Index rebuild ms sql: Reorganize and Rebuild Indexes in the Database
Реорганизовать индекс против перестроить индекс в плане обслуживания Sql Server
Я исследовал в интернете и нашел несколько хороших статей. В то же время я написал функцию и скрипт ниже, которые реорганизуют, воссоздают или перестраивают все индексы в базе данных.
Сначала вам, возможно, придется прочитать эту статью , чтобы понять, почему мы не просто воссоздаем все индексы.
Во-вторых, нам нужна функция для создания скрипта создания индекса. Так что эта статья может помочь. Также я делюсь рабочей функцией ниже.
Последний шаг-сделать while loop, чтобы найти и упорядочить все индексы в базе данных. Это видео -пример решетки, чтобы сделать это.
Функция:
create function GetIndexCreateScript(
@index_name nvarchar(100)
)
returns nvarchar(max)
as
begin
declare @Return varchar(max)
SELECT @Return = ' CREATE ' +
CASE WHEN I.is_unique = 1 THEN ' UNIQUE ' ELSE '' END +
I.type_desc COLLATE DATABASE_DEFAULT +' INDEX ' +
I. name + ' ON ' +
Schema_name(T.Schema_id)+'.'+T.name + ' ( ' +
KeyColumns + ' ) ' +
ISNULL(' INCLUDE ('+IncludedColumns+' ) ','') +
ISNULL(' WHERE '+I.Filter_definition,'') + ' WITH ( ' +
CASE WHEN I.is_padded = 1 THEN ' PAD_INDEX = ON ' ELSE ' PAD_INDEX = OFF ' END + ',' +
'FILLFACTOR = '+CONVERT(CHAR(5),CASE WHEN I.Fill_factor = 0 THEN 100 ELSE I.Fill_factor END) + ',' +
-- default value
'SORT_IN_TEMPDB = OFF ' + ',' +
CASE WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON ' ELSE ' IGNORE_DUP_KEY = OFF ' END + ',' +
CASE WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF ' ELSE ' STATISTICS_NORECOMPUTE = ON ' END + ',' +
-- default value
' DROP_EXISTING = ON ' + ',' +
-- default value
' ONLINE = OFF ' + ',' +
CASE WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON ' ELSE ' ALLOW_ROW_LOCKS = OFF ' END + ',' +
CASE WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON ' ELSE ' ALLOW_PAGE_LOCKS = OFF ' END + ' ) ON [' +
DS. name + ' ] '
FROM sys.indexes I
JOIN sys.tables T ON T.Object_id = I.Object_id
JOIN sys.sysindexes SI ON I.Object_id = SI.id AND I.index_id = SI.indid
JOIN (SELECT * FROM (
SELECT IC2.object_id , IC2.index_id ,
STUFF((SELECT ' , ' + C.name + CASE WHEN MAX(CONVERT(INT,IC1.is_descending_key)) = 1 THEN ' DESC ' ELSE ' ASC ' END
FROM sys.index_columns IC1
JOIN Sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column = 0
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY IC1.object_id,C.name,index_id
ORDER BY MAX(IC1.key_ordinal)
FOR XML PATH('')), 1, 2, '') KeyColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY IC2.object_id ,IC2.index_id) tmp3 )tmp4
ON I.object_id = tmp4.object_id AND I.Index_id = tmp4.index_id
JOIN sys. stats ST ON ST.object_id = I.object_id AND ST.stats_id = I.index_id
JOIN sys.data_spaces DS ON I.data_space_id=DS.data_space_id
JOIN sys.filegroups FG ON I.data_space_id=FG.data_space_id
LEFT JOIN (SELECT * FROM (
SELECT IC2.object_id , IC2.index_id ,
STUFF((SELECT ' , ' + C.name
FROM sys.index_columns IC1
JOIN Sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column = 1
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY IC1.object_id,C.name,index_id
FOR XML PATH('')), 1, 2, '') IncludedColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY IC2.object_id ,IC2.index_id) tmp1
WHERE IncludedColumns IS NOT NULL ) tmp2
ON tmp2.object_id = I.object_id AND tmp2.index_id = I.index_id
WHERE I.is_primary_key = 0 AND I. is_unique_constraint = 0
AND I.[name] = @index_name
return @Return
end
name + ' ON ' +
Schema_name(T.Schema_id)+'.'+T.name + ' ( ' +
KeyColumns + ' ) ' +
ISNULL(' INCLUDE ('+IncludedColumns+' ) ','') +
ISNULL(' WHERE '+I.Filter_definition,'') + ' WITH ( ' +
CASE WHEN I.is_padded = 1 THEN ' PAD_INDEX = ON ' ELSE ' PAD_INDEX = OFF ' END + ',' +
'FILLFACTOR = '+CONVERT(CHAR(5),CASE WHEN I.Fill_factor = 0 THEN 100 ELSE I.Fill_factor END) + ',' +
-- default value
'SORT_IN_TEMPDB = OFF ' + ',' +
CASE WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON ' ELSE ' IGNORE_DUP_KEY = OFF ' END + ',' +
CASE WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF ' ELSE ' STATISTICS_NORECOMPUTE = ON ' END + ',' +
-- default value
' DROP_EXISTING = ON ' + ',' +
-- default value
' ONLINE = OFF ' + ',' +
CASE WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON ' ELSE ' ALLOW_ROW_LOCKS = OFF ' END + ',' +
CASE WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON ' ELSE ' ALLOW_PAGE_LOCKS = OFF ' END + ' ) ON [' +
DS. name + ' ] '
FROM sys.indexes I
JOIN sys.tables T ON T.Object_id = I.Object_id
JOIN sys.sysindexes SI ON I.Object_id = SI.id AND I.index_id = SI.indid
JOIN (SELECT * FROM (
SELECT IC2.object_id , IC2.index_id ,
STUFF((SELECT ' , ' + C.name + CASE WHEN MAX(CONVERT(INT,IC1.is_descending_key)) = 1 THEN ' DESC ' ELSE ' ASC ' END
FROM sys.index_columns IC1
JOIN Sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column = 0
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY IC1.object_id,C.name,index_id
ORDER BY MAX(IC1.key_ordinal)
FOR XML PATH('')), 1, 2, '') KeyColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY IC2.object_id ,IC2.index_id) tmp3 )tmp4
ON I.object_id = tmp4.object_id AND I.Index_id = tmp4.index_id
JOIN sys. stats ST ON ST.object_id = I.object_id AND ST.stats_id = I.index_id
JOIN sys.data_spaces DS ON I.data_space_id=DS.data_space_id
JOIN sys.filegroups FG ON I.data_space_id=FG.data_space_id
LEFT JOIN (SELECT * FROM (
SELECT IC2.object_id , IC2.index_id ,
STUFF((SELECT ' , ' + C.name
FROM sys.index_columns IC1
JOIN Sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column = 1
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY IC1.object_id,C.name,index_id
FOR XML PATH('')), 1, 2, '') IncludedColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY IC2.object_id ,IC2.index_id) tmp1
WHERE IncludedColumns IS NOT NULL ) tmp2
ON tmp2.object_id = I.object_id AND tmp2.index_id = I.index_id
WHERE I.is_primary_key = 0 AND I. is_unique_constraint = 0
AND I.[name] = @index_name
return @Return
end
 name + ' ON ' +
Schema_name(T.Schema_id)+'.'+T.name + ' ( ' +
KeyColumns + ' ) ' +
ISNULL(' INCLUDE ('+IncludedColumns+' ) ','') +
ISNULL(' WHERE '+I.Filter_definition,'') + ' WITH ( ' +
CASE WHEN I.is_padded = 1 THEN ' PAD_INDEX = ON ' ELSE ' PAD_INDEX = OFF ' END + ',' +
'FILLFACTOR = '+CONVERT(CHAR(5),CASE WHEN I.Fill_factor = 0 THEN 100 ELSE I.Fill_factor END) + ',' +
-- default value
'SORT_IN_TEMPDB = OFF ' + ',' +
CASE WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON ' ELSE ' IGNORE_DUP_KEY = OFF ' END + ',' +
CASE WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF ' ELSE ' STATISTICS_NORECOMPUTE = ON ' END + ',' +
-- default value
' DROP_EXISTING = ON ' + ',' +
-- default value
' ONLINE = OFF ' + ',' +
CASE WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON ' ELSE ' ALLOW_ROW_LOCKS = OFF ' END + ',' +
CASE WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON ' ELSE ' ALLOW_PAGE_LOCKS = OFF ' END + ' ) ON [' +
DS.
name + ' ON ' +
Schema_name(T.Schema_id)+'.'+T.name + ' ( ' +
KeyColumns + ' ) ' +
ISNULL(' INCLUDE ('+IncludedColumns+' ) ','') +
ISNULL(' WHERE '+I.Filter_definition,'') + ' WITH ( ' +
CASE WHEN I.is_padded = 1 THEN ' PAD_INDEX = ON ' ELSE ' PAD_INDEX = OFF ' END + ',' +
'FILLFACTOR = '+CONVERT(CHAR(5),CASE WHEN I.Fill_factor = 0 THEN 100 ELSE I.Fill_factor END) + ',' +
-- default value
'SORT_IN_TEMPDB = OFF ' + ',' +
CASE WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON ' ELSE ' IGNORE_DUP_KEY = OFF ' END + ',' +
CASE WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF ' ELSE ' STATISTICS_NORECOMPUTE = ON ' END + ',' +
-- default value
' DROP_EXISTING = ON ' + ',' +
-- default value
' ONLINE = OFF ' + ',' +
CASE WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON ' ELSE ' ALLOW_ROW_LOCKS = OFF ' END + ',' +
CASE WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON ' ELSE ' ALLOW_PAGE_LOCKS = OFF ' END + ' ) ON [' +
DS.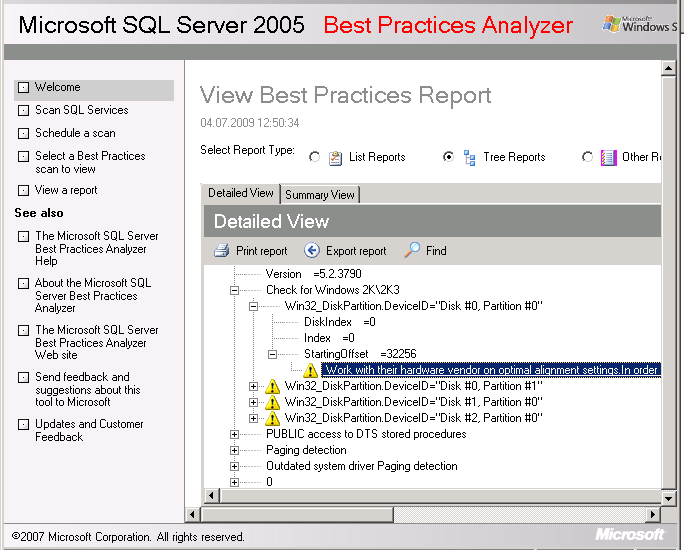 name + ' ] '
FROM sys.indexes I
JOIN sys.tables T ON T.Object_id = I.Object_id
JOIN sys.sysindexes SI ON I.Object_id = SI.id AND I.index_id = SI.indid
JOIN (SELECT * FROM (
SELECT IC2.object_id , IC2.index_id ,
STUFF((SELECT ' , ' + C.name + CASE WHEN MAX(CONVERT(INT,IC1.is_descending_key)) = 1 THEN ' DESC ' ELSE ' ASC ' END
FROM sys.index_columns IC1
JOIN Sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column = 0
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY IC1.object_id,C.name,index_id
ORDER BY MAX(IC1.key_ordinal)
FOR XML PATH('')), 1, 2, '') KeyColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY IC2.object_id ,IC2.index_id) tmp3 )tmp4
ON I.object_id = tmp4.object_id AND I.Index_id = tmp4.index_id
JOIN sys.
name + ' ] '
FROM sys.indexes I
JOIN sys.tables T ON T.Object_id = I.Object_id
JOIN sys.sysindexes SI ON I.Object_id = SI.id AND I.index_id = SI.indid
JOIN (SELECT * FROM (
SELECT IC2.object_id , IC2.index_id ,
STUFF((SELECT ' , ' + C.name + CASE WHEN MAX(CONVERT(INT,IC1.is_descending_key)) = 1 THEN ' DESC ' ELSE ' ASC ' END
FROM sys.index_columns IC1
JOIN Sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column = 0
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY IC1.object_id,C.name,index_id
ORDER BY MAX(IC1.key_ordinal)
FOR XML PATH('')), 1, 2, '') KeyColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY IC2.object_id ,IC2.index_id) tmp3 )tmp4
ON I.object_id = tmp4.object_id AND I.Index_id = tmp4.index_id
JOIN sys. stats ST ON ST.object_id = I.object_id AND ST.stats_id = I.index_id
JOIN sys.data_spaces DS ON I.data_space_id=DS.data_space_id
JOIN sys.filegroups FG ON I.data_space_id=FG.data_space_id
LEFT JOIN (SELECT * FROM (
SELECT IC2.object_id , IC2.index_id ,
STUFF((SELECT ' , ' + C.name
FROM sys.index_columns IC1
JOIN Sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column = 1
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY IC1.object_id,C.name,index_id
FOR XML PATH('')), 1, 2, '') IncludedColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY IC2.object_id ,IC2.index_id) tmp1
WHERE IncludedColumns IS NOT NULL ) tmp2
ON tmp2.object_id = I.object_id AND tmp2.index_id = I.index_id
WHERE I.is_primary_key = 0 AND I.
stats ST ON ST.object_id = I.object_id AND ST.stats_id = I.index_id
JOIN sys.data_spaces DS ON I.data_space_id=DS.data_space_id
JOIN sys.filegroups FG ON I.data_space_id=FG.data_space_id
LEFT JOIN (SELECT * FROM (
SELECT IC2.object_id , IC2.index_id ,
STUFF((SELECT ' , ' + C.name
FROM sys.index_columns IC1
JOIN Sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column = 1
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY IC1.object_id,C.name,index_id
FOR XML PATH('')), 1, 2, '') IncludedColumns
FROM sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY IC2.object_id ,IC2.index_id) tmp1
WHERE IncludedColumns IS NOT NULL ) tmp2
ON tmp2.object_id = I.object_id AND tmp2.index_id = I.index_id
WHERE I.is_primary_key = 0 AND I. is_unique_constraint = 0
AND I.[name] = @index_name
return @Return
end
is_unique_constraint = 0
AND I.[name] = @index_name
return @Return
end
Sql на какое-то время:
declare @RebuildIndex Table(
IndexId int identity(1,1),
IndexName varchar(100),
TableSchema varchar(50),
TableName varchar(100),
Fragmentation decimal(18,2)
)
insert into @RebuildIndex (IndexName,TableSchema,TableName,Fragmentation)
SELECT
B.[name] as 'IndexName',
Schema_Name(O.[schema_id]) as 'TableSchema',
OBJECT_NAME(A.[object_id]) as 'TableName',
A.[avg_fragmentation_in_percent] Fragmentation
FROM sys.dm_db_index_physical_stats(db_id(),NULL,NULL,NULL,'LIMITED') A
INNER JOIN sys.indexes B ON A.[object_id] = B.[object_id] and A.index_id = B.index_id
INNER JOIN sys.objects O ON O.[object_id] = B.[object_id]
where B.[name] is not null and B.is_primary_key = 0 AND B.is_unique_constraint = 0 and A.[avg_fragmentation_in_percent] >= 5
--select * from @RebuildIndex
declare @begin int = 1
declare @max int
select @max = Max(IndexId) from @RebuildIndex
declare @IndexName varchar(100), @TableSchema varchar(50), @TableName varchar(100) , @Fragmentation decimal(18,2)
while @begin <= @max
begin
Select @IndexName = IndexName from @RebuildIndex where IndexId = @begin
select @TableSchema = TableSchema from @RebuildIndex where IndexId = @begin
select @TableName = TableName from @RebuildIndex where IndexId = @begin
select @Fragmentation = Fragmentation from @RebuildIndex where IndexId = @begin
declare @sql nvarchar(max)
if @Fragmentation < 31
begin
set @sql = 'ALTER INDEX ['+@IndexName+'] ON ['+@TableSchema+']. ['+@TableName+'] REORGANIZE WITH ( LOB_COMPACTION = ON )'
print 'Reorganized Index ' + @IndexName + ' for ' + @TableName + ' Fragmentation was ' + convert(nvarchar(18),@Fragmentation)
end
else
begin
set @sql = (select dbo.GetIndexCreateScript(@IndexName))
if(@sql is not null)
begin
print 'Recreated Index ' + @IndexName + ' for ' + @TableName + ' Fragmentation was ' + convert(nvarchar(18),@Fragmentation)
end
else
begin
set @sql = 'ALTER INDEX ['+@IndexName+'] ON ['+@TableSchema+'].['+@TableName+'] REBUILD PARTITION = ALL WITH (ONLINE = ON)'
print 'Rebuilded Index ' + @IndexName + ' for ' + @TableName + ' Fragmentation was ' + convert(nvarchar(18),@Fragmentation)
end
end
execute(@sql)
set @begin = @begin+1
end
 ['+@TableName+'] REORGANIZE WITH ( LOB_COMPACTION = ON )'
print 'Reorganized Index ' + @IndexName + ' for ' + @TableName + ' Fragmentation was ' + convert(nvarchar(18),@Fragmentation)
end
else
begin
set @sql = (select dbo.GetIndexCreateScript(@IndexName))
if(@sql is not null)
begin
print 'Recreated Index ' + @IndexName + ' for ' + @TableName + ' Fragmentation was ' + convert(nvarchar(18),@Fragmentation)
end
else
begin
set @sql = 'ALTER INDEX ['+@IndexName+'] ON ['+@TableSchema+'].['+@TableName+'] REBUILD PARTITION = ALL WITH (ONLINE = ON)'
print 'Rebuilded Index ' + @IndexName + ' for ' + @TableName + ' Fragmentation was ' + convert(nvarchar(18),@Fragmentation)
end
end
execute(@sql)
set @begin = @begin+1
end
['+@TableName+'] REORGANIZE WITH ( LOB_COMPACTION = ON )'
print 'Reorganized Index ' + @IndexName + ' for ' + @TableName + ' Fragmentation was ' + convert(nvarchar(18),@Fragmentation)
end
else
begin
set @sql = (select dbo.GetIndexCreateScript(@IndexName))
if(@sql is not null)
begin
print 'Recreated Index ' + @IndexName + ' for ' + @TableName + ' Fragmentation was ' + convert(nvarchar(18),@Fragmentation)
end
else
begin
set @sql = 'ALTER INDEX ['+@IndexName+'] ON ['+@TableSchema+'].['+@TableName+'] REBUILD PARTITION = ALL WITH (ONLINE = ON)'
print 'Rebuilded Index ' + @IndexName + ' for ' + @TableName + ' Fragmentation was ' + convert(nvarchar(18),@Fragmentation)
end
end
execute(@sql)
set @begin = @begin+1
end
SQL Server 2017: возобновляемое перестроение индексов
Перестроение индексов на критических БД зачастую может быть сложной операцией по ряду причин. Наверное, практически каждый администратор БД сталкивался с длительными блокировками по время обслуживания индексов и ростом журнала транзакций. Отчасти может помочь перестроение индексов в режиме ONLINE или же операция REORGANIZE, но в SQL Server 2017 также в помощь приходит такая возможность, как возобновляемое перестроение, которая позволяет обходить проблемы, которые до этого не решались стандартными способами.
Наверное, практически каждый администратор БД сталкивался с длительными блокировками по время обслуживания индексов и ростом журнала транзакций. Отчасти может помочь перестроение индексов в режиме ONLINE или же операция REORGANIZE, но в SQL Server 2017 также в помощь приходит такая возможность, как возобновляемое перестроение, которая позволяет обходить проблемы, которые до этого не решались стандартными способами.
Операция ALTER INDEX теперь может ставить перестроение на паузу или возобновлять его, что позволяет управлять процессом обслуживания индексов более гранулярно. Представьте ситуацию: вы обнаружили, что процесс перестроения большого индекса сильно нагружает диск или блокирует важные процессы, и, вместо того, чтобы его прервать, вы просто ставите его на паузу и возобновляете, когда снова появляется возможность.
Конечно, приходится чем-то жертвовать ради удобства. В данном случае в БД необходимо будет хранить обе копии индекса: старую и новую до тех пор пока операция не завершится успешно или не будет прервана. Еще одним неприятным моментом может стать то, что опция SORT_IN_TEMPDB не работает в паре с возобновляемым перестроением.
Еще одним неприятным моментом может стать то, что опция SORT_IN_TEMPDB не работает в паре с возобновляемым перестроением.
Зато в качестве бонуса вы получаете возможность усекать журнал транзакций, как только вы ставите перестроение индексов на паузу или прерываете. Ранее он продолжал расти и расти до тех пор пока индекс полностью не перестроится.
Итак, давайте посмотрим на примере, как это работает. Для того, чтобы инициировать процесс перестроения индекса, который затем можно будет прервать, необходимо указать опции ONLINE=ON и RESUMABLE=ON.
alter index pk_MyBigDemoTable on [dbo].[MyBigDemoTable] rebuild with (resumable = on, online = on)
Также появилось новое представление, в котором можно следить за статусом всех возобновляемых перестроений.
select * from sys.
 index_resumable_operations
index_resumable_operationsОчень удобно, что отображается, идет ли сейчас перестроение, когда началось, когда прерывалось, процент выполнения.
Во время выполнения этого перестроения в отдельной сессии вы можете управлять им с помощью следующих команд.
alter index pk_MyBigDemoTable on [dbo].[MyBigDemoTable] pause alter index pk_MyBigDemoTable on [dbo].[MyBigDemoTable] resume alter index pk_MyBigDemoTable on [dbo].[MyBigDemoTable] abort
PAUSE\RESUME позволяют останавливать и продолжать перестроение, в то время как команда ABORT может его полностью прервать, если вам вдруг это понадобилось.
При возобновление вы можете менять параметр MAXDOP.
alter index pk_MyBigDemoTable on [dbo].
 [MyBigDemoTable] resume with (maxdop = 4)
[MyBigDemoTable] resume with (maxdop = 4)Но одна из самых интересных опций, состоит в том, что вы можете указывать максимальное количество минут, которые будет выполняться операция перестроения. Может быть очень полезно, если вы хотите перестраивать индекс, но при этом ограничивать эту операцию по времени.
alter index pk_MyBigDemoTable on [dbo].[MyBigDemoTable] rebuild with (resumable = on, online = on, max_duration = 1)
Как мы видим, новая возможность довольно интересна и позволяет вывести обслуживание индексов на новый уровень. Также вы можете посмотреть следующее видео на YouTube, где есть более детальная демонстрация использования этой возможности.
Ms sql ребилд индекса — Вэб-шпаргалка для интернет предпринимателей!
Начиная с выпуска SQL Server 2012 статистические данные не создаются путем сканирования всех строк таблицы при создании или перестроении секционированного индекса.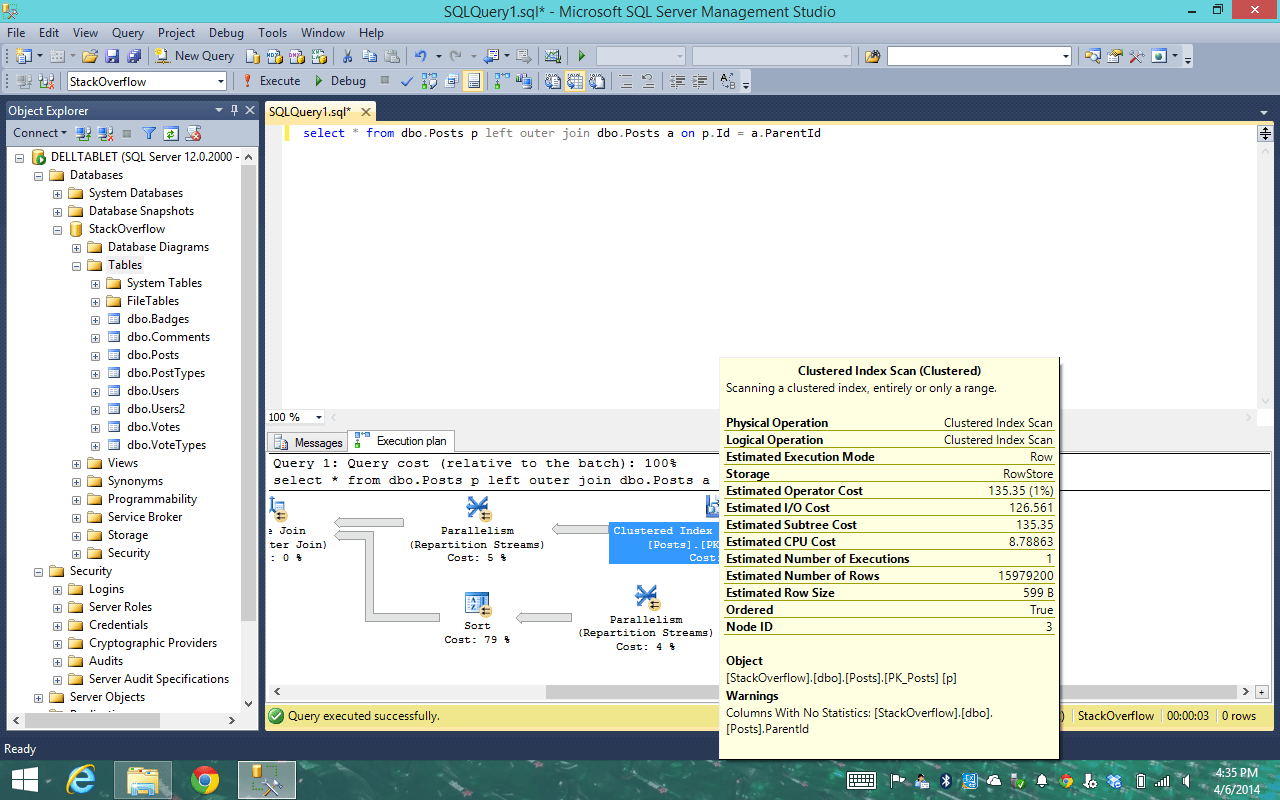 Вместо этого оптимизатор запросов использует для создания статистики алгоритм выборки по умолчанию. Для получения статистики по секционированным индексам путем сканирования всех строк таблицы используйте инструкции CREATE STATISTICS или UPDATE STATISTICS с предложением FULLSCAN.
Вместо этого оптимизатор запросов использует для создания статистики алгоритм выборки по умолчанию. Для получения статистики по секционированным индексам путем сканирования всех строк таблицы используйте инструкции CREATE STATISTICS или UPDATE STATISTICS с предложением FULLSCAN.
Безопасность
Разрешения
Необходимо разрешение ALTER для таблицы или представления. Пользователь должен быть членом предопределенной роли сервера sysadmin или предопределенных ролей базы данных db_ddladmin и db_owner.
Проверка фрагментации индекса
В обозревателе объектов разверните базу данных, содержащую таблицу, в которой необходимо проверить фрагментацию индекса.
Разверните папку Таблицы .
Разверните таблицу, в которой нужно проверить фрагментацию индекса.
Разверните папку Индексы .
Щелкните правой кнопкой мыши индекс, для которого нужно проверить фрагментацию, и выберите пункт Свойства.
В разделе Выбор страницывыберите пункт Фрагментация.
На странице Фрагментация доступны следующие сведения.
Заполненность страниц
Отображает среднее заполнение страниц индекса, в процентах. 100 % означает, что страницы индекса полностью заполнены. 50 % означает, что каждая страница индекса заполнена в среднем наполовину.
Общая фрагментация
Процент логической фрагментации. Отображает количество страниц индекса, хранимых не в порядке.
Средний размер строки
Средний размер строки конечного уровня.
Глубина
Количество уровней индекса, включая конечный уровень.
Перенаправленные записи
Количество записей в куче, содержащих указатели на данные в других местах. (Такое состояние возникает во время обновления, когда не хватает места для сохранения новой строки в исходном расположении.)
Фантомные строки
Количество строк, помеченных как удаленных, но еще фактически не удаленных. Эти строки будут удалены потоком очистки, когда сервер будет не загружен. Это значение не включает в себя строки, сохраняемые из-за ожидающей выполнения транзакции изоляции моментальных снимков.
Эти строки будут удалены потоком очистки, когда сервер будет не загружен. Это значение не включает в себя строки, сохраняемые из-за ожидающей выполнения транзакции изоляции моментальных снимков.
Тип индекса
Тип индекса. Возможными значениями являются Кластеризованный индекс, Некластеризованный индекси Первичный XML. Таблицы могут также сохраняться в виде кучи (без индексов), однако после этого данная страница «Свойства индекса» не может быть открыта.
Строки конечного уровня
Количество строк конечного уровня.
Максимальный размер строки
Максимальный размер строки конечного уровня.
Минимальный размер строки
Минимальный размер строки конечного уровня.
Страницы
Общее число страниц данных.
Partition ID
Идентификатор секции сбалансированного дерева, содержащего индекс.
Фантомные строки версии
Количество фантомных записей, которые сохраняются в памяти из-за незавершенной транзакции изоляции моментального снимка.
Проверка фрагментации индекса
В обозревателе объектовподключитесь к экземпляру компонента Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
Скопируйте следующий пример в окно запроса и нажмите кнопку Выполнить.
Эта инструкция должна возвратить результирующий набор, подобный приведенному ниже.
Реорганизация или перестроение индекса
В обозревателе объектов разверните базу данных, содержащую таблицу, в которой необходимо реорганизовать индекс.
Разверните папку Таблицы .
Разверните таблицу, в которой нужно реорганизовать индекс.
Разверните папку Индексы .
Щелкните правой кнопкой мыши индекс, который требуется реорганизовать, и выберите пункт Реорганизовать.
В диалоговом окне Реорганизация индексов убедитесь, что нужный индекс приведен в сетке Индексы для реорганизации , и нажмите кнопку ОК.
Установите флажок Сжать данные в столбцах больших объектов, чтобы указать, что также сжимаются все страницы, содержащие данные больших объектов.
Нажмите кнопку ОК.
Реорганизация всех индексов в таблице
В обозревателе объектов разверните базу данных, содержащую таблицу, в которой необходимо реорганизовать индексы.
Разверните папку Таблицы .
Разверните таблицу, в которой нужно реорганизовать индексы.
Щелкните правой кнопкой мыши папку Индексы и выберите команду Реорганизовать все.
В диалоговом окне Реорганизация индексов убедитесь, что нужные индексы приведены в сетке Индексы для реорганизации. Для удаления индекса из сетки Индексы для реорганизации выделите индекс и нажмите клавишу DELETE.
Установите флажок Сжать данные в столбцах больших объектов, чтобы указать, что также сжимаются все страницы, содержащие данные больших объектов.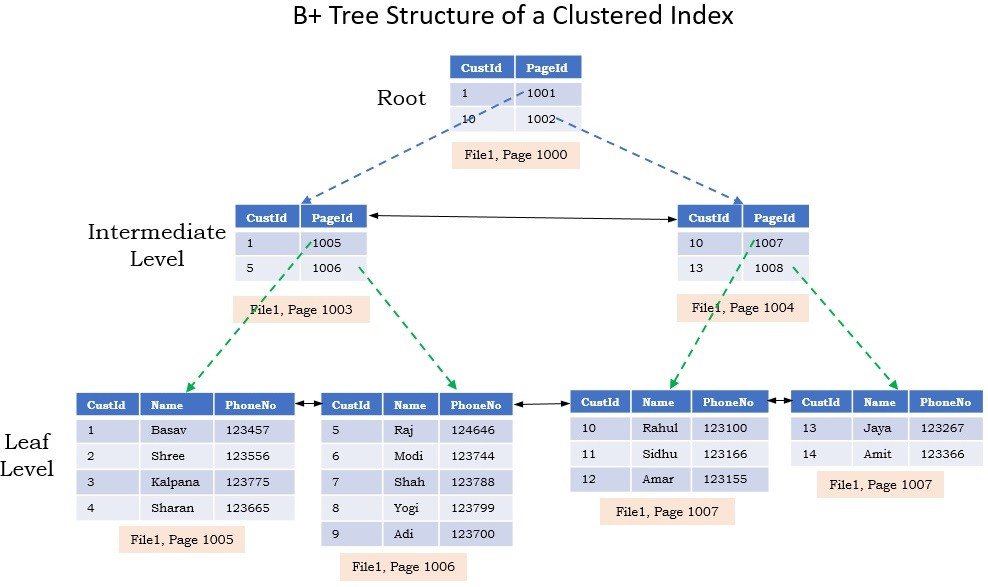
Нажмите кнопку ОК.
Перестроение индекса
В обозревателе объектов разверните базу данных, содержащую таблицу, в которой необходимо реорганизовать индекс.
Разверните папку Таблицы .
Разверните таблицу, в которой нужно реорганизовать индекс.
Разверните папку Индексы .
Щелкните правой кнопкой мыши индекс, который требуется реорганизовать, и выберите пункт Реорганизовать.
В диалоговом окне Перестроение индексов убедитесь, что нужный индекс приведен в сетке Индексы для перестроения , и нажмите кнопку ОК.
Установите флажок Сжать данные в столбцах больших объектов, чтобы указать, что также сжимаются все страницы, содержащие данные больших объектов.
Нажмите кнопку ОК.
Реорганизация дефрагментированного индекса
В обозревателе объектовподключитесь к экземпляру компонента Компонент Database Engine.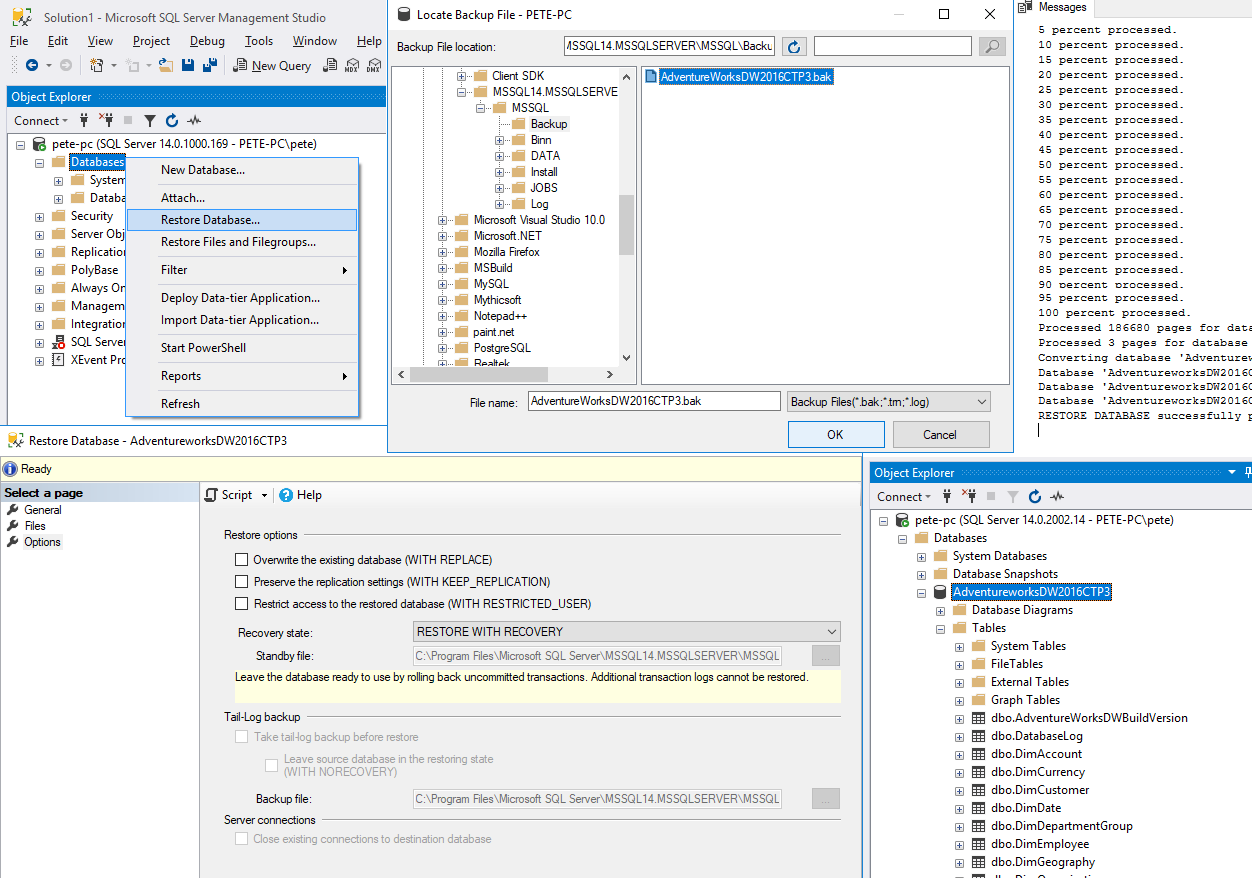
На стандартной панели выберите пункт Создать запрос.
Скопируйте следующий пример в окно запроса и нажмите кнопку Выполнить.
Реорганизация всех индексов в таблице
В обозревателе объектовподключитесь к экземпляру компонента Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
Скопируйте следующий пример в окно запроса и нажмите кнопку Выполнить.
Перестроение дефрагментированного индекса
В обозревателе объектовподключитесь к экземпляру компонента Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
Скопируйте следующий пример в окно запроса и нажмите кнопку Выполнить. В этом примере перестраивается один индекс в таблице Employee .
Перестроение всех индексов в таблице
В обозревателе объектовподключитесь к экземпляру компонента Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
Скопируйте следующий пример в запрос. В примере указывается ключевое слово ALL . Тем самым выполняется перестроение всех индексов, связанных с таблицей. Указываются три параметра.
Дополнительные сведения см. в статье ALTER INDEX (Transact-SQL).
SQL Server 2012
Компонент Компонент SQL Server Database Engine автоматически поддерживает состояние индексов при выполнении операций вставки, обновления или удаления в отношении базовых данных. Со временем эти изменения могут привести к тому, что данные в индексе окажутся разбросанными по базе данных (фрагментированными). Фрагментация имеет место в тех случаях, когда в индексах содержатся страницы, для которых логический порядок, основанный на значении ключа, не совпадает с физическим порядком в файле данных. Значительно фрагментированные индексы могут серьезно снижать производительность запросов и служить причиной замедления откликов приложения.
Для секционированных индексов, построенных на основе схемы секционирования, можно использовать любой из этих методов для всего индекса или отдельной его секции. При перестроении старый индекс удаляется, и создается новый. Таким образом, устраняется фрагментация, восстанавливается место на диске путем сжатия страниц с учетом указанного или существующего коэффициента заполнения, переупорядочиваются индексные строки в последовательных страницах. Если указывается ключевое слово ALL, то все индексы для таблицы удаляются и перестраиваются в одной транзакции. Для реорганизации индекса требуется минимальный объем системных ресурсов. При реорганизации концевой уровень кластеризованных и некластеризованных индексов на таблицах и представлениях дефрагментируется путем физической реорганизации страниц конечного уровня, в результате чего они выстраиваются в соответствии с логическим порядком конечных узлов (слева направо). Кроме того, реорганизация сжимает страницы индекса. Их сжатие производится в соответствии с текущим значением коэффициента заполнения.
- Для проверки фрагментации индекса используется:
Среда SQL Server Management Studio
- Для реорганизации или перестроения индекса используется:
Среда SQL Server Management Studio
Перед началом работы Править
Выявление фрагментации Править
Системная функция sys.dm_db_index_physical_stats позволяет выявить фрагментацию конкретного индекса, всех индексов в таблице или индексированном представлении, всех индексов в базе данных или всех индексов во всех базах данных. Для секционированных индексов sys.dm_db_index_physical_stats также предоставляет сведения о фрагментации каждой секции.
Результирующий набор, возвращаемый функцией sys.dm_db_index_physical_stats, включает следующие столбцы:
Зачем, когда и как восстанавливать и реорганизовывать индексы SQL Server
Цель индекса SQL Server почти такая же, как и у его дальнего родственника — индекса книги — он позволяет быстро получить информацию, но вместо навигации по книге он индексирует базу данных SQL Server.
Индексы SQL Server создаются на уровне столбцов как в таблицах, так и в представлениях. Его цель — обеспечить «быстрое обнаружение» данных на основе значений в индексированных столбцах.Если индекс создается по первичному ключу, всякий раз, когда выполняется поиск строки данных на основе одного из значений первичного ключа, SQL Server находит искомое значение в индексе, а затем использует этот индекс для поиска всей строки данных. Это означает, что SQL Server не должен выполнять полное сканирование таблицы при поиске определенной строки, что является гораздо более сложной задачей, требующей больших затрат времени и ресурсов SQL Server.
Реляционные индексы могут быть созданы даже до того, как в указанной таблице появятся данные или даже в таблицах и представлениях в другой базе данных.
СОЗДАТЬ ИНДЕКС MyIndex НА MyTable (Столбец1);
Подробнее о CREATE INDEX Transact-SQL можно найти в MSDN.
После создания индексов они будут автоматически обслуживаться ядром СУБД SQL Server всякий раз, когда операции вставки, обновления или удаления выполняются с базовыми данными.
Даже в этом случае эти автоматические изменения будут постоянно разбрасывать информацию в индексе по базе данных, фрагментируя индекс с течением времени.В результате в индексах теперь есть страницы, на которых логический порядок (на основе пары «ключ-значение») отличается от физического порядка внутри файла данных. Это означает, что на страницах индекса имеется высокий процент свободного места и что SQL Server должен читать большее количество страниц при сканировании каждого индекса. Кроме того, порядок страниц, принадлежащих одному индексу, искажается, и это добавляет больше работы SQL Server при чтении индекса, особенно в терминах ввода-вывода.
Влияние фрагментации индекса на SQL Server может варьироваться от снижения эффективности запросов — для серверов с низким влиянием на производительность, вплоть до точки, когда SQL Server полностью прекращает использование индексов и прибегает к последнему решению — полному сканированию таблиц для каждый запрос.Как упоминалось ранее, полное сканирование таблицы сильно повлияет на производительность SQL Server, и это последний сигнал тревоги, который поможет устранить фрагментацию индекса на SQL Server.
Решение проблемы фрагментированных индексов — перестроить или реорганизовать индексы.
Но, прежде чем рассматривать обслуживание индексов, важно ответить на два основных вопроса:
1. Какая степень фрагментации?
2. Какое действие следует предпринять? Реорганизовать или перестроить?
Обнаружение фрагментации
Как правило, для решения любой проблемы важно в первую очередь определить ее местонахождение и изолировать пораженный участок, прежде чем применять правильное средство.
Фрагментацию можно легко обнаружить, запустив системную функцию sys.dm_db_index_physical_stats, которая возвращает размер и информацию о фрагментации для данных и индексов таблиц или представлений в SQL Server. Его можно запустить только для определенного индекса в таблице или представлении, для всех индексов в конкретной таблице или представлении или для всех индексов во всех базах данных:
Результаты, возвращаемые после выполнения процедур, включают следующую информацию:
- avg_fragmentation_in_percent — средний процент некорректных страниц в индексе
- fragment_count — количество фрагментов в индексе
- avg_fragment_size_in_pages — среднее количество страниц в одном фрагменте в индексе
Анализ результатов обнаружения
Следующим шагом после обнаружения фрагментации является определение ее воздействия на SQL Server и необходимость каких-либо действий.
Нет точной информации о минимальном количестве фрагментации, которая влияет на SQL Server определенным образом, вызывая перегрузку производительности, тем более что среды SQL Server сильно различаются от одной системы к другой.
Однако есть общепринятое решение, основанное на проценте фрагментации (столбец avg_fragmentation_in_percent из ранее описанной функции sys.dm_db_index_physical_stats)
- Фрагментация менее 10% — дефрагментация не требуется.Принято считать, что в большинстве сред фрагментация индекса менее 10% незначительна, и ее влияние на производительность SQL Server минимально.
- Фрагментация между 10-30% — рекомендуется выполнить реорганизацию индекса
- Фрагментация выше 30% — рекомендуется выполнить восстановление индекса
Вот причины, по которым установлены указанные выше пороговые значения, которые помогут вам определить, следует ли выполнять перестроение индекса или реорганизацию индекса:
Реорганизация индекса — это процесс, при котором SQL Server просматривает существующий индекс и очищает его.Восстановление индекса — это сложный процесс, при котором индекс удаляется, а затем воссоздается с нуля с совершенно новой структурой, свободной от всех скопившихся фрагментов и страниц с пустым пространством.
Хотя реорганизация индекса — это чистая операция очистки, которая оставляет состояние системы таким, какое оно есть, без блокировки затронутых таблиц и представлений, процесс перестроения блокирует затронутую таблицу на весь период перестроения, что может привести к длительным простоям, которые невозможно было устранить. приемлемо в некоторых средах.
Учитывая это, очевидно, что перестроение индекса — это процесс с «более сильным» решением, но он имеет свою цену — возможные длительные блокировки затронутых индексированных таблиц.
С другой стороны, реорганизация индекса — это «легкий» процесс, который решит проблему фрагментации менее эффективным способом, поскольку очищенный индекс всегда будет вторым после нового, полностью созданного с нуля. Но реорганизация индекса намного лучше с точки зрения эффективности, поскольку она не блокирует затронутую индексированную таблицу во время работы.
Серверы с регулярными периодами обслуживания (например, регулярное обслуживание в выходные дни) почти всегда должны выбирать перестроение индекса, независимо от процента фрагментации, поскольку на эти среды вряд ли повлияют блокировки таблиц, налагаемые перестроениями индексов из-за регулярного и длительного обслуживания. периоды.
Как реорганизовать и перестроить индекс:
Использование SQL Server Management Studio:
- На панели «Обозреватель объектов» перейдите к SQL Server и разверните его, а затем к узлу «Базы данных».
- Расширьте конкретную базу данных с помощью фрагментированного индекса
- Разверните узел Таблицы и таблицу с фрагментированным индексом.
- Разверните конкретную таблицу
- Разверните узел индексов
- Щелкните правой кнопкой мыши фрагментированный индекс и выберите опцию Rebuild или Reorganize в контекстном меню (в зависимости от желаемого действия):
- Нажмите кнопку OK и дождитесь завершения процесса
Реорганизация индексов в таблице с помощью Transact-SQL
Укажите соответствующие сведения о базе данных и таблицах и выполните следующий код в SQL Server Management Studio, чтобы реорганизовать все индексы в определенной таблице:
ИСПОЛЬЗОВАТЬ MyDatabase; ИДТИ ИЗМЕНИТЬ ИНДЕКС ВСЕ НА MyTable РЕОРГАНИЗИРОВАТЬ; ИДТИ
Восстановить индексы в таблице с помощью Transact-SQL
Предоставьте соответствующие сведения о базе данных и таблицах и выполните следующий код в SQL Server Management Studio, чтобы перестроить все индексы в определенной таблице:
ИСПОЛЬЗОВАТЬ MyDatabase; ИДТИ ИЗМЕНИТЬ ИНДЕКС ВСЕ НА MyTable REBUILD; ИДТИ
Подробнее
Чтобы исправить фрагментацию индекса SQL, рассмотрите ApexSQL Defrag — средство мониторинга, анализа, обслуживания и дефрагментации индекса SQL Server.
4 января 2016 г.
Индекс SQL Server и обслуживание статистики
IndexOptimize — это хранимая процедура SQL Server Maintenance Solution для восстановления и реорганизации индексов и обновления статистики. IndexOptimize поддерживается в SQL Server 2008, SQL Server 2008 R2, SQL Server 2012, SQL Server 2014, SQL Server 2016, SQL Server 2017, SQL Server 2019, базе данных SQL Azure и управляемом экземпляре базы данных SQL Azure.
Скачать
Загрузите MaintenanceSolution.sql. Этот сценарий создает все необходимые вам объекты и задания. Вы также можете скачать объекты как отдельные скрипты. Решение для обслуживания SQL Server доступно на GitHub.
Лицензия
Решение для обслуживания SQL Server предоставляется бесплатно.
Параметры
Базы данных
Выбрать базы данных. Поддерживаются ключевые слова SYSTEM_DATABASES, USER_DATABASES, ALL_DATABASES и AVAILABILITY_GROUP_DATABASES. Символ дефиса (-) используется для исключения баз данных, а символ процента (%) используется для выбора подстановочного знака.Все эти операции можно комбинировать, используя запятую (,).
| Значение | Описание |
|---|---|
| СИСТЕМНЫЕ БАЗЫ ДАННЫХ | Все системные базы данных (главная, msdb и модель) |
| БАЗЫ ДАННЫХ_ПОЛЬЗОВАТЕЛЯ | Все пользовательские базы |
| ALL_DATABASES | Все базы |
| AVAILABILITY_GROUP_DATABASES | Все базы данных в группах доступности |
| USER_DATABASES, -AVAILABILITY_GROUP_DATABASES | Все пользовательские базы данных, не входящие в группы доступности |
| Db1 | База данных Db1 |
| Db1, Db2 | Базы данных Db1 и Db2 |
| БАЗЫ_ДАННЫХ_ПОЛЬЗОВАТЕЛЯ, -Db1 | Все пользовательские базы, кроме Db1 |
| % Db% | Все базы данных, в имени которых есть «Db» |
| % Db%, -Db1 | Все базы данных, в названии которых есть «Db», кроме Db1 |
| ALL_DATABASES, -% Db% | Все базы данных, в имени которых нет «Db» |
Низкая фрагментация
Укажите операции обслуживания индекса, которые должны выполняться над индексом с низкой степенью фрагментации.
| Значение | Описание |
|---|---|
| INDEX_REBUILD_ONLINE | Перестроить индекс онлайн. |
| INDEX_REBUILD_OFFLINE | Перестроить индекс в автономном режиме. |
| INDEX_REORGANIZE | Реорганизовать индекс. |
| INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE | Перестроить индекс онлайн. Перестроить индекс в автономном режиме, если онлайн-перестройка для индекса не поддерживается. |
| INDEX_REBUILD_ONLINE, INDEX_REORGANIZE | Перестроить индекс онлайн.Реорганизуйте индекс, если онлайн-перестройка для индекса не поддерживается. |
| INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE | Реорганизовать индекс. Перестройте индекс в оперативном режиме, если реорганизация индекса не поддерживается. Перестроить индекс в автономном режиме, если реорганизация и оперативное восстановление не поддерживаются для индекса. |
| ПУСТО | Не выполняйте обслуживание индекса. Это значение по умолчанию для мало фрагментированного индекса. |
Оперативное перестроение индекса или реорганизация индекса не всегда возможны.По этой причине вы можете указать несколько операций обслуживания индекса для каждой группы фрагментации. Эти операции имеют приоритет слева направо: если первая операция поддерживается для индекса, то используется эта операция; если первая операция не поддерживается, то используется вторая операция (если поддерживается) и так далее. Если ни одна из указанных операций не поддерживается для индекса, то этот индекс не поддерживается.
IndexOptimize использует команду SQL Server ALTER INDEX: REBUILD WITH (ONLINE = ON) для восстановления индексов в оперативном режиме, REBUILD WITH (ONLINE = OFF) для восстановления индексов в автономном режиме и REORGANIZE для реорганизации индексов.
Фрагментация Средний
Укажите операции обслуживания индекса, которые будут выполняться над средне фрагментированным индексом.
| Значение | Описание |
|---|---|
| INDEX_REBUILD_ONLINE | Перестроить индекс онлайн. |
| INDEX_REBUILD_OFFLINE | Перестроить индекс в автономном режиме. |
| INDEX_REORGANIZE | Реорганизовать индекс. |
| INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE | Перестроить индекс онлайн.Перестроить индекс в автономном режиме, если онлайн-перестройка для индекса не поддерживается. |
| INDEX_REBUILD_ONLINE, INDEX_REORGANIZE | Перестроить индекс онлайн. Реорганизуйте индекс, если онлайн-перестройка для индекса не поддерживается. |
| INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE | Реорганизовать индекс. Перестройте индекс в оперативном режиме, если реорганизация индекса не поддерживается. Перестроить индекс в автономном режиме, если реорганизация и оперативное восстановление не поддерживаются для индекса.Это значение по умолчанию для индекса со средней степенью фрагментации. |
| ПУСТО | Не выполняйте обслуживание индекса. |
Оперативное перестроение индекса или реорганизация индекса не всегда возможны. По этой причине вы можете указать несколько операций обслуживания индекса для каждой группы фрагментации. Эти операции имеют приоритет слева направо: если первая операция поддерживается для индекса, то используется эта операция; если первая операция не поддерживается, то используется вторая операция (если поддерживается) и так далее.Если ни одна из указанных операций не поддерживается для индекса, то этот индекс не поддерживается.
IndexOptimize использует команду SQL Server ALTER INDEX: REBUILD WITH (ONLINE = ON) для восстановления индексов в оперативном режиме, REBUILD WITH (ONLINE = OFF) для восстановления индексов в автономном режиме и REORGANIZE для реорганизации индексов.
Фрагментация Высокая
Укажите операции обслуживания индекса, которые должны выполняться над индексом с высокой степенью фрагментации.
| Значение | Описание |
|---|---|
| INDEX_REBUILD_ONLINE | Перестроить индекс онлайн. |
| INDEX_REBUILD_OFFLINE | Перестроить индекс в автономном режиме. |
| INDEX_REORGANIZE | Реорганизовать индекс. |
| INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE | Перестроить индекс онлайн. Перестроить индекс в автономном режиме, если онлайн-перестройка для индекса не поддерживается. Это значение по умолчанию для высокофрагментированного индекса. |
| INDEX_REBUILD_ONLINE, INDEX_REORGANIZE | Перестроить индекс онлайн.Реорганизуйте индекс, если онлайн-перестройка для индекса не поддерживается. |
| INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE | Реорганизовать индекс. Перестройте индекс в оперативном режиме, если реорганизация индекса не поддерживается. Перестроить индекс в автономном режиме, если реорганизация и оперативное восстановление не поддерживаются для индекса. |
| ПУСТО | Не выполняйте обслуживание индекса. |
Оперативное перестроение индекса или реорганизация индекса не всегда возможны.По этой причине вы можете указать несколько операций обслуживания индекса для каждой группы фрагментации. Эти операции имеют приоритет слева направо: если первая операция поддерживается для индекса, то используется эта операция; если первая операция не поддерживается, то используется вторая операция (если поддерживается) и так далее. Если ни одна из указанных операций не поддерживается для индекса, то этот индекс не поддерживается.
IndexOptimize использует команду SQL Server ALTER INDEX: REBUILD WITH (ONLINE = ON) для восстановления индексов в оперативном режиме, REBUILD WITH (ONLINE = OFF) для восстановления индексов в автономном режиме и REORGANIZE для реорганизации индексов.
Уровень фрагментации 1
Установите нижний предел в процентах для средней фрагментации. По умолчанию — 5 процентов. Это основано на рекомендации Microsoft в электронной документации.
IndexOptimize проверяет avg_fragmentation_in_percent в sys.dm_db_index_physical_stats, чтобы определить фрагментацию.
Уровень фрагментации 2
Установите нижний предел в процентах для высокой фрагментации. По умолчанию — 30 процентов. Это основано на рекомендации Microsoft в электронной документации.
IndexOptimize проверяет avg_fragmentation_in_percent в sys.dm_db_index_physical_stats, чтобы определить фрагментацию.
MinNumberOfPages
Установить размер в страницах; индексы с меньшим количеством страниц пропускаются для обслуживания индекса. По умолчанию 1000 страниц. Это основано на рекомендации Microsoft.
IndexOptimize проверяет page_count в sys.dm_db_index_physical_stats, чтобы определить размер индекса.
MaxNumberOfPages
Установить размер в страницах; индексы с большим количеством страниц пропускаются для обслуживания индекса.По умолчанию ограничений нет.
IndexOptimize проверяет page_count в sys.dm_db_index_physical_stats, чтобы определить размер индекса.
SortInTempdb
Используйте базу данных tempdb для операций сортировки при перестроении индексов.
| Значение | Описание |
|---|---|
| Y | Используйте базу данных tempdb для операций сортировки при перестроении индексов. |
| № | Не используйте базу данных tempdb для операций сортировки при перестроении индексов.Это значение по умолчанию. |
Параметр SortInTempdb в IndexOptimize использует параметр SORT_IN_TEMPDB в команде SQL Server ALTER INDEX.
MaxDOP
Укажите количество процессоров для использования при перестроении индексов. Если это число не указано, используется максимальная глобальная степень параллелизма.
Параметр MaxDOP в IndexOptimize использует параметр MAXDOP в команде SQL Server ALTER INDEX.
FillFactor
Укажите в процентах, насколько полными должны быть страницы при перестроении индексов.Если процент не указан, используется коэффициент заполнения в sys.indexes.
Параметр FillFactor в IndexOptimize использует параметр FILLFACTOR в команде SQL Server ALTER INDEX.
PadIndex
Примените процент свободного пространства, указанный коэффициентом заполнения, к страницам промежуточного уровня индекса.
| Значение | Описание |
|---|---|
| Y | Примените процент свободного места, который указывает коэффициент заполнения, к страницам промежуточного уровня индекса. |
| № | Страницы промежуточного уровня указателя заполнены почти до предела. Это значение по умолчанию. |
Параметр PadIndex в IndexOptimize использует параметр PADINDEX в команде SQL Server ALTER INDEX.
LOBСжатие
Сжать страницы, содержащие столбцы больших объектов (LOB), при реорганизации индексов.
| Значение | Описание |
|---|---|
| Y | Сжать страницы, содержащие столбцы больших объектов, при реорганизации индексов.Это значение по умолчанию. |
| № | Не сжимайте страницы, содержащие столбцы больших объектов, при реорганизации индексов. |
Параметр LOBCompaction в IndexOptimize использует параметр LOB_COMPACTION в команде SQL Server ALTER INDEX.
Статистика обновлений
Обновить статистику.
| Значение | Описание |
|---|---|
| ВСЕ | Обновить статистику индекса и столбца. |
| ИНДЕКС | Обновить статистику индекса. |
| КОЛОННЫ | Обновить статистику столбца. |
| ПУСТО | Не выполнять ведение статистики. Это значение по умолчанию. |
IndexOptimize использует команду SQL Server UPDATE STATISTICS для обновления статистики.
Только
Модифицированная статистика
Обновлять статистику, только если какие-либо строки были изменены с момента последнего обновления статистики.
| Значение | Описание |
|---|---|
| Y | Обновлять статистику, только если какие-либо строки были изменены с момента последнего обновления статистики. |
| № | Обновить статистику независимо от того, были ли изменены какие-либо строки. |
IndexOptimize проверяет модификацию_counter в sys.dm_db_stats_properties, в SQL Server 2008 R2 начиная с пакета обновления 2 и в SQL Server 2012 начиная с пакета обновления 1. В более ранних версиях он проверяет rowmodctr в sys.sysindexes. Для инкрементной статистики он проверяет модификацию_counter в sys.dm_db_incremental_stats_properties.
Статистика
Уровень модификации
Укажите процент измененных строк, когда должна обновляться статистика.Статистика также будет обновляться, когда количество измененных строк достигнет убывающего динамического порога SQRT (количество строк * 1000).
IndexOptimize проверяет столбцы модификации_counter и строки в sys.dm_db_stats_properties в SQL Server 2008 R2, начиная с пакета обновления 2, и в SQL Server 2012, начиная с пакета обновления 1. В более ранних версиях он проверяет столбцы rowmodctr и rowcnt в sys.sysindexes. Для инкрементной статистики он проверяет столбцы модификации_counter и строки в sys.dm_db_incremental_stats_properties.
StatisticsSample
Укажите в процентах, какая часть таблицы собрана при обновлении статистики. Значение 100 эквивалентно полному сканированию. Если значение не указано, SQL Server автоматически вычисляет требуемую выборку.
Параметр StatisticsSample в IndexOptimize использует параметры SAMPLE и FULLSCAN в команде SQL Server UPDATE STATISTICS.
СтатистикаПример
Обновить статистику с использованием самой последней выборки.
| Значение | Описание |
|---|---|
| Y | Обновить статистику самым последним образцом. |
| № | Позвольте SQL Server автоматически вычислить требуемую выборку. Это значение по умолчанию. |
Параметр StatisticsResample в IndexOptimize использует параметр RESAMPLE в команде SQL Server UPDATE STATISTICS.
Вы не можете комбинировать параметры StatisticsSample и StatisticsResample.
Уровень раздела
Поддерживать секционированные индексы на уровне секций. Если для этого параметра установлено значение Y, уровень фрагментации и количество страниц проверяются для каждого раздела. Затем для каждого раздела выполняется соответствующее обслуживание индекса (реорганизация или перестройка).
| Значение | Описание |
|---|---|
| Y | Поддерживать секционированные индексы на уровне секций. Это значение по умолчанию. |
| № | Поддерживать секционированные индексы на уровне индекса. |
MSShippedObjects
Ведение индексов и статистики по объектам, созданным внутренними компонентами SQL Server.
| Значение | Описание |
|---|---|
| Y | Ведение индексов и статистики для объектов, созданных внутренними компонентами SQL Server. |
| № | Не поддерживать индексы и статистику для объектов, созданных внутренними компонентами SQL Server. Это значение по умолчанию. |
IndexOptimize проверяет is_ms_shipped в sys.objects, чтобы определить, был ли объект создан внутренним компонентом SQL Server.
Индексы
Выберите индексы. Если этот параметр не указан, выбираются все индексы. Поддерживается ключевое слово ALL_INDEXES. Символ дефиса (-) используется для исключения индексов, а символ процента (%) используется для выбора подстановочного знака. Все эти операции можно объединить, используя запятую (,).
| Значение | Описание |
|---|---|
| ВСЕ_ИНДЕКСЫ | Все индексы |
| Db1.Schema1.Tbl1.Idx1 | Индекс Idx1 объекта Schema1.Tbl1 в базе данных Db1 |
| Db1.Schema1.Tbl1.Idx1, Db2.Schema2.Tbl2.Idx2 | Индекс Idx1 объекта Schema1.Tbl1 в базе данных Db1 и индекс Idx2 объекта Schema2.Tbl2 в базе данных Db2 |
| Db1.Schema1.Tbl1 | Все индексы объекта Schema1.Tbl1 в базе данных Db1 |
| Db1.Schema1.Tbl1, Db2.Schema2.Tbl2 | Все индексы объекта Schema1.Tbl1 в базе данных Db1 и все индексы объекта Schema2.Tbl2 в базе данных Db2 |
| Db1.Schema1.% | Все индексы в схеме Schema1 в базе данных Db1 |
| % .Schema1.% | Все индексы в схеме Schema1 во всех базах данных |
| ALL_INDEXES, -Db1.Schema1.Tbl1.Idx1 | Все индексы, кроме индекса Idx1 для объекта Schema1.Tbl1 в базе данных Db1 |
| ВСЕ_ИНДЕКСЫ, -Db1.Schema1.Tbl1 | Все индексы, кроме индексов объекта Schema1.Tbl1 в базе данных Db1 |
Ограничение времени
Установите время в секундах, по истечении которого никакие команды не выполняются. По умолчанию время не ограничено.
Задержка
Установите задержку в секундах между индексными командами. По умолчанию задержки нет.
WaitAtLowPriorityMaxDuration
Время в минутах, в течение которого операция перестроения индекса в оперативном режиме будет ожидать блокировки с низким приоритетом.
Параметр WaitAtLowPriorityMaxDuration в IndexOptimize использует параметры WAIT_AT_LOW_PRIORITY и MAX_DURATION в команде SQL Server ALTER INDEX.
WaitAtLowPriorityAbortAfterWait
Действие, которое будет выполнено после того, как операция перестроения индекса в оперативном режиме ожидала блокировки с низким приоритетом.
| Значение | Описание |
|---|---|
| НЕТ | Продолжить ожидание блокировок с нормальным приоритетом. |
| SELF | Прервать операцию восстановления индекса в оперативном режиме. |
| БЛОКЕРЫ | Убить пользовательские транзакции, которые блокируют операцию перестроения онлайн-индекса. |
Параметр WaitAtLowPriorityAbortAfterWait в IndexOptimize использует параметры WAIT_AT_LOW_PRIORITY и ABORT_AFTER_WAIT в команде SQL Server ALTER INDEX.
Возобновляемый
Укажите, можно ли возобновить операцию онлайн-индексации.
| Значение | Описание |
|---|---|
| Y | Операция с индексом возобновляется. |
| № | Операция с индексом не возобновляется. Это значение по умолчанию. |
Параметр Resumable в IndexOptimize использует параметр RESUMABLE в команде SQL Server ALTER INDEX.
Группы доступности
Выберите группы доступности. Поддерживается ключевое слово ALL_AVAILABILITY_GROUPS. Символ дефиса (-) используется для исключения групп доступности, а символ процента (%) используется для выбора подстановочного знака. Все эти операции можно комбинировать, используя запятую (,).
| Значение | Описание |
|---|---|
| ВСЕ_Доступные_группы | Все группы доступности |
| AG1 | Группа доступности AG1 |
| AG1, AG2 | Группы доступности AG1 и AG1 |
| ALL_AVAILABILITY_GROUPS, -AG1 | Все группы доступности, кроме AG1 |
| % AG% | Все группы доступности, в имени которых есть «AG» |
| % AG%, -AG1 | Все группы доступности, в названии которых есть «AG», кроме AG1 |
| ALL_AVAILABILITY_GROUPS, -% AG% | Все группы доступности, в имени которых нет «AG». |
LockTimeout
Установите время в секундах, в течение которого команда ожидает снятия блокировки.По умолчанию время не ограничено.
Параметр LockTimeout в IndexOptimize использует оператор набора SET LOCK_TIMEOUT в SQL Server.
LockMessageSeverity
Установите серьезность таймаутов блокировки и взаимоблокировок.
| Значение | Описание |
|---|---|
| 10 | Это информационное сообщение. |
| 16 | Это сообщение об ошибке. Это значение по умолчанию. |
Разделитель строк
Укажите разделитель строк.По умолчанию разделителем строк является запятая.
База данныхЗаказ
Укажите порядок базы данных.
| Значение | Описание |
|---|---|
| ПУСТО | Порядок, в котором были указаны базы данных. Затем по возрастанию по имени базы данных. Это значение по умолчанию. |
| DATABASE_NAME_ASC | По возрастанию по имени базы данных |
| DATABASE_NAME_DESC | По убыванию по имени базы данных |
| РАЗМЕР_БАЗЫ ДАННЫХ_ASC | По возрастанию по размеру базы данных |
| DATABASE_SIZE_DESC | По убыванию по размеру базы данных |
Базы данных Параллельные
Обрабатывать базы данных параллельно.
| Значение | Описание |
|---|---|
| Y | Параллельная обработка баз данных. |
| № | Обрабатывать базы данных по одной. Это значение по умолчанию. |
Вы можете обрабатывать базы данных параллельно, создав несколько заданий с одинаковыми параметрами и добавив параметр @DatabasesInParallel = ‘Y’.
ExecuteAsUser
Измените контекст выполнения на пользователя. Пользователь может быть dbo или любым другим пользователем.Пользователь должен присутствовать во всех базах данных, с которыми вы работаете.
Параметр ExecuteAsUser в IndexOptimize использует команду EXECUTE AS в SQL Server.
Таблица LogToTable
Записывать команды в таблицу dbo.CommandLog.
| Значение | Описание |
|---|---|
| Y | Записывать команды в таблицу. |
| № | Не записывать команды в таблицу. Это значение по умолчанию. |
Выполнить
Выполнять команды. По умолчанию команды выполняются нормально. Если для этого параметра установлено значение N, то команды печатаются только.
| Значение | Описание |
|---|---|
| Y | Выполнять команды. Это значение по умолчанию. |
| № | Только команды печати. |
Примеры
A. Восстановить или реорганизовать все индексы с фрагментацией во всех пользовательских базах данных
ВЫПОЛНИТЬ dbo.IndexOptimize
@Databases = ‘USER_DATABASES’,
@FragmentationLow = NULL,
@FragmentationMedium = ‘INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@FragmentationHigh = ‘INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@ FragmentationLevel1 = 5,
@ FragmentationLevel2 = 30
B. Восстановить или реорганизовать все индексы с фрагментацией и обновить измененную статистику во всех пользовательских базах данных
ВЫПОЛНИТЬ dbo.IndexOptimize
@Databases = ‘USER_DATABASES’,
@FragmentationLow = NULL,
@FragmentationMedium = ‘INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@FragmentationHigh = ‘INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@ FragmentationLevel1 = 5,
@ FragmentationLevel2 = 30,
@UpdateStatistics = ‘ALL’,
@OnlyModifiedStatistics = ‘Y’
С.Обновить статистику по всем пользовательским базам
EXECUTE dbo.IndexOptimize
@Databases = ‘USER_DATABASES’,
@FragmentationLow = NULL,
@FragmentationMedium = NULL,
@FragmentationHigh = NULL,
@UpdateStatistics = ‘ALL’
D. Обновить измененную статистику по всем пользовательским базам
EXECUTE dbo.IndexOptimize
@Databases = ‘USER_DATABASES’,
@FragmentationLow = NULL,
@FragmentationMedium = NULL,
@FragmentationHigh = NULL,
@UpdateStatistics = ‘ALL’,
@OnlyModified ‘
=’ YOnlyModified ‘
E.Восстановите или реорганизуйте все индексы с фрагментацией во всех пользовательских базах данных, выполняя операции сортировки в tempdb и используя все доступные процессоры
ВЫПОЛНИТЬ dbo.IndexOptimize
@Databases = ‘USER_DATABASES’,
@FragmentationLow = NULL, то
@FragmentationMedium = ‘INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@FragmentationHigh = ‘INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@ FragmentationLevel1 = 5,
@ FragmentationLevel2 = 30,
@SortInTempdb = ‘Y’,
@MaxDOP = 0
Ф.Перестроить или реорганизовать все индексы с фрагментацией во всех пользовательских базах данных, используя опцию поддержки многораздельных индексов на уровне раздела
ВЫПОЛНИТЬ dbo.IndexOptimize
@Databases = ‘USER_DATABASES’,
@FragmentationLow = NULL,
@FragmentationMedium = ‘INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@FragmentationHigh = ‘INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@ FragmentationLevel1 = 5,
@ FragmentationLevel2 = 30,
@PartitionLevel = ‘Y’
г.Перестроить или реорганизовать все индексы с фрагментацией во всех пользовательских базах данных с ограничением по времени, чтобы никакие команды не выполнялись через 3600 секунд
ВЫПОЛНИТЬ dbo.IndexOptimize
@Databases = ‘USER_DATABASES’,
@FragmentationLow = NULL,
@FragmentationMedium = ‘INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@FragmentationHigh = ‘INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@ FragmentationLevel1 = 5,
@ FragmentationLevel2 = 30,
@TimeLimit = 3600
Х.Перестроить или реорганизовать все индексы с фрагментацией в таблице Production.Product в базе данных AdventureWorks
ВЫПОЛНИТЬ dbo.IndexOptimize
@Databases = ‘AdventureWorks’,
@FragmentationLow = NULL,
@FragmentationMedium = ‘INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@FragmentationHigh = ‘INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@ FragmentationLevel1 = 5,
@ FragmentationLevel2 = 30,
@Indexes = ‘AdventureWorks.Production.Product’
И.Восстановите или реорганизуйте все индексы с фрагментацией, кроме индексов в таблице Production.Product в базе данных AdventureWorks
ВЫПОЛНИТЬ dbo.IndexOptimize
@Databases = ‘USER_DATABASES’,
@FragmentationLow = NULL,
@FragmentationMedium = ‘INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@FragmentationHigh = ‘INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@ FragmentationLevel1 = 5,
@ FragmentationLevel2 = 30,
@Indexes = ‘ALL_INDEXES, -AdventureWorks.Продукция.Продукт ‘
J. Восстановить или реорганизовать все индексы с фрагментацией во всех пользовательских базах данных и записать результаты в таблицу
ВЫПОЛНИТЬ dbo.IndexOptimize
@Databases = ‘USER_DATABASES’,
@FragmentationLow = NULL,
@FragmentationMedium = ‘INDEX_REORGANIZE, INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@FragmentationHigh = ‘INDEX_REBUILD_ONLINE, INDEX_REBUILD_OFFLINE’,
@ FragmentationLevel1 = 5,
@ FragmentationLevel2 = 30,
@LogToTable = ‘Y’
Исполнение
Вы можете выполнять хранимые процедуры из шагов задания T-SQL или из шагов задания CmdExec с sqlcmd и параметром -b.
| SQL Server версии | Тип работы |
|---|---|
| SQL Server 2008 и 2008 R2 в Windows | Шаги задания CmdExec с sqlcmd и параметром -b |
| SQL Server 2012, 2014, 2016 и 2017 в Windows | шаги задания T-SQL или шаги задания CmdExec с sqlcmd и параметром -b |
| SQL Server 2017 в Linux | Шаги задания T-SQL |
| Управляемый экземпляр базы данных SQL Azure | Шаги задания T-SQL |
В SQL Server 2005, 2008 и 2008 R2 существует проблема, заключающаяся в том, что шаг задания T-SQL перестает выполняться после первой ошибки.Используйте шаги задания CmdExec с sqlcmd и параметром -b в этих версиях.
Для создания заданий можно использовать сценарий MaintenanceSolution.sql. Он создаст шаги задания CmdExec с sqlcmd в SQL Server 2005, 2008 и 2008 R2 и шаги задания T-SQL в более поздних версиях.
Выявление и устранение фрагментации индекса SQL Server
Выявление фрагментации индекса — важная задача для любого администратора базы данных. В этой статье мы исследуем, как обнаружить и решить эту проблему в SQL Server.
Последнее обновление от Карен Энтони
В этом руководстве по технологиям SQL мы исследуем, как обнаружить и устранить фрагментацию индекса в SQL Server . Как известно администраторам, идентификация фрагментации индекса и ее обслуживание являются ключевыми элементами в обслуживании базы данных.
MS SQL Server всегда обновляет статистику индекса всякий раз, когда в таблице выполняется операция вставки, обновления или удаления.Фрагментация индекса — это значение производительности индекса, описываемое в процентах, которое может быть легко получено с помощью DMV SQL Server. На основе значения производительности индекса пользователи могут легко исправить обслуживаемые индексы, просто изменив процент фрагментации с помощью операций реорганизации или восстановления.
Причина различий в процентном отношении фрагментации индекса
Может быть вариаций процента фрагментации индекса , потому что порядок страниц может не согласовываться с фактическим порядком физических страниц в индексе распределения страниц.Если данные в таблице изменены, размер информации может быть изменен на странице данных. Страница может быть слишком полной даже до того, как операция обновления будет выполнена по всей таблице.
Однако можно создать свободного места на странице данных , выполнив операцию обновления таблицы. Затем пользователи могут наблюдать за порядком страниц в таблице, запустив операцию массового удаления. При выполнении этих операций обновления и удаления страница не должна быть слишком полной или пустой.Неиспользуемое свободное пространство может снова вызвать несоответствие порядка между логической страницей и реальной физической страницей, что увеличивает фрагментацию и в конечном итоге снижает производительность запроса. Он также может потреблять больше ресурсов сервера и имеет тенденцию увеличивать нагрузку .
Также важно сказать, что фрагментация индекса отрицательно скажется на производительности запроса только при сканировании страницы. В этом случае это увеличит вероятность снижения производительности других запросов SQL, а выполнение запросов с сильно фрагментированными индексами в таблице может занять дополнительное время.Такие запросы могут потреблять намного больше ресурсов — ЦП, кэш и ввод-вывод. Оставшиеся запросы SQL могут оказаться трудными для завершения операции с использованием несовместимых ресурсов сервера. Задачи можно даже заблокировать, запустив операции удаления или обновления. Оптимизатор может не собирать информацию о фрагментации индекса при создании данного плана выполнения запроса.
Повышение производительности БД и устранение фрагментации индекса
В этом случае может быть много индексов, созданных для данной таблицы с комбинациями разных столбцов, и каждый из этих индексов может показывать различный процент фрагментации.Прежде чем решить, что подходит, или рассмотреть индекс, который находится на обслуживании, пользователям, возможно, придется найти правильное пороговое значение для данной базы данных. Для настройки производительности вашей корпоративной базы данных существуют расширенные решения, такие как RemoteDBA.com . Такие поставщики, как удаленный администратор баз данных, приобрели соответствующие навыки и опыт в настройке производительности, фрагментации базы данных, устранении неполадок и различных других задач, управляя многими проектами с тонкой комбинацией всех этих вариантов использования.
Для поиска деталей объекта в идеале используется оператор T-SQL, приведенный ниже:
Примечательно, что 99% — это максимальная средняя фрагментация, которая может быть задействована с другим действием для уменьшения фрагментации с использованием таких вариантов, как REBUILD или REORGANIZE . Это команды для обслуживания индекса, которые могут быть выполнены с помощью оператора ALTER INDEX . Пользователи также могут выполнить эту команду с помощью SSMS.
Вы также можете отметить, что REORGANIZE и REBUILD — это два варианта выполнения операции обрезки на данной странице.Однако эту операцию необходимо выполнять только в непиковые часы, чтобы избежать какого-либо неблагоприятного воздействия на пользователей или транзакции. Корпоративная версия Microsoft SQL Server поддерживает онлайн-индексы, а автономные функции поддерживаются индексом REBUILD .
INDEX REBUILD обычно сначала отбрасывает индекс, а затем воспроизводит его с новыми страницами индекса. Однако эту задачу можно запустить одновременно, используя опцию онлайн, которая доступна в Enterprise Edition с помощью команды ALTER INDEX .Однако это может не повлиять на запрос запуска или задачи, выполняемые в других подобных таблицах. Индекс REBUILD также можно установить в автономном режиме с помощью следующей команды:
- Offline:
ALTER INDEX Имя_индекса ON Имя_таблицы REBUILD - Online:
ALTER INDEX Index_Name ON Имя_таблицы REBUILD WITH (ONLINE = ON) | WITH (ONLINE = ON)
При выполнении REBUILD INDEX в автономном режиме таблица ресурсов объекта того же индекса может быть недоступна до завершения процесса REBUILD .Однако это также может повлиять на другие транзакции, которые выполняются и связаны с этим объектом. Операции перестроения индекса также могут воссоздать индекс, сгенерировать совершенно новую статистику, а затем добавить те же записи журнала из индекса в файлы журнала в качестве транзакции базы данных.
Как мы видим, существует существенная разница между опциями Index REORGANIZE и REBUILD. Пользователи базы данных могут выбрать любую из этих альтернатив в соответствии с процентом фрагментации индекса.Документированного стандарта нет, но администратор должен следовать стандартному уравнению, основанному на требованиях к размеру индекса и типу.
Как определить использование уравнения?
Когда дело доходит до процента фрагментации индекса, всегда возникает вопрос, как определить использование уравнения. Обычно для определения того, какое уравнение использовать, используются следующие проценты:
- Если вы получили процент фрагментации от 15 до 30:
РЕОРГАНИЗИРОВАТЬ - Если вы обнаружите, что процент фрагментации превышает 30:
ПОВТОРИТЬ
В любом случае вариант ПЕРЕСТРОИТЬ может быть более полезным.Он хорошо себя чувствует в варианте ONLINE , когда база данных недоступна для обслуживания индекса в непиковое время.
Выводы
Очевидно, что фрагментация индекса остается критически важной внутренней фрагментацией файлов данных. Основные параметры, которые необходимо учитывать при оценке производительности баз данных:
- Архитектура базы данных играет решающую роль в планировании корпоративной базы данных.
- Дизайн базы данных, основанный на характере данных, которые она хранит, и планах хранения
- Правильное написание запросов
Идеальный дизайн индекса, время от времени поддерживаемый должным образом, всегда будет повышать производительность запросов в данном ядре базы данных, поэтому сделайте мудрый выбор для вашего бизнеса.
Различные методы восстановления всех индексов для всех таблиц — {coding} Взгляд
Существует несколько методов восстановления всех индексов всех таблиц, среди них:
- Использование планов обслуживания SQL Server.
- Использование сценария T-SQL на основе процента фрагментации.
- Использование команды ALTER INDEX.
В этой статье мы исследуем эти методы и проиллюстрируем их на практических примерах.
Перестроить индексы с использованием планов обслуживания базы данных SQL Server
Первый вариант для проверки — это перестроение индексов с планами обслуживания базы данных. Планы обслуживания доступны в папке управления SQL Server Management Studio.
Чтобы создать план обслуживания базы данных, запустите SQL Server Management Studio > разверните экземпляр базы данных > Management > щелкните правой кнопкой мыши план обслуживания > Новый план обслуживания .
Укажите название плана обслуживания. Затем перетащите Rebuild Index Task в конструктор планов обслуживания. Переименуйте задачу в Index Maintenance .
Следующим шагом является настройка плана обслуживания. Дважды щелкните по нему и настройте параметры в Rebuild Index Task следующим образом:
- Выберите базу данных AdventureWorks2017 в раскрывающемся меню База данных (и).
- Чтобы перестроить индексы всех таблиц, выберите Таблицы и представления в раскрывающемся списке Объект .
- Проверить Сортировать результаты в базе данных tempdb .
- MAXDOP — комплект 2 (два).
- В нашем случае мы перестроим индексы, только если значение Fragmentation больше 20%. Поэтому установите 20 в соответствующее поле.
- Щелкните OK , чтобы сохранить конфигурацию индекса и закрыть окно Rebuild Index Task .
А теперь настроим расписание.
Щелкните значок календаря в верхней части конструктора планов предупредительного ТОРО:
Откроется окно Новое расписание заданий . Настроим следующие параметры:
- Выполнять задание каждый день. В меню Тип расписания выбираем Повторяющийся . Затем в разделе Frequency выбираем Occurs > Daily .
- Повторяется каждые > 1 (день).
- Суточная частота > Происходит один раз в > укажите точное время. В нашем случае это час ночи.
- Щелкните ОК .
После этого сохраните план предупредительного ТОРО.
Созданные планы предупредительного ТОРО доступны в каталоге SSMS «План предупредительного ТОРО ». Чтобы просмотреть расписание, связанное с конкретным планом обслуживания, проверьте каталог Jobs в разделе Агент SQL Server .
Чтобы проверить задание, щелкните правой кнопкой мыши его имя в каталоге Maintenance Plan и выберите Execute из меню:
Запускается выполнение. После успешного завершения вы увидите следующее диалоговое окно:
Это был обычный метод восстановления индексов с планами обслуживания. Теперь перейдем к следующему методу — с использованием сценариев T-SQL.
Перестроить индексы с помощью оператора ALTER INDEX
Команду ALTER INDEX можно использовать для восстановления всех индексов таблицы.Синтаксис следующий:
ALTER INDEX ALL ON [table_name] REBUILD Примечание. Параметр table_name указывает имя таблицы, в которой мы хотим перестроить все индексы.
Например, мы хотим перестроить все индексы [HumanResources]. [Employee] . Запрос должен быть таким:
использовать AdventureWorks2017
идти
ИЗМЕНИТЬ ИНДЕКС ВСЕ НА [HumanResources]. [Сотрудник] ВОССТАНОВИТЬ
Идти
T-SQL Скрипты для перестроения на основе процента фрагментации
Обслуживание индекса требует значительных ресурсов.Кроме того, он блокирует таблицу, в которой восстанавливает индекс. Чтобы избежать таких осложнений, мы должны перестроить индекс, где фрагментация превышает 40%.
Чтобы проиллюстрировать этот случай, я создал сценарий T-SQL, который перестраивает индексы со степенью фрагментации выше 30%. Давайте изучим его части и функции.
Переменные и объявление таблицы темпов
Во-первых, нам нужно создать временные таблицы и переменные:
- @IndexFregQuery — хранит динамический запрос, используемый для заполнения фрагментированных индексов.
- @IndexRebuildQuery — содержит запрос ALTER INDEX.
- @IndexName — имя индекса, которое мы хотим перестроить.
- @TableName — имя таблицы, в которой мы хотим перестроить индекс.
- @SchemaName — имя схемы, в которой мы хотим перестроить индекс.
- #Fregmentedindex — таблица из трех столбцов , в которой хранятся имя индекса, имя таблицы и имя схемы.
Следующий код объявляет наши переменные и временную таблицу:
объявить @i int = 0
объявить @IndexCount int
объявить @IndexFregQuery nvarchar (max)
объявить @IndexRebuildQuery nvarchar (max)
объявить @IndexName varchar (500)
объявить @TableName varchar (500)
объявить @SchemaName varchar (500)
создать таблицу #Fregmentedindex (Index_name varchar (max), table_name varchar (max), schema_name varchar (max))
Получить список фрагментированных индексов
Наш следующий шаг — заполнить список индексов со степенью фрагментации 30% или выше.Мы должны вставить эти индексы в таблицу #FregmentedIndexes .
Запрос должен заполнить имя схемы, имя таблицы и имя индекса, чтобы вставить их во временную таблицу. Взгляните на этот запрос:
set @ IndexFregQuery = 'ВЫБРАТЬ i. [Имя], o.name, sch.name
FROM ['+ @DatabaseName +'] .sys.dm_db_index_physical_stats (DB_ID ('' '+ @DatabaseName +' ''), NULL, NULL, NULL, NULL) AS s
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ['+ @DatabaseName +'] .sys.indexes AS i ON s.object_id = i.object_id И s.index_id = i.index_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ['+ @DatabaseName +'] .sys.objects КАК o ON i.object_id = o.object_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ['+ @DatabaseName +'] .sys.schemas AS sch ON o.schema_id = sch.schema_id
WHERE (s.avg_fragmentation_in_percent> 30) и i.name не равно нулю '
вставить в #Fregmentedindex (имя_индекса, имя_таблицы, имя_схемы) exec sp_executesql @IndexFregQuery
Создать динамический SQL-запрос
Наконец, мы должны создать динамическую команду ALTER INDEX и выполнить ее.
Для генерации команды мы используем цикл WHILE. Он выполняет итерацию по таблице #FregmentedIndexes и заполняет имя схемы, имя таблицы и имя индекса, чтобы сохранить их в @SchemaName , @TableName и @IndexName . Значения параметров добавляются в команду ALTER INDEX.
Код следующий:
set @ IndexCount = (выберите count (1) из #Fregmentedindex)
Пока (@IndexCount> @i)
начинать
(выберите первые 1 @ TableName = table_name, @ IndexName = Index_name, @ SchemaName = schema_name из #Fregmentedindex)
Установите @IndexRebuildQuery = 'Изменить индекс [' + @IndexName + '] на [' + @ DatabaseName + '].['+ @ SchemaName +']. ['+ @TableName +'] перестроить '
exec sp_executesql @IndexRebuildQuery
установить @ i = @ i + 1
удалить из #Fregmentedindex, где Index_name = @ IndexName и table_name = @ TableName
Конец
Я инкапсулировал весь код в хранимую процедуру sp_index_main maintenance , созданную в базе данных DBATools . Код следующий:
использовать DBATools
идти
Создайте процедуру sp_index_main maintenance_daily
@DatabaseName varchar (50)
в виде
начинать
объявить @i int = 0
объявить @IndexCount int
объявить @IndexFregQuery nvarchar (max)
объявить @IndexRebuildQuery nvarchar (max)
объявить @IndexName varchar (500)
объявить @TableName varchar (500)
объявить @SchemaName varchar (500)
создать таблицу #Fregmentedindex (Index_name varchar (max), table_name varchar (max), schema_name varchar (max))
set @ IndexFregQuery = 'ВЫБРАТЬ i.[имя], o.name, sch.name
FROM ['+ @DatabaseName +'] .sys.dm_db_index_physical_stats (DB_ID ('' '+ @DatabaseName +' ''), NULL, NULL, NULL, NULL) AS s
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ['+ @DatabaseName +'] .sys.indexes AS i ON s.object_id = i.object_id И s.index_id = i.index_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ['+ @DatabaseName +'] .sys.objects КАК o ON i.object_id = o.object_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ ['+ @DatabaseName +'] .sys.schemas AS sch ON o.schema_id = sch.schema_id
WHERE (s.avg_fragmentation_in_percent> 30) и i.name не равно нулю '
вставить в #Fregmentedindex (имя_индекса, имя_таблицы, имя_схемы) exec sp_executesql @IndexFregQuery
set @ IndexCount = (выберите count (1) из #Fregmentedindex)
Пока (@IndexCount> @i)
начинать
(выберите первые 1 @ TableName = table_name, @ IndexName = Index_name, @ SchemaName = schema_name из #Fregmentedindex)
Установите @IndexRebuildQuery = 'Изменить индекс [' + @IndexName + '] на [' + @ DatabaseName + '].['+ @ SchemaName +']. ['+ @TableName +'] перестроить '
exec sp_executesql @IndexRebuildQuery
установить @ i = @ i + 1
удалить из #Fregmentedindex, где Index_name = @ IndexName и table_name = @ TableName
Конец
Конец
Как только процедура будет готова, мы можем настроить задание SQL.
Разверните Агент SQL Server > щелкните правой кнопкой мыши Jobs > New Job .
Откроется окно Новое задание , в котором необходимо указать желаемое имя задания.
Чтобы создать шаг задания, перейдите в раздел Steps > кнопку New :
Вы попадете в окно New Job Step для настройки этого шага.
Введите желаемое имя шага и введите следующий код в текстовое поле:
использовать DBATools
идти
exec sp_index_mainasted_daily 'AdventureWorks2017'
Чтобы настроить расписание, перейдите к Расписания > щелкните Новый .
Наша работа должна быть выполнена в 01:00. Соответственно настраиваем расписание:
- Тип расписания > Повторяющийся .
- Частота секция> Встречается > Ежедневно ; Повторяется каждые > 1 (один).
- Суточная частота секция> Происходит один раз в > 01:00:00.
- Щелкните ОК .
Вы будете переведены обратно в раздел New Job . Щелкните OK и там, чтобы создать задание.
Вновь созданное задание доступно в каталоге Jobs в папке SQL Server Agent .
Теперь нам нужно протестировать задание: щелкните его правой кнопкой мыши и выберите Начать задание…
Задание запускается, при успешном завершении вы увидите следующее сообщение:
Сводка
В данной статье представлены три функциональных способа восстановления индексов всех таблиц.Мы изучили их все с пошаговыми инструкциями и практическими примерами, чтобы проиллюстрировать конфигурацию задания. Выбор подходящего варианта остается за вами, и мы надеемся, что эта статья вам помогла.
Nisarg — администратор баз данных SQL Server и сертифицированный специалист Microsoft, имеющий более 5 лет опыта в администрировании SQL Server и 2 года в администрировании баз данных Oracle 10g. Он имеет опыт проектирования баз данных, настройки производительности, резервного копирования и восстановления, настройки высокой доступности и аварийного восстановления, миграции и обновления баз данных.Он получил степень бакалавра информационных технологий Университета Ганпат.
Последние сообщения Nisarg Upadhyay (посмотреть все)
бесплатных методов для восстановления индексов в базе данных SQL
Автор: Чаранджит Каур |
Обновлено 10 июня 2021 г.
| Восстановление файлов
| Ремонт баз данных MSSQL
| Читать 5 мин.
Обзор: В этой статье описывается важность восстановления индексов в базе данных SQL Server. В нем также объясняется, как перестроить индексы в базе данных SQL с помощью SQL Server Management Studio (SSMS) и T-SQL.
Когда и зачем нужно перестраивать индексы в базе данных SQL?
Индексы в базе данных SQL автоматически изменяются механизмом базы данных при выполнении операций INSERT, DELETE или UPDATE для строки в таблице. Однако эти модификации могут привести к фрагментации индекса. А поскольку индексы становятся сильно фрагментированными, производительность запросов снижается. Таким образом, индексы в базе данных SQL Server необходимо время от времени перестраивать, чтобы повысить производительность запросов к базе данных.
| ВАЖНО! Сама по себе фрагментация индекса — не единственная причина для восстановления индекса. Вам также может потребоваться перестроить его, чтобы исправить поврежденный индекс SQL Server, поскольку поврежденный индекс также может вызвать задержку выполнения запроса и медленное время ответа. Вы также можете исправить повреждение кластерного индекса в базе данных SQL, восстановив базу данных из резервной копии. Если обновленная резервная копия недоступна, воспользуйтесь программой Stellar Repair для MS SQL, чтобы восстановить поврежденный индекс. |
Прежде чем обсуждать методы перестроения индекса SQL, необходимо сначала определить фрагментацию индексов. Также было бы полезно, если бы вы проанализировали степень фрагментации индекса, чтобы выбрать лучший метод ее устранения.
Как обнаружить фрагментацию индекса и определить степень фрагментации?
Вы можете определить фрагментацию в конкретном индексе или во всех индексах, определенных в таблице или в базе данных, с помощью функции динамического управления (DMF) «sys.dm_db_index_physical_stats ».
| Колонна | ОПИСАНИЕ |
| avg_fragmentation_in_percent | Определяет процент логической фрагментации (неупорядоченные страницы в индексе) |
| количество фрагментов | Определить количество фрагментов (физически последовательных конечных страниц) в индексе |
| avg_fragment_size_in_pages | Определяет среднее количество страниц в одном фрагменте в индексе |
| Примечание. Для получения дополнительных сведений о sys.dm_db_index_physical_stats. |
После обнаружения фрагментации индекса необходимо также проанализировать уровень фрагментации, чтобы выбрать лучший метод удаления фрагментации: РЕОРГАНИЗАЦИЯ ИНДЕКСА или ПЕРЕСТРОЙКА ИНДЕКСА .
avg_fragmentation_in_percent value | Корректирующий акт |
> 5% и 1 | РЕОРГАНИЗАЦИЯ ИЗМЕНЕНИЯ ИНДЕКСА |
> 30% 1 | ВОССТАНОВЛЕНИЕ ИЗМЕНЕНИЯ ИНДЕКСА С (ONLINE = ON) 2 |
Вы можете реорганизовать индекс, если уровень фрагментации низкий.Однако вы должны перестроить индексы со степенью фрагментации, превышающей 30 процентов. Если у вас сильно фрагментирован, продолжите понимание методов восстановления индекса.
Как восстановить индекс в SQL Server?
Метод 1. Используйте SSMS
Вы можете перестроить кластерный индекс в оперативном или автономном режиме. Здесь мы обсудим шаги по восстановлению индекса в интерактивном режиме с помощью SQL Server Management Studio.Подробные шаги следующие:
- В SSMS в поле «Обозреватель объектов» щелкните знак «плюс», чтобы развернули базу данных SQL, содержащую таблицу, для которой необходимо перестроить индекс в оперативном режиме .
- Разверните таблицу базы данных , для которой вы хотите перестроить индекс в оперативном режиме.
- Разверните папку «Индексы» , щелкните правой кнопкой мыши индекс, который вы хотите перестроить в интерактивном режиме, и выберите «Свойства ».
- Выберите Параметры под Выберите страницу .
- Выберите Разрешить онлайн-обработку DML , выберите Истинный из списка, а затем нажмите ОК .
- Щелкните правой кнопкой мыши индекс, который нужно перестроить в интерактивном режиме, и выберите Перестроить .
- Когда откроется диалоговое окно «Перестроить индексы» , убедитесь, что в индексах указан правильный индекс, чтобы перестроить сетку.Нажмите ОК .
Метод 2 — Используйте T-SQL
Вы также можете перестроить индексы с помощью Transact SQL. Синтаксис для восстановления одного индекса следующий:
| ALTER INDEX index1 ON table1 REBUILD; |
Используйте следующий синтаксис, чтобы перестроить все индексы в таблице:
| ALTER INDEX ALL ON table1 REBUILD; |
Чтобы перестроить все индексы в таблице в указанной базе данных, используйте следующий синтаксис:
| ALTER INDEX ALL ON dbo.table1 REBUILD; |
Давайте продемонстрируем пример восстановления единственного индекса для указанной таблицы. Для этого выполните следующие действия:
- В SSMS щелкните Обозреватель объектов , а затем подключитесь к экземпляру компонента Database Engine.
- На стандартной панели щелкните Новый запрос .
- Скопируйте и вставьте приведенный ниже код в окно запроса, а затем нажмите Выполнить .В приведенном ниже примере index_name «AK», связанное с конкретной таблицей «Employee_BusinessEntity», будет перестроено.
| ИСПОЛЬЗОВАТЬ AdventureWorks2012; GO ALTER INDEX AK_Employee_BusinessEntity ON HumanResources.Employee REBUILD; GO |
В следующем примере показано, как перестроить все индексы в таблице:
- В обозревателе объектов щелкните Новый запрос .
- Скопируйте и вставьте в запрос следующую команду. В этом примере ключевое слово «ALL» используется для перестроения всех индексов в таблице базы данных.
| ИСПОЛЬЗОВАТЬ AdventureWorks2012; GO ALTER INDEX ALL ON HumanResources. Сотрудник REBUILD; GO |
Заключение
В этой статье обсуждается, когда и почему вам может потребоваться перестроить индексы в базе данных SQL Server; это может зависеть от того, насколько сильно фрагментирован индекс.В статье также обсуждались шаги по восстановлению индексов с помощью SQL Server Management Studio (SSMS) и выполнения запросов с использованием Transact-SQL (T-SQL). Если вам неудобно писать запросы, вы можете выбрать для работы SSMS. Если индекс, который вы перестроили, поврежден, вы можете исправить это, восстановив базу данных из резервной копии или используя программу Stellar Repair для MS SQL. Программное обеспечение может помочь исправить повреждение индекса в базе данных SQL Server и без прерывания восстановить базу данных в исходную форму.
Вы уже оценили. Спасибо.
75%
людей нашли эту статью полезной
Реорганизация индекса против индекса перестройки в плане обслуживания сервера Sql
Я поискал в Интернете и нашел несколько хороших статей. В и я написал функцию и сценарий ниже, которые реорганизовывают, воссоздают или перестраивают все индексы в базе данных.
Сначала вам может потребоваться прочитать эту статью, чтобы понять, почему мы не просто воссоздаем все индексы.
Во-вторых, нам нужна функция для построения скрипта создания индекса. Так что эта статья может помочь. Также поделюсь рабочей функцией ниже.
Последний шаг создания цикла while для поиска и организации всех индексов в базе данных. Это видео — отличный пример того, как это сделать.
Функция:
создать функцию GetIndexCreateScript (
@index_name nvarchar (100)
)
возвращает nvarchar (max)
в виде
начинать
объявить @Return varchar (max)
ВЫБРАТЬ @Return = 'СОЗДАТЬ' +
СЛУЧАЙ, КОГДА I.is_unique = 1 ТОГДА 'УНИКАЛЬНОЕ' ИНАЧЕ '' КОНЕЦ +
I.type_desc COLLATE DATABASE_DEFAULT + 'INDEX' +
I.name + 'ON' +
Schema_name (T.Schema_id) + '.' + T.name + '(' +
KeyColumns + ')' +
ISNULL ('ВКЛЮЧИТЬ (' + Включенные столбцы + ')', '') +
ISNULL ('WHERE' + I.Filter_definition, '') + 'WITH (' +
СЛУЧАЙ, КОГДА I.is_padded = 1 ТОГДА 'PAD_INDEX = ON' ELSE 'PAD_INDEX = OFF' END + ',' +
'FILLFACTOR =' + CONVERT (CHAR (5), CASE WHEN I.Fill_factor = 0 THEN 100 ELSE I.Fill_factor END) + ',' +
-- значение по умолчанию
'SORT_IN_TEMPDB = OFF' + ',' +
СЛУЧАЙ, КОГДА I.ignore_dup_key = 1 THEN 'IGNORE_DUP_KEY = ON' ELSE 'IGNORE_DUP_KEY = OFF' END + ',' +
СЛУЧАЙ, КОГДА ST.no_recompute = 0 ТОГДА 'STATISTICS_NORECOMPUTE = OFF' ELSE 'STATISTICS_NORECOMPUTE = ON' END + ',' +
-- значение по умолчанию
'DROP_EXISTING = ON' + ',' +
-- значение по умолчанию
'ОНЛАЙН = ВЫКЛ' + ',' +
СЛУЧАЙ, КОГДА I.allow_row_locks = 1 ТОГДА 'ALLOW_ROW_LOCKS = ON' ELSE 'ALLOW_ROW_LOCKS = OFF' END + ',' +
СЛУЧАЙ, КОГДА I.allow_page_locks = 1 ТОГДА 'ALLOW_PAGE_LOCKS = ON' ELSE 'ALLOW_PAGE_LOCKS = OFF' END + ') ON [' +
DS.имя + ']'
ИЗ sys.indexes I
ПРИСОЕДИНЯЙТЕСЬ к sys.tables T ON T.Object_id = I.Object_id
ПРИСОЕДИНЯЙТЕСЬ к sys.sysindexes SI ON I.Object_id = SI.id И I.index_id = SI.indid
ПРИСОЕДИНЯЙТЕСЬ (ВЫБРАТЬ * ИЗ (
ВЫБЕРИТЕ IC2.object_id, IC2.index_id,
STUFF ((SELECT ',' + C.name + CASE WHEN MAX (CONVERT (INT, IC1.is_descending_key)) = 1 THEN 'DESC' ELSE 'ASC' END
ИЗ sys.index_columns IC1
ПРИСОЕДИНЯЙТЕСЬ к системным столбцам C
ВКЛ C.object_id = IC1.object_id
И C.column_id = IC1.column_id
И IC1.is_included_column = 0
ГДЕ IC1.object_id = IC2.object_id
И IC1.index_id = IC2.index_id
ГРУППА ПО IC1.object_id, C.name, index_id
ЗАКАЗАТЬ ПО МАКС. (IC1.key_ordinal)
ДЛЯ ПУТИ XML ('')), 1, 2, '') KeyColumns
ИЗ sys.index_columns IC2
--WHERE IC2.Object_id = object_id ('Person.Address') - Комментарий для всех таблиц
ГРУППА ПО IC2.object_id, IC2.index_id) tmp3) tmp4
НА I.object_id = tmp4.object_id И I.Index_id = tmp4.index_id
ПРИСОЕДИНЯЙТЕСЬ к sys.stats ST ON ST.object_id = I.object_id И ST.stats_id = I.index_id
ПРИСОЕДИНЯЙТЕСЬ к sys.data_spaces DS ON I.data_space_id = DS.data_space_id
ПРИСОЕДИНЯЙТЕСЬ к sys.filegroups FG ON I.data_space_id = FG.data_space_id
LEFT JOIN (ВЫБРАТЬ * ИЗ (
ВЫБЕРИТЕ IC2.object_id, IC2.index_id,
STUFF ((ВЫБРАТЬ ',' + C.name
ИЗ sys.index_columns IC1
ПРИСОЕДИНЯЙТЕСЬ к системным столбцам C
ВКЛ C.object_id = IC1.object_id
И C.column_id = IC1.column_id
И IC1.is_included_column = 1
ГДЕ IC1.object_id = IC2.object_id
И IC1.index_id = IC2.index_id
ГРУППА ПО IC1.object_id, C.name, index_id
ДЛЯ ПУТИ XML ('')), 1, 2, '') IncludedColumns
ИЗ sys.index_columns IC2
--WHERE IC2.Object_id = object_id ('Person.Address') - Комментарий для всех таблиц
ГРУППА ПО IC2.object_id, IC2.index_id) tmp1
ГДЕ IncludedColumns НЕ НУЖНО) tmp2
ON tmp2.object_id = I.object_id И tmp2.index_id = I.index_id
ГДЕ I.is_primary_key = 0 И I.is_unique_constraint = 0
И Я.[name] = @index_name
return @Return
конец
Sql для пока:
объявить таблицу @RebuildIndex (
IndexId int идентификатор (1,1),
IndexName varchar (100),
TableSchema varchar (50),
TableName varchar (100),
Десятичная дробь (18,2)
)
вставить в @RebuildIndex (IndexName, TableSchema, TableName, Fragmentation)
ВЫБРАТЬ
B. [имя] как "IndexName",
Schema_Name (O. [schema_id]) как TableSchema,
OBJECT_NAME (A. [object_id]) как "TableName",
А. [avg_fragmentation_in_percent] Фрагментация
ОТ sys.dm_db_index_physical_stats (db_id (), NULL, NULL, NULL, 'LIMITED') A
INNER JOIN sys.indexes B ON A. [object_id] = B. [object_id] и A.index_id = B.index_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ sys.objects O ON O. [object_id] = B. [object_id]
где B. [name] не равно NULL, а B.is_primary_key = 0 И B.is_unique_constraint = 0 и A. [avg_fragmentation_in_percent]> = 5
--select * из @RebuildIndex
объявить @begin int = 1
объявить @max int
выберите @max = Max (IndexId) из @RebuildIndex
объявить @IndexName varchar (100), @TableSchema varchar (50), @TableName varchar (100), @Fragmentation decimal (18,2)
а @begin <= @max
начинать
Выберите @IndexName = IndexName из @RebuildIndex, где IndexId = @begin
выберите @TableSchema = TableSchema из @RebuildIndex, где IndexId = @begin
выберите @TableName = TableName из @RebuildIndex, где IndexId = @begin
выберите @Fragmentation = Fragmentation from @RebuildIndex, где IndexId = @begin
объявить @sql nvarchar (max)
если @Fragmentation <31
начинать
установите @sql = 'ALTER INDEX [' + @ IndexName + '] ON [' + @ TableSchema + '].['+ @ TableName +'] РЕОРГАНИЗИРОВАТЬ С (LOB_COMPACTION = ON) '
print 'Reorganized Index' + @IndexName + 'for' + @TableName + 'Fragmentation was' + convert (nvarchar (18), @ Fragmentation)
конец
еще
начинать
установите @sql = (выберите dbo.GetIndexCreateScript (@IndexName))
если (@sql не равно нулю)
начинать
print 'Recreated Index' + @IndexName + 'for' + @TableName + 'Fragmentation was' + convert (nvarchar (18), @ Fragmentation)
конец
еще
начинать
установите @sql = 'ALTER INDEX [' + @ IndexName + '] ON [' + @ TableSchema + '].['+ @ TableName +'] ВОССТАНОВИТЬ РАЗДЕЛ = ВСЕ С (ONLINE = ON) '
print 'Rebuilded Index' + @IndexName + 'for' + @TableName + 'Fragmentation was' + convert (nvarchar (18), @ Fragmentation)
конец
конец
выполнить (@sql)
установить @begin = @ begin + 1
конец
Восстановление индексов с помощью мастера обслуживания базы данных SSMS
В этой статье описывается, как использовать задачу «Перестроить индекс» в мастере обслуживания базы данных для поддержания работоспособности индексов базы данных, что, в свою очередь, может повысить производительность ваших запросов.Покроет:
- Что делает Rebuild Index и проблемы, которые могут возникнуть, если он не используется
- Соображения при использовании задачи и возможные альтернативы
- Как настроить и запланировать задачу с помощью мастера
В этой статье предполагается, что вы знакомы с интерфейсом мастера планов обслуживания SSMS, и основное внимание уделяется деталям задачи «Перестроить индекс». Если вам требуется подробное руководство по использованию мастера, см. Мою бесплатную электронную книгу «Руководство Брэда по планам обслуживания SQL Server».
Со временем, поскольку индексы подвергаются модификации данных, может произойти фрагментация индекса в виде:
- Пробелы на страницах данных - это приводит к потере пустого пространства.
- Логическая фрагментация - это логический порядок данных, который больше не соответствует физическому порядку данных
Пробелы на страницах данных могут уменьшить количество строк, которые могут храниться в кэше данных SQL Server, что приведет к увеличению дискового ввода-вывода.Логическая фрагментация может вызвать дополнительную активность диска, поскольку дисковая подсистема должна усерднее работать, чтобы найти данные на диске и переместить их в кэш данных. Единственный способ избавиться от ненужного пространства и логической фрагментации - это регулярно перестраивать или реорганизовывать индексы. Это одна из самых полезных и мощных задач обслуживания, которые вы можете выполнить с базой данных, потому что выполняемые ею шаги могут значительно повысить производительность базы данных.
Если вы настраиваете задачу «Перестроить индекс» с использованием всех параметров по умолчанию, то при запуске задачи она физически удаляет и перестраивает каждый индекс в выбранных вами базах данных, удаляя как бесполезное пустое пространство, так и логическую фрагментацию.В качестве побочного продукта восстановления всех индексов статистика индексов и столбцов также воссоздается заново и полностью обновляется.
Команда T-SQL, созданная из этих параметров по умолчанию, выглядит следующим образом:
ALTER INDEX имя_индекса ON имя_таблицы REBUILD PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, ONLINE = OFF, SORT_IN_TEMPDB = OFF) |
Хотя эта команда выглядит сложной, основная часть кода просто отключает различные параметры.Команда ALTER INDEX имеет множество параметров, некоторые из которых вы можете настроить с помощью мастера плана обслуживания, но многие другие - нет. Мы обсудим все доступные параметры конфигурации по мере работы над этой статьей.
Если вы просмотрите текстовый файл отчета из этой задачи, он будет выглядеть примерно так:
Получение отчетов из текстовых файлов
Если не указано иное на экране «Выбор параметров отчета» мастера, текстовые отчеты, созданные мастером, по умолчанию находятся в этой папке: C: \ Program Files \ Microsoft SQL Server \ MSSQL10.MSSQLSERVER \ MSSQL \ JOBS
1 2 3 4 5 6 7 8 9 10 11 12 13 140002 18 19 20 21 22 | Утилита обслуживания сервера Microsoft (R) (Unicode), версия Отчет был создан на «HAWAII». План обслуживания: план обслуживания баз данных пользователей Продолжительность: 00:00:23 Статус: выполнено. Подробности: Индекс перестроения (HAWAII) Перестроить индекс при подключении к локальному серверу Базы данных: AdventureWorks Объект: таблицы и представления Исходный объем свободного места Начало задачи: 2009-07-29T16: 01 : 48. Окончание задачи: 2009-07-29T16: 02: 09. Успех Команда: USE [AdventureWorks] GO ALTER INDEX [PK_AWBuildVersion_SystemInformationID] ON [dbo].[AWBuildVersion] ПЕРЕСТРОИТЬ РАЗДЕЛ = ВСЕ С (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, ONLINE = OFF, SORT_IN_TEMPDB = OFF) ork GO , GO PK_DatabaseLog_DatabaseLogID] ON [dbo]. [DatabaseLog] REBUILD PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, ONLINE = OFF, SORT_IN_TEMP 9D_IN_TEMP 9D_IN_IN_TEMP) |
После отображения информации заголовка обратите внимание, что команда выполняется для каждого индекса в базе данных.Я сократил отчет, чтобы показать только два перестраиваемых индекса, поскольку в полном отчете было фактически перестроено намного больше.
Производительность ваших индексов и, следовательно, ваших запросов к базе данных будет снижаться по мере того, как индексы становятся фрагментированными. Задача «Перестроить индекс» отлично справляется с перестройкой индексов для удаления логической фрагментации и пустого пространства, а также обновлением статистики. Поэтому очень важно запланировать регулярное выполнение этой задачи.
С другой стороны, задача «Перестроить индекс» - это ресурсоемкая задача.Кроме того, по мере того, как индекс перестраивается, на индекс будут наложены блокировки, предотвращающие доступ к нему во время перестройки. Любые запросы, пытающиеся получить доступ к этому индексу для возврата требуемых результатов, будут временно заблокированы до завершения перестройки. Таким образом, задача «Перестроить индекс» считается автономным действием , которое должно выполняться, когда к базе данных обращается как можно меньше людей. В общем, это означает, что во время планового периода обслуживания.
Довольно сложно дать общий совет относительно того, когда и как часто перестраивать индексы с помощью мастера плана обслуживания, так как это зависит от природы данных, индексов и запросов, которые их используют.Однако взгляните на мои общие советы по перестроению индекса, и затем мы рассмотрим их более подробно в следующих разделах:
- Ночью, при необходимости . Если ваши индексы быстро фрагментируются, и у вас есть ночной период обслуживания, который позволяет вам запускать задачу Rebuild Index вместе со всеми другими задачами обслуживания; тогда сделай так. Фрагментация индекса снизит производительность ваших индексов. Предполагая, что у вас есть окно обслуживания, восстановление каждую ночь не принесет никакого вреда и вполне может повысить производительность вашего сервера.
- Еженедельно, минимум . Если вы не можете выполнять эту задачу каждую ночь, то, как минимум, ее следует запускать один раз в неделю во время периода обслуживания. Если вы будете ждать намного дольше, чем неделю, вы рискуете снизить производительность SQL Server из-за негативного влияния потраченного впустую пустого пространства и логической фрагментации.
- Рассмотрим альтернативы, иначе . Если у вас недостаточно продолжительного окна обслуживания, чтобы выполнять эту задачу хотя бы раз в неделю, вам необходимо рассмотреть следующие альтернативы:
- Используйте онлайн-версию Rebuild Index задачу - доступно только с Enterprise Edition SQL Server.
- Используйте задачу Реорганизовать индекс , а затем задачу Обновить статистику - если вы используете стандартный выпуск SQL Server. Это ваша единственная реальная альтернатива при использовании мастера плана обслуживания, если вы хотите избежать задачи «Перестроить индекс».
- Избегайте мастера плана обслуживания - сценарии T-SQL или PowerShell обеспечивают больший контроль и гибкость в отношении точного характера и продолжительности этой задачи.
На вопрос , как часто нужно перестраивать индексы , сложно ответить, и мастер плана обслуживания не предлагает никаких указаний.Скорость и степень фрагментации индекса зависит от того, как он используется, и сильно варьируется от базы данных к базе данных.
Полное обсуждение измерения фрагментации индексов и, следовательно, принятия решения о том, как часто следует перестраивать индексы базы данных, выходит за рамки данной статьи. Однако стоит отметить, что функция динамического управления sys.dm_db_index_physical_stats содержит два столбца, в которых хранится ценная информация о фрагментации индекса:
- avg_page_space_used_in_percent - в этом столбце хранится средний объем пространства, используемого на странице.Например, для конкретного индекса может использоваться 50% пространства, что означает, что только половина пространства на странице данных в среднем используется для хранения строк данных.
- avg_fragmentation_in_percent - в этом столбце хранится степень логической фрагментации индекса в процентах. Например, конкретный индекс может быть фрагментирован на 80%, что означает, что в среднем 80% физического упорядочения страниц данных не соответствует их логическому порядку.
Если бы вы отслеживали эти данные в течение определенного периода времени, вы могли бы лучше оценить, насколько быстро ваши индексы фрагментируются, и, следовательно, как часто вам следует подумать о их восстановлении.Однако, если вы находитесь на этом уровне, велики шансы, что вы будете использовать методы сценариев для восстановления индексов, а не мастер плана обслуживания.
Хотя выполнение задачи перестроения индекса в автономном режиме не является обязательным, пока к базе данных нет доступа, это, безусловно, сильная рекомендация, особенно для больших баз данных с большим количеством пользователей. Если ваши таблицы относительно малы, восстановление будет быстрым, и большинство пользователей, которые будут одновременно обращаться к базе данных, вероятно, не заметят какого-либо снижения производительности в результате блокировки, требуемой задачей Rebuild Index.С другой стороны, если ваши таблицы большие или если у вас много одновременно работающих пользователей, задача Rebuild Index может негативно повлиять на взаимодействие с пользователем, значительно замедляя их доступ к базе данных и потенциально вызывая тайм-аут некоторых запросов. клиентское приложение.
Вообще говоря, если у вас достаточно большое окно обслуживания для выполнения задачи Rebuild Index в автономном режиме, то я рекомендую вам использовать эту задачу и запускать ее во время этого окна.
Если у вас нет окна обслуживания или его недостаточно для выполнения автономной задачи Rebuild Index, тогда у вас есть одна или две возможные альтернативы при использовании мастера плана обслуживания:
- Используйте онлайн-версию задачи Rebuild Index
- Используйте задачу реорганизации индекса, а затем задачу обновления статистики
Если у вас есть версия SQL Server Enterprise Edition, мастер плана обслуживания предлагает вариант Сохранить индекс в оперативном режиме при переиндексировании , что означает, что индекс будет по-прежнему доступен для пользователей даже во время его перестройки.Несмотря на то, что это онлайн-действие, вы все равно захотите запланировать эту задачу на время суток, когда сервер менее загружен, поскольку это все еще ресурсоемкая деятельность. Выполнение этой онлайн-задачи в напряженное время дня может повлиять на способность ваших пользователей получать своевременный доступ к базе данных, особенно если ваш SQL Server уже имеет узкие места в производительности.
Если у вас нет Enterprise Edition, а период обслуживания слишком короткий для выполнения автономной задачи перестроения индекса, вам следует подумать об использовании задачи «Реорганизация индекса», а затем сразу после этого запустить задачу «Обновить статистику».Задача «Реорганизация индекса» - это оперативная операция, что означает, что она может выполняться, пока пользователи обращаются к базе данных. Хотя это интерактивный процесс, он по-прежнему требует значительных ресурсов, и вы должны запланировать задачу на то время дня, когда сервер менее загружен.
Обратной стороной использования задачи «Реорганизация индекса» является то, что ее возможность дефрагментации индекса не является такой полной и полной, как задача «Перестроить индекс». Кроме того, выполнение этой задачи может занять больше времени, чем выполнение задачи «Перестроить индекс», и вам необходимо выполнить задачу «Обновить статистику» как отдельный шаг.
Реорганизация индексов
Эта тема, а также последующее обновление статистики также подробно освещены в моей книге Brad’s Sure Guide to SQL Server Maintenance Plan, которую можно бесплатно загрузить отсюда.
Если у вас есть Enterprise Edition SQL Server, есть вероятность, что ваши базы данных могут быть очень большими, и использование мастера плана обслуживания для обслуживания ваших баз данных может быть не лучшим выбором. Вы можете получить большую гибкость и контроль, создав свои собственные планы обслуживания с использованием сценариев T-SQL или PowerShell.
Например, вы можете измерять и отслеживать фрагментацию с помощью sys.dm_db_index_physical_stats, а затем создавать сценарий для дефрагментации только тех индексов, которые действительно в этом нуждаются.
Теперь, когда мы немного знаем о задаче «Перестроить индекс» и о том, когда ее следует запускать, давайте взглянем на ее экран конфигурации в мастере плана обслуживания, показанный на рисунке 1.1.
Рисунок 1.1: Мы готовы настроить задачу «Перестроить индекс».
Наш первый выбор - выбрать, для каких баз данных мы хотим запустить эту задачу..
Во-первых, обратите внимание, что на экране появляется раскрывающийся список Базы данных . Во-вторых, обратите внимание, что непосредственно под раскрывающимся списком баз данных находятся еще два раскрывающихся списка: Object и Selection . Эти два раскрывающихся списка отображаются для некоторых задач, а для других - нет. Мы поговорим о том, что они делают чуть позже.
Выбор нескольких баз данных
Как правило, вы хотите свести количество отдельных планов обслуживания к минимуму, поэтому в идеале вы должны создать один план и применить задачу Rebuild Index ко всем индексам в заданном наборе баз данных, например, во всех пользовательских баз данных.Кроме того, чтобы упростить обслуживание и избежать путаницы, каждую задачу в Плане следует применять к одному и тому же набору баз данных.
Однако могут быть особые случаи, когда вам нужно будет создать отдельные планы для удовлетворения конкретных требований к обслуживанию индексов в разных базах данных. Например, предположим, что на одном экземпляре SQL Server у вас есть 25 небольших баз данных, каждая размером менее 1 ГБ, и одна большая база данных, скажем, 50 ГБ. Предположим также, что немногим пользователям потребуется доступ к небольшим базам данных во время окон обслуживания, но многим пользователям может потребоваться доступ к базе данных объемом 50 ГБ в это время.В этом случае вы можете подумать о создании специального плана обслуживания для базы данных объемом 50 ГБ, который использует задачи реорганизации индекса и обновления статистики, и другого плана обслуживания, который применяет задачу восстановления индекса к меньшим базам данных.
В этом примере мы собираемся упростить задачу, поэтому предположим, что мы хотим выполнить задачу Rebuild Index для всех пользовательских баз данных. В этом случае мы можем выбрать вариант, показанный на рисунке 1.2, а затем нажать OK .
Рисунок 1.2: Чтобы упростить задачу, выберите опцию «Все пользовательские базы данных».
Экран Define Rebuild Index Task снова появляется, и два раскрывающихся списка, о которых я упоминал ранее, отображаются под раскрывающимся списком Databases , но они неактивны, как показано на рисунке 1.3.
Рисунок 1.3: Выпадающие поля «Объект» и «Выбор» недоступны.
Итак, что происходит? Почему эти два варианта неактивны? Причина в том, что эти два параметра доступны только в том случае, если вы выберете одну базу данных , в которой будет выполняться задача «Перестроить индекс».Поскольку мы выбрали Все пользовательские базы данных , эти две опции недоступны.
Выбор конкретной базы данных
Хотя это не относится к нашему примеру, давайте посмотрим, что произойдет, если мы выберем для задачи только одну базу данных, например AdventureWorks. Для этого выберите Эти базы данных на экране, показанном на рисунке 1.2, а затем установите флажок для AdventureWorks. Когда вы нажимаете OK , этот раздел экрана Define Rebuild Index Task будет выглядеть, как показано на рисунке 1.4.
Рисунок 1.4: Когда выбрана одна база данных, становится доступным раскрывающийся список «Объект».
Обратите внимание, что Определенные базы данных теперь отображается в раскрывающемся списке Базы данных , поле Объект теперь доступно, а поле Выбор пока что неактивно.
Опции Object и Selection позволяют нам выборочно перестраивать одни индексы в вашей базе данных, а не другие.Если мы щелкнем по раскрывающемуся списку Object , мы увидим варианты, показанные на рисунке 1.5.
Рисунок 1.5: Вы должны выбрать «Таблица» или «Просмотр».
Обратите внимание, что есть три варианта для Object . Если вы оставите выбранным вариант по умолчанию, Таблицы и представления, то задача «Перестроить индекс» будет применена к индексам, связанным со всеми таблицами и всеми индексированными представлениями в выбранной базе данных. Другими словами, вы ничего не изменили.Чтобы сузить объем задачи до конкретных объектов, вам нужно выбрать Таблица или Просмотр . После этого открывается раскрывающийся список Выбор . Например, давайте выберем Table , а затем нажмем «Выбрать один или несколько» в теперь доступном раскрывающемся списке Selection , как показано на рисунке 1.6.
Рисунок 1.6: Вы можете выбрать, какие таблицы вы хотите перестроить, с помощью задачи «Перестроить индекс».
Теперь у нас есть возможность выбрать определенные таблицы в базе данных AdventureWorks, к которым должна применяться эта задача.Например, мы могли бы перестроить только индексы, связанные с таблицей dbo.ErrorLog, или мы могли бы выбрать некоторую комбинацию таблиц, установив каждый из соответствующих флажков.
Почему нам нужно перестраивать индексы для одних таблиц, а не для других? Собственно, для этого есть очень веская причина. В большинстве баз данных есть таблицы, которые практически статичны; они редко, если вообще когда-либо, меняются, и поэтому нет никакой пользы в восстановлении связанных с ними индексов, поскольку со временем они не создают бесполезное пустое пространство или становятся логически фрагментированными.Выбирая только те индексы, которые действительно нуждаются в дефрагментации, вы можете сократить время, необходимое для выполнения задачи «Перестроить индекс», и в то же время уменьшить накладные расходы ресурсов, связанные с этой задачей.
Проблема, которую я вижу, заключается в том, что у большинства людей, использующих Мастер обслуживания, нет знаний, чтобы определить, какие индексы являются относительно статичными, а какие подвержены большой потере места и логической фрагментации. Если вы находитесь на том уровне, где знаете, как оценивать каждый индекс с помощью sys.dm_db_index_physical_stats DMF, чтобы применить процесс выборочной перестройки, тогда есть вероятность, что вам, вероятно, лучше реализовать этот процесс с использованием сценариев T-SQL или PowerShell и в первую очередь избегать использования мастера плана обслуживания.
Прежде чем мы продолжим, давайте кратко рассмотрим опцию View , которая доступна в раскрывающемся списке Object , как показано на рисунке 1.7.
Рисунок 1.7: Вы можете выбрать, какие индексированные представления вы хотите перестроить с помощью задачи «Перестроить индекс».
В данном случае «представление» относится не к обычным представлениям, а к индексированным представлениям. Индексированные представления - это физические представления, в отличие от обычных представлений, которые материализуются только тогда, когда они вызываются запросом. Поскольку индексированные представления являются физическими, их нужно перестраивать, как и обычные индексы. В соответствии с моим советом относительно опции Таблица , если вам нужна такая степень детализации для обслуживания индексов, вам не следует использовать мастер плана обслуживания для этой задачи.
Хотя я потратил немного времени, чтобы объяснить, что делают раскрывающиеся списки Object и Selection , я рекомендую вам не использовать их, поскольку они просто усложняют планы обслуживания, сводя на нет преимущество использования их в первую очередь.
У нас еще есть еще несколько вариантов, прежде чем мы закончим настройку этой задачи. Обратите внимание, что обсуждение этих параметров предполагает, что каждая из ваших таблиц имеет кластерный индекс, а не кучу. Куча - это таблица без кластерного индекса. Рекомендуется, чтобы все таблицы имели кластерный индекс.
Первые два варианта перечислены в разделе Параметры свободного пространства и включают «Реорганизовать страницы с размером свободного пространства по умолчанию» и «Изменить процент свободного места на странице на», как показано на рисунке 1.8. Вы можете выбрать тот или иной вариант, но не оба сразу.
Рисунок 1.8: Эти параметры могут существенно повлиять на задачу Rebuild Index.
Параметр по умолчанию «Реорганизовать страницы с количеством свободного места по умолчанию» немного сбивает с толку. Во-первых, он говорит, что реорганизует , а не перестраивает . Помните, что мы работаем над задачей «Перестроить индекс», а не над задачей «Реорганизовать индекс». Не позволяйте этому сбивать вас с толку и думать, что выбор этого параметра реорганизует индексы, а не создает их заново.Он делает последнее, и на самом деле это ошибка пользовательского интерфейса. На самом деле следует сказать «перестроить», а не «реорганизовать».
Вторая часть этой первой опции говорит «количество свободного места по умолчанию». Что это обозначает? При создании индекса SQL Server есть возможность создать индекс с определенным объемом свободного места на каждой странице данных. Этот параметр известен как коэффициент заполнения . Если индекс создается без указания коэффициента заполнения, то используется коэффициент заполнения по умолчанию, который равен 100 (фактически 0, но 0 означает то же самое, что и коэффициент заполнения 100%).Это означает, что для страниц данных индекса не создается свободного места.
Потенциальная проблема с коэффициентом заполнения 100 возникает, когда данные добавляются в таблицу в результате INSERT или UPDATE, и на страницу данных необходимо добавить новую строку. Если для него нет места, SQL Server реорганизует строки, перемещая некоторые строки на новую страницу данных и оставляя некоторые на старой странице данных. Это известно как разделение страниц . Хотя разбиение страниц - это обычное дело для SQL Server, слишком большое разбиение страниц может вызвать проблемы с производительностью, поскольку оно приводит к фрагментации индекса, как раз то, что мы пытаемся устранить с помощью задачи «Перестроить индекс».Чтобы смягчить эту проблему, администраторы баз данных часто уменьшают коэффициент заполнения, скажем, до 90, что означает, что страницы данных будут заполнены на 90%, оставляя 10% свободного места.
Дополнительную информацию о коэффициентах заполнения и разделении страниц см. В электронной документации. Полное обсуждение этих тем выходит за рамки данной статьи, но мне нужно было включить небольшую предысторию, чтобы вы лучше понимали, что происходит, когда вы делаете определенный выбор в мастере. Кроме того, не думайте, что пример 90, который я привожу в этом примере для коэффициента заполнения, подходит для ваших индексов.Может быть, а может и нет.
Что действительно сбивает с толку, так это то, что фраза «количество свободного места по умолчанию» в мастере не означает то же самое, что «коэффициент заполнения по умолчанию», который может быть установлен для всего сервера. Некоторые путают их.
В задаче «Перестроить индекс» «объем свободного пространства по умолчанию» относится к коэффициенту заполнения, который использовался при первом или последнем перестроении конкретного индекса. Другими словами, если вы выберете опцию «Реорганизовать страницы с объемом свободного места по умолчанию», произойдет то, что каждый индекс будет перестроен с использованием того значения коэффициента заполнения, которое использовалось при последнем перестроении.Это может быть то же самое, что и значение по умолчанию для всего сервера, или это может быть конкретное значение, указанное для этого индекса, или это может быть значение, установленное с помощью второй опции «Изменить процент свободного места на странице на» (обсуждается далее) .
Практически во всех случаях вы хотите использовать параметр «объем свободного пространства по умолчанию», поскольку он означает, что индекс будет перестроен с использованием коэффициента заполнения, который был первоначально указан при создании индекса.
При использовании второй опции «Изменить процент свободного места на странице на» вы указываете единственное значение коэффициента заполнения, которое будет использоваться для каждого индекса при его перестроении.Например, если вы выберете «Изменить процент свободного места на странице на» и установите его на 10%, это будет то же самое, что установить для всех индексов в вашей базе данных коэффициент заполнения 90, независимо от того, какое значение было, когда индекс был создан. Редко бывает, что каждый индекс в вашей базе данных имеет одинаковый коэффициент заполнения. Соответствующий коэффициент заполнения зависит от индекса, и вы не можете обобщить коэффициент заполнения, который будет хорошо работать для каждого индекса в вашей базе данных. Хотя этот параметр может быть полезен для некоторых индексов, он может вызвать проблемы с производительностью для других индексов.Поэтому я не рекомендую использовать эту опцию.
Конечно, выбор параметров по умолчанию «Реорганизовать страницы с размером свободного пространства по умолчанию» предполагает, что коэффициенты заполнения всех ваших индексов были идеально установлены при их первоначальном создании или последнем перестроении. Если нет, то остается только решить, какой вариант действительно лучше. Но предполагая, что вы не знаете, идеальны коэффициенты заполнения или нет, а вы, вероятно, не знаете, я все же рекомендую использовать этот параметр по умолчанию.
Две опции в Расширенные опции показаны на Рисунке 1.9.
Рисунок 1.9: Раздел «Дополнительные параметры» экрана
Задачи определения индекса восстановления.
По умолчанию оба параметра отключены. Первый - «Сортировать результаты в базе данных tempdb». Если не выберет , то при перестроении индекса все действия по перестроению будут выполняться в самом файле базы данных. Если вы выберете опцию «Сортировать результаты в базе данных tempdb», тогда некоторые действия по-прежнему будут выполняться в базе данных, но некоторые из них также будут выполняться в базе данных tempdb.Преимущество в том, что это часто может ускорить процесс восстановления индекса. Недостатком является то, что он также занимает немного больше общего дискового пространства, так как требуется пространство в базе данных tempdb в дополнение к некоторому пространству в базе данных, где восстанавливаются индексы.
Преимущество этой опции зависит от того, где на вашем сервере расположена база данных tempdb. Если tempdb находится на том же диске или массиве, что и файл базы данных, индексы которого перестраиваются, то преимущество может быть минимальным, если оно вообще есть.Однако, если база данных tempdb расположена на собственных изолированных шпинделях дисковода, преимущество будет больше, так как будет меньше конфликтов ввода-вывода на диск.
Итак, стоит ли вам использовать эту опцию? Если ваши базы данных небольшие, вы, вероятно, не сможете ощутить большой выигрыш в производительности, но если у вас большие базы данных с большими таблицами и индексами, и если tempdb находится на собственных шпинделях, то включение этой функции, вероятно, повысит производительность восстановления индекса.
Второй расширенный вариант, который мы обсуждали ранее: «Сохранять индекс в сети во время переиндексации».Этот параметр доступен только в том случае, если у вас есть Enterprise Edition SQL Server. При выборе этого параметра перестройка индекса становится оперативной, а не автономной задачей. Если вы используете Enterprise Edition, вы, вероятно, захотите выбрать этот вариант. Я говорю «возможно», потому что у выполнения перестроения индекса в режиме онлайн есть свои плюсы и минусы; тема, выходящая за рамки данной статьи.
Нашим последним шагом является определение подходящего расписания для запуска нашего задания Rebuild Index. Принимая во внимание предыдущий совет, лучшим вариантом было бы запускать задание в рамках ночного окна обслуживания.Однако во многих организациях доступен только один период еженедельного обслуживания, который часто составляет целый день воскресенья.
Поэтому давайте запланируем выполнение задачи Rebuild Index на воскресенье, сразу после завершения задачи Database Integrity. Таким образом, экран будет выглядеть, как показано на Рисунке 1.10.
Рисунок 1.10: Расписание для задания Rebuild Index
Единственный вопрос, который нам нужно рассмотреть, - как скоро после выполнения задачи проверки целостности базы данных нам следует запланировать задачу восстановления базы данных? Это зависит от того, сколько времени займет выполнение задачи «Проверка целостности базы данных», и мы не узнаем, пока не попробуем.
Поскольку это новый план обслуживания, у нас еще нет опыта в отношении того, как долго выполняется каждая задача, поэтому нам приходится гадать. В этом примере я предполагаю, что первая задача проверки целостности базы данных займет час, начиная с 1:00, поэтому я запланирую запуск задачи «Перестроить индекс» на 2:00. Если я ошибаюсь, два задания будут перекрываться, что может вызвать проблемы с производительностью.
Как администратор баз данных, при первом запуске любого плана обслуживания необходимо проверить, сколько времени требуется для выполнения каждого задания, чтобы избежать дублирования заданий.Если ваше предположение неверно и задания перекрываются, вы можете использовать конструктор планов обслуживания (описанный в моей книге), чтобы изменить расписание для следующего запуска.
Я рекомендую вам запустить задачу Rebuild Index перед выполнением любой из задач резервного копирования. Таким образом, если вам нужно восстановить резервную копию, ваша резервная копия будет последней версии с восстановленным индексом.
Фрагментация индекса - проблема, с которой сталкиваются все базы данных, и если ее не удалять на регулярной основе, это может привести к проблемам с производительностью запросов.Один из способов устранения фрагментации индекса - регулярный запуск задачи «Перестроить индекс», которая удаляет и перестраивает каждый индекс в базе данных. Хотя задача «Перестроить индекс» очень эффективна в том, что она делает, она считается автономной и требует значительных ресурсов. Таким образом, использование этой задачи может не всегда подходить для всех ваших баз данных.