Mysql сложные запросы: MySql. Сложные sql запросы » PacificSky.Ru
Оптимизация производительности MySQL | Losst
MySQL — это одна из самых популярных реляционных систем управления базами данных, которая используется для обеспечения большинства веб-сайтов в интернете. От скорости записи и получения данных из таблиц зависит скорость работы сайта, в целом, так как, если на один запрос будет уходить больше секунды, то это будет тормозить работу php, а в следствии скоро накопиться столько запросов, что сервер не сможет их обработать.
В сегодняшней статье мы поговорим о том, как выполняется оптимизация производительности mysql. Какие программы для этого лучше использовать и как это работает.
Содержание статьи:
Скорость работы MySQL
Оптимизация без аналитики бессмысленна. Перед тем как переходить к оптимизации давайте посмотрим как работает база данных сейчас, есть ли запросы, которые выполняются очень медленно. Все настройки вашего сервиса mysql находятся в файле /etc/my. cnf. Чтобы включить отображение медленных запросов добавьте такие строки в my.cnf, в секцию [mysqld]:
cnf. Чтобы включить отображение медленных запросов добавьте такие строки в my.cnf, в секцию [mysqld]:
log-slow-queries=/var/log/mariadb/slow_queries.log
long_query_time=5
Здесь первая строка включает запись лога медленных запросов, вторая указывает, что минимальное время запроса для внесения его в этот лог — две секунды. Еще можно включить в лог запросы, которые не используют индексы:
log-queries-not-using-indexes=1
Но это уже необязательно для проверки скорости и используется больше для отладки кода и правильности создания таблиц. Дальше перезапустите сервер баз данных и посмотрите лог:
systemctl restart mariadb
tail -f /var/log/mariadb/slow-queries.log
Мы можем видеть, что есть запросы, которые выполняются больше, чем 10 секунд. Это, например, запрос
SELECT option_name, option_value FROM wp_options WHERE autoload = 'yes';
Можно его выполнить отдельно, в консоли mysql:
Здесь тоже измеряется время, и мы видим результат — три секунды. Это очень много. И еще ничего, если такие запросы приходят редко, если ваш сайт постоянно под нагрузкой, то тремя секундами вы не отделаетесь, количество необработанных запросов будет расти, а скорость ответа увеличиваться до нескольких минут. Можно пойти двумя путями — оптимизировать код, убрать сложные запросы, или же нужна оптимизация mysql на сервере.
Это очень много. И еще ничего, если такие запросы приходят редко, если ваш сайт постоянно под нагрузкой, то тремя секундами вы не отделаетесь, количество необработанных запросов будет расти, а скорость ответа увеличиваться до нескольких минут. Можно пойти двумя путями — оптимизировать код, убрать сложные запросы, или же нужна оптимизация mysql на сервере.
Оптимизация MySQL
Конфигурация MySQL достаточно сложная, но, к счастью, вам не нужно в нее сильно углубляться. Есть специальный скрипт под названием MySQLTunner, который анализирует работу MySQL и дает советы какие параметры нужно изменить и какие значения для них установить. Скрипт поддерживает большинство версий MariaDB, MySQL и Percona XtraDB. Нам понадобится загрузить три файла с помощью wget:
wget http://mysqltuner.pl/ -O mysqltuner.plwget https://raw.githubusercontent.com/major/MySQLTuner-perl/master/basic_passwords.txt -O basic_passwords.txtwget https://raw.githubusercontent.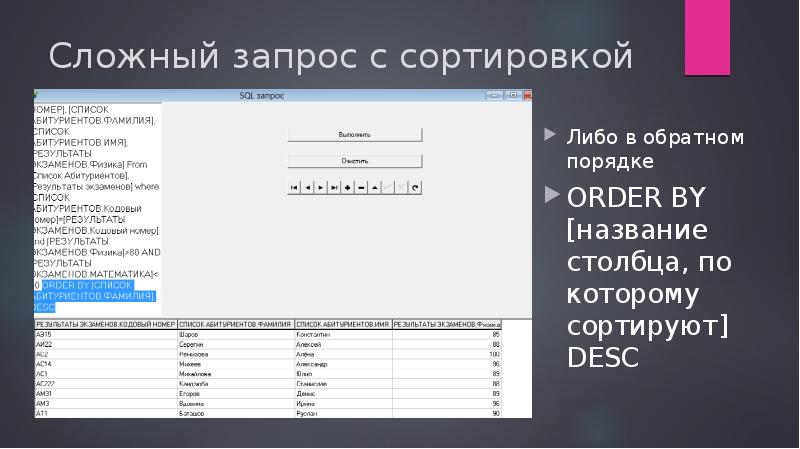 com/major/MySQLTuner-perl/master/vulnerabilities.csv -O vulnerabilities.csv
com/major/MySQLTuner-perl/master/vulnerabilities.csv -O vulnerabilities.csv
Первый из них — это сам скрипт, написанный на Perl, второй и третий — база данных простых паролей и уязвимостей. Они позволяют обнаружить проблемы с безопасностью. Дальше можно переходить к тестированию. Я использую сервер с настройками mysql по умолчанию, установленными панелью управления VestaCP.
perl ./mysqltuner.pl
Буквально за несколько минут скрипт выдаст полную статистику по работе MySQL. Количеству запросов, занимаемому объему памяти и эффективности работы буферов. Вы можете ознакомиться со всем этим, чтобы лучше понять в чем причина проблем. Проблемные места обозначены красными восклицательными знаками. Например, здесь мы видим, что размер буфера движка таблиц InnoDB (InnoDB buffer pool) намного меньше, чем должен быть для оптимальной работы:
Кроме того, в самом конце вывода утилита предоставит список рекомендаций как исправить ситуацию. Мы рассмотрим все сообщения утилиты из этого примера и почему нужно использовать именно их, а не другие.
Мы рассмотрим все сообщения утилиты из этого примера и почему нужно использовать именно их, а не другие.
Все параметры нужно добавлять в /etc/my.cnf. Еще раз замечу, что вы не копируете статью, а смотрите что вам выдала утилита. Начнем с query-cache.
query_cache_size=0
query_cache_type=0
query_cache_limit=1M
Скрипт рекомендует отключить кэш запросов. Query Cache — это кэш вызовов SELECT. Когда базе данных отправляется запрос, она выполняет его и сохраняет сам запрос и результат в этом кэше. И все бы ничего, но при использовании его вместе с InnoDB при любом изменении совпадающих данных кэш будет перестраиваться, что влечет за собой потерю производительности. И чем больше объем кэша, тем больше потери. Кроме того при обновлении кэша могут возникать блокировки запросов. Таким образом, если данные часто пишутся в базу данных — его надежнее отключить.
tmp_table_size=16M
max_heap_table_size=16M
Оба параметра устанавливают размер памяти, которая используется для внутренних временных таблиц MySQL. Утилита рекомендует использовать объем больше 16 мегабайт, просто установите это ваше значение для обоих переменных, если у вас достаточно памяти, то можно выделить 32 или даже 64. Но важно чтобы оба значения совпадали, иначе будет использоваться минимальное.
Утилита рекомендует использовать объем больше 16 мегабайт, просто установите это ваше значение для обоих переменных, если у вас достаточно памяти, то можно выделить 32 или даже 64. Но важно чтобы оба значения совпадали, иначе будет использоваться минимальное.
thread_cache_size=16
Этот параметр отвечает за количество потоков, которые будут закэшированны. После того, как работа с подключением будет завершена, база данных не разорвет его, а закэширует, если количество кэшированных потоков не превышает ограничение. Утилита рекомендует больше четырех, например, 16.
skip-name-resolve=1
Указывает, что не нужно пытаться определить доменное имя для подключений извне. Ускоряет работу, так как не тратится время на DNS запросы.
innodb_buffer_pool_size=800M
Этот параметр определяет размер буфера InnoDB в оперативной памяти, от этого размера очень сильно зависит скорость выполнения запросов. Значение зависит от размера ваших таблиц и количества данных в них. Если памяти недостаточно, запросы будут обрабатываться дольше. У меня используется стандартный объем 128, а нужно больше 652.
Если памяти недостаточно, запросы будут обрабатываться дольше. У меня используется стандартный объем 128, а нужно больше 652.
innodb_log_file_size=200M
Размер файла лога innodb должен составлять 25% от размера буфера. В случае 800 мегабайт это будет 200М. Но тут есть одна проблема. Чтобы изменить размер лога нужно выполнить несколько действий. Поскольку мы изменили все нужные параметры перейдем к перезагрузке сервера. Для нашего лога нужно остановить сервис:
systemctl stop mariadb
Затем переместите файлы лога в /tmp:
mv /var/lib/mysql/ib_logfile[01] /tmp
И запустите сервис:
systemctl start mariadb
Когда размер лога меняется сервис видит поврежденный лог, выдает ошибку и не запускается. Поэтому сначала нужно удалить старый. После этого смотрите есть ли сообщения об ошибках:
systemctl status mariadb
Тестирование результата
Готово оптимизация базы данных mysql завершена, теперь тестируем тот же запрос через клиент mysql:
mysql
> USE база_данных;> SELECT option_name, option_value FROM wpfc_options WHERE autoload = 'yes';
Первый раз он выполняется долго, может даже дольше чем обычно, но все последующие разы буквально мгновенно. Результат с более 3 секунд до 0,15. А если брать статистику из slow-log, то от более 12. Если в выводе утилиты для вас были предложены и другие оптимизации, то их тоже стоит применить.
Результат с более 3 секунд до 0,15. А если брать статистику из slow-log, то от более 12. Если в выводе утилиты для вас были предложены и другие оптимизации, то их тоже стоит применить.
Выводы
Как видите, оптимизация mysql это достаточно просто благодаря такому скрипту, но, в то же время, такая операция может очень сильно помочь, особенно высоконагруженным проектам. Еще лучше ускорить работу может только оптимизация запросов mysql. Не забывайте время от времени проверять параметры, чтобы быть уверенным что все в порядке. Если у вас остались вопросы, спрашивайте в комментариях!
На завершение лекция про производительность MySQL от Percona:
Оцените статью:
Загрузка…
Уроки PHP — урок 3.6 — Работа с БД MySQL. Виды оператора JOIN.
В MySQL выборку с помощью JOIN можно производить разными способами. Мы постараемся рассмотреть все эти виды запросов. Вот список всех запросов с участием JOIN:
Мы постараемся рассмотреть все эти виды запросов. Вот список всех запросов с участием JOIN:
- INNER JOIN
- LEFT JOIN
- LEFT JOIN без пересечений с правой таблицей
- RIGHT JOIN
- RIGHT JOIN без пересечений с левой таблицей
- FULL OUTER
- FULL OUTER где левая или правая таблица пустая
А вот иллюстрация к этим видам JOIN:
Я прикреплю к статье файлы нашего сайта, среди которых будет join.php в которых я буду выводить все записи с помощью разных операторов JOIN.
INNER JOIN
Начнем мы с этого оператора INNER JOIN, потому что этот оператор срабатывает по умолчанию, если вы пишите в запросе просто JOIN. Этот оператор выбирает все записи из двух таблиц, где выполняется условие идущее после оператора ON. У нас есть две таблицы Files и Messages:
Таблица Messages:
| mid | bodytext | fid |
| 1 | Test | NULL |
| 2 | Hi | 2 |
| 3 | Hello | NULL |
Таблица Files:
| fid | path |
| 1 | /files/1. png png |
| 2 | /files/2.png |
| 3 | /files/3.png |
Запрос с JOIN будет следующий:
SELECT * FROM Messages INNER JOIN Files ON Messages.fid=Files.fid
В результате будут выведены такие записи
| mid | bodytext | fid | path |
| 2 | Hi | 2 | /files/2.png |
То есть там где fid совпадает, то mysql выведит эти строки.
LEFT JOIN
При LEFT JOIN мы выводим все записи в которых в таблице слева (у нас это Messages), в том числе и те записи в которых эти значения fid есть в таблице Files.
Таблица Messages:
| mid | bodytext | fid |
| 1 | Test | 2 |
| 2 | Hi | NULL |
| 3 | Hello | 3 |
Таблица Files:
| fid | path |
| 1 | /files/1. png png |
| 2 | /files/2.png |
| 3 | /files/3.png |
Запрос с LEFT JOIN будет следующий:
SELECT * FROM Messages LEFT JOIN Files ON Messages.fid=Files.fid
В результате будут выведены такие записи
| mid | bodytext | fid | path |
| 1 | Test | 2 | /files/2.png |
| 2 | Hi | NULL | NULL |
| 3 | Hello | 3 | /files/3.png |
LEFT JOIN будет нужен когда выводим все записи сообщений, а есть или нет прикрепленный файл, мы проверим уже через PHP.
LEFT JOIN без пересечений с правой таблицей
LEFT JOIN выводит все записи из левой таблицы, кроме тех в которых fid совпадают в правой таблице.
Таблица Messages:
| mid | bodytext | fid |
| 1 | Test | 2 |
| 2 | Hi | NULL |
| 3 | Hello | 3 |
Таблица Files:
| fid | path |
| 1 | /files/1.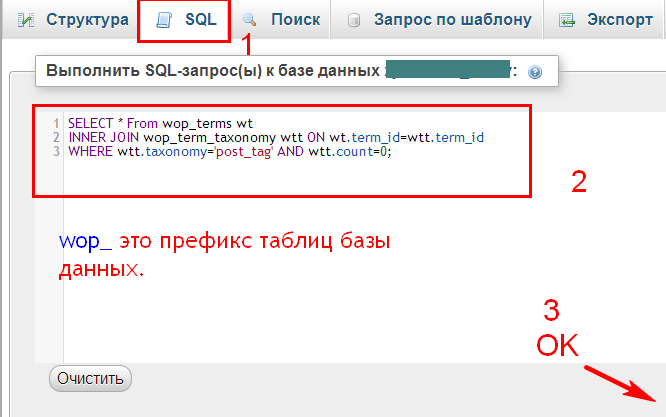 png png |
| 2 | /files/2.png |
| 3 | /files/3.png |
Запрос с LEFT JOIN без пересечений будет следующий:
SELECT * FROM Messages LEFT JOIN Files ON Messages.fid=Files.fid WHERE Files.fid IS NULL
В результате мы получим вот такую вот выборку:
| mid | bodytext | fid | path |
| 2 | Hi | NULL | NULL |
LEFT JOIN без перечений будет нужен когда выводим все записи без прикрепленных файлов.
RIGHT JOIN
RIGHT JOIN выводит все записи из правой таблицы, если есть пересечения, то выводится данные из левой таблицы.
Таблица Messages:
| mid | bodytext | fid |
| 1 | Test | 2 |
| 2 | Hi | NULL |
| 3 | Hello | 3 |
Таблица Files:
| fid | path |
| 1 | /files/1. png png |
| 2 | /files/2.png |
| 3 | /files/3.png |
Запрос с RIGHT JOIN будет следующий:
SELECT * FROM Messages RIGHT JOIN Files ON Messages.fid=Files.fid
В результате мы получим вот такую вот выборку:
| mid | bodytext | fid | path |
| NULL | NULL | 1 | /files/1.png |
| 1 | Test | 2 | /files/2.png |
| 3 | Hello | 3 | /files/3.png |
RIGHT JOIN будет нужен когда выводим все прикрепленные файлы без разницы используются они или нет, просто все файлы.
RIGHT JOIN без пересечений
RIGHT JOIN без пересечений выводит все записи из правой таблицы, кроме тех где есть пересечения с левой таблицей.
Таблица Messages:
| mid | bodytext | fid |
| 1 | Test | 2 |
| 2 | Hi | NULL |
| 3 | Hello | 3 |
Таблица Files:
| fid | path |
| 1 | /files/1. png png |
| 2 | /files/2.png |
| 3 | /files/3.png |
Запрос с RIGHT JOIN без пересечений будет следующий:
SELECT * FROM Messages RIGHT JOIN Files ON Messages.fid=Files.fid WHERE Messages.fid IS NULL
Таким образом мы получим следующие данные:
| mid | bodytext | fid | path |
| NULL | NULL | 1 | /files/1.png |
RIGHT JOIN будет нужен когда выводим все прикрепленные файлы, которые не прикреплены ни к каким сообщениям. Например, если мы хотим вывести файлы которые не используются.
FULL OUTER JOIN
Несмотря на то что в языке SQL есть FULL OUTER JOIN, в MySQL этого оператора нет. Дело в том что подобный оператор это огромная нагрузка на сервер. Сейчас у нас 3 файла и 3 сообщения, при этом образуется 4 строк в результате выполнения запроса. Я не уверен, что это хорошая идея писать запрос, который дает в совокупности два запроса LEFT JOIN и RIGHT JOIN. Но все же есть возможность эмулировать запрос FULL OUTER JOIN.
Я не уверен, что это хорошая идея писать запрос, который дает в совокупности два запроса LEFT JOIN и RIGHT JOIN. Но все же есть возможность эмулировать запрос FULL OUTER JOIN.
Таблица Messages:
| mid | bodytext | fid |
| 1 | Test | 2 |
| 2 | Hi | NULL |
| 3 | Hello | 3 |
Таблица Files:
| fid | path |
| 1 | /files/1.png |
| 2 | /files/2.png |
| 3 | /files/3.png |
Эмуляция запроса с FULL OUTER JOIN будет следующей:
SELECT * FROM Messages LEFT JOIN Files ON Messages.fid = Files.fid UNION SELECT * FROM Messages RIGHT JOIN Files ON Messages.fid = Files.fid
В этом запросе мы используем оператор UNION, чтобы объединить два запроса LEFT JOIN и RIGHT JOIN.
В результате мы получим следующие записи:
| mid | bodytext | fid | path |
| 1 | Test | 2 | /files/2.png |
| 2 | Hi | NULL | NULL |
| 3 | Hello | 3 | /files/3.png |
| NULL | NULL | 1 | /files/1.png |
И здесь я уже затрудняюсь сказать зачем потребуется FULL OUTER JOIN. Но раз это есть в SQL, то видимо потребуется потом.
FULL OUTER JOIN без пересечений
Еще один вид JOIN еще более безумный, чем просто FULL OUTER JOIN, а именно FULL OUTER JOIN без пересечений. Я даже не могу предложить где можно использовать этот вид JOIN. Потому что в результате мы получаем файлы которые не используются и сообщения без файлов. И как вы наверно уже догадались этого оператора тоже нет в MySQL. Остается его только эмулировать с помощью двух операторов LEFT JOIN без перечений и RIGHT JOIN без пересечений.
Остается его только эмулировать с помощью двух операторов LEFT JOIN без перечений и RIGHT JOIN без пересечений.
Эмуляция запроса FULL OUTER JOIN без пересечений:
$sql = 'SELECT * FROM Messages LEFT JOIN Files ON Messages.fid = Files.fid WHERE Files.fid IS NULL UNION SELECT * FROM Messages RIGHT JOIN Files ON Messages.fid = Files.fid WHERE Messages.fid IS NULL';
В результате (исходные таблицы те же что и в примере с FULL OUTER JOIN) мы получим:
| mid | bodytext | fid | path |
| 2 | Hi | NULL | NULL |
| NULL | NULL | 1 | /files/1.png |
Вот наверно и все, в следующих уроках мы начнем писать еще более сложные запросы к нескольким таблицам сразу.
Проверка нескольких условий (операторы OR и AND)
Вывести
данные о всех клиентах, проживающих в Сиэтле и только о тех клиентах из
Лос-Анджелеса, численность семьи которых превышает 3-х человек.
SQL:
SELECT lastname, name, region, fam_size
FROM tbl_clients
WHERE region= ‘Seattle’ OR region = ‘Los Angeles’ AND fam_size>3
Результат:
| lastname | name | region | fam_size |
| Stolz | Barbara | Seattle | 6 |
| Abbott | Thomas | Seattle | 2 |
| Vaughn | Jeffrey | Seattle | 2 |
| Sperber | Gregory | Seattle | 3 |
| Org | Liina | Los Angeles | 4 |
| Reynolds | Christian | Los Angeles | 5 |
| Salinas | Danny | Los Angeles | 5 |
| Miller | Robert | Los Angeles | 4 |
| Ausmees | Ingrid | Seattle | 6 |
| Clark | Margaret | Los Angeles | 4 |
| Philbrick | Penny | Seattle | 1 |
. … …
| ….. | ….. |
…
|
Ограничение на количество членов семьи в предыдущем запросе применяется
только к клиентам из Лос-Анджелеса, так как оператор AND выполняется
перед оператором OR.
Чтобы первым выполнялся оператор OR, в запросе нужно использовать
скобки.
В результате выполнения следующего запроса будут данные о всех клиентах
из Сиэтла и Лос-Анджелеса, имеющих семьи численностью больше 3 человек:
SQL:
SELECT lastname, name, region, fam_size
FROM tbl_clients
WHERE (region= ‘Seattle’ OR region = ‘Los Angeles’) AND
fam_size>3
mysql — объединение двух сложных SQL-запросов в один
Моя база данных mySQL имеет школ и пользователей таблицы. Каждая школа имеет идентификационный номер
Каждая школа имеет идентификационный номер , который ее идентифицирует. Когда пользователь присоединяется к школе, в столбце school пользователя устанавливается id этой школы. Мне нужно выполнить запрос, который выполняет следующие действия:
- Получает случайную школу из базы данных, к которой присоединились пользователи. (В базе данных должен быть хотя бы один учащийся, чей столбец
schoolустановлен наidэтой школы.) - Получает пользователя в этой школе с наибольшим значением (успехов / попыток).
- Если несколько пользователей в школе привязаны к наивысшему значению, запрос выберет случайного пользователя и вернет его.
Взамен мне нужен только объект пользователя. Я знаю, что могу использовать PHP для некоторой работы, но я бы хотел выполнить большую часть запросов SQL. Если возможно, я хотел бы сделать все это в одном запросе. Это возможно? Пока что я придумал:
ВЫБРАТЬ *
ИЗ "школ"
INNER JOIN `users` НА школы. id = users.school
ЗАКАЗАТЬ СЛУЧАЙ ()
ПРЕДЕЛ 1
id = users.school
ЗАКАЗАТЬ СЛУЧАЙ ()
ПРЕДЕЛ 1
 id = users.school
ЗАКАЗАТЬ СЛУЧАЙ ()
ПРЕДЕЛ 1
id = users.school
ЗАКАЗАТЬ СЛУЧАЙ ()
ПРЕДЕЛ 1
, после чего я мог сохранить идентификатор выбранной школы в PHP как $ schoolID и выполнить другой запрос:
ВЫБРАТЬ *
ОТ `пользователей`
ГДЕ школа = 2
И попытки! = 0
СОРТИРОВАТЬ ПО (
успехи / попытки
) DESC, RAND ()
ПРЕДЕЛ 1
Есть ли способ объединить их в один SQL-запрос, чтобы уменьшить нагрузку на сервер?
Строение:
Таблица пользователей:
+ ------------ + ---------- + ------ + ----- + --------- + ---------------- +
| Поле | Тип | Null | Ключ | По умолчанию | Экстра |
+ ------------ + ---------- + ------ + ----- + --------- + - -------------- +
| id | int (11) | НЕТ | PRI | | auto_increment |
| имя пользователя | символ (35) | НЕТ | | | |
| школа | int (11) | ДА | | | |
| успехи | int (11) | НЕТ | | 0 | |
| попытки | int (11) | НЕТ | | 0 | |
+ ------------ + ---------- + ------ + ----- + --------- + - -------------- +
Schools Таблица:
+ ------------ + ---------- + ------ + ----- + --------- + ---------------- +
| Поле | Тип | Null | Ключ | По умолчанию | Экстра |
+ ------------ + ---------- + ------ + ----- + --------- + - -------------- +
| id | int (11) | НЕТ | PRI | | auto_increment |
| имя | символ (35) | НЕТ | | | |
+ ------------ + ---------- + ------ + ----- + --------- + - -------------- +
Пример данных:
Таблица пользователей:
id имя пользователя школа успешных попыток
1 Джош 1 0 0
2 Джеймс 2 0 1
3 Эшли 2 2 2
4 Иоанна 1 1 1
5 будет 3 4 8
6 домкрат 3 1 2
Стол школы:
id имя
1 школа1
2 школа2
3 школа3
4 школа4
Только школы 1–3 могут быть выбраны из школ , и только пользователь 4 должен показывать, если была выбрана школа 1, пользователь 3 должен отображать, была ли выбрана школа 2, и пользователь 5 или 6 должен отображать, если школа 3 был выбран.
зависает — сложные проблемы с запросами MySQL, а также зависает SQL
Я пытаюсь написать довольно сложный SQL-запрос. Требования следующие:
Мне нужно вернуть эти поля из запроса:
трек. Исполнитель
track.title
track.seconds
track.track_id
track.relative_file
album.image_file
альбом.album
альбом.album_id
track.track_number
Я могу выбрать случайную дорожку с помощью следующего запроса:
выбрать
отслеживать.исполнитель, track.title, track.seconds, track.track_id,
track.relative_file, album.image_file, album.album,
альбом.album_id, track.track_number
ИЗ
трек, альбом
КУДА
альбом.album_id = track.album_id
ORDER BY RAND () ограничение 10;
Вот где у меня проблемы. У меня также есть таблица с названием «trackfilters1» — «trackfilters10». Каждая строка имеет поле идентификатора с автоматическим приращением. Следовательно, строка 10 — это данные для album_id 10. Эти поля заполнены единицами и нулями.Например, в альбоме № 10 10 треков, тогда trackfilters1.flags будет содержать «1111111111», если все треки должны быть включены в поиск. Если бы дорожку 10 нужно было исключить, она бы содержала «1111111110»
Эти поля заполнены единицами и нулями.Например, в альбоме № 10 10 треков, тогда trackfilters1.flags будет содержать «1111111111», если все треки должны быть включены в поиск. Если бы дорожку 10 нужно было исключить, она бы содержала «1111111110»
.
Моя проблема заключается в том, чтобы включить этот пункт.
Последний вопрос, который я придумал, следующий:
выбрать
track.artist, track.title, track.seconds,
track.track_id, track.relative_file, album.image_file,
album.album, album.album_id, трек.номер дорожки
ИЗ
трек, альбом, trackfilters1, trackfilters2
КУДА
альбом.album_id = track.album_id
И
((album.album_id = trackfilters1.id)
ИЛИ ЖЕ
(album.album_id = trackfilters2.id))
И
((mid (trackfilters1.flags, track.track_number, 1) = 1)
ИЛИ ЖЕ
(mid (trackfilters2.flags, track.track_number, 1) = 1))
ORDER BY RAND () предел 2;
, однако это приводит к зависанию SQL. Я предполагаю, что делаю что-то не так. Кто-нибудь знает, что это такое? Я был бы открыт для предложений, если есть более простой способ достичь моего конечного результата, я не собираюсь восстанавливать свой сломанный запрос, если есть лучший способ сделать это.
Кроме того, в своих испытаниях я заметил, что когда у меня был рабочий запрос и я добавил, скажем, trackfilters2 в предложение FROM, не используя его где-либо в запросе, он также зависал. Это заставляет меня задуматься. Это правильное поведение? Я бы подумал, что добавление в список FROM без использования данных просто заставит сервер получить больше данных, я бы не ожидал, что он зависнет.
Как написать сложный запрос SELECT
За свою карьеру я много раз слышал такие вещи, как «Как написать сложный запрос SELECT?», «С чего начать?» или же
«Этот запрос выглядит таким сложным.Как вы научились писать такие сложные запросы? ». Хотя я хотел бы думать о себе как о блестящем уме или гении или добавить что-то вроде «волшебника запросов» в свои профили в социальных сетях, что ж,
написание сложного SQL — не единственное, что для этого потребуется. Поэтому в этой статье я попытаюсь раскрыть «магию» написания сложных операторов SELECT.
Модель
Как всегда, я начну с модели данных, которую мы будем использовать. Перед тем, как начать писать (сложные) запросы, вы должны понять, что где, какие таблицы хранят какие данные.Также вы должны понимать характер отношений между этими таблицами.
Перед тем, как начать писать (сложные) запросы, вы должны понять, что где, какие таблицы хранят какие данные.Также вы должны понимать характер отношений между этими таблицами.
Если у вас нет этих двух, у вас есть 3 варианта:
- Спросите кого-нибудь, кто создал модель для документации (если этот человек доступен). То же означает
понимание бизнес-логики данных - Создавайте документацию самостоятельно. Это требует времени, но действительно очень полезно, особенно если вы прыгаете посередине.
недокументированного проекта - Вы всегда можете сделать это без документации, но вы должны быть уверены, что знаете, что делаете.Например. я
не рекомендовал бы вам водить машину, где я ремонтировал тормоза. Я имею в виду, вы можете попробовать, но …
Все эти советы можно использовать независимо от того, что вы делаете со своей базой данных.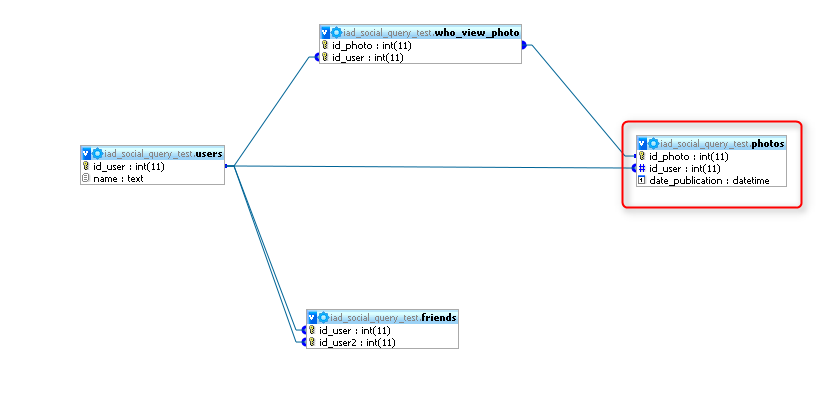 Общая картина будет
Общая картина будет
сэкономит вам много времени в долгосрочной перспективе, так что потратьте немного времени, когда вы только начинаете.
Давайте начнем со сложного запроса
Если я до сих пор потратил слишком много слов, давайте вспомним исходный вопрос: «Как написать сложный
ВЫБРАТЬ запрос? ».И начнем со сложного запроса.
SELECT country.country_name_eng, SUM (CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) AS calls, AVG (ISNULL (DATEDIFF (SECOND, call.start_time, call.end_time), 0 )) AS avg_difference FROM country LEFT JOIN city ON city.country_id = country.id LEFT JOIN customer ON city.id = customer.city_id LEFT JOIN call ON call.customer_id = customer.id GROUP BY country.id, country.country_name_eng HAVING AVG (ISNULL (DATEDIFF (SECOND, call.start_time, call.end_time), 0))> (SELECT AVG (DATEDIFF ( ВТОРАЯ, call. ORDER BY вызывает DESC, country.id ASC; |
 start_time, call.end_time)) FROM call)
start_time, call.end_time)) FROM call)И вот что возвращает запрос:
Как видите, у нас сложный запрос и в результате 2 строки.Без комментариев мы не сможем легко сказать, что делает этот запрос и как он работает. Давайте изменим это сейчас.
Как написать сложный запрос SELECT и где находятся данные?
Мы вернулись к исходному вопросу. Теперь мы ответим на этот вопрос шаг за шагом. Я скажу вам, каков был желаемый результат запроса (данное нам задание).
Возвращает все страны вместе с количеством связанных вызовов и их средней продолжительностью в секундах. в
результаты отображают только страны, в которых средняя продолжительность звонка больше, чем средняя продолжительность звонка всех
звонки.
Первое, что мы сделаем, это определим, какие таблицы мы будем использовать в процессе. В модели данных я добавил цвета в таблицы, которые нам нужно использовать.
А как определить, какие должны быть таблицы? Ответ состоит из двух частей:
- Используйте все таблицы, содержащие данные, которые необходимо отобразить в вашем результате. В нашем случае речь идет о таблицах.
страна (нам нужно country_name) и вызов (нам нужно start_time и end_time, чтобы
рассчитать среднюю продолжительность звонка) - Если таблицы из предыдущего пункта не связаны напрямую, вам также необходимо включить все
таблицы между ними (в нашем случае это было бы — как попасть из таблицы страна в
звонок стол)
После этого анализа мы знаем, что должны использовать следующие таблицы: страна , город ,
клиент , а звонит .Если мы хотим использовать их правильно, нам нужно СОЕДИНЯТЬ эти таблицы с помощью внешних ключей. Даже без
Даже без
думая о последнем запросе, теперь мы знаем, что он будет содержать эту часть:
ВЫБРАТЬ … ИЗ страны ЛЕВОЕ СОЕДИНЕНИЕ city ON city.country_id = country.id ЛЕВОЕ СОЕДИНЕНИЕ клиента ON city.id = customer.city_id ЛЕВОЕ СОЕДИНЕНИЕ звонок ВКЛ call.customer_id = customer.id …; |
Мы могли бы сделать одно — проверить, что будет возвращать такой запрос:
ВЫБРАТЬ * ИЗ страны ЛЕВОЕ СОЕДИНЕНИЕ город ВКЛ city.country_id = country.id ЛЕВОЕ СОЕДИНЕНИЕ клиента ВКЛ city.id = customer.city_id ЛЕВОЕ СОЕДИНЕНИЕ вызов ВКЛ call.customer_id = customer.id; |
Я не буду публиковать изображение всего результата, потому что в нем слишком много столбцов.Тем не менее, вы можете это проверить. я
всегда советую вам тестировать части ваших запросов. Хотя они не будут отображаться в окончательных результатах, они будут использоваться в фоновом режиме. Протестировав эти части, вы получите представление о том, что происходит в фоновом режиме, и сможете предположить, каким должен быть конечный результат. Но все же мы должны ответить на вопрос «Как написать сложный запрос SELECT?».
Хотя они не будут отображаться в окончательных результатах, они будут использоваться в фоновом режиме. Протестировав эти части, вы получите представление о том, что происходит в фоновом режиме, и сможете предположить, каким должен быть конечный результат. Но все же мы должны ответить на вопрос «Как написать сложный запрос SELECT?».
Как написать сложный запрос SELECT — записывать части запроса во время
Мы уже написали часть запроса, и это хорошая практика.Это поможет вам построить сложный запрос из
более простые «блоки», но вы также будете тестировать свой запрос по пути, потому что вы будете проверять его части за раз, как
хорошо, проверьте, как работает запрос при добавлении или выполнении определенных частей.
Я бы начал с этой части «где средняя продолжительность звонка больше, чем средняя продолжительность звонка для всех звонков» . Очевидно, что нам нужно рассчитать среднюю продолжительность всех звонков (в секундах). Итак, начнем
Итак, начнем
сделай это.
ВЫБРАТЬ СРЕДНЕЕ (РАЗНДАТ (СЕКУНДА, call.start_time, call.end_time)) ОТ вызова |
Мы объяснили агрегатные функции в предыдущей статье. Пока мы не говорили о функциях даты и времени, но достаточно сказать, что
Функция DATEDIFF вычисляет разницу в единицах заданного периода времени (здесь мы после секунд)
между временем начала и временем окончания.Возвращенный результат означает, что средняя продолжительность вызова составляла 354 секунды.
Теперь запишем запрос, который возвращает агрегированные значения для всех стран.
SELECT country.country_name_eng, SUM (CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) AS calls, AVG (ISNULL (DATEDIFF (SECOND, call.start_time, call.end_time), 0 )) AS avg_difference ИЗ страны LEFT JOIN city ON city. LEFT JOIN customer ON city.id = customer.city_id LEFT JOIN call ON call.customer_id = customer.id GROUP BY country.id, country.country_name_eng ORDER BY вызывает DESC, country.id ASC; |
 country_id = country.id
country_id = country.idЗдесь я хотел бы отметить две вещи:
- SUM (CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) — Суммирует только существующие вызовы.Поскольку мы использовали LEFT JOIN, мы также присоединимся к странам
без звонка. Если бы мы использовали COUNT, то для стран без вызова было бы возвращено значение 1, и
мы хотим 0 там (мы хотим видеть эту информацию) - AVG (ISNULL (DATEDIFF (SECOND, call.start_time, call.end_time), 0)) — это очень похоже на ранее упомянутый AVG. Разница в том, что я использовал ISNULL (…, 0). Это просто проверяет, соответствует ли вычисленное значение
NULL, и если да, заменяет его на 0.Расчетное значение может быть NULL, если нет данных (мы использовали LEFT JOIN)
Посмотрим, что вернет этот запрос.
«Как написать сложный запрос SELECT?» -> Теперь мы действительно близки к завершению нашего запроса и очень близки к этому ответу.
Итак, результат содержит все страны с их количеством звонков и средней продолжительностью звонков. Из этого результата
нас интересуют только те, у которых средняя продолжительность звонка превышает среднюю продолжительность звонка для всех звонков.Это наш исходный запрос, но с добавленными комментариями.
— запрос возвращает сводку вызовов для стран, в которых средняя продолжительность вызова> средней продолжительности вызова для всех вызовов SELECT country.country_name_eng, SUM (CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) Вызовы AS, AVG (ISNULL (DATEDIFF (SECOND, call.start_time, call.end_time), 0)) AS avg_difference FROM country — мы использовали левое соединение, чтобы включить также страны без вызова ВЛЕВО ПРИСОЕДИНЯЙТЕСЬ город НА ГОРОД. LEFT JOIN customer ON city.id = customer.city_id LEFT JOIN call ON call.customer_id = customer.id GROUP BY country.id, country.country_name_eng — отфильтровать только страны со средней продолжительностью вызова> средней продолжительности вызова для всех вызовов HAVING AVG (ISNULL (DATEDIFF (SECOND, call.start_time, call.end_time), 0))> (SELECT AVG (DATEDIFF (SECOND, call. start_time, call.end_time)) FROM call) ORDER BY звонки DESC, страна.id ASC; |
 country_id = country.id
country_id = country.idРезультат запроса вы можете увидеть на картинке ниже.
По сравнению с предыдущим запросом мы только что добавили часть HAVING. В части запроса WHERE мы тестируем
«Обычные» значения, часть запроса HAVING используется для проверки агрегированных значений. Мы используем его для сравнения AVG
значения.
Комментарии имеют решающее значение не только в базах данных, но и в программировании в целом. Добавив эти 3 строки комментариев,
запрос должен стать более читабельным. Даже тот, кто впервые взглянет на этот запрос, увидит, что вы сделали и почему. Этот кто-то может быть даже вами, если вы посмотрите на код, который вы написали некоторое время назад. Хотя на написание этих комментариев уходит некоторое время, не поленитесь и сделайте это. Вы, вероятно, сэкономите гораздо больше времени, пересматривая старые запросы / код.
Подведем итоги
Итак, вопрос был — «Как написать сложный запрос SELECT?».Хотя нет простого ответа, я бы предложил
следующие шаги:
- Думайте об этом как о кубиках LEGO и строите запрос таким образом. Относитесь к сложным деталям как к черным ящикам — они будут
верните то, что им нужно, и вы напишете (и включите в основной запрос) их позже - Определите все таблицы, которые вам понадобятся в запросе
- Объедините таблицы, содержащие данные, которые необходимо отобразить, или данные, используемые в части запроса WHERE.
- Отобразите все данные, чтобы проверить, правильно ли вы все соединили, и увидеть результат такого запроса
- Создавайте все подзапросы отдельно.Проверьте их, чтобы увидеть, возвращают ли они то, что должны. Добавьте их в основной запрос
- Все проверить
- Добавить комментарии

Не могли бы вы дать нам свой ответ на тему «Как написать сложный запрос SELECT?». Какой подход вы использовали?
Содержание
Эмиль — профессионал в области баз данных с более чем 10-летним опытом работы во всем, что касается баз данных.В течение многих лет он работал в сфере информационных технологий и финансов, а сейчас работает фрилансером.
Его прошлые и настоящие занятия варьируются от дизайна и программирования баз данных до обучения, консультирования и написания статей о базах данных. Также не забывайте, BI, создание алгоритмов, шахматы, филателия, 2 собаки, 2 кошки, 1 жена, 1 ребенок . ..
..
Вы можете найти его в LinkedIn
Просмотреть все сообщения Эмиля Drkusic
Последние сообщения Эмиля Drkusic (увидеть все)
Понимание запросов MySQL с помощью Explain
Вы находитесь на новой работе в качестве администратора базы данных или инженера по данным и просто заблудились, пытаясь понять, что эти безумно выглядящие запросы должны означать и делать.Почему существует 5 объединений и почему в подзапросе используется ORDER BY до того, как произойдет одно из соединений? Помните, вас наняли по какой-то причине — скорее всего, эта причина также связана со многими запутанными запросами, которые были созданы и отредактированы за последнее десятилетие.
Ключевое слово EXPLAIN используется в различных базах данных SQL и предоставляет информацию о том, как ваша база данных SQL выполняет запрос. В MySQL EXPLAIN может использоваться перед запросом, начинающимся с SELECT , INSERT , DELETE , REPLACE и UPDATE . Для простого запроса это будет выглядеть так:
Для простого запроса это будет выглядеть так:
EXPLAIN SELECT * FROM foo WHERE foo.bar = 'инфраструктура как услуга' OR foo.bar = 'iaas';
Вместо обычного вывода результатов MySQL будет затем показывать свой план выполнения оператора, объясняя, какие процессы и в каком порядке происходят при выполнении оператора.
Примечание: Если EXPLAIN не работает для вас, возможно, у пользователя вашей базы данных нет привилегии SELECT для таблиц или представлений, которые вы используете в своем операторе.
EXPLAIN — отличный инструмент для быстрого исправления медленных запросов. Хотя это, безусловно, может помочь вам, это не избавит вас от необходимости структурного мышления и хорошего обзора имеющихся моделей данных. Часто самым простым решением и самым быстрым советом является добавление индекса к конкретным столбцам таблицы, о которых идет речь, если они используются во многих запросах с проблемами производительности.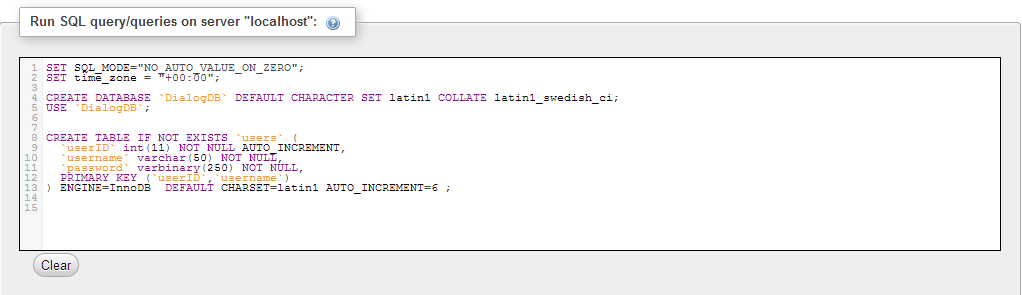 Однако будьте осторожны, не используйте слишком много индексов, так как это может быть контрпродуктивным. Чтение индексов и таблицы имеет смысл только в том случае, если таблица имеет значительное количество строк и вам нужно только несколько точек данных.Если вы извлекаете огромный набор результатов из таблицы и часто запрашиваете разные столбцы, индекс для каждого столбца не имеет смысла и больше снижает производительность, чем помогает. Чтобы узнать больше о фактических расчетах индекса по сравнению с отсутствием индекса, прочтите «Оценка производительности» в официальной документации MySQL.
Однако будьте осторожны, не используйте слишком много индексов, так как это может быть контрпродуктивным. Чтение индексов и таблицы имеет смысл только в том случае, если таблица имеет значительное количество строк и вам нужно только несколько точек данных.Если вы извлекаете огромный набор результатов из таблицы и часто запрашиваете разные столбцы, индекс для каждого столбца не имеет смысла и больше снижает производительность, чем помогает. Чтобы узнать больше о фактических расчетах индекса по сравнению с отсутствием индекса, прочтите «Оценка производительности» в официальной документации MySQL.
Вещи, которые вы хотите избежать везде, где это возможно и применимо, — это сортировка и вычислений внутри запросов. Если вы думаете, что не можете избежать вычислений в своих запросах: да, вы можете.Напишите набор результатов в другом месте и вычислите точку данных вне запроса, это снизит нагрузку на базу данных и, следовательно, в целом будет лучше для вашего приложения. Просто убедитесь, что вы задокументировали, почему вы выполняете вычисления в своем приложении, а не сразу получаете результат в SQL. В противном случае придет следующий администратор или разработчик базы данных, и у него возникнет великолепная идея использовать вычисление в запросе типа «о, смотрите, мой предшественник даже не знал, что вы можете сделать это в SQL!» Некоторые команды разработчиков, у которых еще не было неизбежной проблемы с умирающими базами данных, могут использовать вычисления в запросе для определения разницы между датами или аналогичными точками данных.
Общее практическое правило для SQL-запросов выглядит следующим образом:
Будьте точны и получайте только те результаты, которые вам нужны.
Давайте проверим более сложный запрос…
ВЫБЕРИТЕ site_options.domain, sites_users.user, site_taxes.monthly_statement_fee, site.name, AVG (цена) AS average_product_price FROM sites_orders_products, site_taxes, site, sites_users, site_options WHERE site_options.user_id И site_taxes.site_id = site.id И sites_orders_products.site_id = site.id ГРУППА ПО site.id ORDER BY site.date_modified desc LIMIT 5;
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| домен | пользователь | month_statement_fee | имя | average_product_price |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
| www.xxxxxxxxxxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxx | 3.254781 |
| www.xxxxxxxxxxx.com | [email protected] | 0,50 | xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx | 9.471022 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxxxx | 8.646297 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxx | 9.042460 |
| | [email protected] | 0.00 | xxxxxxxxxxxxxxxxxx | 6.679182 |
+ ----------------------------- + ------------------- ---------- + ----------------------- + --------------- --------------------------- + ---------------------- - +
5 рядов в наборе (0,00 сек)
… и его выход EXPLAIN .
+ ------ + ------------- + -------------------------- ------- + -------- + ----------------- + --------------- + --------- + --------------------------------- + ----- - + ----------- +
| id | select_type | стол | тип | possible_keys | ключ | key_len | ref | строки | Экстра |
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
| 1 | ПРОСТО | сайты | индекс | ПЕРВИЧНЫЙ, user_id | ПЕРВИЧНЫЙ | 4 | NULL | 858 | Использование временных; Использование файловой сортировки |
| 1 | ПРОСТО | sites_options | ref | site_id | site_id | 4 | служба.sites.id | 1 | |
| 1 | ПРОСТО | sites_taxes | ref | site_id | site_id | 4 | service.sites.id | 1 | |
| 1 | ПРОСТО | sites_users | eq_ref | ПЕРВИЧНЫЙ | ПЕРВИЧНЫЙ | 4 | service.sites.user_id | 1 | |
| 1 | ПРОСТО | sites_orders_products | ref | site_id | site_id | 4 | service.sites.id | 4153 | | //
+ ------ + ------------- + ---------------------------- ----- + -------- + ----------------- + --------------- + - -------- + --------------------------------- + ------ + ----------- +
5 рядов в наборе (0.00 сек)
Столбцы в выходных данных EXPLAIN с теми, которые требуют особого внимания для выявления проблем, выделены жирным шрифтом:
- id (идентификатор запроса)
- select_type (тип выписки)
- (ссылка на таблицу)
- (соединительный тип)
- possible_keys (какие ключи могли быть использованы)
- ключ (ключ, который был использован)
- key_len (длина используемого ключа)
- ref (столбцы по сравнению с индексом)
- строки (количество найденных строк)
- Extra (доп. Информация)
Таблица
Тип
Чем выше количество строк, в которых производится поиск, тем лучше должен быть уровень оптимизации индексов и точности запроса, чтобы максимизировать производительность.Столбец Extra показывает возможные действия, на которых вы могли бы сосредоточиться, чтобы улучшить свой запрос, если это применимо.
Показать предупреждения;
Если запрос, который вы использовали с EXPLAIN , не разбирается правильно, вы можете ввести SHOW WARNINGS; в редактор запросов MySQL, чтобы показать информацию о последнем операторе, который был запущен и не был диагностическим, т.е. он не будет отображать информацию для таких операторов, как SHOW FULL PROCESSLIST; . Хотя он не может дать надлежащий план выполнения запроса, как EXPLAIN , он может дать вам подсказки о тех фрагментах запроса, которые он может обработать.Допустим, мы используем запрос EXPLAIN SELECT * FROM foo WHERE foo.bar = 'Infrastructure as a service' OR foo.bar = 'iaas'; в любой данной базе данных, в которой фактически нет таблицы foo . Результат MySQL будет:
ОШИБКА 1146 (42S02): Таблица db.foo не существует
Если набрать ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; вывод выглядит следующим образом:
+ ------- + ------ + -------------------------------- ----- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- --- +
| Ошибка | 1146 | Таблица 'db.foo 'не существует |
+ ------- + ------ + ---------------------------------- --- +
1 ряд в комплекте (0,00 сек)
Давайте попробуем это с намеренной синтаксической ошибкой.
EXPLAIN SELECT * FROM foo WHERE name = ///;
Это генерирует следующие предупреждения:
> ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ;
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Уровень | Код | Сообщение |
+ ------- + ------ + ---------------------------------- ----------------------------------- +
| Ошибка | 1064 | У вас есть ошибка в синтаксисе SQL; (...) рядом с '///' в строке 1 |
+ ------- + ------ + ---------------------------------- ----------------------------------- +
Вывод этих предупреждений довольно прост и сразу же отображается MySQL как вывод результата, но для более сложных запросов, которые не анализируются, все еще можно посмотреть, что происходит в тех фрагментах запроса, которые могут быть проанализированы. ПОКАЗАТЬ ПРЕДУПРЕЖДЕНИЯ; включает специальные маркеры, которые могут предоставлять полезную информацию, например:
-
(фрагмент запроса) -
(условие, выражение1, выражение2) -
(фрагмент запроса) -
<временная таблица>: здесь будет создана внутренняя таблица для сохранения временных результатов, например, в подзапросах перед объединениями
Чтобы узнать больше об этих специальных маркерах, прочтите Extended Explain Output Format в официальной документации MySQL.
Есть несколько способов устранить основную причину плохой работы базы данных. Первое, на что следует обратить внимание, — это модель данных, то есть как структурированы данные и правильно ли вы используете базу данных? Для многих продуктов вполне подойдет база данных SQL. Следует помнить одну важную вещь — всегда отделять журналы доступа от обычной производственной базы данных, что, к сожалению, не происходит во многих компаниях. Чаще всего в этих случаях компания начинала с малого, росла и по сути все еще использовала одну и ту же базу данных, что означает, что они обращаются к одной и той же базе данных как для функций ведения журнала, так и для других транзакций.Это значительно снижает общую производительность, особенно по мере роста компании. Следовательно, очень важно создать подходящую и устойчивую модель данных.
Модель данных
Выбор модели данных, скорее всего, также откроет правильную форму базы данных (ов). Если ваш продукт не является очень простым, у вас, вероятно, будет несколько баз данных для нескольких вариантов использования — если вам нужно отображать числа, близкие к реальному времени, для журналов доступа, вам, скорее всего, понадобится высокопроизводительное хранилище данных, тогда как обычные транзакции могут происходить через SQL. база данных, и у вас может быть база данных графов, в которой также накапливаются соответствующие точки данных обеих баз данных в механизм рекомендаций.
Программная архитектура всего продукта так же важна, как и сама база данных, так как плохой дизайн здесь приведет к возникновению узких мест, которые идут к базе данных и замедляют все как со стороны программного обеспечения, так и то, что база данных может выводить. Вам нужно будет выбрать, подходят ли контейнеры для вашего продукта, является ли монолит лучшим способом справиться с задачами, может ли вы иметь основной монолит с несколькими микросервисами, нацеленными на другие функции, распространенные в другом месте, и как вы получаете доступ, собираете, обрабатываете , и хранить данные.
Оборудование
Так же важно, как и ваша общая структура, ваше оборудование является ключевым компонентом производительности вашей базы данных. Exoscale предлагает вам различные варианты инстансов, которые вы можете использовать в зависимости от вашей транзакции и объема хранилища, а также желаемого времени отклика.
Очень важно определить пиковые периоды вашего приложения и, следовательно, знать, когда, если возможно, опустить более медленные административные запросы. Дисковый ввод-вывод и сетевая статистика также должны быть приняты во внимание при проектировании времени транзакций и аналитики базы данных.
Сводка
В заключение кратко изложим основные моменты для долгосрочной работы:
- создать устойчивую модель данных, которая соответствует потребностям вашей компании
- выбрать правильную форму базы данных
- используйте программную архитектуру, которая соответствует вашему продукту
- регулярно проверяет структуру ваших запросов и использует
EXPLAINдля более сложных, оптимизирует использование выбранных вами баз данных, а также в отношении обновлений баз данных и их влияния на вас - выберите экземпляры, которые наилучшим образом соответствуют потребностям вашего приложения и базы данных в соответствии с производительностью и пропускной способностью.
Почему мы выбрали базу данных HTAP вместо MySQL для горизонтального масштабирования и сложных запросов
Отрасль: Прямая трансляция
Автор: Цзяцин Сю (DBA в BIGO)
Основанная в 2014 году, BIGO — это быстро- растущая компания социальных сетей, базирующаяся в Сингапуре.Основываясь на нашей мощной технологии обработки аудио и видео, глобальной передачи в реальном времени и сети доставки контента (CDN), BIGO выпустила такие продукты, как Bigo Live (потоковое видео в реальном времени), Likee (короткое видео) и imo (видеоконференцсвязь). ). В настоящее время BIGO может похвастаться почти 400 миллионами активных пользователей в месяц, а наши продукты и услуги охватывают более 150 стран и регионов.
Быстрый рост нашего бизнеса неотделим от нашей инфраструктуры и программного обеспечения.Поскольку данные нашего приложения быстро росли, мы пытались управлять нашими данными с помощью PhxSQL, MySQL и Pika, но их слабость в плане горизонтальной масштабируемости или сложных запросов разочаровала нас.
Благодаря TiDB, базе данных с открытым исходным кодом, совместимой с MySQL, горизонтально масштабируемой базе данных с высокой согласованностью, мы можем лучше обрабатывать наши данные. В этой статье мы поговорим о преимуществах TiDB и его новых функциях в TiDB 4.0.
Почему мы выбрали TiDB
Перед тем, как использовать TiDB, мы пробовали PhxSQL, MySQL и Pika, но у них были следующие недостатки:
- PhxSQL:
- Трудно масштабировать и сегментировать
- Не удавалось обрабатывать высокие запросы на второй (QPS)
- Почти не обслуживается
- MySQL:
- Трудно масштабировать
- Не очень хорошо выполнять сложные SQL-запросы
- Pika:
- Сложно выполнять сложные запросы и запросы диапазона
Мы искали новое решение и обнаружили, что TiDB, распределенная база данных гибридной транзакционной / аналитической обработки (HTAP) с открытым исходным кодом, была хорошим выбором.Мы приняли TiDB, потому что у него были следующие преимущества:
- Он совместим с протоколом MySQL. Чтобы перенести производственное приложение на TiDB, нам нужно всего лишь изменить небольшой фрагмент кода.
- Он подходит для различных сценариев использования, требующих высокой согласованности и высокой доступности с крупномасштабными данными.
- Он поддерживает горизонтальное масштабирование. Архитектура TiDB отделяет вычисления от хранилища и позволяет нам отдельно масштабировать или масштабировать вычислительные ресурсы или емкость хранилища в режиме онлайн по мере необходимости.
- Легко развернуть.
TiDB 4.0 в BIGO
TiDB — это распределенная база данных SQL с открытым исходным кодом, которая обеспечивает горизонтальную масштабируемость, высокую доступность и HTAP в реальном времени. В мае 2020 года TiDB выпустила версию 4.0 GA, что стало важной вехой в ее истории.
Ранее в этом году мы начали использовать бета-версию TiDB 4.0. Мы создали тестовый кластер, который будет повторяться вместе с последней разрабатываемой версией TiDB. Поэтому мы обновились до TiDB 4.0 GA вскоре после его выпуска.
Мы сделали смелый шаг и развернули два кластера TiDB в производственной среде, в основном для аналитической обработки.
- Один использовался для анализа показателей мониторинга сети. Объем данных этого кластера быстро рос, и его операторы SQL были в основном аналитическими. Приложение также требовало быстрого ответа.
- Другой был развернут в качестве дополнительного хранилища для системы больших данных. После обработки инструментами больших данных данные в кластере TiDB были предоставлены для онлайн-сервисов в реальном времени.Объем данных одной таблицы велик.
В TiDB 4.0 TiUP используется для развертывания кластера, Pump и Drainer используются для репликации данных на разных континентах на основе бинарных журналов, а TiFlash используется для анализа данных в реальном времени. Мы широко используем эти компоненты TiDB 4.0 в нашей системе.
Почему мы обновились до TiDB 4.0
Новая версия базы данных может внести нестабильность в существующую систему. Однако после осторожного и тщательного рассмотрения мы решили перейти на TiDB 4.0. Основными факторами были требования к нашему приложению и необходимость эффективного обслуживания базы данных.
Требования к приложению
Когда команда разработчиков выдвигает новые требования, мы как администраторы баз данных всегда делаем все возможное, чтобы удовлетворить их потребности.
Разработчики приложений жаловались, что сортировка набора символов TiDB не работает должным образом. Они были правы. До 4.0 TiDB не мог определять регистр букв при сортировке. Он обрабатывал прописные и строчные буквы одинаково.Благодаря 4.0, TiDB теперь поддерживает чувствительность к регистру с помощью наборов символов и сопоставлений.
В TiDB 4.0 пессимистическая модель транзакций, важная функция для электронной коммерции и финансовых платформ, обычно доступна. С TiDB 4.0 приложениям больше не нужно уделять много внимания несоответствиям или конфликтам данных.
Требования к обслуживанию
С TiDB 4.0 обслуживание также упрощается.
TiUP: лучшее управление пакетами
TiUP — это менеджер пакетов, который позволяет нам развертывать и поддерживать TiDB с помощью только одной строки команд TiUP.Это делает управление компонентами TiDB простым и гибким.
Кроме того, мы можем использовать TiUP для просмотра состояния всего кластера. Нам не нужно заходить в каждый кластер и смотреть на его статус отдельно.
Резервное копирование и восстановление
Еще одна полезная функция TiDB 4.0 — это резервное копирование и восстановление (BR). BR — это инструмент командной строки для распределенного резервного копирования и восстановления данных кластера TiDB. По сравнению с mydumper или загрузчиком BR больше подходит для кластеров с огромным объемом данных.
До TiDB 4.0, мы могли выполнять резервное копирование и восстановление только через mydumper или создавая моментальные снимки диска, что затрудняет обслуживание баз данных администраторами баз данных. Хотя мы хотели опробовать наши основные приложения с TiDB, отсутствие полной функции резервного копирования и восстановления помешало нам сделать это.
С BR мы будем использовать TiDB в большем количестве наших приложений и пойдем дальше и более уверенно с этой распределенной базой данных.
TiFlash: HTAP в реальном времени
Если вы спросите меня, какая мне больше всего нравится в TiDB 4.0, ответ абсолютно TiFlash. TiFlash — это компонент, который делает TiDB настоящей базой данных HTAP.
TiDB имеет два механизма хранения: TiKV, хранилище строк, и TiFlash, хранилище столбцов. TiFlash — это колоночное расширение TiKV, которое реплицирует данные из TiKV в соответствии с алгоритмом консенсуса Raft.
Архитектура TiDB с TiFlash
Обычно мы делим запросы на два типа: оперативная обработка транзакций (OLTP) и оперативная аналитическая обработка (OLAP). Мы можем считать само собой разумеющимся, что запросы от онлайн-приложений в реальном времени являются рабочими нагрузками OLTP, а сводка аналитики больших данных — рабочими нагрузками OLAP.Но так ли это на самом деле? В реальных сценариях использования для удовлетворения эксплуатационных требований многие онлайн-приложения запрашивают отчеты в реальном времени.
Если просто использовать инструменты для работы с большими данными, обработка этих запросов может занять T + 1 или даже T + N дней. Это далеко не реальное время. Одно из существующих решений — делать запросы к хранилищу OLTP. Другие решения включают изменение индексов, репликацию одних и тех же данных в другое хранилище или запись одних и тех же данных в разные таблицы. Эти решения либо неэффективны, либо хлопотны. TiFlash предоставляет нам новую возможность: добавление столбчатой реплики для получения аналитики в реальном времени.
Пример большого SQL-запроса
На изображении выше показан большой SQL-запрос из приложения реального времени. Он занимает более 100 строк и содержит множество таблиц и предложений GROUP BY , некоторые условия и агрегатную функцию SUM . Обычно запрос обрабатывается в онлайн-базе данных MySQL или базе данных TiDB с TiKV в качестве единственного механизма, и это может занять минуты или даже часы.Но с TiFlash, механизмом хранения столбцов, мы успешно сократили время обработки до 50 секунд. Более того, поскольку данные в TiFlash реплицируются из TiKV, а их согласованность гарантируется Raft, запрос TiFlash не только выполняется быстро, но и возвращает согласованные результаты в реальном времени.
TiDB также можно комбинировать с нашей существующей системой больших данных. Он предоставляет TiSpark, слой, созданный для запуска Apache Spark поверх TiDB. Мы можем использовать TiSpark для доступа к уровню хранения, включая TiKV и TiFlash.
В TiDB 4.0 GA в TiFlash добавлены два новых параметра, которые позволяют задействовать большее количество операторов и объединять больше запросов регионов. (Регион — это основная единица хранения данных в механизме хранения TiDB.) Настроив эти параметры, мы можем значительно повысить производительность. В нашем тесте TiFlash повысил производительность на 100%, а время запроса упало с 25 секунд до 11 ~ 12 секунд. Это означает, что онлайн-данные анализируются практически в реальном времени. По сравнению с TiFlash обработка извлечения, преобразования и загрузки (ETL) в нашей системе больших данных должна проходить через длинный конвейер данных.Без двусторонней проверки данных это может вызвать несогласованность данных или даже потерю данных. Теперь все наши приложения, как правило, выбирают TiFlash, а не традиционные решения для работы с большими данными.
Таким образом, кластер TiDB 4.0 для каждого из наших онлайн-приложений имеет как минимум одну реплику TiFlash. Даже если реплика TiFlash выйдет из строя, мы все равно сможем отправлять запросы на TiKV. Для администраторов баз данных стабильность базы данных является приоритетом, и TiFlash гарантирует, что база данных продолжает работать даже в сложных ситуациях.Это важная причина, по которой мы выбрали TiDB 4.0 и TiFlash.
Наши планы на будущее в отношении TiDB 4.0
TiDB 4.0 предлагает множество возможностей, которые нам еще предстоит изучить. В этом разделе я расскажу о том, как мы планируем наши следующие шаги с TiDB 4.0.
TiCDC: репликация из нескольких источников
Поскольку наш бизнес распространяется на более чем один континент, нашим приложениям часто приходится иметь дело с репликацией из нескольких источников. Раньше мы использовали Pump and Drainer для реализации репликации, но когда данные записывались из нескольких источников, нам также приходилось дедуплицировать записанные данные.
В таком сценарии насос и слив не являются идеальным решением. У них есть проблемы с развертыванием и доступностью, они потребляют слишком много ресурсов и создают нежелательные двоичные журналы. В TiDB 4.0 мы поэкспериментируем с TiCDC, инструментом сбора данных об изменениях, для репликации данных между несколькими кластерами TiDB и между различными источниками данных. Мы также разработаем некоторые функции самостоятельно, такие как разрешение конфликтов и объединение данных.
Обнаружение службы на основе драйвера размещения
Многие приложения используют TiKV и TiFlash в качестве механизмов хранения, а сервер TiDB — это служба без отслеживания состояния.Большинство приложений интегрированы с этой службой без отслеживания состояния и используют службу, похожую на прокси, для пересылки запросов на различные серверы TiDB для достижения балансировки нагрузки. Такая архитектура не очень изящна. Когда прокси-сервер подключен к контейнеру, кластер может выполнять эластичное планирование через контейнер или другими методами. В таких случаях прокси-сервер может быть не в состоянии достаточно быстро обнаружить изменения в серверной части.
Placement Driver (PD) решает эту проблему, поскольку предоставляет интерфейсы на основе etcd.Мы можем найти доступные узлы TiDB в этих интерфейсах. Когда кластер эластично масштабируется, например, в часы пик, он может быстро масштабировать узел TiDB без сохранения состояния. Затем PD может быстро обнаружить сервер TiDB, и мы сможем найти услугу у клиента и направить увеличившийся трафик на этот сервер.
Таким образом, масштабируемая служба может перейти в оперативный режим за короткое время, и нам не придется изменять большую часть кода приложения. Если мы сделаем это по-старому, масштабируемая база данных должна будет зарегистрировать службу, а затем снова зарегистрироваться в прокси, что может задержать весь процесс.
Панель мониторинга TiDB: как выглядит рабочая нагрузка базы данных
Панель мониторинга TiDB представляет собой графический интерфейс со встроенными виджетами, которые позволяют пользователям легко диагностировать, отслеживать и управлять кластерами. В едином интерфейсе пользователи могут проверять состояние выполнения распределенного кластера и управлять кластером, в том числе:
- Быстрый поиск горячих точек кластера
- Анализ производительности выполнения операторов SQL
- Просмотр медленных запросов
- Создание отчетов диагностики кластера
- Поиск и экспорт журналов
- Экземпляры профилирования
Панель мониторинга TiDB
Как администратор баз данных я иногда сталкиваюсь с конфликтами с разработчиками приложений.Разработчики могут настаивать на том, что они не отправляли никаких запросов, не видели изменений и, следовательно, данные не имеют точки доступа. До TiDB 4.0 у нас не было возможности доказать или опровергнуть такое утверждение. Теперь с TiDB Dashboard, , мы можем четко видеть , как выглядит рабочая нагрузка базы данных .
Например, возьмем виджет Key Visualizer. Это инструмент визуальной диагностики, который позволяет пользователям наблюдать за объемом чтения и записи в кластере TiDB с течением времени и представляет данные в виде тепловой карты.
Key Visualizer
На этой тепловой карте:
- Ось X представляет время.
- Ось Y представляет ключевые диапазоны с отображениями между ключевыми диапазонами в таблицы и индексы.
- Цвета представляют объем чтения или записи диапазонов клавиш. Чем ярче цвет, тем выше объем чтения или записи.
Key Visualizer популярен среди пользователей. Мы слышали, что пользователь даже для развлечения создал тепловую карту смайлов с помощью Key Visualizer:
Тепловая карта смайликов в Key Visualizer
С помощью Key Visualizer мы можем наблюдать рабочую нагрузку для диапазона клавиш.Таким образом, когда команда разработчиков заявляет, что их данные не имеют точки доступа, администраторы баз данных могут показать им тепловую карту и объяснить. В конце концов, приложение может не знать о рабочей нагрузке кластера и тенденции. Этот полный снимок рабочей нагрузки дает нам много информации.
Конечно, у TiDB Dashboard есть и другие преимущества. Он точно отслеживает медленные запросы, позволяет нам искать журналы во всех экземплярах и даже может отображать данные профилирования в виде графика пламени одним щелчком мыши. С помощью этого мощного инструмента мы можем лучше устранять неисправности кластера и обеспечивать стабильную работу базы данных.
Заключение
Прошло больше года с тех пор, как мы начали использовать TiDB. Его совместимость с MySQL , высокая согласованность и простые в использовании функции помогли нам в различных ситуациях и дали качественные результаты, которых мы ожидали.
Мы с нетерпением ждем будущих инноваций TiDB и продолжим тесно сотрудничать с проектом, чтобы ускорить рост нашего глобального бизнеса.
Сложные запросы в MySQL
| Сведения об имени хоста ACES | |||||
|---|---|---|---|---|---|
| Настольный | : | IP-адрес хоста | : | ||
| Имя пользователя | : | Пароль | : | ||
Дополнительная информация
| Сведения об имени хоста ACES | |||||
| Настольный | : | IP-адрес хоста | : | ||
| Имя пользователя | : | Пароль | : | ||
Дополнительная информация
| Сведения об имени хоста ACES | |||||
| Настольный | : | IP-адрес хоста | : | ||
| Имя пользователя | : | Пароль | : | ||
Дополнительная информация
| Сведения об имени хоста GRID | |||||
| Настольный | : | IP-адрес хоста | : | ||
| Имя пользователя | : | Пароль | : | ||
Дополнительная информация
| Сведения об имени хоста GRID | |||||
| Настольный | : | IP-адрес хоста | : | ||
| Имя пользователя | : | Пароль | : | ||
Дополнительная информация
| Сведения об имени хоста GRID | |||||
| Настольный | : | IP-адрес хоста | : | ||
| Имя пользователя | : | Пароль | : | ||
Дополнительная информация
Ваша лаборатория запланирована на
.Повторите попытку за 12 часов до начала лабораторной работы, чтобы узнать ваше имя пользователя и пароль.
был одобрен. Чтобы получить свое имя пользователя / пароль для доступа к лабораторной среде, вернитесь в 9:00 по местному времени в день, когда запланирована ваша лаборатория.
Ваша лаборатория запланирована на. Повторите попытку за 12 часов до начала лабораторной работы, чтобы узнать ваше имя пользователя и пароль.
Ваш запрос на расписание был отклонен. Обратитесь в службу поддержки Oracle для дальнейших действий.
Вы не выбрали дату для вашей лаборатории.
Запрошенная вами лаборатория обрабатывается.
Ваша лаборатория запросила его обработку. Пожалуйста, проверьте еще раз за 12 часов до того, как лаборатория начнет получать ваше имя пользователя и пароль.
Запрошенная вами лабораторная работа была отклонена, выберите другую неделю.
Запрошенная вами лаборатория была одобрена. Повторите попытку за 12 часов до начала лабораторной работы, чтобы узнать ваше имя пользователя и пароль.
Sharaal / sql-mysql: Сложные запросы могут быть написаны с помощью обычного SQL, в том числе значения должны быть связаны и иметь префикс с тегом sql.
Сложные запросы могут быть написаны с помощью обычного SQL, включая значения, которые должны быть связаны и иметь префикс sql .
Пакет очень вдохновлен slonik и статьей с критическим обзором knex:
https://medium.com/@gajus/stop-using-knex-js-and-earn-30-bf410349856c
Особая благодарность gajus.
Кроме того, это больше исследование, чем готовый к производству пакет, позволяющий глубоко понять концепции и получить больше опыта в эффективной работе с SQL.
const sql = требуется ('sql-mysql') Атом
- Установить
пакет language-babel - В настройках этого пакета найдите «Расширения грамматики шаблонных литералов с тегами JavaScript» и добавьте поддержку SQL через
sql: source.sql - Если не работает, отключите «Use Tree Sitter Parsers» в настройках ядра.
Извлечь и связать значения
const email = 'электронная почта'
const passwordhash = 'пароль хеша'
const result = ожидание соединения.запрос (sql`
ВЫБЕРИТЕ * ОТ пользователей, ГДЕ email = $ {email} И passwordhash = $ {passwordhash}
`)
// sql: SELECT * FROM users WHERE email =? И passwordhash =?
// значения: ['email', 'passwordhash'] Клавиши выхода для таблиц и столбцов
const table = 'пользователи'
const columns = ['id', 'email']
const результат = ожидание соединения. запрос (sql`
ВЫБЕРИТЕ $ {sql.keys (столбцы)} ИЗ $ {sql.key (таблица)}
`)
// sql: SELECT `id`,` email` FROM `users`
// значения: [] Если параметр является объектом (например,грамм. пользователь) будут использоваться ключи объекта:
const user = {id: 'id', email: 'email'}
const результат = ожидание соединения. запрос (sql`
ВЫБЕРИТЕ $ {sql.keys (user)} ОТ пользователей
`)
// sql: SELECT `id`,` email` FROM `users`
// значения: [] Поддерживаемый список значений
const values = ['email', 'passwordhash']
const результат = ожидание соединения. запрос (sql`
ВСТАВИТЬ пользователей (электронная почта, хэш паролей) ЗНАЧЕНИЯ ($ {sql.values (values)})
`)
// sql: INSERT INTO users (email, passwordhash) VALUES (?,?)
// значения: ['email', 'passwordhash'] Если параметр является объектом (например,грамм. пользователь) будут использованы значения объекта:
const user = {email: 'email', passwordhash: 'passwordhash'}
const результат = ожидание соединения. запрос (sql`
ВСТАВИТЬ пользователей (электронная почта, хэш паролей) ЗНАЧЕНИЯ ($ {sql.values (пользователь)})
`)
// sql: INSERT INTO users (email, passwordhash) VALUES (?,?)
// значения: ['email', 'passwordhash'] Поддержка нескольких списков значений
const valuesList = [
['emailA', 'passwordhashA'],
['emailB', 'passwordhashB']
]
const result = ожидание соединения.запрос (sql`
ВСТАВИТЬ пользователей (электронная почта, хэш паролей) ЗНАЧЕНИЯ $ {sql.values (valuesList)}
`)
// sql: INSERT INTO users (email, passwordhash) VALUES (?,?), (?,?)
// значения: ['emailA', 'passwordhashA', 'emailB', 'passwordhashB'] Если параметр представляет собой массив объектов (например, список пользователей), будут использоваться значения объектов:
постоянных пользователей = [
{электронная почта: 'emailA', passwordhash: 'passwordhashA'},
{электронная почта: 'emailB', passwordhash: 'passwordhashB'}
]
const result = ожидание соединения.запрос (sql`
ВСТАВИТЬ пользователей (электронная почта, хэш паролей) ЗНАЧЕНИЯ $ {sql.values (пользователи)}
`)
// sql: INSERT INTO users (email, passwordhash) VALUES (?,?), (?,?)
// значения: ['emailA', 'passwordhashA', 'emailB', 'passwordhashB'] Поддержка заданий для обновлений
const user = {email: 'email', passwordhash: 'passwordhash'}
const результат = ожидание соединения. запрос (sql`
ОБНОВЛЕНИЕ пользователей SET $ {sql.assignments (user)} WHERE id = 'id'
`)
// sql: ОБНОВЛЕНИЕ пользователей SET `email` =?,` passwordhash` =? ГДЕ id = 'id'
// значения: ['email', 'passwordhash'] Поддержка пар ключей и значений столбцов с использованием в качестве альтернативы назначений для обновлений
const user = {email: 'email', passwordhash: 'passwordhash'}
const result = ожидание соединения.запрос (sql`
ОБНОВЛЕНИЕ пользователей SET $ {sql.pairs (user, ',')} WHERE id = 'id'
`)
// sql: ОБНОВЛЕНИЕ пользователей SET `email` =?,` passwordhash` =? ГДЕ id = 'id'
// значения: ['email', 'passwordhash'] Условия поддержки для базовых сценариев использования
const user = {email: 'email', passwordhash: 'passwordhash'}
const результат = ожидание соединения. запрос (sql`
ВЫБРАТЬ * ОТ пользователей ГДЕ $ {sql.conditions (пользователь)}
`)
// sql: SELECT * FROM users WHERE `email` =? И `passwordhash` =?
// значения: ['email', 'passwordhash'] Поддержка пар ключей и значений столбцов с использованием в качестве альтернативы условий
const user = {email: 'email', passwordhash: 'passwordhash'}
const result = ожидание соединения.запрос (sql`
ВЫБРАТЬ * ОТ пользователей ГДЕ $ {sql.pairs (пользователь, 'И')}
`)
// sql: SELECT * FROM users WHERE `email` =? И `passwordhash` =?
// значения: ['email', 'passwordhash'] Поддержка вложенных запросов
const state = 'active'
const email = 'электронная почта'
const passwordhash = 'пароль хеша'
const результат = ожидание соединения. запрос (sql`
ВЫБРАТЬ * ОТ пользователей ГДЕ
состояние = $ {состояние}
И
id = ($ {sql`SELECT id FROM users WHERE email = $ {email} AND passwordhash = $ {passwordhash} `})
`)
// sql: SELECT * FROM users WHERE
// состояние =?
// И
// id = (ВЫБЕРИТЕ id ОТ пользователей, ГДЕ email =? И passwordhash =?)
// значения: ['active', 'email', 'passwordhash'] Поддержка ограничения, смещения и разбивки на страницы
const actualLimit = 10
const maxLimit = 50
const смещение = 20
const result = ожидание соединения.запрос (sql`
ВЫБРАТЬ * ИЗ пользователей $ {sql.limit (actualLimit, maxLimit)} $ {sql.offset (смещение)}
`)
// sql: SELECT * FROM users LIMIT 10 OFFSET 20
// значения: [] maxLimit является необязательным, но он должен быть установлен с не определяемым пользователем числом, чтобы гарантировать, что пользователь не может выбрать бесконечное количество строк.
Поскольку нумерация страниц является обычным вариантом использования, существует также ее сокращение:
const page = 5
const pageSize = 10
const результат = ожидание соединения. запрос (sql`
ВЫБРАТЬ * ИЗ пользователей $ {sql.разбивка на страницы (page, pageSize)}
`)
// sql: SELECT * FROM users LIMIT 10 OFFSET 50
// значения: [] Можно определить собственные методы фрагмента, добавив их в тег sql :
const bcrypt = require ('bcrypt')
sql.passwordhash = (пароль, saltRounds = 10) => ({
sql: '?',
значения: [bcrypt.hashSync (пароль, saltRounds)]
})
const user = {email: 'email'}
const пароль = 'пароль'
const результат = ожидание соединения. запрос (sql`
ВСТАВИТЬ пользователей (электронная почта, хэш паролей) ЗНАЧЕНИЯ ($ {sql.значения (пользователь)}, $ {sql.passwordhash (пароль)})
`)
// sql: INSERT INTO users (email, passwordhash) VALUES (?,?)
// значения: ['email', '$ 2b $ 10 $ ODInlkbnvW90q.EGZ.1Ale3YpOqqdn0QtAotg8q / JzM5HGky6Q2j6'] Также возможно повторно использовать существующие методы фрагментов для определения собственных:
const bcrypt = require ('bcrypt')
sql.passwordhash = (пароль, saltRounds = 10) => sql.values ([bcrypt.hashSync (пароль, saltRounds)])
const user = {email: 'email'}
const пароль = 'пароль'
const result = ожидание соединения.запрос (sql`
ВСТАВИТЬ пользователей (электронная почта, хэш паролей) ЗНАЧЕНИЯ ($ {sql.values (пользователь)}, $ {sql.passwordhash (пароль)})
`)
// sql: INSERT INTO users (email, passwordhash) VALUES (?,?)
// значения: ['email', '$ 2b $ 10 $ ODInlkbnvW90q.EGZ.1Ale3YpOqqdn0QtAotg8q / JzM5HGky6Q2j6'] Или определите объект постоянного результата, если значения не нужны:
sql.