессор «застрял» в результате какого-либо промаха (промаха кэша, неправильно предсказанного ветвления, зависимости инструкций и т. п.).
п.).
В то же время, анализ дескрипторов кэша, да и проведенные тесты D-TLB (пресет D-TLB Size) не показали каких-либо различий в размере этого буфера при включении и выключении Hyper-Threading он остается равным 64 записям в обоих случаях, т.е. при включении Hyper-Threading становится общим для обоих логических процессоров (в терминологии Intel «обобщенный» (shared) ресурс процессора). Обобщенными ресурсами при задействовании Hyper-Threading становится большинство ресурсов процессора целью этого является повышение эффективности динамической утилизации соответствующего ресурса. К ним относятся кэши процессора и все исполнительные ресурсы. Касательно D-TLB, который, как мы обнаружили, действительно является обобщенным ресурсом, в документации отмечается, что его записи в этом случае содержат идентификатор логического процессора.
В заключение отметим, что результаты всех остальных тестов RMMA не показали каких-либо значимых различий в остальных важнейших низкоуровневых параметрах процессоров при включении/отключении технологии Hyper-Threading. Разумеется, с той оговоркой, отмеченной в документации RMMA, что тестирование процессоров Pentium 4 в режиме Hyper-Threading проводилось в строго «однопоточном» режиме, т.е. в условиях минимальной загрузки системы посторонними процессами.
Разумеется, с той оговоркой, отмеченной в документации RMMA, что тестирование процессоров Pentium 4 в режиме Hyper-Threading проводилось в строго «однопоточном» режиме, т.е. в условиях минимальной загрузки системы посторонними процессами.
CPU Level 3 Cache
| Доступные параметры | Enabled |
| Disabled(по умолчанию) |
Абсолютно во всех процессорах есть кэш первого и второго уровня, которые расположены непосредственно на кристалле. Современные многоядерные процессоры обладают и кэшем третьего уровня, который динамически распределяется между всеми. Он является самым медленным, но в то же время самым объемным — до 15 Мб и выше!
Именно благодаря CPU Level 3 Cache удается добиться настоящей многопоточности работы процессора. По сути, он является своеобразной «прослойкой» межу кэшем второго уровня и оперативной памятью. Это позволяет значительно сократить количество обращений процессора к RAM, благодаря чему уменьшается время его простоя.
Многие производители BIOS уже добавили в свои прошивки возможность включать и выключать кэш третьего уровня. Зачем же выключать такую полезную функцию? Дело в том, что в некоторых случаях лучше, чтобы данные грузились напрямую в кэш второго уровня. Например, при математических вычислениях, когда обрабатываемые данные занимают немного памяти. В таком случае лишняя прослойка между оперативной памятью и кэшем 2-го уровня будет только тормозить процесс.
Но все же большинство прикладных приложений работает с большими объемами данных и ориентировано на многопоточное выполнение. В таком случае отключение кэша третьего уровня может привести к значительному ухудшению производительности. Если вам кажется, что компьютер работает не на пределе своих возможностей, то следует зайти в биос и обратить внимание на функцию CPU Level 3 Cache. Она должна быть переключена в состояние Enable. Отключать функцию следует только при разгоне процессора и для работы с небольшими объемами данных.
Отключение кэша третьего уровня также помогает при диагностике процессора.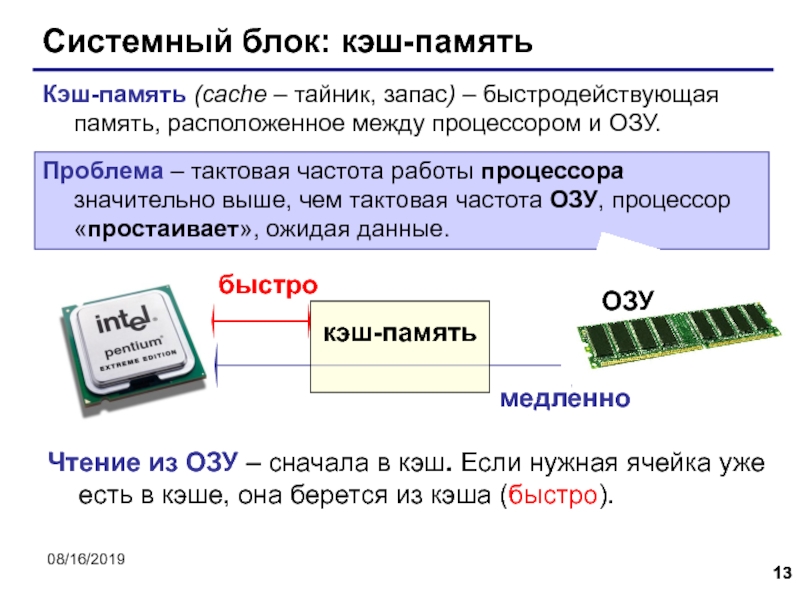 Если он не может преодолеть определенное значение частоты, то можно попробовать загрузить его при отключенном кэше. Если в таком случае получится разогнать его сильнее, значит, с процессором все в порядке и его частоту ограничивал кэш. Это не означает, что процессор стал более продуктивным, просто такты в таком случае становятся менее эффективными, и ему приходится разгоняться, чтобы поддерживать общую скорость работы системы. При отключении кэша третьего уровня вы можете столкнуться с постоянным повисанием системы, так как в таком случае процессор будет простаивать, ожидая обмена данными между кэшем второго уровня и оперативной памятью. Это будет особенно заметно в играх и на серверных компьютерах с большой нагрузкой.
Если он не может преодолеть определенное значение частоты, то можно попробовать загрузить его при отключенном кэше. Если в таком случае получится разогнать его сильнее, значит, с процессором все в порядке и его частоту ограничивал кэш. Это не означает, что процессор стал более продуктивным, просто такты в таком случае становятся менее эффективными, и ему приходится разгоняться, чтобы поддерживать общую скорость работы системы. При отключении кэша третьего уровня вы можете столкнуться с постоянным повисанием системы, так как в таком случае процессор будет простаивать, ожидая обмена данными между кэшем второго уровня и оперативной памятью. Это будет особенно заметно в играх и на серверных компьютерах с большой нагрузкой.
Порекомендуйте Друзьям статью:
Уровни кэша (кеша) процессора — зависимость производительности от уровня. Иерархия кеша (кэша) и для чего она нужна.
Микропроцессор, как правило, имеет несколько уровней КЭШ—а (processor cache memory, кеш). Первый (L1 & L1i (кэш для инструкций)), второй (L2) и третий (L3) ( на серверных решениях бывает и больше).
Первый (L1 & L1i (кэш для инструкций)), второй (L2) и третий (L3) ( на серверных решениях бывает и больше).
Чем ниже по рангу кэш, тем медленней скорость его работы.
Первый уровень обычно работает на частоте процессора и имеет самую широкую шину, но и самый маленький объём. Служит для адресации команд и инструкций, но не их временного хранения.
Второй и третий уровни КЭШ-а служат для записи значений вычислений и для служебной информации, используемой чаще всего в данный момент. Имеет в несколько раз больший объём, чем кэш первого уровня, но и в несколько раз меньшую шину, что отрицательно сказывается на пропускной способности.
Кэш бывает разделяемый (на каждое ядро) и общий (объединённый).
Бесспорно, общий кэш работает быстрее. Так как в разделённом кэше, если одному ядру требуется информация, которая до этого была просчитана другим ядром и находится в его КЭШе, то ей придётся проходить по гораздо более медленной оперативной памяти. Иногда быстрее посчитать снова, что процессор и делает. А в случае с общим кэшем, мог бы просто взять данные из общего КЭШа.
К примеру, процессор Intel C2D q9550 состоит из двух Intel C2D E8400.
Четыре ядра будут медленнее не только из-за использования общих ресурсов шины. Кэш L2 теперь не общий и ему приходится искать обходные пути, если к примеру ядру 1 понадобилась информация обработанная ядром 3. Это увеличивает время обработки информации, следовательно уменьшает быстродействие.
Это увеличивает время обработки информации, следовательно уменьшает быстродействие.
Что такое кэш память L3?
- Подробности
-
мая 23, 2017 -
Просмотров: 8668
Уровень 3 или кэш L3 специализированная память, которая работает рука об руку с кэшем L1 и L2 для улучшения производительности компьютера. L1, L2 и L3 кэш необходимы для блока компьютерной обработки (процессора), есть также и другие типы кэша в системе, такие как кэш жёсткого диска.
Процессорный кэш позволяет удовлетворять потребности микропроцессора, предвосхищая запросы о предоставлении данных, так что инструкции по обработке предоставляются без задержки. Кэш процессора работает быстрее, чем оперативная память (ОЗУ), и предназначен для предотвращения узких мест в потере производительности.
При запросе системы процессору требуется инструкция для выполнения этой просьбы. Процессор работает во много раз быстрее, чем оперативная память, поэтому, чтобы сократить задержки, кэш L1 хранит данные, и он ожидает, что они будут необходимы. L1 кэш очень маленький, что позволяет ему быть очень быстрым. Если инструкции нет в кэш-памяти L1, ЦП проверяет кэш L2, немного больший пул кэш, с немного большей задержкой. При каждом промахе кэша он смотрит на следующий уровень кэша. Кэш-память L3 может быть гораздо больше, чем L1 и L2, и хотя она и медленнее, но всё-таки много быстрее, чем извлечение данных из памяти.
Если нужны инструкции которые находятся в кэше L3, биты данных могут быть перемещены из кэша L1 в новые инструкции на случай, если они понадобятся снова. Кэш-память L3 может тогда удалить эту строку из инструкции, так как она сейчас находится в другой кэш-памяти (называется эксклюзивный кэш), или она может создать копии (именуемые инклюзивный кэш), в зависимости от конструкции процессора.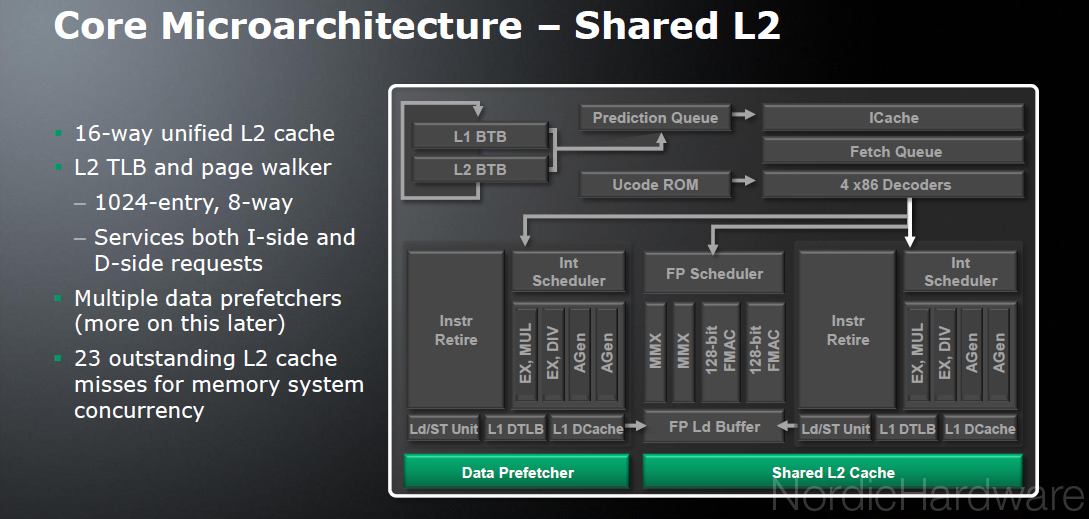
Например, в ноябре 2008 года компания AMD® выпустила четырехъядерный чип Шанхай. Каждое ядро имеет свой собственный L1 и L2 кэш, но ядра используют общий кэш L3. L3 сохраняет копии запрошенных элементов в случае если другие ядра делает последующий запрос.
Архитектура многоуровневого кэша продолжает развиваться. Кэш L1 используется, чтобы быть внешним для процессора, встроенный в материнскую плату, но теперь оба L1 и L2 кэш, обычно включены в матрицу процессора. Кэш-память L3, как правило, встроена в материнскую плату, но в некоторых моделях ЦП его уже включили как кэш-память L3. Преимущество иметь на борту кэш-память заключается в том, что это быстрее, эффективнее и дешевле, чем размещение отдельной кэш-памяти на материнской плате.
Выборки инструкций из кэша происходят быстрее, чем из системы оперативной памяти, и хорошая кэш-память существенно увеличивает производительность системы. Дизайн и стратегии кэша будут отличаться на различных материнских платах и процессорах, но при прочих равных, чем больше кэш L3, тем лучше.
Читайте также
Нужен ли кэш 3 уровня для игр. Небольшое сравнение L3 кэша в играх и приложениях
Кэш -промежуточный буфер с быстрым доступом, содержащий информацию, которая может быть запрошена с наибольшей вероятностью. Доступ к данным в кэше идёт быстрее, чем выборка исходных данных из оперативной (ОЗУ) и быстрее внешней (жёсткий диск или твердотельный накопитель) памяти, за счёт чего уменьшается среднее время доступа и увеличивается общая производительность компьютерной системы.
Ряд моделей центральных процессоров (ЦП) обладают собственным кэшем, для того чтобы минимизировать доступ к оперативной памяти (ОЗУ), которая медленнее, чем регистры. Кэш-память может давать значительный выигрыш в производительности, в случае когда тактовая частота ОЗУ значительно меньше тактовой частоты ЦП. Тактовая частота для кэш-памяти обычно ненамного меньше частоты ЦП.
Кэш центрального процессора разделён на несколько уровней. В универсальном процессоре в настоящее время число уровней может достигать 3. Кэш-память уровня N+1 как правило больше по размеру и медленнее по скорости доступа и передаче данных, чем кэш-память уровня N.
В универсальном процессоре в настоящее время число уровней может достигать 3. Кэш-память уровня N+1 как правило больше по размеру и медленнее по скорости доступа и передаче данных, чем кэш-память уровня N.
Самой быстрой памятью является кэш первого уровня — L1-cache. По сути, она является неотъемлемой частью процессора, поскольку расположена на одном с ним кристалле и входит в состав функциональных блоков. В современных процессорах обычно кэш L1 разделен на два кэша, кэш команд (инструкций) и кэш данных (Гарвардская архитектура). Большинство процессоров без L1 кэша не могут функционировать. L1 кэш работает на частоте процессора, и, в общем случае, обращение к нему может производиться каждый такт. Зачастую является возможным выполнять несколько операций чтения/записи одновременно. Латентность доступа обычно равна 2?4 тактам ядра. Объём обычно невелик — не более 384 Кбайт.
Вторым по быстродействию является L2-cache — кэш второго уровня, обычно он расположен на кристалле, как и L1. В старых процессорах — набор микросхем на системной плате. Объём L2 кэша от 128 Кбайт до 1?12 Мбайт. В современных многоядерных процессорах кэш второго уровня, находясь на том же кристалле, является памятью раздельного пользования — при общем объёме кэша в nM Мбайт на каждое ядро приходится по nM/nC Мбайта, где nC количество ядер процессора. Обычно латентность L2 кэша, расположенного на кристалле ядра, составляет от 8 до 20 тактов ядра.
В старых процессорах — набор микросхем на системной плате. Объём L2 кэша от 128 Кбайт до 1?12 Мбайт. В современных многоядерных процессорах кэш второго уровня, находясь на том же кристалле, является памятью раздельного пользования — при общем объёме кэша в nM Мбайт на каждое ядро приходится по nM/nC Мбайта, где nC количество ядер процессора. Обычно латентность L2 кэша, расположенного на кристалле ядра, составляет от 8 до 20 тактов ядра.
Кэш третьего уровня наименее быстродействующий, но он может быть очень внушительного размера — более 24 Мбайт. L3 кэш медленнее предыдущих кэшей, но всё равно значительно быстрее, чем оперативная память. В многопроцессорных системах находится в общем пользовании и предназначен для синхронизации данных различных L2.
Иногда существует и 4 уровень кэша, обыкновенно он расположен в отдельной микросхеме. Применение кэша 4 уровня оправдано только для высоко производительных серверов и мейнфреймов.
Проблема синхронизации между различными кэшами (как одного, так и множества процессоров) решается когерентностью кэша.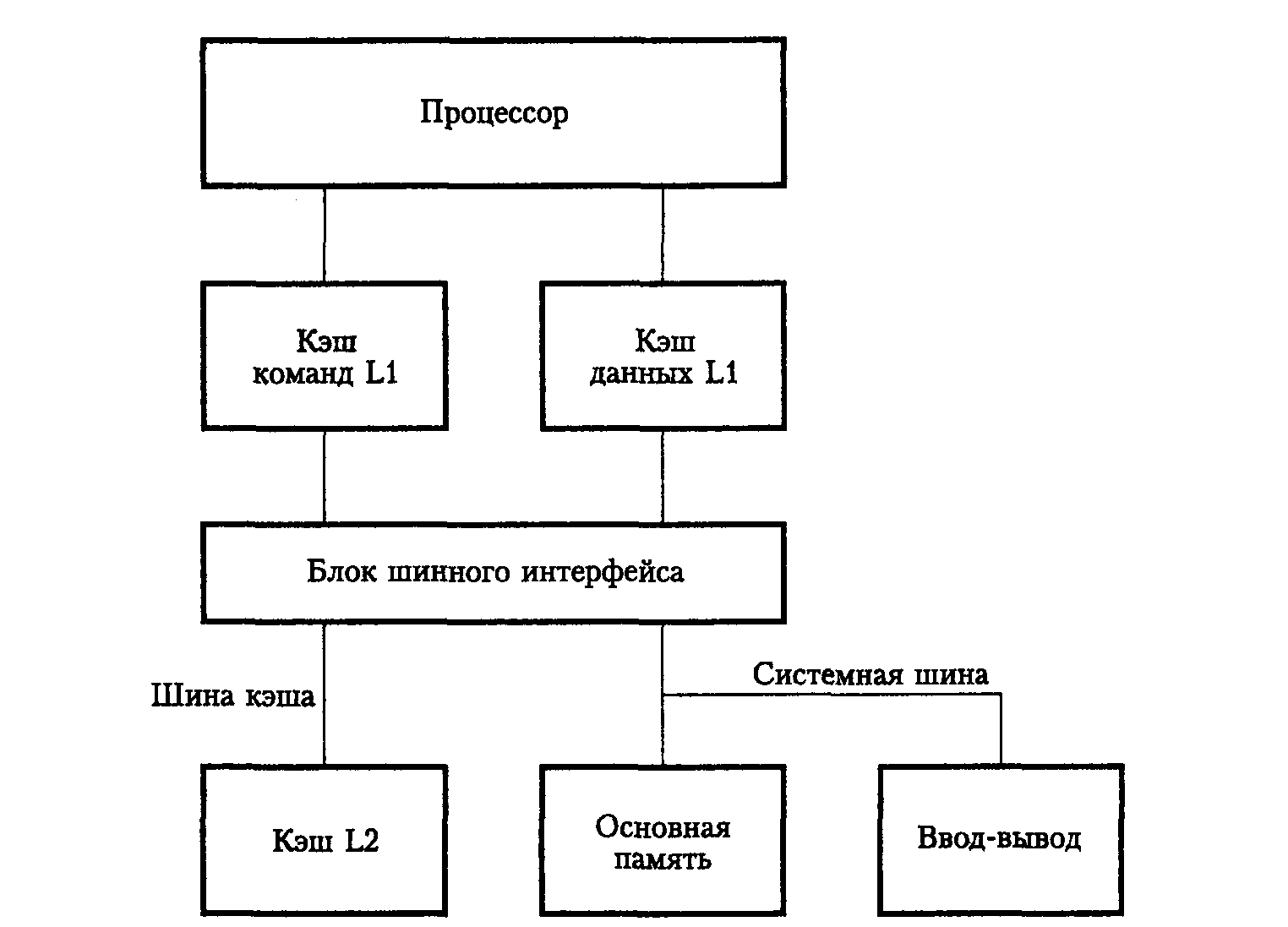 Существует три варианта обмена информацией между кэш-памятью различных уровней, или, как говорят, кэш-архитектуры: инклюзивная, эксклюзивная и неэксклюзивная.
Существует три варианта обмена информацией между кэш-памятью различных уровней, или, как говорят, кэш-архитектуры: инклюзивная, эксклюзивная и неэксклюзивная.
При выполнении различных задач в процессор вашего компьютера поступают необходимые блоки информации из оперативной памяти. Обработав их ЦП записывает полученные результаты вычислений в память и получает на обработку последующие блоки данных. Так продолжается до тех пор, пока поставленная задача не будет выполнена.
Вышеупомянутые процессы производятся на очень большой скорости. Однако скорость даже самой быстрой оперативной памяти значительно меньше скорости любого слабого процессора. Каждое действие, будь то запись на неё информации или считывание с неё занимают много времени. Скорость работы оперативной памяти в десятки раз ниже скорости процессора.
Не смотря на такую разницу в скорости обработки информации, процессор ПК не простаивает без дела и не ожидает, когда ОЗУ выдаст и примет данные. Процессор всегда работает и всё благодаря присутствию в нем кэш памяти.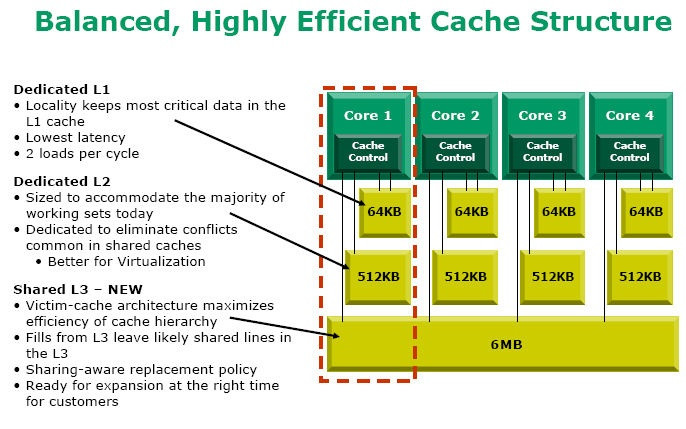
Кэш — особый вид оперативной памяти. Процессор использует память кэша для хранения тех копий информации из основной оперативной памяти компьютера, вероятность обращения к которым в ближайшее время очень велика.
По сути кэш-память выполняет роль бы
Кэш – память и принципы ее организации, страница 7
Если разместить их в памяти, не выравнивая на границу
четырехбайтного блока, например, по соображению экономии памяти, то половина
слов (два из каждых четырех) будет распределена по двум строкам буфера (Рис.IV.5).
Такое решение
приведет к тому, что достаточно часто
каждая попытка доступа к одному информационному слову закончится двумя неудачными
обращениями к кэш-памяти. Выравнивание слова на границу слова позволит
уменьшить число неудачных обращений к буферу до одного в расчете на слово, то
есть в два раза. А это уже весьма существенное значение.
Следует отметить, что подобные приемы могут оказаться
очень эффективными в тех случаях, когда важно время выполнения программы или
какой-либо ее части, а все используемые ранее методы оптимизации не дали
требуемого результата.
В заключение приведем обобщенную блок-схему алгоритма
выполнения запроса к памяти в системе, использующей кэширование (рис.IV.6).
Рис.IV.6. Блок-схема алгоритма выполнения запроса к памяти в
системе, использующей кэширование.
4. Двухуровневое кэширование.
В современных компьютерах используется не одна
ступень кэш-памяти, а две, а в некоторых даже три. Кэш-память непосредственно связанная
с процессором носит название кэш-памяти первого уровня: кэш Level
1 (кэш L1).
Рис.IV.7 Блок-схема алгоритма выполнения запроса на чтение
в системе с
двухуровневой кэш-памятью.
Кэш-память,
расположенная между кэш L1 и основной памятью носит название кэш-памяти второго
уровня (кэш L2), а кэш-память, расположенная между кэш L2 и
основной памятью называется кэш-памятью третьего уровня (кэш L3).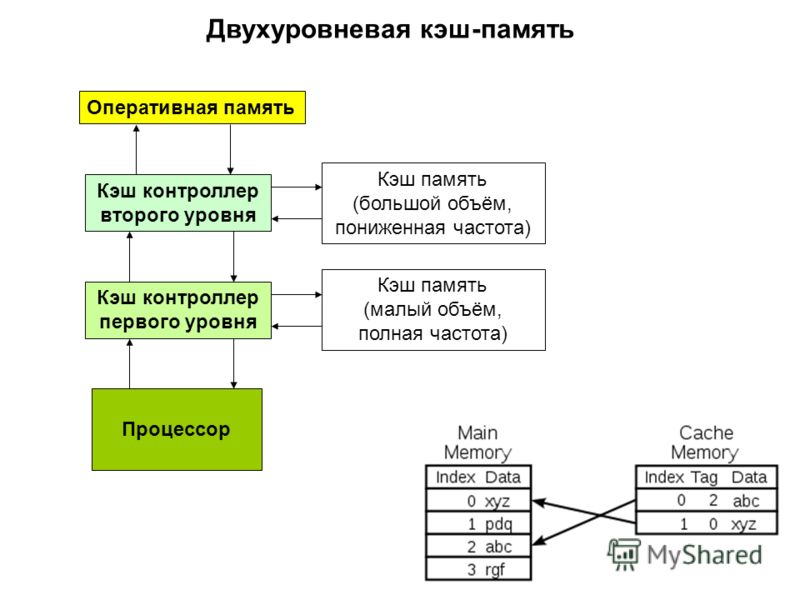
Объем кэш L1 в современных процессорах
обычно имеет размеры 64 Кбайт (32 Кбайт для инструкций и 32 Кбайт для данных) и
время доступа 1-2 тактовых интервала CPU. Отметим, правда, что, в
процессоре Pentium 4, в кэш L1 инструкций хранятся не их коды, а
последовательности микрокоманд, в которые уже декодированы инструкции (до 12К
микрокоманд). Поэтому, такой кэш обычно называют не кэш инструкций, а кэш
трассы (tracecache).
Объем кэш L2 – 256…2048 Кбайт со временем
доступа 3-5 тактовых интервала, а объем кэш L3 достигает 12 Мбайт и даже больше.
Для пояснения функционирования двухуровневой
кэш-памяти, в упрощенном виде, на рис.IV.7 и рис.IV.8
изображены обобщенные блок-схемы алгоритмов выполнения ими запросов на чтение и
на запись соответственно.
Рис.IV.8. Блок-схема алгоритма выполнения запроса на запись
с
двухуровневой кэш-памятью.
4. Пакетный режим обмена
информацией
Обмен информацией между ОЗУ и кэш-памятью должен
осуществляться с максимально-возможной скоростью, чтобы свести к минимуму
количество тактов ожидания процессора. Этот обмен осуществляется блоками
Этот обмен осуществляется блоками
данных, размер которых соответствует длине строки кэш-памяти. Для ускорения
операции пересылки строк кэш-памяти используется так называемый режим пакетной
передачи (BurstMode), или
передача пакетными циклами. При этом, под пакетом понимается упомянутый блок
данных, передаваемый за одно обращение к памяти. Иллюстрация посылки адресной
информации и пакетов данных процессорами семейства Х86 приведена на рис.IV.9.
Сутью пакетной передачи является то, что адрес на
адресную шину процессор выставляет всего один раз за время пакетного цикла.
Этот адрес является адресом первой посылки данных в пакете. Адреса последующих
посылок пакета формируются непосредственно в самой памяти специальным
контроллером. Так при строке кэш-памяти равной 16 байтам, характерной для
процессоров i486, пакет состоит из четырех посылок, размером 4 байта каждая.
Размер посылки определяется разрядностью шины данных, которая у процессоров
i486 составляет 32 бита.
Рис.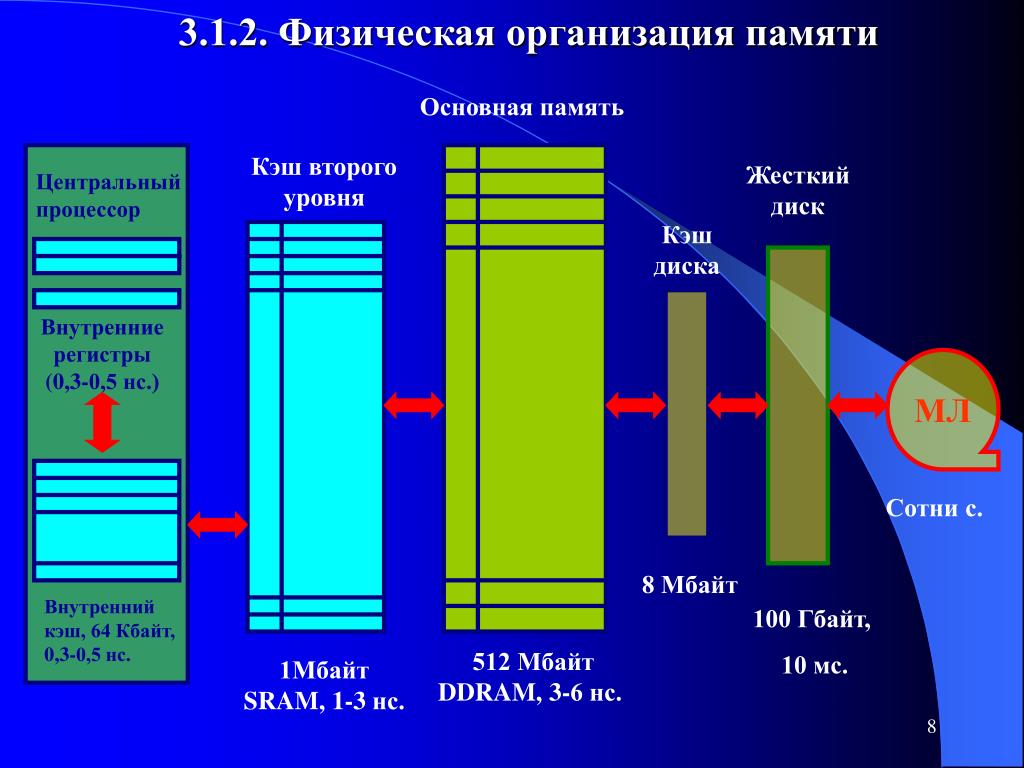 IV.9 Иллюстрация посылки адресной информации и пакетов
IV.9 Иллюстрация посылки адресной информации и пакетов
данных в
процессорах семейства
Х86.
Адрес, выставляемый процессором в начале пакетного
цикла на адресную шину, будет состоять из двух частей: неизменяемые за время
пакетного цикла 28 старших бит адреса A[31:4] и, изменяемые контроллером памяти,
биты A[3,2], а также сигналы управления байтами BE[3:0].
Строка кэш-памяти процессоров Pentium+ равна
32 байтам, но, поскольку у них разрядность шины данных увеличена до 64 бит, то
одна строка передается пакетом также за 4 такта (по 8 байт за каждый такт). И в
этом случае адресная посылка генерируется процессором за время передачи пакета
тоже только один раз. При этом биты адреса A[31:5] (или A[35:5] – для
процессоров Pentium Pro+) остаются неизменяемыми во
время передачи пакета, а биты A[4,3] и сигналы разрешения байт BE[7:0],
определяются и изменяются контроллером самой памяти.
Описанная технология пакетной передачи данных
позволяет существенно ускорить пересылку информации между ОЗУ и кэш-памятью.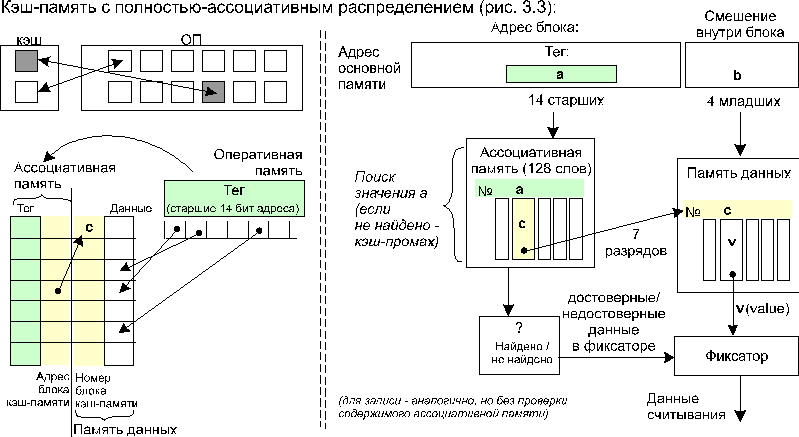 Так,
Так,
если время доступа к оперативной памяти (т.е. время обращения к памяти по
случайным адресам) сейчас равно 40…60 нс, то время цикла, (т.е. интервал
времени между двумя пересылками в пакете) составляет 8…10 нс.
Кстати, следует отметить, что режим пакетной передачи
данных используется не только при обмене информацией между оперативной и
кэш-памятью. Так, например, пакетный режим используется при регенерации памяти
и в ряде других случаев, где он может быть в принципе применен. Любая последовательность
циклов чтения может быть преобразована в пакетный цикл.
С другой стороны надо иметь в виду, что быстродействие
динамической оперативной памяти существенно отстает от быстродействия
статической кэш-памяти (у ОЗУ время доступа сейчас 40…60 нс, а у статической
кэш-памяти не превышает единиц нс). Кроме того, специфика функционирования
динамической памяти требует нескольких тактов задержки перед выдачей пакета
данных. Поэтому реальный обмен информацией между процессором и ОЗУ занимает
большее число тактов, по сравнению с теоретически рассмотренным ранее.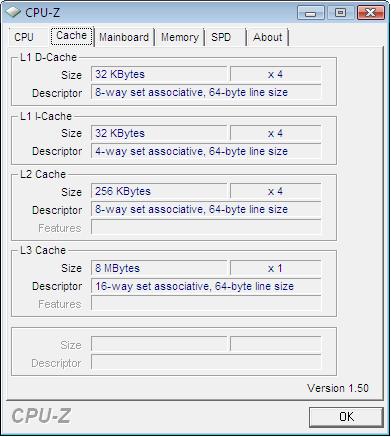
Премия CACHE уровня 3 в области ухода за детьми и образования
Об этом курсе
Чтобы получить награду CACHE Level 3 в области ухода за детьми и образования (VRQ), вам необходимо выполнить 12 заданий.
По этому курсу не проводятся официальные экзамены, и сбор за сертификацию включен в стоимость курса. Также предоставляется полная поддержка репетитора, и ваш онлайн-репетитор проведет вас через уроки и онлайн-материалы, а также ответит на любые ваши вопросы по содержанию курса.Курс, написанный нашими опытными преподавателями, дает углубленный, но захватывающий взгляд на уход за детьми и на то, что значит быть практикующим 3-го уровня.
Для получения дополнительной информации посетите: http://www.cache.org.uk. Квалификационный код 601/3998/5
Для получения полной квалификации учащиеся должны достичь (как указано в CACHE):
• Успешные оценки за 2 обязательных блока
• Требуется минимум 180 часов обучения с гидом
См.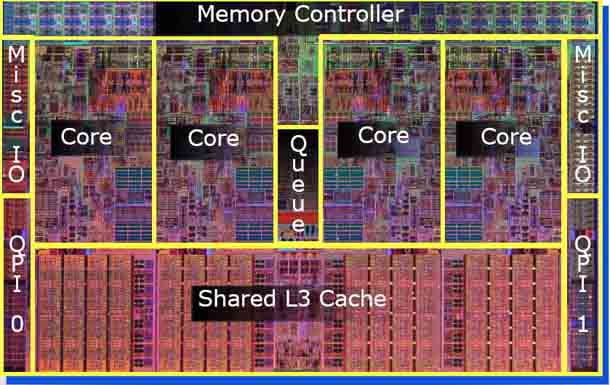 Сводку квалификации CACHE для этого курса
Сводку квалификации CACHE для этого курса
См. Сводку о квалификации Ofqual для этого курса
| Время исследования: | 200 часов |
| Срок регистрации: | 12 месяцев |
| Формат курса: | Онлайн |
| Требования к поступающим: | Никаких конкретных |
По завершении этой квалификации студенты получают награду CACHE Level 3 и сертификат OLC.Все сборы за сертификацию включены в стоимость вашего курса.
Метод
Всем нашим студентам предоставляется доступ к нашему онлайн-кампусу через их личные логин и пароль. После входа в систему вы можете получить доступ к материалам курса, урокам, ресурсам и заданиям в удобное для вас время. Задания загружаются через вашу учетную запись, и процесс прост и интуитивно понятен. В нашем онлайн-кампусе:
В нашем онлайн-кампусе:
- 24/7/365 доступ ко всем материалам вашего курса — все уроки, задания и ресурсы доступны с момента регистрации
- Мгновенный доступ к вашему курсу после регистрации — немедленно приступайте к обучению!
- Интегрированные системы чата и обмена сообщениями, чтобы вы могли связаться со своим преподавателем
- Онлайн-загрузка заданий позволяет сэкономить время при возврате оценок и отзывов.
- Ссылки на дополнительные ресурсы и информацию о курсах
- Самостоятельное обучение по всем курсам — учитесь в удобное для вас время и выполняйте задания в удобном для вас темпе
- Надежное электронное портфолио ваших работ хранится под замком на наших защищенных серверах
- Индикатор выполнения, чтобы показать работу, которую вы выполнили, и сколько задач вам еще нужно выполнить на вашем курсе
- Подробный справочный центр с пошаговыми инструкциями по получению максимальной отдачи от курса, а также о том, как загружать задания и связываться с преподавателем.

Содержание курса
В этот курс входят следующие два обязательных модуля:
- Развитие ребенка от зачатия до 7 лет
- Здоровье и благополучие детей
Поддержка
Самый важный инструмент, который есть в распоряжении всех наших студентов, — это их репетитор.При обучении на курсах у нас вам будет назначен личный наставник с глубокими знаниями и опытом в выбранном вами предмете.
Настоятельно рекомендуется использовать опыт преподавателей и задавать вопросы о содержании курса. Ваши задания отмечаются вашим личным наставником, и дается подробный отзыв. Кроме того, ваш наставник предоставит вам указатели и советы о том, где вы можете улучшить — это поможет вам получить максимальную отдачу от ваших курсов и постоянно улучшать свои навыки.
Оценки
Для прохождения этого курса слушателям необходимо выполнить несколько заданий. Они заполняются после просмотра соответствующих уроков и написания ответов на вопросы задания.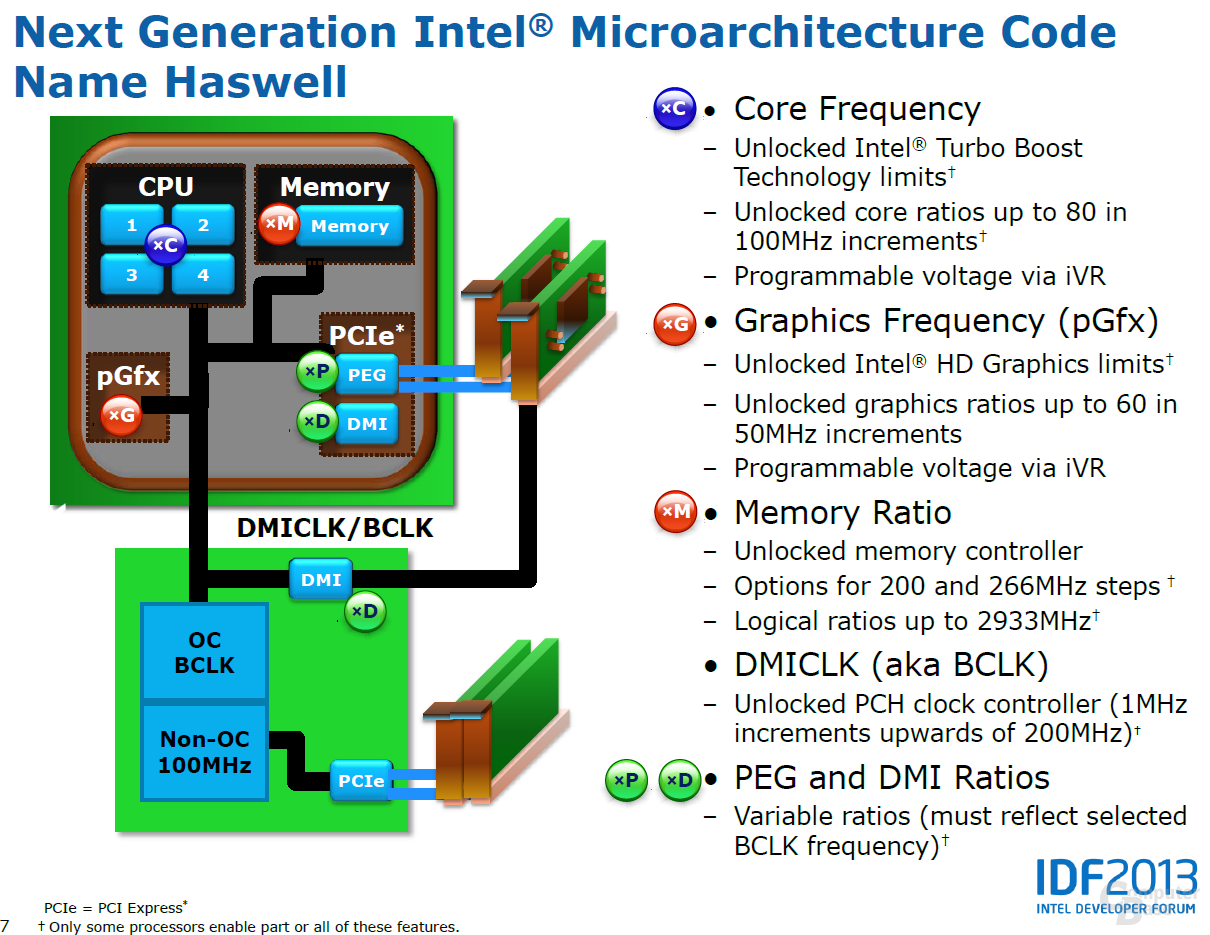 После того, как ваш личный наставник прочитает и отметит их, учащимся предоставляется обратная связь и оценки, содержащие полезные советы по улучшению работы при выполнении будущих заданий.
После того, как ваш личный наставник прочитает и отметит их, учащимся предоставляется обратная связь и оценки, содержащие полезные советы по улучшению работы при выполнении будущих заданий.
Продолжительность регистрации
На все наши курсы у студентов отводится достаточно времени, чтобы они могли завершить учебу, и все материалы предназначены для самостоятельного изучения, поэтому вы можете пройти курс в удобном для вас темпе.Если вам требуется дополнительное время на одном из наших курсов, вы можете продлить регистрацию на 30 дней за дополнительную плату в размере 60 фунтов стерлингов.
Кроме того, мы предоставляем 14-дневную гарантию возврата денег по каждой из наших квалификаций — вот насколько мы уверены в том, что вам понравится учиться у нас!
Квалификация
Это квалификация только для знаний. Опыт работы в реальной рабочей среде не требуется, и весь курс проходит онлайн. Обратите внимание, что это квалификация только уровня 3 и не требует каких-либо практических оценок. Курс дает основу для практикующего уровня 3, но не дает лицензии на практику.
Курс дает основу для практикующего уровня 3, но не дает лицензии на практику.
Этот курс требует от студентов выполнить 12 заданий, отмеченных репетитором.
Этот курс можно пройти в течение 12 месяцев, но вы можете проходить его так быстро или медленно, как хотите.
Теперь по завершении этого курса студенты получают определенное количество баллов UCAS в зависимости от полученной оценки. Количество заработанных баллов UCAS:
| Марка | Очки UCAS |
| А * | 28 |
| А | 24 |
| B | 20 |
| С | 16 |
| Д | 12 |
Награда
CACHE уровня 3 за подготовку к работе в сфере ухода за детьми на дому
Об этом курсе
Этот курс предназначен для студентов, которые хотят работать в домашних условиях по уходу за детьми в качестве помощников по уходу за детьми или других домашних воспитателей (например,грамм. няни, помощницы по хозяйству). Он учит необходимым требованиям для создания бизнеса по уходу за детьми в домашних условиях и дает сертификат Cache, который полностью аккредитован Ofsted и требуется нянями и помощниками по хозяйству в различных местных органах власти.
няни, помощницы по хозяйству). Он учит необходимым требованиям для создания бизнеса по уходу за детьми в домашних условиях и дает сертификат Cache, который полностью аккредитован Ofsted и требуется нянями и помощниками по хозяйству в различных местных органах власти.
| Время исследования: | 50 часов |
| Срок регистрации: | 12 месяцев |
| Формат курса: | Онлайн |
| Требования к поступающим: | Никаких конкретных |
По завершении этой квалификации студенты получают сертификат CACHE уровня 3 и сертификат OLC.Все сборы за сертификацию включены в стоимость вашего курса.
Квалификация
Чтобы получить полную награду CACHE Level 3 за подготовку к работе в сфере ухода за детьми на дому, вам необходимо отправить и сдать 13 заданий, отмеченных репетитором. Есть девять заданий для блока 1 и четыре задания для блока 2.
Есть девять заданий для блока 1 и четыре задания для блока 2.
Формального экзамена нет, плата за сертификацию включена в стоимость курса.
Для получения дополнительной информации посетите: http://www.cache.org.uk. Квалификационный код 603/3642/0
См. Сводку квалификации CACHE для этого курса здесь
См. Сводку о квалификации Ofqual для этого курса здесь
Метод
Всем нашим студентам предоставляется доступ к нашему онлайн-кампусу через их личные логин и пароль.После входа в систему вы можете получить доступ к материалам курса, урокам, ресурсам и заданиям в удобное для вас время. Задания загружаются через вашу учетную запись, и процесс прост и интуитивно понятен. В нашем онлайн-кампусе:
- 24/7/365 доступ ко всем материалам вашего курса — все уроки, задания и ресурсы доступны с момента регистрации
- Мгновенный доступ к вашему курсу после регистрации — немедленно приступайте к обучению!
- Интегрированные системы чата и обмена сообщениями, чтобы вы могли связаться со своим преподавателем
- Онлайн-загрузка заданий позволяет сэкономить время при возврате оценок и отзывов.
- Ссылки на дополнительные ресурсы и информацию о курсах
- Самостоятельное обучение по всем курсам — учитесь в удобное для вас время и выполняйте задания в удобном для вас темпе
- Надежное электронное портфолио ваших работ хранится под замком на наших защищенных серверах
- Индикатор выполнения, чтобы показать работу, которую вы выполнили, и сколько задач вам еще нужно выполнить на вашем курсе
- Подробный справочный центр с пошаговыми инструкциями по получению максимальной отдачи от курса, а также о том, как загружать задания и связываться с преподавателем.

Содержание курса
Этот курс оценивает следующие критерии:
Блок 1
- Ознакомиться с действующим законодательством и нормативными актами в отношении ухода за детьми на дому
- Понимать, как создать безопасную и здоровую домашнюю среду ухода за детьми для детей
- Понимать, как поддерживать защиту, защиту и благополучие детей
- Понимать, как способствовать равенству, разнообразию и вовлеченности
- Понимать, как повседневный уход за детьми способствует благополучию детей
- Поймите, как работать в партнерстве, чтобы помочь детям добиться результатов
- Понимать процесс обучения и поведения детей в зависимости от последовательности, скорости и стадии развития
- Понимать ценность игры в содействии обучению и развитию детей
- Понимать роль наблюдения в содействии обучению и развитию детей
Блок 2
- Понимать, как вести и управлять учреждением по уходу за детьми на дому
- Понимать, как соблюдать финансовые и налоговые требования при создании детских учреждений на дому
- Узнайте, как создать бизнес-план
- Узнайте, как зарегистрироваться в соответствующем регулирующем органе.
Этот курс можно пройти в течение 12 месяцев, но вы можете проходить его так быстро или медленно, как хотите.
Поддержка
Самый важный инструмент, который есть в распоряжении всех наших студентов, — это их репетитор. При обучении на курсах у нас вам будет назначен личный наставник с глубокими знаниями и опытом в выбранном вами предмете.
Настоятельно рекомендуется использовать опыт преподавателей и задавать вопросы о содержании курса.Ваши задания отмечаются вашим личным наставником, и дается подробный отзыв. Кроме того, ваш наставник предоставит вам указатели и советы о том, где вы можете улучшить — это поможет вам получить максимальную отдачу от ваших курсов и постоянно улучшать свои навыки.
Оценки
Для прохождения этого курса слушателям необходимо выполнить 13 заданий. Они заполняются после просмотра соответствующих уроков и написания ответов на вопросы задания. После того, как ваш личный наставник прочитает и отметит их, учащимся предоставляется обратная связь и оценки, содержащие полезные советы по улучшению работы при выполнении будущих заданий.
Продолжительность регистрации
На все наши курсы у студентов отводится достаточно времени, чтобы они могли завершить учебу, и все материалы предназначены для самостоятельного изучения, поэтому вы можете пройти курс в удобном для вас темпе. Если вам требуется дополнительное время на одном из наших курсов, вы можете продлить регистрацию на 30 дней за дополнительную плату в размере 60 фунтов стерлингов.
Кроме того, мы предоставляем 14-дневную гарантию возврата денег по каждой из наших квалификаций — вот насколько мы уверены в том, что вам понравится учиться у нас!
CACHE Уровень 3 для дошкольников CACHE LEVEL 3 ДЕТСКОЕ ОБРАЗОВАНИЕ И ОБРАЗОВАНИЕ Раздел 9 Поддержка экстренной грамотности © Hodder & Stoughton Limited.
Презентация на тему: «CACHE Level 3 Early Years Educator CACHE LEVEL 3 CHILDCARE & EDUCATION Unit 9 Supporting Emergency Literacy © Hodder & Stoughton Limited.» — стенограмма презентации:
1
CACHE Уровень 3 для дошкольников CACHE LEVEL 3 ДЕТСКОЕ ОБРАЗОВАНИЕ и ОБРАЗОВАНИЕ Раздел 9 Поддержка экстренной грамотности © Hodder & Stoughton Limited
2
CACHE Уровень 3 для дошкольников LO4 Изучите стратегии, которые поддерживают развивающуюся грамотность. AC 4.5: Объясните стратегии для планирования мероприятий, которые поощряют: говорение и аудирование, возникающее чтение, устойчивое совместное мышление, возникающие технологии письма / цифровую грамотность. © Hodder & Stoughton Limited
AC 4.5: Объясните стратегии для планирования мероприятий, которые поощряют: говорение и аудирование, возникающее чтение, устойчивое совместное мышление, возникающие технологии письма / цифровую грамотность. © Hodder & Stoughton Limited
3
CACHE Уровень 3 для преподавателей дошкольного образования Начальное задание LO4 Понимание стратегий, способствующих повышению грамотности [AC 4.5] Время: 15 минут Сколько технологических устройств вы можете использовать? К скольким мобильным устройствам у вас есть доступ? Какие дополнительные технологии есть у вас дома? Какое устройство обязательно должно быть у вас? Какой была бы ваша жизнь без мобильных технологий и Интернета? Обсудите свои ответы с партнером.© Hodder & Stoughton Limited
4
CACHE Уровень 3 Планирование дошкольного образования От вас потребуется объяснить стратегии планирования мероприятий, которые поддерживают и расширяют возникающие навыки грамотности и поощряют следующие области: Говорение и слушание Новое чтение Устойчивое общее мышление Письмо Цифровая грамотность. © Hodder & Stoughton Limited LO4 Разберитесь в стратегиях, способствующих повышению грамотности [AC 4.5]
© Hodder & Stoughton Limited LO4 Разберитесь в стратегиях, способствующих повышению грамотности [AC 4.5]
5
CACHE Уровень 3 для дошкольников Цифровая грамотность Цифровая грамотность позволяет детям уверенно и компетентно пользоваться цифровыми медиа и технологиями. Дети должны иметь доступ к широкому спектру устройств. Их следует использовать для различных целей, и детей следует поощрять использовать их самостоятельно. Эти устройства могут помочь детям проявить творческий подход и стимулировать углубленное общение.© Hodder & Stoughton Limited LO4 Понимание стратегий, способствующих повышению грамотности [AC 4.5]
6
CACHE Уровень 3 Преподаватель дошкольного возраста Поддержка цифровой грамотности Мобильные телефоны Камеры Консоли Компьютеры Планшеты Электронные книги ТВ / DVD Электронные игрушки Интернет Художественные пакеты LO4 Понимание стратегий, способствующих возникновению грамотности [AC 4. 5]
5]
7
CACHE Уровень 3 для дошкольников Обсуждение в классе Продолжительность: 15 минут Технологии в вашем окружении Какие устройства доступны для использования детьми в вашем окружении? Как часто они становятся доступными? Все ли дети имеют равный доступ к этим устройствам? Как они используются для поддержки возникающих навыков грамотности? © Hodder & Stoughton Limited LO4 Разберитесь в стратегиях, способствующих повышению грамотности [AC 4.5]
8
CACHE Уровень 3 Планирование для преподавателей дошкольного образования При планировании занятий вам необходимо учитывать все, что вы уже рассмотрели в этом модуле. Вам нужно будет убедиться, что занятия соответствуют возрасту и стадии. Вы должны использовать ресурсы, доступные вам в настройке. Вы также должны опираться на интересы детей, чтобы вовлечь их в развитие своих навыков. © Hodder & Stoughton Limited LO4 Разберитесь в стратегиях, способствующих повышению грамотности [AC 4.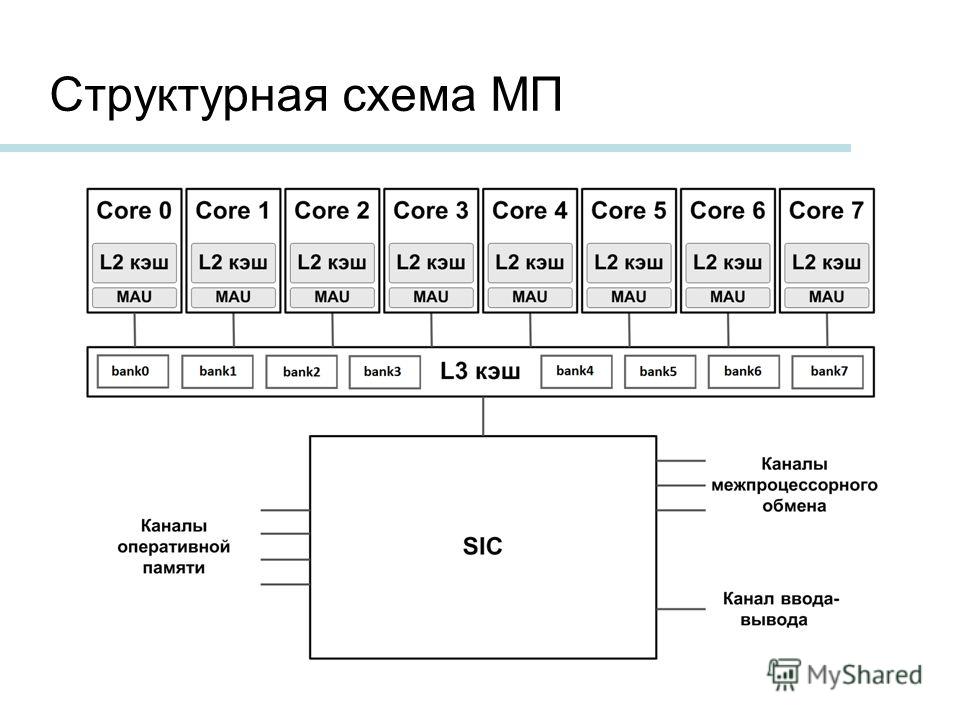 5]
5]
9
CACHE Уровень 3 Планирование для преподавателей дошкольного возраста Используйте таблицу планирования на рабочем листе, предоставленном для создания набора идей для каждой области, которую необходимо охватить. Говорение и аудирование Чтение Устойчивое совместное мышление ПисьмоЦифровая технология © Hodder & Stoughton Limited LO4 Понимание стратегий, поддерживающих развивающуюся грамотность [AC 4.5]
10
CACHE Уровень 3 Педагогические пары для дошкольников Время: 15 мин. Поделитесь заполненной таблицей планирования с партнером.Обсудите: Подходящие возрастные группы. Как каждая идея или мероприятие может способствовать развитию навыков грамотности. Необходимые ресурсы. © Hodder & Stoughton Limited LO4 Понимание стратегий, способствующих повышению грамотности [AC 4.5]
11
CACHE Уровень 3 для дошкольников Устойчивое совместное мышление (SST) Устойчивое совместное мышление (SST) включает в себя практикующих, работающих вместе с детьми над расширением и развитием их навыков речи, слушания и мышления. Это требует, чтобы практикующий был вовлечен в мысли ребенка и помогал ему развить навык или решить проблему. SST может поддержать возникающие навыки грамотности, поскольку практикующий может слушать ребенка, моделировать соответствующий язык и побуждать ребенка обсуждать свои мысли. © Hodder & Stoughton Limited LO4 Понимание стратегий, способствующих повышению грамотности [AC 4.5]
Это требует, чтобы практикующий был вовлечен в мысли ребенка и помогал ему развить навык или решить проблему. SST может поддержать возникающие навыки грамотности, поскольку практикующий может слушать ребенка, моделировать соответствующий язык и побуждать ребенка обсуждать свои мысли. © Hodder & Stoughton Limited LO4 Понимание стратегий, способствующих повышению грамотности [AC 4.5]
12
CACHE Уровень 3 для дошкольников Обсуждение в классе Продолжительность: 15 мин. Устойчивое совместное мышление требует, чтобы практикующий был полностью вовлечен в мыслительный процесс ребенка.Подумайте: что может помешать этому случиться? Что может произойти, если практикующий слишком увлечется деятельностью ребенка? Какие навыки необходимы практикующему специалисту, чтобы полностью поддерживать возникающую грамотность посредством устойчивого совместного мышления? Какую пользу принесет ребенку участие практикующего врача? © Hodder & Stoughton Limited LO4 Понимание стратегий, способствующих повышению грамотности [AC 4. 5]
5]
Почему у ЦП несколько уровней кэш-памяти?
Это вопрос читателя от «jlforrest», на который, кажется, стоит ответить более подробно, чем просто одно предложение:
Я понимаю необходимость кеширования, но не понимаю, почему существует несколько уровней кеша вместо одного большего уровня.Другими словами, предположим, что размер кэша L1 составляет 32 КБ, кэш L2 — 256 КБ, а кэш L3 — 2 МБ, почему бы не иметь один кэш L1 размером 32 КБ + 256 КБ + 2 МБ?
Вкратце, различные уровни кэша имеют очень большие различия в том, как они устроены; они подвержены различным ограничениям и служат разным целям. Как показывает опыт, по мере того, как вы поднимаетесь по уровням иерархии кешей, кеши становятся больше, медленнее, с большей плотностью (больше битов хранится на единицу площади), потребляют меньше энергии на один сохраненный бит и получают дополнительные задачи.
В надежде получить здесь некоторую интуицию, давайте начнем с сложной и несколько причудливой аналогии.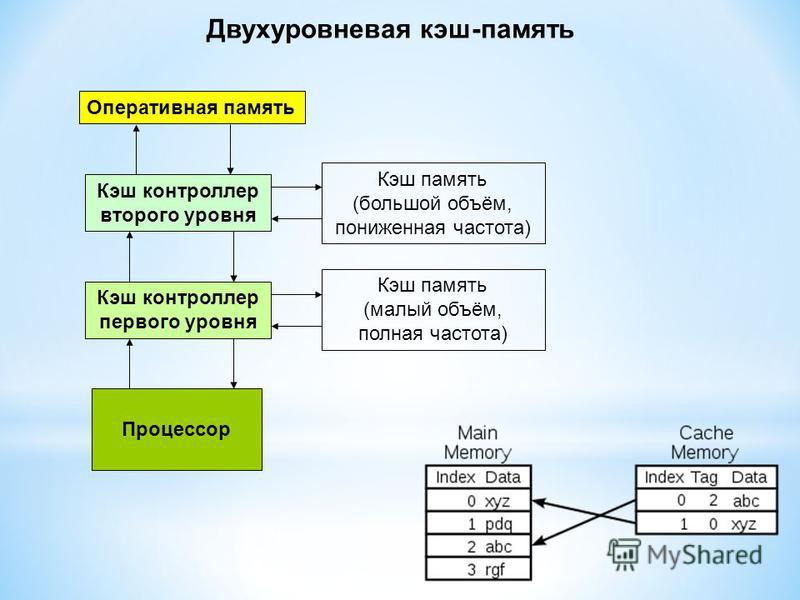 Правильно, это…
Правильно, это…
Тайник времени истории!
Предположим, вы служащий офисным служащим в какой-то безымянной разросшейся бюрократии 1960-х годов, и у вас нет компьютеров в поле зрения, и ваша работа включает в себя много просмотров и перекрестных ссылок на файлы дел (здесь папки с листами бумаги).
У вас есть рабочий стол (кэш данных L1). На вашем столе находятся файлы (строки кэша), над которыми вы работаете прямо сейчас, и некоторые другие файлы, которые вы недавно загрузили и которые либо закончили, либо ожидаете снова просмотреть.Работа с файлом обычно означает просмотр отдельных страниц, которые он содержит (соответствующих байтам в строке кэша). Но если они не лежат на вашем столе, файлы рассматриваются как единое целое. Вы всегда берете файлы целиком, даже если в них есть только одна страница, которая вам действительно интересна прямо сейчас.
Также в офисе находится картотека (кэш L2). В этом шкафу находятся файлы, с которыми вы работали недавно, но сейчас не используете. Когда вы закончите работу с тем, что находится на вашем столе, большая часть этих файлов вернется в картотеку.Взять что-то из шкафа не сразу — вам нужно подняться туда, открыть правый ящик и пролистать несколько учетных карточек, чтобы найти нужный файл, — но это все еще довольно быстро.
Когда вы закончите работу с тем, что находится на вашем столе, большая часть этих файлов вернется в картотеку.Взять что-то из шкафа не сразу — вам нужно подняться туда, открыть правый ящик и пролистать несколько учетных карточек, чтобы найти нужный файл, — но это все еще довольно быстро.
Иногда другим людям нужно посмотреть файл в вашем кабинете. Есть парень с тележкой, Бастер (представляющий что-то вроде кольцевого автобуса), который просто ходит по всем офисам. Когда офисному работнику нужен файл, которого у него нет в личном кабинете, он просто пишет небольшой бланк запроса и передает его Бастеру.Для простоты допустим, Бастер знает, где все находится. Поэтому в следующий раз, когда он придет к вам в офис, Бастер проверит, запрашивал ли кто-нибудь какие-либо файлы, которые находятся в вашем шкафу, и, если да, просто молча вытащит эти файлы из шкафа и поместит их в свою тележку. В следующий раз, когда он придет в офис того, кто запрашивал файл, он бросит его в его шкаф и оставит квитанцию на столе.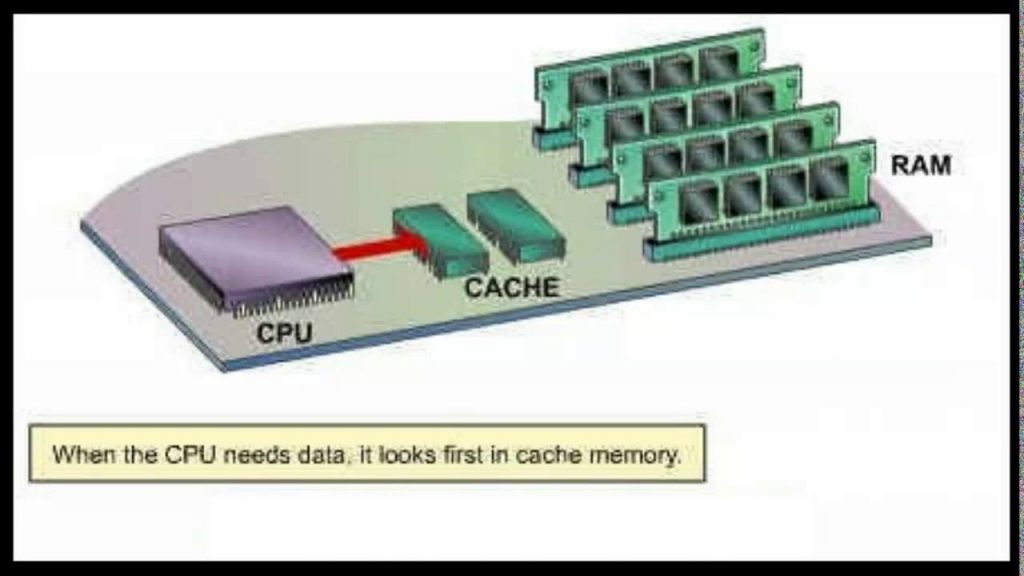
Время от времени Бастер замечает, что запрошенный файл находится не в шкафу, а на столе.В таком случае он не может просто молча схватить его; ему нужно спросить работника за столом, закончили ли они с этим, и, если нет, этот работник и тот, кто отправил запрос, должны договориться о том, что делать. Существуют утомительно проработанные корпоративные протоколы о том, что делать в такой ситуации (встречи обязательно будут!).
Шкафы для документов обычно полны. Это означает, что Бастер не может просто вставить новый файл; сначала он должен освободить место, что он делает, беря другой файл, желательно тот, который давно не использовался.Эти файлы Бастер переносит в архив в подвале (кэш L3). В подвале группы файлов хранятся плотно упакованными в картонные коробки на промышленных стеллажах. Обычные офисные работники вообще сюда не приезжают; это не для них, и они не знакомы с деталями файловой системы. Мы оставляем это работникам архива.
Всякий раз, когда Бастер спускается сюда, он бросает все старые файлы, которые он взял для архивации, во входной лоток на стойке регистрации. Он также оставляет все квитанции о запросах файлов, которых нет ни в одном из картотек наверху, но он не ждет, пока клерки вернут файлы, поскольку это требует времени.Они просто возьмут бланки с запросами, возьмут соответствующий файл и бросят его в лоток для исходящих документов, когда они закончат. Таким образом, каждый раз, когда Бастер приходит, он хватает все, что находится в лотке для «вывоза», кладет его на свою тележку и относит получателю, когда тот в следующий раз подходит.
Он также оставляет все квитанции о запросах файлов, которых нет ни в одном из картотек наверху, но он не ждет, пока клерки вернут файлы, поскольку это требует времени.Они просто возьмут бланки с запросами, возьмут соответствующий файл и бросят его в лоток для исходящих документов, когда они закончат. Таким образом, каждый раз, когда Бастер приходит, он хватает все, что находится в лотке для «вывоза», кладет его на свою тележку и относит получателю, когда тот в следующий раз подходит.
Проблема в том, что таких файлов , партия , и даже с хорошей упаковкой они даже близко не поместятся в подвале. Большинство файлов хранятся за пределами сайта; Это офисное здание в красивой части города, и арендная плата здесь слишком высока, чтобы тратить столько места на складские помещения.Вместо этого компания арендует складские помещения в 30 минутах езды от города, где хранится большая часть старых файлов (это соответствует DRAM). За стойкой регистрации в подвале сидит Меган, главный архивист. Меган отслеживает, какие файлы хранятся в подвале, а какие — на складе. Поэтому, когда Бастер опускает свои заявки в лоток для входящих, она проверяет, какие из них соответствуют файлам в подвале (для обработки архивных клерков), а какие нет на месте. Последние просто добавляются к большой пачке запросов.Может быть, один или два раза в день они отправляют фургон на склад, чтобы забрать запрошенные файлы вместе с соответствующим количеством старых файлов для консервации (как сказано, подвал полон; им нужно освободить место, прежде чем они смогут хранить какие-либо еще файлы со склада).
Меган отслеживает, какие файлы хранятся в подвале, а какие — на складе. Поэтому, когда Бастер опускает свои заявки в лоток для входящих, она проверяет, какие из них соответствуют файлам в подвале (для обработки архивных клерков), а какие нет на месте. Последние просто добавляются к большой пачке запросов.Может быть, один или два раза в день они отправляют фургон на склад, чтобы забрать запрошенные файлы вместе с соответствующим количеством старых файлов для консервации (как сказано, подвал полон; им нужно освободить место, прежде чем они смогут хранить какие-либо еще файлы со склада).
Buster не знает и не заботится о деталях всей складской операции; это работа Меган. Все, что он знает, это то, что обычно те бланки запросов, которые он передает в архив, обрабатываются довольно быстро, но иногда на это уходит часы.
Вернуться к исходному вопросу
Итак, в чем смысл этого сложного упражнения? Короче говоря, создать более конкретную модель, чем непрозрачный «волшебный тайник», которая позволяет нам более ясно думать о задействованной логистике.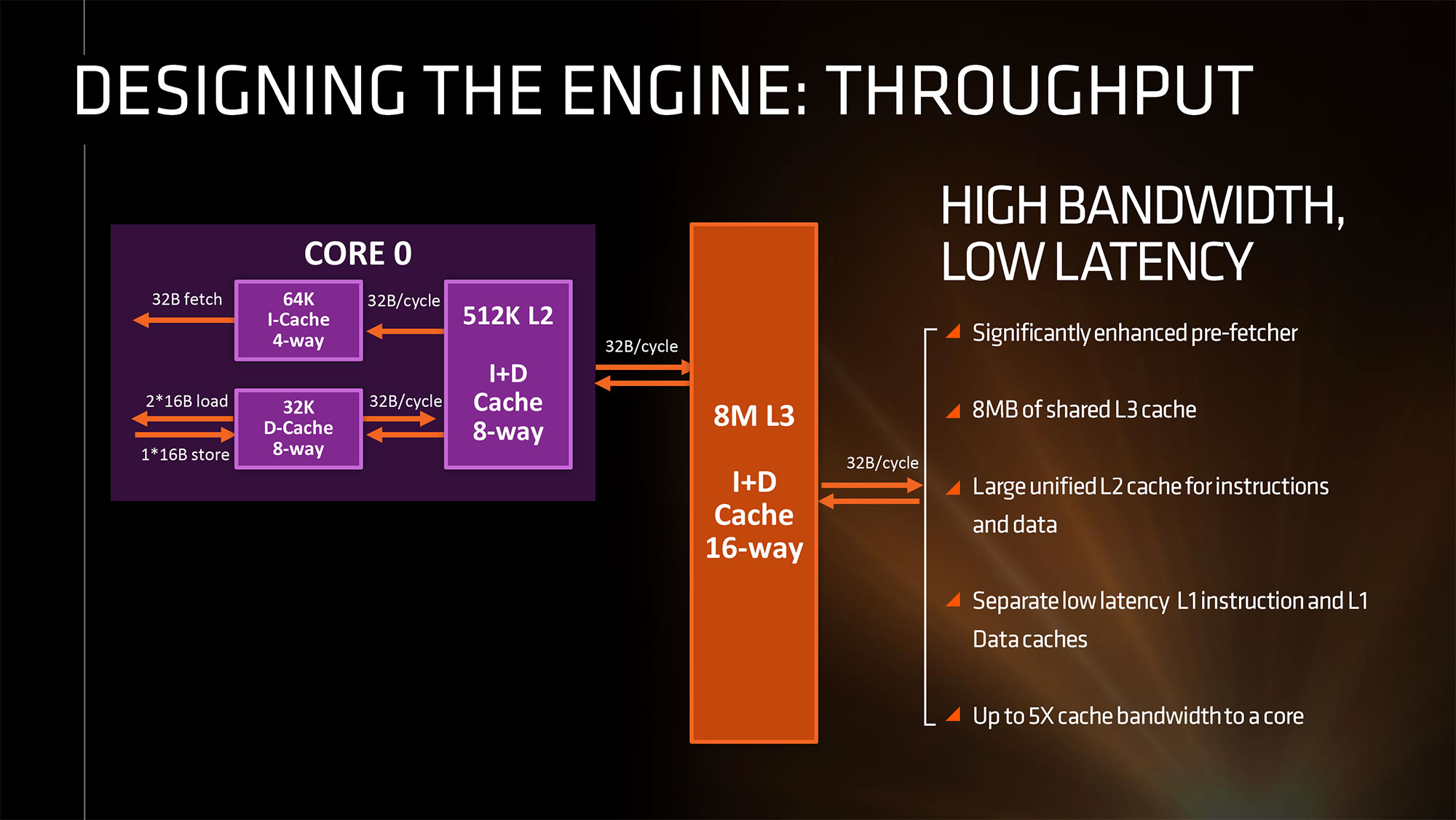 Логистика так же важна при разработке микросхемы, как и при управлении эффективным офисом.
Логистика так же важна при разработке микросхемы, как и при управлении эффективным офисом.
Первоначальный вопрос заключался в том, «почему бы нам не создать один большой кеш вместо нескольких маленьких». Итак, если у вас есть, скажем, четырехъядерный компьютер с 4 ядрами, каждое из которых имеет 32 КБ кэша данных L1, 256 КБ кеш-памяти L2 плюс 2 МБ общего кеша L3, почему бы нам просто не иметь для начала общий кэш ~ 3 МБ?
В нашей аналогии: примерно по той же причине у нас есть отдельные офисные столы, которых может быть 1.50 метров в ширину, вместо того, чтобы разместить четырех разных людей за одним огромным столом шириной 150 метров.
Смысл наличия чего-либо на столе в том, что до него легко добраться. Если мы сделаем стол слишком большим, мы не достигнем этой цели: если нам нужно пройти 50 метров, чтобы получить нужный файл, тот факт, что он технически «прямо здесь, на нашем столе», не помогает. То же самое и с кешами L1! Увеличение их делает их (физически) больше. Среди прочего, это замедляет доступ к ним и увеличивает потребление энергии (по разным причинам).Кеши L1 имеют размер, поэтому они достаточно велики, чтобы быть полезными, но достаточно малы, чтобы к ним можно было быстро получить доступ.
Среди прочего, это замедляет доступ к ним и увеличивает потребление энергии (по разным причинам).Кеши L1 имеют размер, поэтому они достаточно велики, чтобы быть полезными, но достаточно малы, чтобы к ним можно было быстро получить доступ.
Второй момент заключается в том, что кеши L1 имеют дело с разными типами доступа, чем другие уровни в иерархии кешей. Во-первых, их несколько: есть кэш данных L1, но есть также кеш инструкций L1, и, например, Процессоры Intel Core также имеют другой кэш инструкций, uOp cache, который (в зависимости от вашей точки зрения) является либо параллельным кешем инструкций L1, либо «кешем инструкций L0».
Кэш данных
L1 получает запрос на чтение и запись отдельных элементов, размер которых обычно составляет от 1 до 8 байтов, несколько реже больше (для инструкций SIMD). Уровни кеширования, расположенные выше в иерархии, обычно не имеют значения для отдельных байтов. В нашей аналогии с офисом все, что не находится где-то на столе, просто обрабатывается с детализацией отдельных файлов (или более крупных), соответствующих строкам кеша.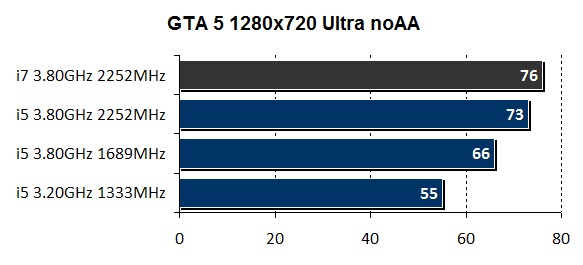 То же самое и с подсистемами памяти. Когда ядро выполняет доступ к памяти, вы имеете дело с отдельными байтами; кэши более высокого уровня обычно обрабатывают данные оптом, по одной строке кэша за раз.
То же самое и с подсистемами памяти. Когда ядро выполняет доступ к памяти, вы имеете дело с отдельными байтами; кэши более высокого уровня обычно обрабатывают данные оптом, по одной строке кэша за раз.
У
кэшей инструкций L1 совершенно другие шаблоны доступа, чем к кешам данных, и, в отличие от кеша данных L1, они доступны только для чтения, если говорить о ядре. (Запись в кэш инструкций обычно происходит косвенно, путем помещения данных в один из унифицированных кешей более высокого уровня, а затем кэш инструкций перезагружает их данные оттуда). По этим (и другим) причинам кеши инструкций обычно строятся совершенно иначе, чем кеши данных; Использование единого унифицированного кэша L1 означает, что результирующий проект должен соответствовать нескольким противоречивым критериям проектирования, что приводит к компромиссам, которые ухудшают его при любой цели.Унифицированный кэш L1 также должен обрабатывать как трафик инструкций, так и трафик данных, а это довольно большая нагрузка!
Кстати: программисту легко не обращать внимания на то, какая полоса пропускания кэша требуется для выборки инструкций, но это довольно много. Например, когда не выполняется код из кеша uOp, все ядра ЦП Intel Core i7 могут извлекать инструкции на 16 байт из кеша инструкций L1 за каждый цикл и фактически будут делать это до тех пор, пока выполнение инструкций не отстает от расшифровка.На частоте 3 ГГц мы говорим о порядка 50 ГБ / с на ядро здесь, только для выборки инструкций — хотя, конечно, только в том случае, если блок выборки инструкций постоянно занят, вместо того, чтобы по какой-то причине зависать. . На практике кэш L2 обычно видит только небольшую часть этого, потому что кеши инструкций L1 работают достаточно хорошо. Но если вы разрабатываете унифицированный кеш L1, вам нужно ожидать, по крайней мере, всплесков как высокого уровня инструкций, так и большого трафика данных (подумайте о чем-то вроде быстрого memcpy из нескольких килобайт данных с источником и получателем в кешах данных L1) .
Например, когда не выполняется код из кеша uOp, все ядра ЦП Intel Core i7 могут извлекать инструкции на 16 байт из кеша инструкций L1 за каждый цикл и фактически будут делать это до тех пор, пока выполнение инструкций не отстает от расшифровка.На частоте 3 ГГц мы говорим о порядка 50 ГБ / с на ядро здесь, только для выборки инструкций — хотя, конечно, только в том случае, если блок выборки инструкций постоянно занят, вместо того, чтобы по какой-то причине зависать. . На практике кэш L2 обычно видит только небольшую часть этого, потому что кеши инструкций L1 работают достаточно хорошо. Но если вы разрабатываете унифицированный кеш L1, вам нужно ожидать, по крайней мере, всплесков как высокого уровня инструкций, так и большого трафика данных (подумайте о чем-то вроде быстрого memcpy из нескольких килобайт данных с источником и получателем в кешах данных L1) .
Между прочим, это общий момент. Ядра ЦП могут обрабатывать многих обращений к памяти за цикл, если все они попадают в кеш L1. Для Haswell или более поздних версий Core i7 с тактовой частотой 3 ГГц мы говорим о совокупной полосе пропускания L1 кода и данных, намного превышающей 300 ГБ / с на ядро , если у вас есть только правильное сочетание инструкций; очень маловероятно на практике, но иногда вы все равно получаете всплески очень высокой активности.
Для Haswell или более поздних версий Core i7 с тактовой частотой 3 ГГц мы говорим о совокупной полосе пропускания L1 кода и данных, намного превышающей 300 ГБ / с на ядро , если у вас есть только правильное сочетание инструкций; очень маловероятно на практике, но иногда вы все равно получаете всплески очень высокой активности.
Кеши
L1 предназначены для максимально быстрой обработки таких всплесков активности, когда они происходят.Только то, что пропускает L1, необходимо передать на более высокие уровни кэша, которые не должны быть почти такими же быстрыми или иметь такую большую пропускную способность. Вместо этого они могут больше беспокоиться об энергоэффективности и плотности.
Третий момент: обмен. Большая часть смысла наличия отдельных рабочих столов в аналогии с офисом или кэш-памяти L1 на уровне ядра заключается в том, что они являются частными . Если он на вашем личном столе, вам не нужно никого спрашивать; вы можете просто схватить это.
Это очень важно. По аналогии с офисом, если вы делите гигантский стол с 4 людьми, вы не можете просто взять файл.Это не просто ваш стол , и один из трех ваших коллег может нуждаться в этом файле прямо сейчас (возможно, они пытаются сопоставить его с другим файлом, который они только что подняли на другом конце стола!) . Каждый раз, когда вы хотите что-то забрать, вам нужно кричать: «Все в порядке, если я возьму это?», А если кто-то еще захотел это сначала, вы должны подождать. Или у вас может быть какая-то схема, по которой каждый должен взять билет и ждать своей очереди, если возникнет конфликт.Или что-то другое; детали здесь не имеют большого значения, но все, что вы делаете, требует координации с другими.
То же самое относится и к нескольким ядрам, совместно использующим кеш. Вы не можете просто начать перебирать данные без предупреждения; все, что вы делаете в общем кэше, должно быть скоординировано со всеми остальными, с кем вы делитесь им.
Вот почему у нас есть частные кеши L1.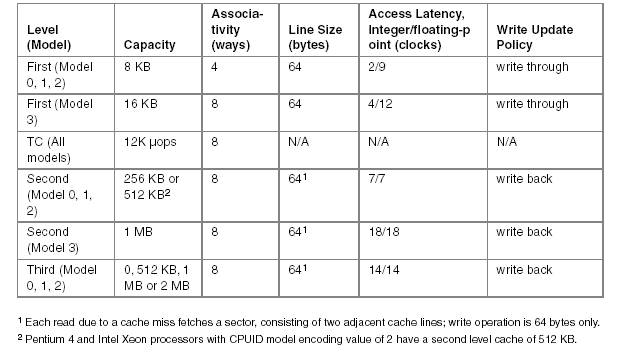 Кэш L1 — это ваш «стол». Пока вы там сидите, вы можете просто работать. Кэш L2 («картотека») выполняет большую часть координации с другими.Большую часть времени рабочий (ядро ЦП) сидит за столом. Бастер может просто прийти, забрать список новых запросов и положить ранее запрошенные файлы в картотеку, совершенно не отвлекая работника.
Кэш L1 — это ваш «стол». Пока вы там сидите, вы можете просто работать. Кэш L2 («картотека») выполняет большую часть координации с другими.Большую часть времени рабочий (ядро ЦП) сидит за столом. Бастер может просто прийти, забрать список новых запросов и положить ранее запрошенные файлы в картотеку, совершенно не отвлекая работника.
Только тогда, когда рабочий и Бастер хотят получить доступ к шкафу для хранения документов одновременно, или когда кто-то другой запросил файл, лежащий на столе рабочего, им нужно остановиться и поговорить друг с другом.
Короче говоря, кэш L1 в первую очередь обслуживает ядро процессора.Поскольку это личное, оно требует очень небольшой координации. Кэш L2 по-прежнему является частным для ядра ЦП, но, помимо кэширования, он несет дополнительную ответственность: обрабатывать большую часть трафика шины и связи вместо прерывания ядра (у которого есть дела поважнее).
Кэш L3 — это совместно используемый ресурс, и доступ к нему должен быть глобально скоординирован. В аналогии с офисом это работало, когда у рабочих был только один способ получить к нему доступ: а именно, пройти через Бастер (автобус).Автобус — это узкое место; есть надежда, что на предыдущих двух уровнях кэш-памяти количество обращений к памяти сократилось настолько, что это не привело к снижению производительности.
В аналогии с офисом это работало, когда у рабочих был только один способ получить к нему доступ: а именно, пройти через Бастер (автобус).Автобус — это узкое место; есть надежда, что на предыдущих двух уровнях кэш-памяти количество обращений к памяти сократилось настолько, что это не привело к снижению производительности.
Предупреждения
В этой статье рассматривается одна конкретная топология кэша, которая соответствует текущим процессорам x86 для настольных компьютеров (и ноутбуков): кэш-память L1I / L1D с разбивкой по ядрам, унифицированный кэш L2 по ядрам, общий унифицированный кэш L3 с ядрами, подключенными через кольцевую шину.
Не всякая система выглядит так. Некоторые (в основном старые) системы не имеют разделенных кешей инструкций и данных; у некоторых есть полная гарвардская архитектура, в которой память инструкций и память данных полностью разделены. Часто L2 используются несколькими ядрами (представьте себе один офис с одним шкафом для документов и несколькими столами). В этом типе конфигурации кэши L2 эффективно действуют как часть шины между ядрами. Многие системы не имеют кешей L3, а некоторые имеют кеши L3 и L4! Я также не говорил о системах с несколькими сокетами ЦП и т. Д.
В этом типе конфигурации кэши L2 эффективно действуют как часть шины между ядрами. Многие системы не имеют кешей L3, а некоторые имеют кеши L3 и L4! Я также не говорил о системах с несколькими сокетами ЦП и т. Д.
Я остановился на кольцевой шине, потому что она хорошо вписывается в аналогию. Кольцевые автобусы довольно распространены. Иногда (особенно когда нужно соединить только два или три блока) это полная сетка; иногда это несколько кольцевых автобусов, соединенных перекладиной (что вполне соответствует аналогии с офисом: многоэтажное офисное здание с одним «Бастером», курсирующим по этажу, и лифтом, соединяющим этажи).
Как разработчик программного обеспечения, существует естественная тенденция предполагать, что вы можете волшебным образом соединить модуль A с модулем B, и данные просто телепортируются с одного конца на другой.То, как фактически работает память, сейчас невероятно сложно, но абстракция, представленная программисту, представляет собой всего лишь один из большого плоского массива байтов.
Аппаратно так не работает. Кусочки не связаны волшебным образом через невидимый эфир. Модули A и B не являются абстрактными понятиями; это физические устройства, настоящие крошечные машины, которые занимают реальную физическую площадь на кремниевом кристалле. У чипов есть «план этажа», и это не расплывчатый кивок или шутка; это настоящая двухмерная карта того, что и куда идет.Если вы хотите подключить A к B, вам необходимо проложить между ними реальный физический провод. Провода занимают место, и для их управления требуется энергия (чем больше они длины). Проведение связки проводов между A и B означает, что это физически блокирующая область, которую можно использовать для подключения других вещей (да, чипы используют провода на нескольких уровнях, но это все еще серьезная проблема; если вам интересно, погуглите «перегрузка маршрутизации») . Перемещение данных на чипе — настоящая логистическая проблема, к тому же чрезвычайно сложная.
Итак, хотя офисная штука ирония, «кому нужно с кем говорить» и «как выглядит геометрия этой системы — допускает ли она разумную планировку?» это очень актуальные вопросы как для аппаратного обеспечения, так и для общей конструкции системы, которые могут иметь огромное влияние. Пространственные метафоры — полезный способ концептуализации лежащей в основе реальности.
Нравится:
Нравится Загрузка …
Связанные
Как включить кэширование второго уровня в спящем режиме
Кэш первого уровня будет включен по умолчанию, но для включения кеширования второго уровня нам нужно выполнить некоторые настройки, давайте рассмотрим несколько моментов по этому поводу..
- Кэш второго уровня был введен в спящем режиме 3.0
- Когда мы когда-либо загружаем какой-либо объект из базы данных, спящий режим проверяет, доступен ли этот объект в локальной кэш-памяти этого конкретного сеанса [ означает кеш первого уровня ], если недоступен, то спящий режим проверяет, доступен ли объект в глобальном кэше или заводском кеше [ кеш второго уровня ], если он недоступен, то спящий режим попадет в базу данных и загрузит объект оттуда, а затем сначала сохранится в локальном кеш сеанса [первый уровень], затем в глобальном кеше [кеш второго уровня]
- Когда другой сеанс должен загрузить тот же объект из базы данных, то спящий режим копирует этот объект из глобального кеша [кеш второго уровня] в локальный кеш этого нового сеанса
Кэш второго уровня в спящем режиме от 4 поставщиков…
- Easy Hibernate [EH Кэш] Кэш из фреймворка гибернации
- Кэш Open Symphony [OS] из Open Symphony
- SwarmCache
- TreeCache из JBoss
Как включить кэш второго уровня в спящем режиме
Нам нужен один класс провайдера, мы собираемся чтобы увидеть класс провайдера гибернации, который является EHCache
Требуются изменения
Чтобы включить кэш второго уровня в спящем режиме, необходимы следующие изменения 3
- Добавьте файл конфигурации класса провайдера в спящий режим, например…
<имя свойства = "спящий режим.cache.provider_class "> org.hibernate.cache.EhCacheProvider
- Настроить элемент кеша для класса в файле сопоставления гибернации…
Примечание : это должно быть записано вскоре после
- создать файл xml с именем ehcache.xml и сохраните в месте пути к классу [без путаницы, я имею в виду в том месте, где у вас есть отображение и конфигурация XML] в веб-приложении.
Важные моменты этого кэша второго уровня
Давайте возьмем пример, у нас есть 2 класса pojo в нашем приложении, такие как Student, Employee.
- Если мы загружаем объект ученика из базы данных, то, поскольку его первый раз спящий режим попадет в базу данных и получит данные этого объекта ученика и сохранит их в кэш-памяти сеанса 1 [кэш первого уровня], затем в глобальном кеше [второй уровень cache] предоставляется, если мы запишем
в файле сопоставления учащихся - Я имею в виду, что спящий режим по умолчанию будет храниться в локальной памяти сеанса, но он хранится только в глобальном кеше [кеш второго уровня] только если мы напишем
в файле сопоставления учащихся, в противном случае спящий режим не будет хранить в глобальном кеше - Теперь возьмем другой сеанс, например, сеанс 2, если сеанс 2 также загрузит студента объект, то спящий режим будет загружен из глобального кеша [кеш второго уровня], поскольку объект ученика доступен в глобальном [Фактически, когда мы когда-либо хотим загрузить любой объект, спящий режим сначала будет проверять локальный, затем глобальный, а затем базу данных, надеюсь, вы это помните], теперь если сессия 3 измените этот объект ученика, тогда спящий режим выдаст ошибку, потому что мы написали
в файле сопоставления учеников - Мы можем избежать этого, написав
- так что помните, что элемент
имеет такое большое значение
Сопряжения, я еще не объяснил про ehcache.xml, вы заметили? Я объясню это на примере этого кэша второго уровня гибернации в следующем сеансе
Вам также может понравиться
::. Об авторе. :: | |||
Основатель Java4s — Get It Yourself, популярного блога по программированию на Java / J2EE, Love Java и фреймворки пользовательского интерфейса. | |||
Разница между кешем L1, L2 и L3: типы и важность кеш-памяти ЦП
Каждый современный процессор имеет небольшой объем кэш-памяти. За последние несколько десятилетий архитектуры кэш-памяти стали все более сложными: уровни кеш-памяти ЦП увеличились до трех: L1, L2 и L3, размер каждого блока увеличился, а ассоциативность кеша также претерпела несколько изменений.Но прежде чем мы углубимся в подробности, позвольте мне спросить вас, что такое кеш-память и почему она важна? Кроме того, современные процессоры состоят из кеш-памяти L1, L2 и L3. В чем разница между этими уровнями кеша?
Кэш-память против системной памяти: SRAM против DRAM
Кэш-память основана на гораздо более быстрой (и дорогой) статической памяти, тогда как системная память использует более медленную DRAM (динамическую RAM). Основное различие между ними заключается в том, что первый сделан из КМОП-технологии и транзисторов (по шесть на каждый блок), а второй использует конденсаторы и транзисторы.
DRAM необходимо постоянно обновлять (из-за утечки платы) для хранения данных в течение более длительных периодов. Из-за этого он потребляет значительно больше энергии, а также работает медленнее. SRAM не нужно обновлять, и он намного эффективнее. Однако более высокая цена помешала массовому внедрению, ограничивая его использование кеш-памятью процессора.
Важность кэш-памяти в процессорах?
Современные процессоры на световые годы опережают своих примитивных предков, которые были примерно в 80-х и начале 90-х годов.В наши дни топовые потребительские чипы работают на частоте более 4 ГГц, в то время как большинство модулей памяти DDR4 рассчитаны на частоту менее 1800 МГц. В результате системная память слишком медленная, чтобы напрямую работать с процессорами, не сильно замедляя их работу. Здесь на помощь приходит кэш-память. Она действует как промежуточное звено между ними, храня небольшие фрагменты повторно используемых данных или, в некоторых случаях, адресов памяти этих файлов.
Кэш L1, L2 и L3: в чем разница?
В современных процессорах кэш-память разделена на три сегмента: кэш L1, L2 и L3, в порядке увеличения размера и уменьшения скорости.Кэш L3 является самым большим, а также самым медленным (процессоры Ryzen 3-го поколения имеют большой кэш L3 размером до 64 МБ). L2 и L1 намного меньше и быстрее, чем L3, и являются отдельными для каждого ядра. В старых процессорах не было кэша третьего уровня третьего уровня, а системная память напрямую взаимодействовала с кешем второго уровня:
Кэш
первого уровня делится на две части: кэш данных первого уровня и кэш инструкций первого уровня. Последний содержит инструкции, которые будут использоваться ядром ЦП, в то время как первый используется для хранения данных, которые будут записаны обратно в основную память.
Кэш
L1 не только работает как кэш инструкций, но также содержит данные предварительного декодирования и информацию о ветвлениях. Кроме того, в то время как кэш данных L1 часто действует как кэш вывода, кэш инструкций L1 ведет себя как кэш ввода. Это полезно, когда задействованы петли, поскольку необходимые инструкции находятся рядом с блоком выборки.
Современные процессоры включают до 512 КБ кэш-памяти L1 (64 КБ на ядро) для флагманских процессоров, в то время как серверные части имеют почти вдвое больше.
Кэш L2 намного больше, чем L1, но в то же время медленнее.Они варьируются от 4 до 8 МБ на флагманских процессорах (512 КБ на ядро). Каждое ядро имеет свой собственный кэш L1 и L2, в то время как последний уровень, кеш L3, используется всеми ядрами на кристалле.
Кэш
L3 — это кэш самого низкого уровня. Он варьируется от 10 МБ до 64 МБ. Серверные микросхемы имеют до 256 МБ кеш-памяти третьего уровня. Кроме того, процессоры AMD Ryzen имеют гораздо больший размер кеш-памяти по сравнению с конкурирующими чипами Intel. Это связано с дизайном MCM по сравнению с Monolithic на стороне Intel. Подробнее об этом читайте здесь.
Когда ЦП нужны данные, он сначала выполняет поиск в кэше L1 связанного ядра.Если он не найден, затем выполняется поиск кешей L2 и L3. Если необходимые данные найдены, это называется попаданием в кэш . С другой стороны, если данных нет в кеше, ЦП должен запросить их загрузку в кеш из основной памяти или хранилища. Это требует времени и отрицательно сказывается на производительности. Это называется промахом в кэше .
Как правило, частота попаданий в кэш повышается при увеличении размера кэша. Это особенно верно в случае игр и других рабочих нагрузок, чувствительных к задержкам.
Инклюзивный и монопольный кэш
Базовая конфигурация кеша бывает двух типов: включающая и монопольная. Если все блоки данных, присутствующие в кэше более высокого уровня, присутствуют в кэше более низкого уровня, то кэш низкого уровня известен как включающий кэш более высокого уровня.
С другой стороны, если кэш нижнего уровня содержит только блоки данных, которых нет в кэше верхнего уровня, то считается, что кэш не включает кэш верхнего уровня.
Рассмотрим ЦП с двумя уровнями кэш-памяти.Теперь предположим, что запрошен блок X. Если блок находится в кэше L1, данные считываются из кеша L1 и потребляются ядром ЦП. Однако, если блок не найден в кэше L1, но присутствует в L2, он извлекается из кеша L2 и помещается в L1.
Если кэш L1 также заполнен, блок удаляется из L1, чтобы освободить место для более нового блока, в то время как кэш L2 остается неизменным. Однако, если блок данных не обнаружен ни в L1, ни в L2, он извлекается из памяти и помещается на оба уровня кеша.В этом случае, если кэш L2 заполнен и блок вытесняется, чтобы освободить место для новых данных, кэш L2 отправляет запрос недействительности в кэш L1, поэтому вытесненный блок также удаляется оттуда. Из-за этой процедуры аннулирования инклюзивный кеш работает немного медленнее, чем не включающий или монопольный.
Теперь рассмотрим тот же пример с неисключающим или исключительным кешем. Предположим, что ядро ЦП отправляет запрос на блок X. Если найден блок X, то ядро считывает и потребляет его из этого места.Однако, если блок X не найден в L1, но присутствует в L2, то он перемещается из L2 в L1. Если в L1 нет места, один блок удаляется из L1 и сохраняется в L2. Это единственный способ пополнения кэша L2, так как он действует как кэш жертвы. Если блок X не найден в L1 или L2, он извлекается из памяти и помещается только в L1.
Существует третья, менее часто используемая политика кеширования, называемая неисключительным неисключительным (NINE). Здесь блоки не включают и не исключают кеш верхнего уровня.Давайте в последний раз рассмотрим тот же пример. Есть запрос на блок X, и он находится в L1. Затем ядро процессора будет читать и потреблять этот блок из кеша L1. Если блок не найден в L1, но присутствует в L2, то он выбирается из L2 в L1. Кэш L2 остается неизменным, подобно тому, как работает инклюзивный кеш.
Однако, если блок не найден ни на одном из уровней кэша, он извлекается из основной памяти и помещается как в L1, так и в L2. Однако, если это приводит к вытеснению блока из L2, в отличие от инклюзивного кеша, в кеш L1 не происходит обратного аннулирования, чтобы удалить тот же блок оттуда.
Взгляд на отображение памяти
Покончив с основными пояснениями кэширования, давайте поговорим о том, как системная память взаимодействует с кэш-памятью. Это называется отображением кэша или памяти . Кэш-память делится на блоки или наборы. Эти блоки, в свою очередь, разделены на n строк по 64 байта. Системная память делится на такое же количество блоков (наборов), что и кэш, и затем эти два блока связываются.
Если у вас 1 ГБ оперативной памяти, то кеш будет разделен на 8192 строки, а затем разделен на блоки.Это называется n-полосный ассоциативный кэш . В двухстороннем ассоциированном кэше каждый блок содержит по две строки, четырехсторонний включает четыре строки каждый, восемь строк для 8-полосного и шестнадцать строк для 16-полосного. Каждый блок в памяти будет размером 512 КБ, если общий размер ОЗУ составляет 1 ГБ.
Если у вас есть 512 КБ кэш-памяти с четырьмя линиями, ОЗУ будет разделено на 2048 блоков (8192/4 для 1 ГБ) и связано с таким же количеством блоков кэш-памяти с 4 строками.
Точно так же с 16-позиционным ассоциативным кешем кэш делится на 512 блоков, связанных с 512 (2048 КБ) блоками в памяти, каждый блок кеш-памяти содержит 16 строк.Когда в кэше заканчиваются блоки данных, контроллер кеша перезагружает новый набор блоков с необходимыми данными, чтобы продолжить выполнение процессора.
N-сторонний ассоциативный кэш — это наиболее часто используемый метод сопоставления. Есть еще два метода, известных как прямое сопоставление и полностью связанное сопоставление. В первом случае существует жесткая связь между строками кэша и памятью, а во втором случае кэш может содержать любой адрес памяти. По сути, каждая строка может обращаться к любому блоку основной памяти.У этого метода самый высокий процент попаданий. Однако его реализация требует больших затрат, и поэтому производители микросхем в основном избегают его.
Полностью ассоциированное отображение
Какое отображение лучше всего?
Прямое сопоставление — это самая простая в реализации конфигурация, но в то же время она наименее эффективна. Например, если ЦП запрашивает заданный адрес памяти (в данном случае 1000), контроллер загрузит 64-байтовую строку из памяти и сохранит ее в кэше (от 1000 до 1063). В будущем, если ЦП потребует данные с тех же адресов или адресов сразу после этого (от 1000 до 1063), они уже будут в кеше.
Это становится проблемой, когда центральному процессору нужны два адреса один за другим, которые находятся в блоке памяти, сопоставленном с одной и той же строкой кэша. Например, если ЦП сначала запрашивает адрес 1000, а затем адрес 2000, произойдет сбой в кэше, потому что эти два адреса находятся внутри одного и того же блока памяти (размер блока составляет 128 КБ). С другой стороны, сопоставленная ему строка кэша была строкой, начинающейся с адреса от 1000 до 1063. Таким образом, контроллер кеша загрузит строку с адреса 2000–2063 в первую строку кэша, удаляя старые данные.Это причина того, что кэш прямого отображения является наименее эффективным методом отображения кэша, и от него в значительной степени отказались.
Полностью ассоциативное отображение в некоторой степени противоположно прямому отображению. Между строками кеш-памяти и ячейками RAM-памяти нет жесткой связи. Контроллер кеша может хранить любой адрес. Там вышеуказанной проблемы не возникает. Этот метод сопоставления кэша является наиболее эффективным с наибольшей частотой попаданий. Однако, как уже объяснялось, это наиболее сложно и дорого реализовать.
В результате используется ассоциативно-множественное сопоставление, которое является гибридом между полностью ассоциативным и прямым отображением. Здесь каждый блок памяти связан с набором строк (в зависимости от типа отображения SA), и каждая строка может содержать данные с любого адреса в отображенном блоке памяти. В четырехстороннем ассоциативном кэш-памяти наборов каждый набор в кэше памяти может содержать до четырех строк из одного и того же блока памяти. При 16-позиционной конфигурации это число увеличивается до 16.
Когда все слоты в сопоставленном наборе израсходованы, контроллер вытесняет содержимое одного из слотов и загружает другой набор данных из того же сопоставленного блока памяти. .Увеличивая количество способов, которыми кэш-память ассоциативной памяти может иметь, например, с 4-го на 8-сторонний, у вас появляется больше слотов кэша, доступных для каждого набора. Однако, если вы не увеличиваете объем кеша, размер каждого связанного блока памяти увеличивается. По сути, увеличение количества доступных слотов в наборе кэш-памяти без увеличения общего размера кэша означает, что набор будет связан с большим блоком памяти, что эффективно снижает эффективность из-за увеличения количества сбросов.