Php utf8 to unicode: PHP: utf8_encode — Manual
Что Лучше Для Разработчиков Php
UTF-8 — это кодировка Unicode, способ представления (абстрактной) последовательности символов Unicode в виде (конкретной) последовательности байтов. Существуют и другие кодировки, такие как UTF-16 (у которых есть и варианты с большим и низким порядком). Оба UTF-8 и UTF-16 могут представлять любой символ в Unicode, поэтому вы можете поддерживать все языки, независимо от того, какой из них вы выберете.
UTF-8 полезен, если большая часть вашего текста находится на западных языках, поскольку он представляет символы ASCII всего за один байт, но для многих символов для «символов» иностранного алфавита, такого как китайский, для каждого символа требуется три байта. UTF-16, с другой стороны, использует ровно два байта для всех символов, с которыми вы, вероятно, столкнетесь (хотя некоторые очень эзотерические символы, за пределами Unicode «Basic Multilingual Plane», требуют четыре).
Я бы не рекомендовал использовать PHP для разработки международного программного обеспечения, потому что он действительно не поддерживает Unicode. Он имеет некоторые дополнительные функции для работы с кодировками Unicode (посмотрите на многобайтовая строка), но ядро PHP обрабатывает строки как байты, а не символы, поэтому стандартные строковые функции PHP не подходят для работы с символами, которые кодируются как более чем один байт. Например, если вы вызываете PHP
Он имеет некоторые дополнительные функции для работы с кодировками Unicode (посмотрите на многобайтовая строка), но ядро PHP обрабатывает строки как байты, а не символы, поэтому стандартные строковые функции PHP не подходят для работы с символами, которые кодируются как более чем один байт. Например, если вы вызываете PHP strlen() в строке, содержащей представление UTF-8 символа «大», оно вернет 3, потому что этот символ занимает три байта в UTF-8, хотя это только один символ. Использование функций разбиения строк, таких как substr(), является неустойчивым, потому что если вы разделите середину многобайтового символа, вы повредите строку.
Большинство других языков, используемых для веб-разработки, таких как Java, С# и Python, имеют встроенную поддержку Unicode, поэтому вы можете помещать произвольные символы Unicode в строку и не нужно беспокоиться о том, какая кодировка используется для представляют их в памяти, потому что с вашей точки зрения строка содержит символы, а не байты. Это гораздо более безопасный, менее подверженный ошибкам способ работы с текстом Unicode. По этой и другим причинам (PHP на самом деле не такой замечательный язык), я бы рекомендовал использовать что-то еще.
Это гораздо более безопасный, менее подверженный ошибкам способ работы с текстом Unicode. По этой и другим причинам (PHP на самом деле не такой замечательный язык), я бы рекомендовал использовать что-то еще.
(Я читал, что PHP 6 будет иметь надлежащую поддержку Unicode, но это пока недоступно.)
полезная информация и краткая ретроспектива
- Главная
- ->
- Материалы
- ->
- Кодировки: полезная информация и краткая ретроспектива
Reg.ru: домены и хостинг
Крупнейший регистратор и хостинг-провайдер в России.
Более 2 миллионов доменных имен на обслуживании.
Продвижение, почта для домена, решения для бизнеса.
Более 700 тыс. клиентов по всему миру уже сделали свой выбор.
Перейти на сайт->
Бесплатный Курс «Практика HTML5 и CSS3»
Освойте бесплатно пошаговый видеокурс
по основам адаптивной верстки
на HTML5 и CSS3 с полного нуля.
Начать->
Фреймворк Bootstrap: быстрая адаптивная вёрстка
Пошаговый видеокурс по основам адаптивной верстки в фреймворке Bootstrap.
Научитесь верстать просто, быстро и качественно, используя мощный и практичный инструмент.
Верстайте на заказ и получайте деньги.
Получить в подарок->
Бесплатный курс «Сайт на WordPress»
Хотите освоить CMS WordPress?
Получите уроки по дизайну и верстке сайта на WordPress.
Научитесь работать с темами и нарезать макет.
Бесплатный видеокурс по рисованию дизайна сайта, его верстке и установке на CMS WordPress!
Получить в подарок->
*Наведите курсор мыши для приостановки прокрутки.
Назад
Вперед
Кодировки: полезная информация и краткая ретроспектива
Данную статью я решил написать как небольшой обзор, касающийся вопроса кодировок.
Мы разберемся, что такое вообще кодировка и немного коснемся истории того, как они появились в принципе.
Мы поговорим о некоторых их особенностях а также рассмотрим моменты, позволяющие нам работать с кодировками более осознанно и избегать появления на сайте так называемых кракозябров, т.е. нечитаемых символов.
Итак, поехали…
Что такое кодировка?
Упрощенно говоря, кодировка — это таблица сопоставлений символов, которые мы можем видеть на экране, определенным числовым кодам.
Т.е. каждый символ, который мы вводим с клавиатуры, либо видим на экране монитора, закодирован определенной последовательностью битов (нулей и единиц). 8 бит, как вы, наверное, знаете, равны 1 байту информации, но об этом чуть позже.
Внешний вид самих символов определяется файлами шрифтов, которые установлены на вашем компьютере. Поэтому процесс вывода на экран текста можно описать как постоянное сопоставление последовательностей нулей и единиц каким-то конкретным символам, входящим в состав шрифта.
Прародителем всех современных кодировок можно считать ASCII.
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
Это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
Позже она была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в ASCII символы национальных языков, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8-R — это тоже расширенная кодировка ASCII, предназначенная для работы с символами русского языка.
Следующим шагом в развитии кодировок можно считать появление так называемых ANSI-кодировок.
По сути это были те же расширенные версии ASCII, однако из них были удалены различные псевдографические элементы и добавлены символы типографики, для которых ранее не хватало «свободных мест».
Примером такой ANSI-кодировки является всем известная Windows-1251. Помимо типографических символов, в эту кодировку также были включены буквы алфавитов языков, близких к русскому (украинский, белорусский, сербский, македонский и болгарский).
ANSI-кодировка — это собирательное название. В действительности, реальная кодировка при использовании ANSI будет определяться тем, что указано в реестре вашей операционной системы Windows. В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
В случае с русским языком это будет Windows-1251, однако, для других языков это будет другая разновидность ANSI.
Как вы понимаете, куча кодировок и отсутствие единого стандарта до добра не довели, что и стало причиной частых встреч с так называемыми кракозябрами — нечитаемым бессмысленным набором символов.
Причина их появления проста — это попытка отобразить символы, закодированные с помощью одной кодировочной таблицы, используя другую кодировочную таблицу.
В контексте веб-разработки, мы можем столкнуться с кракозябрами, когда, к примеру, русский текст по ошибке сохраняется не в той кодировке, которая используется на сервере.
Разумеется, это не единственный случай, когда мы можем получить нечитаемый текст — вариантов тут масса, особенно, если учесть, что есть еще база данных, в которой информация также хранится в определенной кодировке, есть сопоставление соединения с базой данных и т.д.
Возникновение всех этих проблем послужило стимулом для создания чего-то нового. Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Это должна была быть кодировка, которая могла бы кодировать любой язык в мире (ведь с помощью однобайтовых кодировок при всем желании нельзя описать все символы, скажем, китайского языка, где их явно больше, чем 256), любые дополнительные спецсимволы и типографику.
Одним словом, нужно было создать универсальную кодировку, которая решила бы проблему кракозябров раз и навсегда.
Юникод — универсальная кодировка текста (UTF-32, UTF-16 и UTF-8)
Сам стандарт был предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (Unicode Consortium, Unicode Inc.), и первым результатом его работы стало создание кодировки UTF-32.
Кстати, сама аббревиатура UTF расшифровывается как Unicode Transformation Format (Формат Преобразования Юникод).
В этой кодировке для кодирования одного символа предполагалось использовать аж 32 бита, т.е. 4 байта информации. Если сравнивать это число с однобайтовыми кодировками, то мы придем к простому выводу: для кодирования 1 символа в этой универсальной кодировке нужно в 4 раза больше битов, что «утяжеляет» файл в 4 раза.
Очевидно также, что количество символов, которое потенциально могло быть описано с помощью данной кодировки, превышает все разумные пределы и технически ограничено числом, равным 2 в 32 степени. Понятно, что это был явный перебор и расточительство с точки зрения веса файлов, поэтому данная кодировка не получила распространения.
На смену ей пришла новая разработка — UTF-16.
Как очевидно из названия, в этой кодировке один символ кодируют уже не 32 бита, а только 16 (т.е. 2 байта). Очевидно, это делает любой символ вдвое «легче», чем в UTF-32, однако и вдвое «тяжелее» любого символа, закодированного с помощью однобайтовой кодировки.
Количество символов, доступное для кодирования в UTF-16 равно, как минимум, 2 в 16 степени, т.е. 65536 символов. Вроде бы все неплохо, к тому же окончательная величина кодового пространства в UTF-16 была расширена до более, чем 1 миллиона символов.
Однако и данная кодировка до конца не удовлетворяла потребности разработчиков. Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
Скажем, если вы пишете, используя исключительно латинские символы, то после перехода с расширенной версии кодировки ASCII к UTF-16 вес каждого файла увеличивался вдвое.
В результате, была предпринята еще одна попытка создания чего-то универсального, и этим чем-то стала всем нам известная кодировка UTF-8.
UTF-8 — это многобайтовая кодировка с переменной длинной символа. Глядя на название, можно по аналогии с UTF-32 и UTF-16 подумать, что здесь для кодирования одного символа используется 8 бит, однако это не так. Точнее, не совсем так.
Дело в том, что UTF-8 обеспечивает наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Для кодирования одного символа в UTF-8 реально используется от 1 до 4 байт (гипотетически можно и до 6 байт).
В UTF-8 все латинские символы кодируются 8 битами, как и в кодировке ASCII. Иными словами, базовая часть кодировки ASCII (128 символов) перешла в UTF-8, что позволяет «тратить» на их представление всего 1 байт, сохраняя при этом универсальность кодировки, ради которой все и затевалось.
Итак, если первые 128 символов кодируются 1 байтом, то все остальные символы кодируются уже 2 байтами и более. В частности, каждый символ кириллицы кодируется именно 2 байтами.
Таким образом, мы получили универсальную кодировку, позволяющую охватить все возможные символы, которые требуется отобразить, не «утяжеляя» без необходимости файлы.
C BOM или без BOM?
Если вы работали с текстовыми редакторами (редакторами кода), например Notepad++, phpDesigner, rapid PHP и т.д., то, вероятно, обращали внимание на то, что при задании кодировки, в которой будет создана страница, можно выбрать, как правило, 3 варианта:
— ANSI
— UTF-8
— UTF-8 без BOM
Сразу скажу, что выбирать всегда стоит именно последний вариант — UTF-8 без BOM.
Итак, что же такое BOM и почему нам это не нужно?
BOM расшифровывается как Byte Order Mark.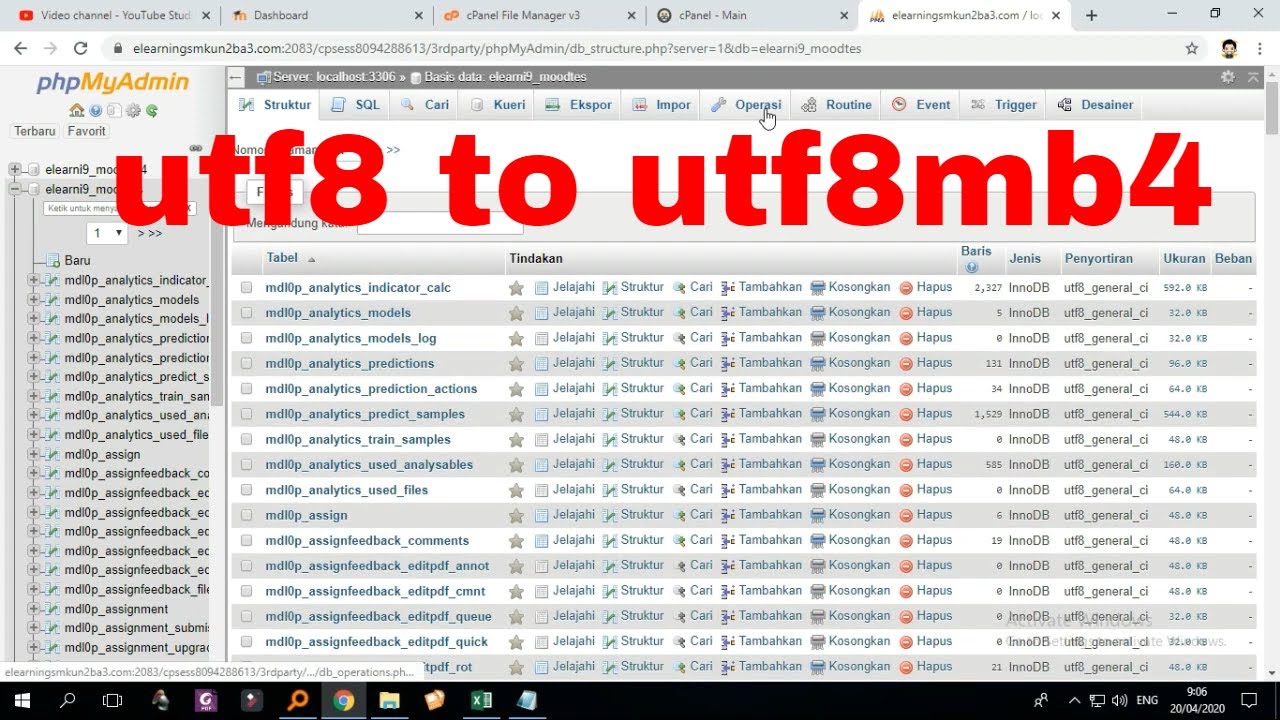 Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Это специальный Unicode-символ, используемый для индикации порядка байтов текстового файла. По спецификации его использование не является обязательным, однако если BOM используется, то он должен быть установлен в начале текстового файла.
Не будем вдаваться в детали работы BOM. Для нас главный вывод следующий: использование этого служебного символа вместе с UTF-8 мешает программам считывать кодировку нормальным образом, в результате чего возникают ошибки в работе скриптов.
Поэтому, при работе с UTF-8 используйте именно вариант «UTF-8 без BOM». Также лучше не используйте редакторы, в которых в принципе нельзя указать кодировку (скажем, Блокнот из стандартных программ в Windows).
Кодировка текущего файла, открытого в редакторе кода, как правило, указывается в нижней части окна.
Обратите внимание, что запись «ANSI as UTF-8» в редакторе Notepad++ означает то же самое, что и «UTF-8 без BOM». Это одно и то же.
Это одно и то же.
В программе phpDesigner нельзя сразу точно сказать, используется BOM, или нет. Для этого нужно кликнуть правой кнопкой мыши по надписи «UTF-8», после чего во всплывающем окне можно увидеть, используется ли BOM (опция Save with BOM).
В редакторе rapid PHP кодировка UTF-8 без BOM обозначается как «UTF-8*».
Как вы понимаете, в разных редакторах все выглядит немного по-разному, однако главную идею вы поняли.
После того, как документ сохранен в UTF-8 без BOM, нужно также убедиться, что верная кодировка указана в специальном метатэге в секции head вашего html-документа:
<meta charset = "utf-8" />
Соблюдение этих простых правил уже позволит вам избежать многих пробелем с кодировками.
На этом все, надеюсь, что данный небольшой экскурс и пояснения помогли вам лучше понять, что такое кодировки, какие они бывают и как работают.
Если вам интересна эта тема с более прикладной точки зрения, то рекомендую вам изучить мой видеоурок Полный UTF-8: чеклист для начинающих.
Дмитрий Науменко.
P.S. Присмотритесь к премиум-урокам по различным аспектам сайтостроения, а также к бесплатному курсу по созданию своей CMS-системы на PHP с нуля. Все это поможет вам быстрее и проще освоить различные технологии веб-разработки.
Понравился материал и хотите отблагодарить?
Просто поделитесь с друзьями и коллегами!
Смотрите также:
Наверх
Кракозябры на сайте — 6 проблем и их решения
Когда я только начинал изучать тему разработки сайтов, кракозябры были одной из моих постоянных проблем. Создал HTML-страницу — в браузере кракозябры, установил денвер и попробовал создать сайт на PHP — снова вместо букв кракозябры. Скачал иностранную тему, подключился к базе данных — та же проблема.
Скачал иностранную тему, подключился к базе данных — та же проблема.
На своих сайтах я обычно использую UTF-8 (это такая кодировка текста, она ещё называется юникод), соответственно она будет присутствовать во всех примерах в этой статье.
1. UTF-8 без BOM
Начнём с самой простой проблемы. Вы создали какой-то HTML-файл, открыли его в браузере и получили:
Кракозябры (проблема с кодировкой).
Проблема актуальна в основном для пользователей Windows, на маке я с таким ни разу не сталкивался.
Решение проблемы зависит в основном от того, каким редактором вы пользуетесь. Для пользователей Windows я рекомендую бесплатный офигительный Notepad++.
Значит, открываем файл в Notepad++ и переходим в Кодировки > Преобразовать в UTF-8 без BOM. Вопрос — почему без BOM? Потому что с BOM у вас будут постоянно вставляться пустые символы (на самом деле они не пустые, у них тоже есть своя функция, но нам она в данном случае не нужна) куда не надо, а для PHP это уже критично.
2. Мета тег charset
Если вы сделали то, что я описывал в предыдущем шаге и ваша проблема не разрешилась, тогда самое время испробовать второй метод устранения кракозябров.
Всё, что нам требуется, это вставить следующий код между тегами <head> сайта. Прежде всего проверьте, возможно этот метатег у вас уже присутствует. Если да, то посмотрите какое у него стоит значение параметра charset.
В темах WordPress обычно этот тег уже имеется по умолчанию и выглядит следующим образом:
<meta charset="<?php bloginfo('charset'); ?>" />3. .htaccess
Если русские буквы до сих пор отображаются кракозябрами, тогда открываем ваш .htaccess, который лежит в корне сайта и вставляем туда с новой строки это:
4. Заголовки сервера через header()
Ещё один способ определения кодировки. На этот раз через PHP. На WordPress никогда не приходилось им пользоваться.
header('Content-Type: text/html; charset=utf-8');Важно! Этот код должен вставляться до того, как будет что-либо выведено на странице сайта, иначе — ошибка.
5. Проблемы с последним символом при обрезке строки
На многих сайтах встречаются блоки с популярными записями, последними комментариями, отзывами и так далее. Обычно в таких обзорных блоках выводится часть записи/комментария/отзыва и кнопка «читать далее». Так вот, для того, чтобы вывести первые несколько предложений или первые несколько слов текста, используется функция PHP substr(). Конечно же в основном я имею ввиду англоязычные темы, которых так много в интернете. Даже если у этих тем есть локализация — то есть вроде бы она на русском — переведена админка, переведён практически весь сайт, но при этом мы встречаем такие вот косяки:
Как решить эту проблему?
Легко — всё что нам нужно, это найти функцию substr() в коде и поменять её на mb_substr().
Если после этого у вас полезут ошибки на сайт, то скорее всего multibyte-функции не поддерживаются вашим хостингом, первое, что вам следует сделать, это написать в супорт и спросить, нельзя ли их подключить на ваш аккаунт. Если нет, меняем хостинг, например на тот, которым пользуюсь я.
Если нет, меняем хостинг, например на тот, которым пользуюсь я.
6. MySQL
У меня не раз бывало такое, что я подключался к MySQL, вытаскивал какие-нибудь данные, и при их выводе на сайте, текст отображался кракозябрами.
Такое может произойти, если кодировка вашего сайта не совпадает с кодировкой базы данных, к которой вы подключаетесь. В WordPress обычно таких проблем не бывает.
Для того, чтобы исправить это, после подключения к БД, делаем следующее:
mysql_query("SET NAMES 'UTF8'");Если ни один из вышеперечисленных методов вам не помог, оставляйте комментарий и попробуем вместе разобраться.
Миша
Недавно я осознал, что моя миссия – способствовать распространению WordPress. Ведь WordPress – это лучший движок для разработки сайтов – как для тех, кто готов использовать заложенную структуру этой CMS, так и для тех, кто предпочитает headless решения.
Сам же я впервые познакомился с WordPress в 2009 году. Организатор WordCamp. Преподаватель в школах Epic Skills и LoftSchool.
Преподаватель в школах Epic Skills и LoftSchool.
Если вам нужна помощь с вашим сайтом или может даже разработка с нуля на WordPress / WooCommerce — пишите. Я и моя команда сделаем вам всё на лучшем уровне.
Включение PHP 8 в дорожную карту
В нашей электронной книге «Объяснение PHP 7» мы уже объяснили, почему преемник
PHP 5 — это PHP 7, а не PHP 6.
Поскольку попытка создания реализации PHP на основе Unicode не удалась, PHP 7
— как и PHP 5 — изначально не обрабатывает строки Unicode. Обычно используемая кодировка UTF-8 для
Например, это многобайтовая кодировка, в отличие от ASCII, где каждый символ представлен одним байтом.
Для символов ASCII вычислить длину строки тривиально: просто посчитайте байты.Расчет длины
строка, закодированная с использованием UTF-8, более сложна. UTF-8 — это кодировка переменной длины, и каждый символ (код
точка, чтобы быть точным) представлен от одного до четырех байтов. Для символов ASCII все работает плавно, потому что
UTF-8 — это расширенный набор ASCII. Проблемы начинаются с символов, отличных от ASCII:
Проблемы начинаются с символов, отличных от ASCII:
Этот простой сценарий, по крайней мере, при сохранении как UTF-8, даст очень интересный результат:
int (2)
При кодировании одного немецкого умляута как UTF-8, используются два байта.Поскольку PHP не знает о UTF-8 (или
Unicode в целом) встроенная функция strlen () просто считает байты, что приводит к неверному результату.
Обычно используются расширения PHP, например iconv или mbstring («multibyte
string «), которые предлагают функции обработки строк с поддержкой Unicode, например mb_strlen () (что, конечно,
требуется расширение mbstring ):
1 | var_dump (mb_strlen (‘ö’)); |
Эта функция считает кодовые точки, а не байты, и, таким образом, дает правильный результат:
внутр (1)
Вы можете сделать то же самое с расширением `iconv`, если оно у вас установлено:
1 | var_dump (iconv_strlen (‘ö’)); |
Неудивительно, что эта функция дает тот же результат:
внутр (1)
В обоих случаях мы немного обманываем, поскольку не указываем, что наша строка закодирована в UTF-8. Этот
Этот
работает, поскольку по соглашению кодировка UTF-8 является предполагаемой кодировкой по умолчанию практически везде в Интернете.
Теперь мы добавим магию в микс, и возникнут новые проблемы. Если вы используете mbstring
расширение, вы можете использовать php.ini директиву mbstring.func_overload для перегрузки
встроенные функции PHP с многобайтовыми функциями mb_ . В зависимости от установленного вами значения
mbstring.func_overload to, функция mail () , строковые функции и регулярные выражения
(к сожалению, не preg_ , а удаленные ereg_ ) могут быть перегружены.
Проблема с этой магией в том, что ваша программа не может знать, работают ли строковые функции PHP с или
без поддержки многобайтовых символов. И вы, конечно, не хотите оборачивать , если вокруг каждого
строковая функция. Так же, как и с волшебными цитатами, которые
как мы писали ранее, использование mbstring. — не лучшая идея. Вот почему это func_overload
func_overload
php.ini Директива устарела в PHP 7.2 и, вероятно, будет удалена в PHP 8.
Даже если это потенциально означает много работы: вы должны пройтись по вашему коду и явно указать, с каким
кодировки у вас работают. Не ждите до PHP 8, потому что это поставит вас в ситуацию, когда вы не сможете обновить
на PHP 8. Фактически вы хотите начать миграцию с PHP 8 прямо сейчас.
Эта статья — отрывок из нашей электронной книги PHP 7 Explained , которую мы недавно обновили для PHP 7.2.
Чтобы получить больше информации о PHP 7, скачайте свою копию сейчас, она включает в себя пожизненные бесплатные обновления.
Заинтересованы в нашем семинаре на целый день по PHP 7? Посетите https://php7day.de/ сегодня и забронируйте место!
Поддержка Unicode
в CentOS 5.2 с PHP и PCRE :: Крис Жан
Вчера я говорил о том, как максимально эффективно использовать регулярные выражения в PHP. Причина, по которой мне нужно было углубиться в синтаксис регулярных выражений в PHP, заключается в том, что мне нужно было написать несколько регулярных выражений, которые имеют дело с символами Unicode.
Причина, по которой мне нужно было углубиться в синтаксис регулярных выражений в PHP, заключается в том, что мне нужно было написать несколько регулярных выражений, которые имеют дело с символами Unicode.
После долгого чтения я поверил, что знаю все, что мне нужно.Я начал писать несколько строк регулярных выражений и тестировать код. К сожалению, каждый раз, когда я запускал тест со строкой, содержащей символы Unicode, совпадение не удавалось. Когда я удалил символы Unicode из строки и снова проверил, все заработало. Я был сбит с толку.
В поисках проблемы
У меня были символы тестирования регулярных выражений ( \ X , \ pL и т.д.) внутри класса символов, например [\ X-] , поскольку я создавал регулярное выражение для проверки доменов.\ X $ / и проверка регулярного выражения с одним символом Юникода. Удивительно, но наличие \ X за пределами квадратных скобок все изменило, поскольку теперь я получил следующее очень тревожное предупреждение:
Предупреждение PHP: preg_match (): Ошибка компиляции: поддержка \ P, \ p и \ X не была скомпилирована по смещению 2 в wp-content / plugins / dnsyogi / testunicode.php в строке 4
 php в строке 4
php в строке 4 Поскольку PHP использует механизм PCRE для выполнения регулярных выражений, я начал копаться в нем. Я обнаружил, что могу напрямую запросить PCRE.У меня получилось что-то очень похожее:
[chris @ home ~] $ pcregrep '/ \ X * / u' character.txt pcregrep: ошибка в регулярном выражении командной строки со смещением 2: поддержка \ P, \ p и \ X не была скомпилирована
Похоже, ошибка исходила от самого PCRE. Некоторое время я искал, думая, что могу просто установить новый пакет с помощью yum. Я надеялся найти что-то вроде pcre-utf8 , pcre-unicode , php-pcre-unicode или что-то, что упростит и ускорит добавление этой поддержки, поскольку я предпочитаю использовать инструменты управления пакетами, а не компилировать и установка из исходников.
К сожалению, такого пакета не существует. Эта поддержка должна быть опцией, с которой компилируется PCRE, а в моем репозитории CentOS есть только пакеты, которые не включают эту поддержку. После долгих поисков я обнаружил, что это не обязательно вина CentOS, поскольку этот пакет перенесен из RHEL (Red Hat Enterprise Linux).
После долгих поисков я обнаружил, что это не обязательно вина CentOS, поскольку этот пакет перенесен из RHEL (Red Hat Enterprise Linux).
Отличный способ проверить, не является ли это проблемой в вашей системе, — запустить следующее:
[chris @ home ~] $ pcretest -C PCRE версии 6.6 6 февраля 2006 г. Скомпилировано с Поддержка UTF-8 Нет поддержки свойств Unicode Символ новой строки - LF Размер внутренней ссылки = 2 POSIX malloc threshold = 10 Предел соответствия по умолчанию = 10000000 Предел глубины рекурсии по умолчанию = 10000000 Рекурсия совпадений использует стек
Это результат, который я получил. Обратите внимание на строки «Поддержка UTF-8» и «Нет поддержки свойств Unicode». Это означает, что PRCE был скомпилирован с параметром конфигурации --enable-utf8 , который позволяет PCRE распознавать строки в кодировке UTF-8 и работать с ними.Однако он не был скомпилирован с опцией конфигурации --enable-unicode-properties , которая работает вместе с опцией --enable-utf8 для добавления поддержки для \ p , \ P и \ X классы символов.
Похоже, это была недоработка, когда файл rpm был впервые собран. К счастью, есть способ исправить это.
Устранение проблемы
Поскольку я уверен, что многие из вас похожи на меня и предпочли бы не компилировать и устанавливать программное обеспечение вручную вне системы управления пакетами, решение состоит в том, чтобы обновить rpm, чтобы получить нужную опцию, и установить его.
Я никогда раньше этого не делал. К счастью, я нашел очень полезное руководство, в котором очень подробно описан этот процесс: Как исправить и пересобрать пакет RPM.
Я предоставил новый файл rpm, который я создал в конце этого поста. Если вас не интересует весь этот треп, вы можете пропустить его и взять файл. Однако, если вы хотите узнать, как решить эту проблему самостоятельно или у вас есть система, которую мой файл не поддерживает, прочтите, пожалуйста, чтобы узнать, как я перестроил rpm с новой опцией.
Восстановление об / мин
- Первое, что я сделал, это настроил мой файл
~ / .rpmmacrosи структуру папокsrc / rpm, как описано в разделе «Настройка» руководства, которому я следую. Я просто направлю вас туда, здесь повторять не нужно. - Мне нужно было получить исходный rpm для текущей версии PCRE на моей платформе. Я использую CentOS 5.2 с PCRE версии 6.6. Я нашел соответствующий исходный файл rpm (
pcre-6.6-2.el5_1.7.src.rpm) здесь. - Затем я установил исходный rpm-пакет, чтобы получить доступ к его файлам:
[chris @ home ~] $ rpm -ivh pcre-6.6-2.el5_1.7.src.rpm
Это поместит необходимые файлы в мои папки
~ / src / rpm / SOURCESи~ / src / rpm / SPECS. - Я открыл файл
~ / src / rpm / SPECS / pcre.specи нашел следующую строку:% configure --enable-utf8
Я изменил его, чтобы включить параметр свойств Unicode:
% configure --enable-utf8 --enable-unicode-properties
Затем я сохранил и закрыл файл.
- Это единственное изменение, которое мне нужно было внести. Итак, пришло время создать новый файл rpm. Я просто выполнил следующее, чтобы построить его:
[chris @ home ~] $ rpmbuild -ba ~ / src / rpm / SPECS / pcre.spec
Ближе к концу большого объема вывода я получил следующее:
Написал: ~ / src / rpm / SRPMS / pcre-6.6-2.7.src.rpm Написал: ~ / src / rpm / RPMS / x86_64 / pcre-6.6-2.7.x86_64.rpm Написал: ~ / src / rpm / RPMS / x86_64 / pcre-devel-6.6-2.7.x86_64.rpm Написал: ~ / src / rpm / RPMS / x86_64 / pcre-debuginfo-6.6-2.7.x86_64.об / мин
Это говорит мне, где именно я могу найти свои новые исходные файлы rpm и rpm.
Обновленный файл rpm для 64-разрядной версии CentOS 5.2
Если вы используете 64-разрядную версию CentOS 5.2, следующий файл должен работать для вас. Если у вас другая архитектура, дистрибутив Linux или вы столкнулись с какими-либо ошибками при попытке установить этот файл, вам следует следовать приведенным выше инструкциям, чтобы создать rpm-пакет, подходящий для вашего дистрибутива.
ПКР-6.6-2.7.x86_64.rpm — PCRE 6.6 для CentOS 5.2 64-бит
Спасибо Робину за 32-битную версию: pcre-6.6-2.7.i386.rpm
Установка новых об / мин
Теперь, когда у меня есть новый файл rpm, мне просто нужно его установить. Поскольку у меня уже установлен пакет pcre, мне нужно указать команде rpm обновлять, а не устанавливать. Следующая команда делает это за меня:
[root @ home ~] # rpm -Uvh ~ / src / rpm / RPMS / x86_64 / pcre-6.6-2.7.x86_64.rpm
Обратите внимание, что для выполнения этой команды мне нужно быть root.
Наконец, чтобы убедиться, что все работает, я снова запустил программу pcrecheck :
[chris @ home ~] $ pcretest -C PCRE, версия 6.6, 06 февраля 2006 г. Скомпилировано с Поддержка UTF-8 Поддержка свойств Unicode Символ новой строки - LF Размер внутренней ссылки = 2 POSIX malloc threshold = 10 Предел соответствия по умолчанию = 10000000 Предел глубины рекурсии по умолчанию = 10000000 Рекурсия совпадений использует стек
Выглядит хорошо.
Наконец, пора двигаться дальше по жизни.
Я вам помог?
Декодировать или кодировать текст Unicode
Поделиться
http: // www.online-toolz.com/tools/text-unicode-entities-convertor.php
Unicode — это стандарт компьютерной индустрии для согласованного кодирования,
представление и обработка текста, выраженного в большей части письменности мира
системы. Разработан совместно со стандартом универсального набора символов
и опубликован в виде книги как стандарт Unicode, последняя версия
Unicode состоит из более чем 109 000 символов, охватывающих 93
скрипты, набор кодовых диаграмм для наглядного ознакомления, методология кодирования
и набор стандартных кодировок символов, перечисление символов
свойства, такие как верхний и нижний регистр, набор справочных данных компьютера
файлы и ряд связанных элементов, таких как свойства персонажей, правила для
нормализация, декомпозиция, сопоставление, рендеринг и двунаправленное отображение
порядок (для правильного отображения текста, содержащего оба скрипта с письмом справа налево,
такие как арабский и иврит, а также письма с написанием слева направо).По состоянию на 2011 г.
последняя основная версия Unicode — Unicode 6.0. Консорциум Unicode,
некоммерческая организация, которая координирует разработку Unicode, имеет
амбициозная цель в конечном итоге заменить существующие схемы кодирования символов
с Unicode и его стандартными схемами формата преобразования Unicode (UTF), как
многие из существующих схем ограничены по размеру и охвату и
несовместим с многоязычной средой. Успех Unicode в унификации
наборы символов привели к его широкому распространению и преимущественному использованию в
интернационализация и локализация компьютерного программного обеспечения.В стандарте есть
были реализованы во многих новейших технологиях, включая XML, Java
язык программирования, Microsoft .NET Framework и современные операционные
системы. Юникод может быть реализован с помощью различных кодировок символов. Большинство
обычно используются кодировки UTF-8 (который использует один байт для любого ASCII
символы, которые имеют одинаковые кодовые значения как в кодировке UTF-8, так и в кодировке ASCII,
и до четырех байтов для других символов), ныне устаревший UCS-2 (который использует
два байта для каждого символа, но не может кодировать каждый символ в текущем
Стандарт Unicode) и UTF-16 (который расширяет UCS-2 для обработки кодовых точек.
выходит за рамки UCS-2).
Источник: Википедия
AKA:
Ключевые слова: текст, HTML, сущности, преобразователь, кодировка, символы,
экранирование, декодирование, unescape, unicode, utf8, ascii
Объявление кодировки символов в HTML
Целевая аудитория:
Авторы HTML (использующие редакторы или сценарии), разработчики сценариев (PHP, JSP и т. Д.), Менеджеры веб-проектов и все, кому нужно введение в то, как объявить кодировку символов в своем HTML-файле.
Как мне объявить кодировку моего файла HTML?
Вы всегда должны указывать кодировку, используемую для страницы HTML или XML. Если вы этого не сделаете, вы рискуете, что символы в вашем контенте будут неправильно интерпретированы. Это не только вопрос удобочитаемости человека, все чаще машинам также необходимо понимать ваши данные. Объявление кодировки символов также необходимо для обработки символов, отличных от ASCII, вводимых пользователем в формы, в URL-адресах, сгенерированных сценариями, и т. Д.В этой статье описывается, как это сделать для файла HTML.
Если вам нужно лучше понять, что такое символы и кодировки символов, см. Статью Кодировки символов для начинающих . Для получения информации об объявлении кодировок для таблиц стилей CSS см. Объявления кодировки символов CSS .
Всегда объявляйте кодировку вашего документа с помощью элемента meta с атрибутом charset или с помощью атрибутов http-Equ и content (называемых директивой pragma).Объявление должно полностью помещаться в первые 1024 байта в начале файла, поэтому лучше всего поместить его сразу после открывающего тега head .
...
.. .
Неважно, какой именно вы используете, но проще набрать первый. Также не имеет значения, набираете ли вы UTF-8 или utf-8 .
Всегда следует использовать кодировку символов UTF-8. (Помните, что это означает, что вам также нужно сохранить вашего контента как UTF-8.) Посмотрите, что вам следует учитывать, если вы действительно не можете использовать UTF-8.
Если у вас есть доступ к настройкам сервера, вам также следует подумать, имеет ли смысл использовать заголовок HTTP. Отметьте, однако, , что, поскольку заголовок HTTP имеет более высокий приоритет, чем мета-объявления в документе , авторы контента всегда должны учитывать, объявлена ли уже кодировка символов в заголовке HTTP. Если это так, должен быть установлен мета-элемент для объявления той же кодировки.
Вы можете обнаружить любые кодировки, отправленные заголовком HTTP, с помощью средства проверки интернационализации.
А как насчет отметки порядка байтов?
Если у вас есть метка порядка байтов (BOM) UTF-8 в начале вашего файла, то последние версии браузера, отличные от Internet Explorer 10 или 11, будут использовать это, чтобы определить, что кодировка вашей страницы - UTF-8.Он имеет более высокий приоритет, чем любое другое объявление, включая заголовок HTTP.
Вы можете пропустить объявление кодировки meta , если у вас есть спецификация, но мы рекомендуем вам сохранить его, поскольку это помогает людям, просматривающим исходный код, определить, какая кодировка страницы.
Подробнее о метке порядка байтов.
Следует ли указывать кодировку в заголовке HTTP?
Используйте объявления кодировки символов в заголовках HTTP, если это имеет смысл, и если вы можете, для любого типа содержимого, , но в сочетании с объявлением в документе.
Авторы контента должны всегда обеспечивать соответствие деклараций HTTP декларациям в документе.
Плюсы и минусы использования HTTP-заголовка
Одним из преимуществ использования HTTP-заголовка является то, что пользовательские агенты могут быстрее находить информацию о кодировке символов, когда она отправляется в HTTP-заголовке.
Информация заголовка HTTP имеет наивысший приоритет, когда она конфликтует с декларациями в документе, отличными от отметки порядка байтов.Средний
серверы, которые перекодируют данные (т. е. конвертируют в другую кодировку), могут воспользоваться этим, чтобы изменить кодировку документа перед его отправкой на небольшие устройства, которые распознают только несколько
кодировки. Неясно, широко ли используется эта перекодировка в настоящее время. Если это так, и он преобразует контент в кодировку, отличную от UTF-8, существует высокий риск потери данных, и это не является хорошей практикой.
С другой стороны, есть ряд потенциальных недостатков:
Авторам контента может быть сложно изменить информацию о кодировке для статических файлов на сервере, особенно при работе с интернет-провайдером.Авторам потребуются знания и доступ к настройкам сервера.
Настройки сервера могут по тем или иным причинам не синхронизироваться с документом. Это может произойти, например, если вы
полагаться на серверное значение по умолчанию, и это значение по умолчанию будет изменено. Это очень плохая ситуация, поскольку более высокий приоритет информации HTTP по сравнению с
объявление в документе может сделать документ нечитаемым.Существуют потенциальные проблемы как для статических, так и для динамических документов, если они не читаются с сервера; например, если они сохранены в
место, такое как компакт-диск или жесткий диск. В этих случаях информация о кодировке из заголовка HTTP недоступна.Точно так же, если кодировка символов объявлена только в заголовке HTTP, эта информация больше не доступна для файлов во время редактирования или когда они
обрабатываются такими вещами, как XSLT или скрипты, или когда они отправляются на перевод и т. д.
Так следует ли мне использовать этот метод?
Если файлы обслуживаются через HTTP с сервера, никогда не будет проблемой отправить информацию о кодировке символов документа в заголовке HTTP, если эта информация верна.
С другой стороны, из-за перечисленных выше недостатков мы также рекомендуем всегда объявлять информацию о кодировке внутри документа. Объявление в документе также помогает разработчикам, тестировщикам или руководителям отдела переводов, которые хотят визуально проверить кодировку документа.
(Некоторые люди утверждают, что объявлять кодировку в HTTP-заголовке бывает уместно, если вы собираетесь повторить ее в
содержание документа. В этом случае они предлагают, чтобы заголовок HTTP ничего не говорил о кодировке документа. Обратите внимание, что это обычно означает
принятие мер, чтобы отключить любые настройки сервера по умолчанию.)
Работа с полиглотами и форматами XML
XHTML5: Документ XHTML5 обслуживается как XML и имеет синтаксис XML.Анализаторы XML не распознают объявления кодировки в мета-элементах . Они распознают только декларацию XML. Вот пример:
Объявление XML требуется только в том случае, если страница не обслуживается как UTF-8 (или UTF-16), но может быть полезно включить его, чтобы разработчики, тестировщики или менеджеры по производству переводов могли визуально проверить кодировку документ, посмотрев на источник.
Разметка полиглота: Страница, использующая разметку полиглота, использует подмножество HTML с синтаксисом XML, которое может быть проанализировано с помощью синтаксического анализатора HTML или XML. Он описан в «Разметка полиглота: надежный профиль словаря HTML5 ».
Поскольку документ полиглота должен быть в кодировке UTF-8, вам не нужно и даже не следует использовать объявление XML. С другой стороны, если файл должен читаться как HTML, вам нужно будет объявить кодировку, используя мета-элемент , отметку порядка байтов или заголовок HTTP.
Поскольку объявление в мета-элементе будет распознаваться только парсером HTML, если вы используете подход с атрибутом content , его значение должно начинаться с text / html; .
Если вы используете мета-элемент с атрибутом charset , это не то, что вам нужно учитывать.
Информация в этом разделе относится к вещам, которые вам обычно не нужно знать, но которые включены сюда для полноты.
Работа с кодировками, отличными от UTF-8
Использование UTF-8 не только упрощает создание страниц, но и позволяет избежать неожиданных результатов при отправке формы и кодировках URL-адресов, которые по умолчанию используют кодировку символов документа. Если вы действительно не можете избежать использования кодировки символов, отличной от UTF-8, вам нужно будет выбрать из ограниченного набора имен кодировок, чтобы обеспечить максимальную совместимость и максимально долгий срок читабельности вашего контента.
Хотя обычно они называются кодировкой именами ,
в действительности они относятся к кодировкам, а не к наборам символов.Например, набор символов Юникода или «репертуар» может быть закодирован по трем различным схемам кодирования.
До недавнего времени реестр IANA был местом, где можно было найти имена для кодировок. Реестр IANA обычно включает несколько имен для одной и той же кодировки. В этом случае вы должны использовать имя, обозначенное как
"предпочтительный".
Новая спецификация Encoding теперь предоставляет список, который был протестирован на реальных реализациях браузеров. Вы можете найти список в таблице в разделе «Кодировки».Лучше всего использовать имена из левого столбца этой таблицы.
Примечание , однако, присутствие имени в любом из этих источников не обязательно означает, что использовать эту кодировку можно. Некоторые кодировки проблематичны. Если вы действительно не можете использовать UTF-8, вам следует внимательно изучить рекомендации из статьи Выбор и применение кодировки символов .
Не придумывайте свои собственные имена кодировок, которым предшествует x- . Это плохая идея, так как она
ограничивает совместимость.
Работа с устаревшими форматами HTML
HTML 4.01 не указывает использование атрибута charset с мета-элементом , но любой недавний крупный браузер все равно обнаружит и использует его, даже если страница объявлена как HTML4, а не HTML5. Этот раздел актуален только в том случае, если у вас есть другая причина, кроме обслуживания браузера для соответствия старому формату HTML. В нем описаны любые отличия от раздела ответов выше.
Для страниц, обслуживаемых как XML, см. Работа с многоязычными форматами и XML.
HTML4: Как уже упоминалось выше, для полного соответствия HTML 4.01 вам необходимо использовать директиву pragma, а не атрибут charset .
XHTML 1.x используется как text / html: Для полного соответствия HTML 4.01 также требуется директива pragma, а не атрибут charset . Вам не нужно использовать объявление XML, поскольку файл обслуживается как HTML.
XHTML 1.x используется как XML: Используйте объявление в кодировке объявления XML в первой строке страницы.Убедитесь, что перед ним ничего нет, включая пробелы (хотя отметка порядка байтов в порядке).
Атрибут кодировки
в ссылке
HTML5 не поддерживает использование атрибута charset в элементе a или link , поэтому вам следует избегать его использования. Он возник в спецификации HTML 4.01 для использования с элементами a , link и script и должен был указывать кодировку документа, на который вы ссылаетесь.
Он был предназначен для использования во встроенном элементе ссылки, например:
Плохой код. Не копируйте!
См. Наш список публикаций .
Идея заключалась в том, что браузер сможет применить правильную кодировку к документу, который он извлекает, если никакая другая кодировка не указана для документа.
Всегда были проблемы с использованием этого атрибута. Во-первых, он плохо поддерживается основными браузерами.Одна из причин не поддерживать этот атрибут заключается в том, что, если браузеры будут делать это без специальных дополнительных правил, это будет вектором XSS-атаки. Во-вторых, трудно гарантировать, что информация верна в любой момент времени. Автор указанного документа вполне может изменить кодировку документа без вашего ведома. Если автор все еще не указал кодировку своего документа, вы теперь попросите браузер применить неправильную кодировку. И, в-третьих, в этом нет необходимости, если люди следуют рекомендациям, изложенным в этой статье, и правильно размечают свои документы.Это гораздо лучший подход.
Этот способ указания кодировки документа имеет самый низкий приоритет (т. Е. Если кодировка объявлена каким-либо другим способом, это будет проигнорировано). Это означает, что вы также не можете использовать это для исправления неверных объявлений.
Работа с UTF-16
Согласно результатам выборки Google из нескольких миллиардов страниц, менее 0,01% страниц в Интернете закодированы в UTF-16. На UTF-8 приходится более 80% всех веб-страниц, если вы включаете его подмножество, ASCII, и более 60%, если вы этого не делаете.Настоятельно не рекомендуется использовать UTF-16 в качестве кодировки страницы.
Если по какой-то причине у вас нет выбора, вот несколько правил объявления кодировки. Они отличаются от кодировок для других кодировок.
Спецификация HTML5 запрещает использование мета-элемента для объявления UTF-16, поскольку значения должны быть совместимы с ASCII. Вместо этого вы должны убедиться, что у вас всегда есть метка порядка байтов в самом начале файла в кодировке UTF-16. По сути, это декларация в документе.
Кроме того, если ваша страница закодирована как UTF-16, не объявляйте ваш файл как «UTF-16BE» или «UTF-16LE», используйте только «UTF-16». Отметка порядка байтов в начале вашего файла укажет, является ли схема кодирования прямым или обратным порядком байтов. (Это связано с тем, что контент, явно закодированный, например, как UTF-16BE, не должен использовать метку порядка байтов; но HTML5 требует метки порядка байтов для страниц в кодировке UTF-16.)
Поддержка маршрутизации
Unicode (блог Symfony)
В Symfony 3.2, компонент маршрутизации был улучшен, чтобы добавить поддержку
символов UTF-8 в путях маршрута и требованиях . Благодаря новому
utf8 route option, вы можете сопоставить Symfony и сгенерировать маршруты с помощью
Символы UTF-8:
1 2 3 4 5 6 7 8 9 10 11 12 13 | используйте Sensio \ Bundle \ FrameworkExtraBundle \ Configuration \ Route;
/ **
* @Маршрут(
* "/ категория / {имя}",
* "requirements" = {"name": ". +"},
* "options" = {"utf8": true}
*)
* /
публичная функция categoryAction ($ name)
{
//...
}
|
На этом пути опция utf8 , установленная на true , заставляет Symfony рассматривать
. Требование для соответствия любым символам UTF-8 вместо одного байта
символ, поэтому будут соответствовать следующие URL-адреса: / category / 日本語 ,
/ category / ارسی , / category / 한국어 и т. Д. Если вам интересно, это
опция также позволяет включать и сопоставлять смайлики в URL-адресах.
В Symfony 3.2 нет необходимости явно устанавливать этот utf8 .Как только
Symfony находит символ UTF-8 в пути или требованиях маршрута, он превратится
автоматическая поддержка UTF-8:
1 2 3 4 5 6 7 8 9 10 11 12 13 | / **
* 'utf8' автоматически устанавливается в 'true' из-за
* содержание требований «имя»:
*
* @Маршрут(
* "/ категория / {имя}",
* "requirements" = {"name": "日本語 | ارسی"}
*)
* /
публичная функция categoryAction ($ name)
{
// ...
}
|
Однако, чтобы еще раз прояснить ситуацию, это поведение устарело и
приведет к LogicException в Symfony 4.0. Поэтому не забудьте
явно определите опцию utf8 для любого маршрута, который может в ней нуждаться.
Помимо символов UTF-8, компонент «Маршрутизация» также поддерживает все
Свойства Unicode PCRE, которые представляют собой escape-последовательности, соответствующие общему
типы персонажей. Например, \ p {Lu} соответствует любому символу верхнего регистра в
любой язык, \ p {греческий} соответствует любому греческому символу, \ P {Han} соответствует
любой символ, не включенный в китайское письмо хань и т. д.
Unicode-string-manager | Безжирный фреймворк для PHP
править
Класс UTF - это служебный класс, упрощающий обработку строк Unicode.
Пространство имен: \
Расположение файла: lib / utf.php
Создание экземпляра
Возврат экземпляра класса
$ utf = \ UTF :: instance (); Класс UTF использует фабричную оболочку Prefab, поэтому вы можете получить один и тот же экземпляр этого класса в любой точке вашего кода.
Методы
Подобно стандартным строковым методам PHP, все методы класса UTF возвращают смещения, отсчитываемые от нуля.
стрлен
Получить длину строки
int strlen (строка $ str) Эта функция возвращает длину заданной строки
Пример:
$ utf-> strlen ('나는 유리 를 먹을 수 있어요. 그래도'); полоски
Найти позицию первого вхождения строки без учета регистра
int | FALSE stripos (строка $ stack, строка $ Need [, int $ ofs = 0]) Эта функция возвращает позицию первого вхождения строки $ Need в строке $ stack .Поиск без учета регистра. Возвращает ЛОЖЬ , если $ игла не найдена.
Если указано $ ofs , поиск начнется с этого количества символов, отсчитываемых от начала строки. Смещение $ из не может быть отрицательным.
Примеры:
$ utf-> stripos ('Les Naïfs ægithales hâtifs', 'наифы');
$ utf-> stripos ('Les Naïfs ægithales hâtifs', 'NAFS');
$ utf-> stripos ('Les Naïfs ægithales hâtifs', 'NAÏFS', 10); стр.
Найти позицию первого вхождения строки с учетом регистра
int | FALSE strpos (строка $ stack, string $ Need [, int $ ofs = 0 [, bool $ case = FALSE]]) Эта функция возвращает позицию первого вхождения строки $ Need в строке $ stack .Возвращает ЛОЖЬ , если $ игла не найдена.
Если указано $ ofs , поиск начнется с этого количества символов, отсчитываемых от начала строки. Смещение $ из не может быть отрицательным.
Если для $ case задано значение TRUE , поиск выполняется без учета регистра и функция ведет себя как stripos () .
Примеры:
$ utf-> strpos ('Góa ē-tàng Chia̍h Po-lê', 'Góa');
$ utf-> strpos ('Góa ē-tàng Chia̍h Po-lê', 'Góa', 4);
$ utf-> strpos ('Góa ē-tàng Chia̍h Po-lê', 'chia̍h', 0);
$ utf-> strpos ('Góa ē-tàng Chia̍h Po-lê', 'chia̍h', 0, ИСТИНА); стр.
Возвращает часть строки стога сена от первого появления иголки до конца стога сена, без учета регистра
строка | FALSE stristr (строка $ stack, строка $ Need [, bool $ before = FALSE]) Эта функция возвращает часть строки $ stack , начиная с первого вхождения $ иглы и заканчивая его концом $ stack .Без учета регистра. Возвращает ЛОЖЬ , если $ игла не найдена.
Если для $ перед установлено значение ИСТИНА , stristr () возвращает часть стека $ до первого появления $ иглы (исключая иглу).
Примеры:
$ utf-> stristr ('Mayia Góa Chàyia̍h Lêh-Pok', 'CHÀYIA̍H');
$ utf-> stristr ('Mayia Góa Chàyia̍h Lêh-Pok', 'GóA', ИСТИНА); улица
Возвращает часть строки стога сена от первого появления иголки до конца стога сена
строка | FALSE strstr (строка $ stack, string $ Need [, bool $ before = FALSE [, bool $ case = FALSE]]) Эта функция возвращает часть строки $ stack , начиная с первого вхождения $ иглы и заканчивая его концом $ stack .Возвращает ЛОЖЬ , если $ игла не найдена.
Если для $ перед установлено значение ИСТИНА , strstr () возвращает часть стека $ до первого появления $ иглы (исключая иглу).
Если для $ case задано значение TRUE , поиск выполняется без учета регистра и функция ведет себя как stristr () .
Пример:
$ email = 'Mïchañ [адрес электронной почты защищен]';
$ domain = $ utf-> strstr ($ email, '@');
$ user = $ utf-> strstr ($ email, '@', ИСТИНА); substr
Возвращает часть строки
строка | FALSE substr (строка $ str, int $ start [, int $ length = 0]) Эта функция возвращает часть строки $ str , заданную параметрами $ start и $ length .Если $ length опущено, будет возвращена подстрока, начинающаяся с $ start до конца строки.
Если значение $ start отрицательное, возвращаемая строка будет содержать $ start в начальном символе с конца строки $ str .
Если строка $ str меньше или равна $ start длиной символов, будет возвращено FALSE .
Примеры:
$ utf-> substr ('El pingüino Wenceslao hizo kilómetros', 3,8);
$ utf-> substr ('El pingüino Wenceslao hizo kilómetros', - 10,4); substr_count
Подсчитать количество вхождений подстроки
int substr_count (строка $ стек, строка $ игла) Эта функция подсчитывает и возвращает, сколько раз подстрока $ Need встречается в строке $ stack .Обратите внимание, что игла $ чувствительна к регистру.
Примеры:
$ utf-> substr_count ('Это пример как есть', 'is');
$ utf-> substr_count (implode (array ('This', 'example', 'as', 'it')), 'is');
$ arr = array ('Это', 'пример', 'как', 'оно');
$ utf-> substr_count (implode ($ arr, 'есть'), 'есть'); литр
Удалить пробелы в начале строки
строка ltrim (строка $ str) Эта функция удаляет пробелы и другие символы (согласно регулярному выражению / [\ pZ \ pC] + / u ) из начала данной строки.
Примеры:
$ utf-> ltrim ("\ xe2 \ x80 \ x83 \ x20 WhatAMana! \ Xc2 \ xa0 \ xe1 \ x9a \ x80");
$ utf-> ltrim ('невидимые начальные пробелы ...'); rtrim
Удаление пробелов с конца строки
строка rtrim (строка $ str) Эта функция удаляет пробелы и другие символы (согласно регулярному выражению / [\ pZ \ pC] + $ / u ) из конца данной строки.
Примеры:
$ utf-> rtrim ("\ xe2 \ x80 \ x83 \ x20 WhatAMana! \ Xc2 \ xa0 \ xe1 \ x9a \ x80"); $ utf-> rtrim ('невидимые конечные пробелы.[\ pZ \ pC] + | [\ pZ \ pC] + $ / u) от начала и до конца данной строки.Примеры:
$ utf-> trim ("\ xe2 \ x80 \ x83 \ x20 WhatAMana! \ Xc2 \ xa0 \ xe1 \ x9a \ x80"); $ utf-> trim ('невидимые пробелы ...');бом
Вернуть метку порядка байтов UTF-8 (BOM)
струнная бомба ()Возвращает метку порядка байтов (BOM) Unicode-символ, используемый для обозначения порядка байтов текстового файла или потока. Символ спецификации может также указывать, в каком из нескольких представлений Unicode закодирован текст.Использование спецификации не является обязательным и, если оно используется, должно появиться в начале текстового потока.
Пример:
$ bom = \ UTF :: instance () -> bom (); echo '0x'.dechex (ord ($ bom [0])). dechex (ord ($ bom [1])). dechex (ord ($ bom [2])); $ f3-> write ($ filename, $ bom. $ f3-> read ($ filename));перевести
Преобразование кодовых точек в символы Юникода
перевод строки (строка $ str)Преобразует и возвращает кодовые точки (например,грамм. U + 0E8D U + 053D) на эквивалентные символы Unicode (например, ຍ Խ)
смайликов
Преобразование токенов эмодзи в символы, поддерживаемые шрифтом Unicode
строка emojify (строка $ str)Преобразует и возвращает символы, поддерживаемые шрифтом Unicode, эквивалентные токенам эмодзи.
токенов эмодзи, переведенных по умолчанию:
':(' => '\ u2639', ':)' => '\ u263a', '<3' => '\ u2665', ': D' => '\ u1f603', 'XD' => '\ u1f606', ';)' => '\ u1f609', ': P' => '\ u1f60b', ':,' => '\ u1f60f', ': /' => '\ u1f623', '8O' => '\ u1f632',Пример:
echo \ UTF :: instance () -> emojify ('Спасибо :) I <3');Имейте в виду, что вам нужен шрифт, поддерживающий эти символы, чтобы даже иметь надежду правильно увидеть их на страницах вашего браузера.
Вы можете указать свои собственные дополнительные токены эмодзи с помощью системной переменной EMOJI. При наличии эти токены эмодзи добавляются к базовому набору, указанному выше, и будут использоваться при переводе строки в символы, поддерживаемые шрифтом Unicode.
Примеры:
$ f3-> set ('EMOJI', array ('(c)' => '& # 169;', '?' => '& # 191')); echo \ UTF :: instance () -> emojify ('Вам нравится (c) opyrights ??'); $ f3-> set ('EMOJI', array ('@ om' => '\ U0F00', '& oooooom' => '\ U0F02', '% om' => '\ U0F00')); echo \ UTF :: instance () -> emojify ('@om приветствует & oooooom из Тибета% om');Как видите, определять жетоны эмодзи нужно только вам.Вы даже можете представить себе автоматизацию вызова функции
emojifyдля переменных, которые вы используете в своих шаблонах.В MySQL никогда не используйте «utf8». Используйте «utf8mb4». | автор: Adam Hooper
Сегодняшняя ошибка: я попытался сохранить строку UTF-8 в базе данных MariaDB с кодировкой «utf8», и Rails выдала странную ошибку:
Неверное строковое значение: '\ xF0 \ x9F \ x98 \ x83 < … 'Для столбца' summary 'в строке 1Это клиент UTF-8 и сервер UTF-8 в базе данных UTF-8 с параметрами сортировки UTF-8.Строка «😃 <…» допустима в кодировке UTF-8.
Но вот загвоздка: MySQL « utf8 » - это не UTF-8 .
Кодировка «utf8» поддерживает только три байта на символ. Настоящая кодировка UTF-8, которую используют все, включая вас, требует до четырех байтов на символ.
Разработчики MySQL никогда не исправляли эту ошибку. В 2010 году они выпустили обходной путь: новый набор символов под названием « utf8mb4 ».
Конечно, они никогда этого не рекламировали (вероятно, потому, что ошибка настолько неприятна).Теперь руководства в Интернете предлагают пользователям использовать «utf8». Все эти гиды ошибаются.
Вкратце:
- «utf8mb4» MySQL означает «UTF-8».
- MySQL «utf8» означает «проприетарная кодировка символов». Эта кодировка не может кодировать многие символы Юникода.
Здесь я сделаю широкое заявление: всем пользователям MySQL и MariaDB, которые в настоящее время используют «utf8», следует , на самом деле, использовать «utf8mb4». Никто никогда не должен использовать «utf8».
Что такое кодировка? Что такое UTF-8?
Joel on Software написал мое любимое введение.Я сокращу это.
Компьютеры хранят текст как единицы и нули. Первая буква в этом абзаце была сохранена как «01000011», а ваш компьютер нарисовал букву «C». Ваш компьютер выбрал «C» в два этапа:
- Ваш компьютер прочитал «01000011» и определил, что это число 67. Это потому, что 67 было в кодировке как «01000011».
- Ваш компьютер нашел символ номер 67 в наборе символов Unicode и обнаружил, что 67 означает «C».
То же самое произошло на моем конце, когда я набрал эту «C»:
- Мой компьютер сопоставил «C» с 67 в наборе символов Unicode.
- Мой компьютер закодировал 67, отправив «01000011» на этот веб-сервер.
Наборы символов - решенная проблема. Практически каждая программа в Интернете использует набор символов Юникода, потому что нет никакого стимула использовать другой набор символов.
Но кодировка - это скорее вопрос суждения. Unicode имеет слоты для более миллиона символов. («C» и «💩» - два таких символа.) В простейшей кодировке UTF-32 каждый символ занимает 32 бита. Это просто, потому что компьютеры целую вечность обрабатывают 32-битные группы как числа, и у них это действительно хорошо получается.Но это бесполезно: это пустая трата места.
UTF-8 экономит место. В UTF-8 общие символы, такие как «C», занимают 8 бит, а редкие символы, такие как «💩», занимают 32 бита. Остальные символы занимают 16 или 24 бита. Подобное сообщение в блоге занимает примерно в четыре раза меньше места в UTF-8, чем в UTF-32. Так что он загружается в четыре раза быстрее.
Вы можете этого не осознавать, но наши компьютеры негласно согласились на UTF-8. Если они этого не сделали, то, когда я наберу «💩», вы увидите множество случайных данных.
Набор символов MySQL «utf8» не согласуется с другими программами.Когда они говорят «💩», это значит, что они упираются.
Немного истории MySQL
Почему разработчики MySQL сделали «utf8» недействительным? Мы можем догадаться, посмотрев на журналы фиксации.
MySQL поддерживает UTF-8, начиная с версии 4.1. Это было в 2003 году - до сегодняшнего стандарта UTF-8, RFC 3629.
Предыдущий стандарт UTF-8, RFC 2279, поддерживал до шести байтов на символ. Разработчики MySQL закодировали RFC 2279 в первой предварительной версии MySQL 4.1 28 марта 2002 года.
Затем в сентябре произошла загадочная однобайтовая настройка исходного кода MySQL: «UTF8 теперь работает с тремя только байтовые последовательности.”
Кто просил об этом изменении? Почему? Я не могу сказать. В списке рассылки в сентябре 2003 г. нет ничего, что объясняло бы это изменение. (RFC 2279 был объявлен устаревшим в ноябре 2003 года, чтобы уступить место текущему стандарту UTF-8, RFC 3629.)
Но я могу догадаться, почему MySQL нарушил стандарт.
Еще в 2002 году MySQL дал пользователям прирост скорости, если пользователи могли гарантировать, что каждая строка в таблице имеет одинаковое количество байтов. Для этого пользователи должны объявить текстовые столбцы как «CHAR».Значение каждой записи в столбце «CHAR» имеет одинаковое количество символов. Если вы введете слишком мало символов, MySQL добавит пробелы в конец; если вы введете слишком много символов, MySQL обрежет последние.
Когда разработчики MySQL впервые попробовали UTF-8 с шестью байтами на символ, они, вероятно, отказались: столбец CHAR (1) занимал шесть байтов; столбец CHAR (2) займет 12 байтов; и так далее.
Давайте проясним: первоначальное поведение, которое так и не было опубликовано, было правильным .Он был хорошо задокументирован и широко принят, и любой, кто понимал UTF-8, согласился бы, что это правильно.
Но очевидно, что разработчик MySQL (или пользователь, или бизнесмен) был обеспокоен тем, что один или два пользователя сделают две вещи:
- Выберите столбцы CHAR. (Формат CHAR в настоящее время является пережитком. Тогда MySQL был быстрее с столбцами CHAR. С 2005 года это не так.)
- Выберите кодирование этих столбцов CHAR как «utf8».
Я предполагаю, что разработчики MySQL взломали свою кодировку «utf8», чтобы помочь этим пользователям: пользователям, которые 1) пытались оптимизировать пространство и скорость; и 2) пренебрегли оптимизацией по скорости и пространству.
Никто не выиграл. Пользователи, которым нужна была скорость и пространство, все еще ошибались, использовали столбцы CHAR «utf8», потому что эти столбцы все еще были больше и медленнее, чем они должны были быть. И разработчики, которые хотели правильности, ошиблись, использовав «utf8», потому что он не может хранить «💩».
Как только MySQL опубликует этот недопустимый набор символов, он никогда не сможет его исправить: это заставит каждого пользователя перестраивать каждую базу данных. Наконец, в 2010 году MySQL выпустил поддержку UTF-8 под другим именем: «utf8mb4».
Почему это так неприятно
Очевидно, на этой неделе я был разочарован. Мою ошибку было трудно найти, потому что меня обмануло имя «utf8». И я не единственный - почти каждая статья, которую я нашел в Интернете, рекламировала как «utf8», так и UTF-8.
Имя «utf8» всегда было ошибкой. Это проприетарный набор символов. Это создало новые проблемы, но не решило проблему, которую намеревалось решить.