Кодировка unicod: ✔️ ❤️ ★ Unicode Character Table
UTF-16 — UTF-16 — qaz.wiki
Кодирование Unicode с переменной шириной с использованием одной или двух 16-битных кодовых единиц
Схема базовой многоязычной плоскости как UCS-2 (щелкните, чтобы увеличить). Строки, показанные сплошным серым цветом (D8 – DF), используются в качестве суррогатных половин в UTF-16. | |
| Язык (и) | Международный |
|---|---|
| Стандарт | Стандарт Юникода |
| Классификация | Формат преобразования Unicode , кодирование переменной ширины |
| Расширяется | UCS-2 |
| Преобразует / кодирует | ISO 10646 ( Юникод ) |
UTF-16 (16- битный формат преобразования Unicode ) — это кодировка символов, способная кодировать все 1 112 064 действительных кодовых точки Unicode (фактически, это количество кодовых точек продиктовано конструкцией UTF-16).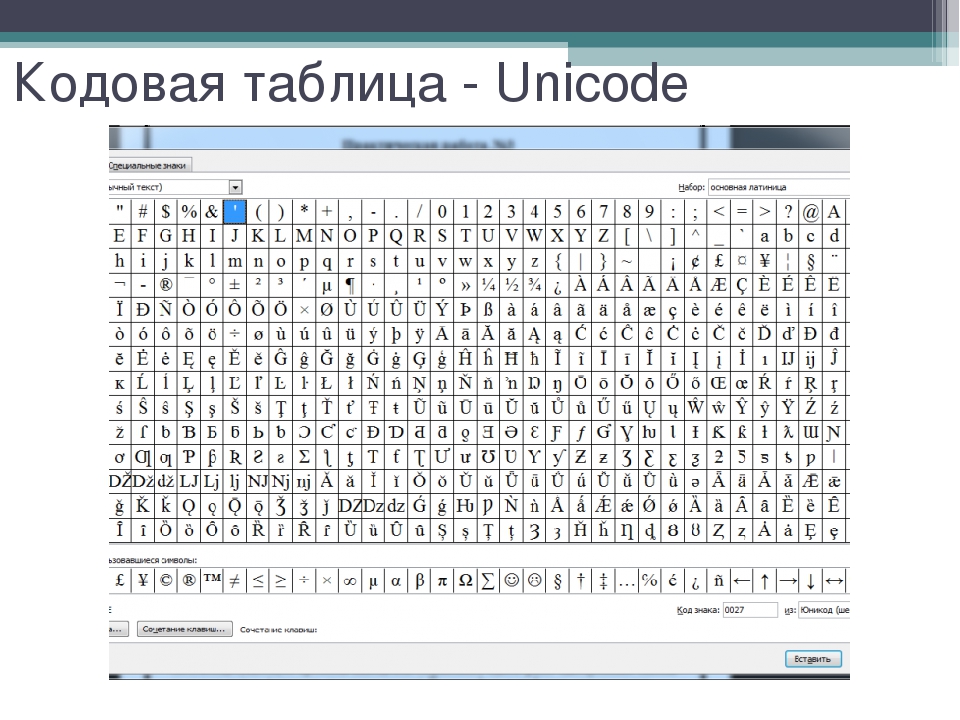 Кодирование имеет переменную длину , поскольку кодовые точки кодируются с помощью одной или двух 16-битных кодовых единиц . UTF-16 возник на основе более ранней 16-разрядной кодировки фиксированной ширины, известной как UCS-2 (для 2-байтового универсального набора символов), когда стало ясно, что требуется более 2 16 (65 536) кодовых точек.
Кодирование имеет переменную длину , поскольку кодовые точки кодируются с помощью одной или двух 16-битных кодовых единиц . UTF-16 возник на основе более ранней 16-разрядной кодировки фиксированной ширины, известной как UCS-2 (для 2-байтового универсального набора символов), когда стало ясно, что требуется более 2 16 (65 536) кодовых точек.
UTF-16 используется внутри таких систем, как Microsoft Windows , язык программирования Java и JavaScript / ECMAScript. Он также часто используется для обычного текста и файлов данных обработки текста в MS Windows. Он редко используется для файлов в Unix-подобных системах. По состоянию на май 2019 года Microsoft, похоже, изменила курс и теперь поддерживает и рекомендует использовать UTF-8 .
UTF-16 — единственная веб-кодировка, несовместимая с ASCII , и никогда не завоевывала популярность в Интернете, где ее используют менее 0,01% (1 сотая 1%) веб-страниц. Для сравнения, UTF-8 используется примерно 95% всех веб-страниц. Hypertext Application Technology Рабочая группа Web (WHATWG) считает UTF-8 «обязательное кодирование для всех [текст]» и что по соображениям безопасности приложений браузер не должны использовать UTF-16.
Hypertext Application Technology Рабочая группа Web (WHATWG) считает UTF-8 «обязательное кодирование для всех [текст]» и что по соображениям безопасности приложений браузер не должны использовать UTF-16.
История
В конце 1980-х годов началась работа по разработке единой кодировки для «универсального набора символов» ( UCS ), который заменит более ранние языковые кодировки единой скоординированной системой. Цель заключалась в том, чтобы включить все необходимые символы из большинства языков мира, а также символы из технических областей, таких как наука, математика и музыка. Первоначальная идея заключалась в замене типичных 256-символьных кодировок, которые требовали 1 байт на символ, кодировкой с использованием 65 536 (2 16 ) значений, что потребовало бы 2 байта (16 бит) на символ.
Две группы работали над этим параллельно: ISO / IEC JTC 1 / SC 2 и Unicode Consortium , последний представлял в основном производителей компьютерного оборудования. Обе группы попытались синхронизировать свои назначения символов, чтобы развивающиеся кодировки были взаимно совместимы. Раннее двухбайтовое кодирование первоначально называлось «Unicode», но теперь называется «UCS-2».
Раннее двухбайтовое кодирование первоначально называлось «Unicode», но теперь называется «UCS-2».
Когда стало все более ясно, что 2 16 символов недостаточно, IEEE ввел большее 31-битное пространство и кодировку ( UCS-4 ), которая потребовала бы 4 байта на символ. Консорциум Unicode сопротивлялся этому как потому, что 4 байта на символ занимали много памяти и дискового пространства, так и потому, что некоторые производители уже вложили значительные средства в технологию 2 байта на символ. Схема кодирования UTF-16 была разработана как компромисс и представлена в версии 2.0 стандарта Unicode в июле 1996 года. Она полностью указана в RFC 2781 , опубликованном в 2000 году IETF .
В кодировке UTF-16 кодовые точки меньше 2 16 кодируются с помощью одной 16-битной кодовой единицы, равной числовому значению кодовой точки, как в более старой UCS-2. Новые кодовые точки больше или равные 2 16 кодируются составным значением с использованием двух 16-битных кодовых единиц. Эти две 16-битные кодовые единицы выбираются из диапазона 0xD800–0xDFFF (который ранее не был назначен символам). Значения в этом диапазоне не используются в качестве символов, и UTF-16 не предоставляет законного способа кодировать их как отдельные кодовые точки. Таким образом, поток UTF-16 состоит из одиночных 16-битных кодовых точек за пределами этого диапазона (для кодовых точек в BMP) и пар 16-битных значений внутри этого диапазона (для кодовых точек выше BMP).
Эти две 16-битные кодовые единицы выбираются из диапазона 0xD800–0xDFFF (который ранее не был назначен символам). Значения в этом диапазоне не используются в качестве символов, и UTF-16 не предоставляет законного способа кодировать их как отдельные кодовые точки. Таким образом, поток UTF-16 состоит из одиночных 16-битных кодовых точек за пределами этого диапазона (для кодовых точек в BMP) и пар 16-битных значений внутри этого диапазона (для кодовых точек выше BMP).
UTF-16 указан в последних версиях как международного стандарта ISO / IEC 10646, так и стандарта Unicode. «UCS-2 теперь следует считать устаревшим. Он больше не относится к форме кодирования ни в 10646, ни в стандарте Unicode». С 2020 года нет планов по расширению UTF-16 для поддержки большего количества кодовых точек или замены кода суррогатами, поскольку это нарушит Политику стабильности Unicode в отношении общей категории или суррогатных кодовых точек. Примером идеи, которую можно было бы принять, было бы выделить другое значение BMP для префикса тройки суррогатов низкого, низкого и высокого уровня (при этом внутренний порядок поменялся местами, чтобы он не мог соответствовать суррогатной паре при поиске), что позволяет получить еще 2 30 кодовых точек.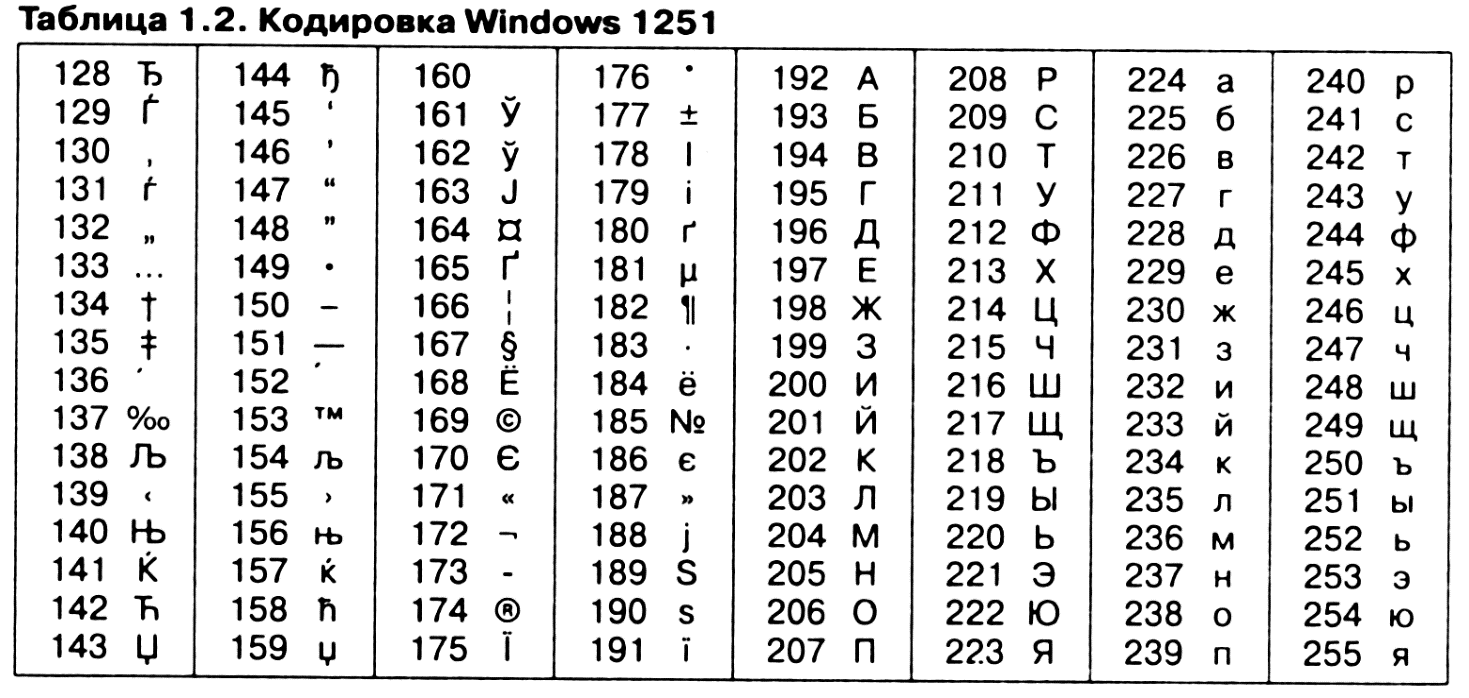 должны быть закодированы, однако изменение цели кодовой точки запрещено (использование префикса также запрещено, поскольку два из этих символов рядом друг с другом будут соответствовать суррогатной паре) или выделение двух плоскостей для суррогатов для еще 2 ² кодовых точек в восьми байтах в UTF-8 и UTF-16.
должны быть закодированы, однако изменение цели кодовой точки запрещено (использование префикса также запрещено, поскольку два из этих символов рядом друг с другом будут соответствовать суррогатной паре) или выделение двух плоскостей для суррогатов для еще 2 ² кодовых точек в восьми байтах в UTF-8 и UTF-16.
Описание
Каждый символ Unicode кодируется в виде одной или двух 16-битных кодовых единиц . То, как эти 16-битные коды хранятся как байты, зависит от порядка байтов текстового файла или протокола связи.
От U + 0000 до U + D7FF и от U + E000 до U + FFFF
И UTF-16, и UCS-2 кодируют кодовые точки в этом диапазоне как одиночные 16-битные кодовые единицы, которые численно равны соответствующим кодовым точкам. Эти кодовые точки в базовой многоязычной плоскости (BMP) являются единственными кодовыми точками, которые могут быть представлены в UCS-2. Начиная с Unicode 9.0, некоторые современные нелатинские азиатские, ближневосточные и африканские алфавиты выходят за пределы этого диапазона, как и большинство символов эмодзи .
Кодовые точки от U + 010000 до U + 10FFFF
Кодовые точки из других плоскостей (называемые дополнительными плоскостями ) кодируются как две 16-битные кодовые единицы, называемые суррогатной парой , по следующей схеме:
Низкий Высоко | DC00 | DC01 | … | DFFF |
|---|---|---|---|---|
| D800 | 010000 | 010001 | … | 0103FF |
| D801 | 010400 | 010401 | … | 0107FF |
| ⋮ | ⋮ | ⋮ | ⋱ | ⋮ |
| DBFF | 10FC00 | 10FC01 | … | 10FFFF |
- 0x10000 вычитается из кодовой точки (U) , оставляя 20-битное число (U ‘) в диапазоне шестнадцатеричных чисел 0x00000–0xFFFFF. Обратите внимание, что для этих целей значение U не должно превышать 0x10FFFF.

- Старшие десять битов (в диапазоне 0x000–0x3FF) добавляются к 0xD800, чтобы получить первую 16-битную кодовую единицу или старший заменитель (W1) , который будет находиться в диапазоне 0xD800–0xDBFF .
- Младшие десять битов (также в диапазоне 0x000–0x3FF) добавляются к 0xDC00, чтобы получить вторую 16-битную кодовую единицу или младший суррогат (W2) , который будет находиться в диапазоне 0xDC00–0xDFFF .

Визуально проиллюстрированное распределение U ‘ между W1 и W2 выглядит следующим образом:
U' = yyyyyyyyyyxxxxxxxxxx // U - 0x10000 W1 = 110110yyyyyyyyyy // 0xD800 + yyyyyyyyyy W2 = 110111xxxxxxxxxx // 0xDC00 + xxxxxxxxxx
Высокие суррогатный и низкие суррогатный также известны как «ведущий» и «задняя» суррогаты, соответственно, аналогичные передние и задние байты UTF-8.
Поскольку диапазоны для высоких суррогатов ( 0xD800–0xDBFF ), низких суррогатов ( 0xDC00–0xDFFF ) и допустимых символов BMP (0x0000–0xD7FF, 0xE000–0xFFFF) не пересекаются , суррогат не может соответствовать символу BMP, или чтобы две соседние кодовые единицы выглядели как законная суррогатная пара .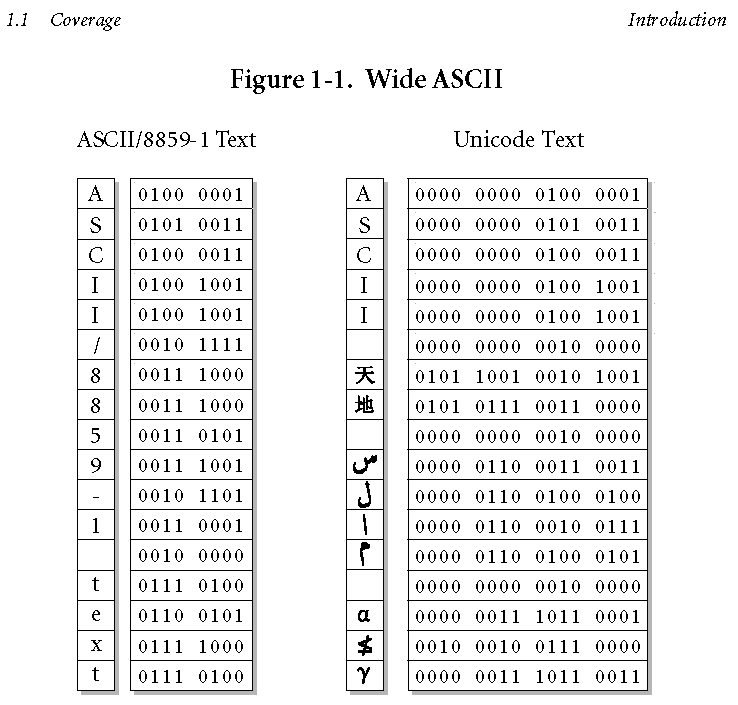 Это значительно упрощает поиск. Это также означает, что UTF-16 самосинхронизируется на 16-битных словах: может ли кодовая единица запускать символ, может быть определено без изучения более ранних кодовых единиц (т.е. тип кодовой единицы может быть определен диапазонами значений, в которых она падает). UTF-8 разделяет эти преимущества, но многие более ранние схемы многобайтового кодирования (такие как Shift JIS и другие азиатские многобайтовые кодировки) не допускали однозначного поиска и могли быть синхронизированы только путем повторного синтаксического анализа с начала строки (UTF -16 не является самосинхронизирующимся, если один байт потерян или если обход начинается со случайного байта).
Это значительно упрощает поиск. Это также означает, что UTF-16 самосинхронизируется на 16-битных словах: может ли кодовая единица запускать символ, может быть определено без изучения более ранних кодовых единиц (т.е. тип кодовой единицы может быть определен диапазонами значений, в которых она падает). UTF-8 разделяет эти преимущества, но многие более ранние схемы многобайтового кодирования (такие как Shift JIS и другие азиатские многобайтовые кодировки) не допускали однозначного поиска и могли быть синхронизированы только путем повторного синтаксического анализа с начала строки (UTF -16 не является самосинхронизирующимся, если один байт потерян или если обход начинается со случайного байта).
Поскольку все наиболее часто используемые символы находятся в BMP, обработка суррогатных пар часто не проверяется тщательно. Это приводит к постоянным ошибкам и потенциальным дырам в безопасности даже в популярном и хорошо изученном прикладном программном обеспечении (например, CVE — 2008-2938 , CVE- 2012-2135 ).
В Дополнительных Плоскостях содержат эмодзи , исторические сценарии, менее часто используемые символы, меньше используемую китайскую идеограмму и т.д. Поскольку кодирование дополнительных плоскостей содержит 20 старших бит (10 из 16 бит в каждом из высоких и низких суррогатов ), 2 20 кодовых точек могут быть закодированы, разделены на 16 плоскостей по 2 16 кодовых точек в каждой. Включая отдельно управляемый базовый многоязычный самолет, всего 17 самолетов.
U + D800 в U + DFFF
Стандарт Unicode постоянно резервирует эти значения кодовых точек для кодирования UTF-16 суррогатов высокого и низкого уровня, и им никогда не будет назначен символ, поэтому не должно быть причин для их кодирования. Официальный стандарт Unicode говорит, что никакие формы UTF, включая UTF-16, не могут кодировать эти кодовые точки.
Однако UCS-2, UTF-8 и UTF-32 могут кодировать эти кодовые точки тривиальными и очевидными способами, и большое количество программного обеспечения делает это, даже если в стандарте указано, что такие схемы следует рассматривать как ошибки кодирования.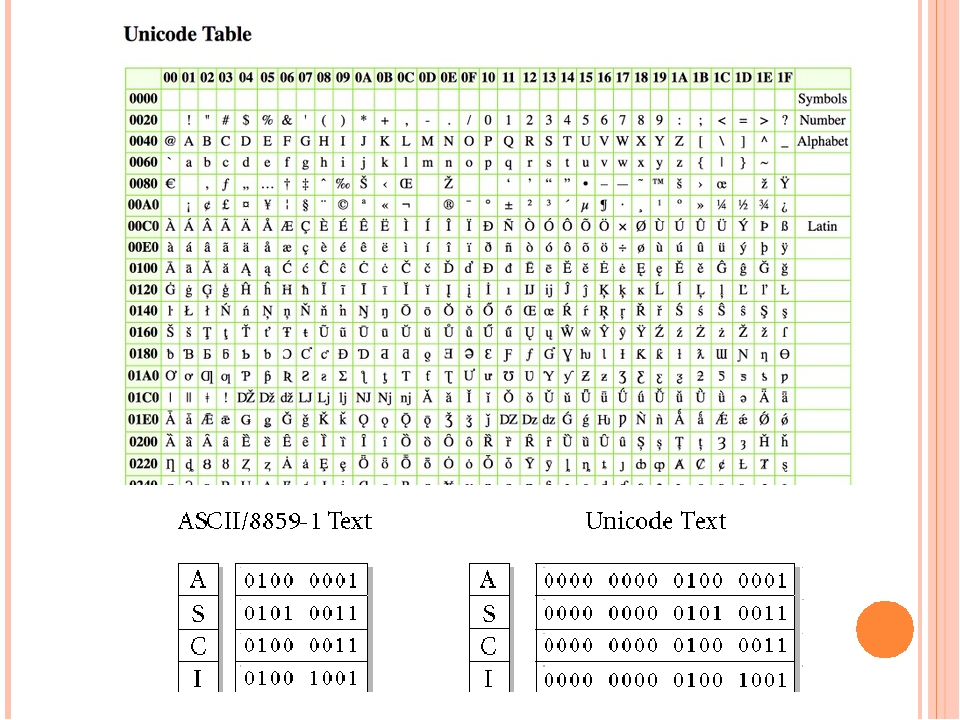
Можно однозначно закодировать непарный суррогат (высокий суррогатный код, за которым не следует низкий, или низкий, без предшествующего высокого) в UTF-16, используя кодовую единицу, равную кодовой точке. Большинство реализаций кодировщиков и декодеров UTF-16 делают это тогда при преобразовании между кодировками. Windows допускает непарные суррогаты в именах файлов и других местах, что обычно означает, что они должны поддерживаться программным обеспечением, несмотря на их исключение из стандарта Unicode.
Примеры
Чтобы кодировать U + 10437 (𐐷) в UTF-16:
- Вычтите 0x10000 из кодовой точки, оставив 0x0437.
- Для старшего суррогата сдвиньте вправо на 10 (разделите на 0x400), затем добавьте 0xD800, в результате получится 0x0001 + 0xD800 = 0xD801.
- Для младшего суррогата возьмите младшие 10 бит (остаток от деления на 0x400), затем добавьте 0xDC00, в результате получится 0x0037 + 0xDC00 = 0xDC37.
Чтобы декодировать U + 10437 (𐐷) из UTF-16:
- Возьмите старший суррогат (0xD801) и вычтите 0xD800, затем умножьте на 0x400, в результате получится 0x0001 × 0x400 = 0x0400.
- Возьмите младший суррогат (0xDC37) и вычтите 0xDC00, в результате получится 0x37.
- Сложите эти два результата вместе (0x0437) и, наконец, добавьте 0x10000, чтобы получить окончательную декодированную кодовую точку UTF-32, 0x10437.

В следующей таблице приведены данные об этом, а также о других преобразованиях. Цвета показывают, как биты из кодовой точки распределяются между байтами UTF-16. Дополнительные биты, добавленные в процессе кодирования UTF-16, показаны черным.
| символ | Двоичный код | Двоичный UTF-16 | Единицы шестнадцатеричного кода UTF-16 | UTF-16BE шестнадцатеричные байты | Шестнадцатеричные байты UTF-16LE | |
|---|---|---|---|---|---|---|
| $ | U+0024 | 0000 0000 0010 0100 | 0000 0000 0010 0100 | 0024 | 00 24 | 24 00 |
| € | U+20AC | 0010 0000 1010 1100 | 0010 0000 1010 1100 | 20AC | 20 AC | AC 20 |
| 𐐷 | U+10437 | 0001 0000 0100 0011 0111 | 1101 1000 0000 0001 1101 1100 0011 0111 | D801 DC37 | D8 01 DC 37 | 01 D8 37 DC |
| 𤭢 | U+24B62 | 0010 0100 1011 0110 0010 | 1101 1000 0101 0010 1101 1111 0110 0010 | D852 DF62 | D8 52 DF 62 | 52 D8 62 DF |
Схемы кодирования порядка байтов
UTF-16 и UCS-2 создают последовательность из 16-битных кодовых единиц. Поскольку большинство протоколов связи и хранения определены для байтов, и каждый блок, таким образом, занимает два 8-битных байта, порядок байтов может зависеть от порядка байтов (порядок байтов) архитектуры компьютера.
Поскольку большинство протоколов связи и хранения определены для байтов, и каждый блок, таким образом, занимает два 8-битных байта, порядок байтов может зависеть от порядка байтов (порядок байтов) архитектуры компьютера.
Чтобы помочь в распознавании порядка байтов кодовых единиц, UTF-16 позволяет метке порядка байтов (BOM), кодовой точке со значением U + FEFF, предшествовать первому фактическому кодированному значению. (U + FEFF — это невидимый неразрывный пробел нулевой ширины / символ ZWNBSP.) Если конечная архитектура декодера совпадает с архитектурой кодера, декодер обнаруживает значение 0xFEFF, но обратный конечный декодер интерпретирует спецификацию как несимвольное значение U + FFFE зарезервировано для этой цели. Этот неверный результат дает подсказку для выполнения замены байтов для оставшихся значений.
Если спецификация отсутствует, RFC 2781 рекомендует использовать кодировку с прямым порядком байтов. На практике, из-за того, что Windows по умолчанию использует прямой порядок следования байтов, многие приложения предполагают обратную кодировку.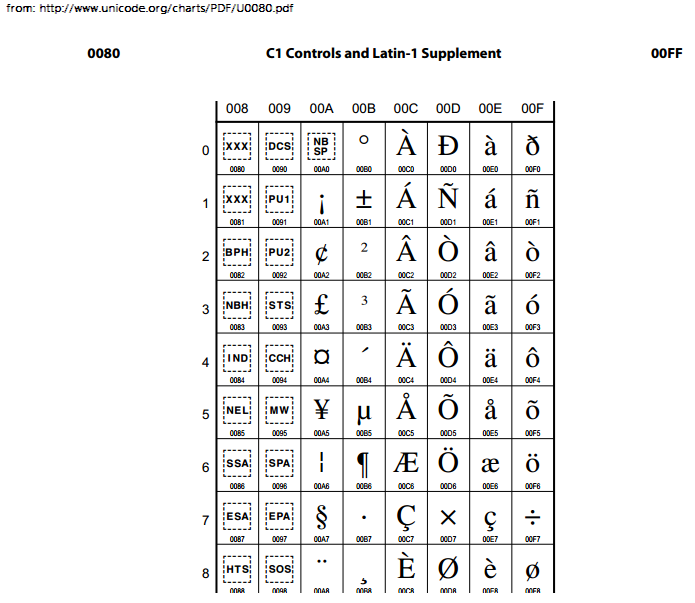 Также надежно обнаруживать порядок байтов путем поиска нулевых байтов при условии, что символы меньше U + 0100 очень распространены. Если большее количество четных байтов (начиная с 0) равны нулю, то это обратный порядок байтов.
Также надежно обнаруживать порядок байтов путем поиска нулевых байтов при условии, что символы меньше U + 0100 очень распространены. Если большее количество четных байтов (начиная с 0) равны нулю, то это обратный порядок байтов.
Стандарт также позволяет явно указывать порядок байтов, указывая UTF-16BE или UTF-16LE в качестве типа кодировки. Когда порядок байтов указан явно таким образом, спецификация специально не должна добавляться к тексту, а U + FEFF в начале следует обрабатывать как символ ZWNBSP. Большинство приложений игнорируют спецификации во всех случаях, несмотря на это правило.
Для интернет- протоколов IANA утвердила «UTF-16», «UTF-16BE» и «UTF-16LE» в качестве имен для этих кодировок (имена регистронезависимы). Псевдонимы UTF_16 или UTF16 могут иметь значение в некоторых языках программирования или программных приложениях, но они не являются стандартными именами в Интернет-протоколах.
Подобные обозначения, UCS-2BE и UCS-2LE , используются для отображения версий UCS-2 .
Применение
UTF-16 используется для текста в API ОС всех поддерживаемых в настоящее время версий Microsoft Windows (включая по крайней мере все, начиная с Windows CE / 2000 / XP / 2003 / Vista / 7 ), включая Windows 10 . Начиная с инсайдерской сборки 17035 и апрельского обновления 2018 года в нее добавлена поддержка UTF-8, и с мая 2019 года Microsoft рекомендует программному обеспечению использовать ее вместо UTF-16. Старые системы Windows NT (до Windows 2000) поддерживают только UCS-2. В Windows XP код выше U + FFFF не входит ни в один шрифт, поставляемый с Windows для европейских языков. Файлы и сетевые данные, как правило, представляют собой смесь кодировок UTF-16, UTF-8 и устаревших байтовых кодировок.
Я IBM операционная система определяет CCSID ( код страницы ) 13488 для UCS-2 кодирования и CCSID 1200 для UTF-16 кодировке, хотя система обрабатывает их обоих , как UTF-16.
UTF-16 используется операционными системами Qualcomm BREW ; в .NET среды; и инструментарий кроссплатформенных графических виджетов Qt .
ОС Symbian, используемая в телефонах Nokia S60 и Sony Ericsson UIQ, использует UCS-2. Мобильные телефоны iPhone используют UTF-16 для службы коротких сообщений вместо UCS-2, описанного в стандартах 3GPP TS 23.038 ( GSM ) и IS-637 ( CDMA ).
Joliet файловой системы , используется в CD-ROM СМИ, кодирует имена файлов с использованием UCS-2be (до шестидесяти четырех символов Unicode в имени файла).
Python языковая среда официально использует только UCS-2 внутри , начиная с версии 2.0, но декодер UTF-8 «Unicode» производит правильно UTF-16. Начиная с Python 2.2, поддерживаются «широкие» сборки Unicode, которые вместо этого используют UTF-32; в основном они используются в Linux. Python 3.3 больше никогда не использует UTF-16, вместо этого кодировка, которая дает наиболее компактное представление для данной строки, выбирается из ASCII / Latin-1, UCS-2 и UTF-32.
Первоначально в Java использовался UCS-2, а в J2SE 5.0 добавлена поддержка дополнительных символов UTF-16 .
JavaScript может использовать UCS-2 или UTF-16. Начиная с ES2015, в язык были добавлены строковые методы и флаги регулярных выражений, которые позволяют обрабатывать строки с точки зрения независимого от кодирования.
Во многих языках строки в кавычках нуждаются в новом синтаксисе для цитирования не-BMP символов, поскольку "\uXXXX"синтаксис в стиле C явно ограничивает себя 4 шестнадцатеричными цифрами. Следующие ниже примеры иллюстрируют синтаксис символа не-BMP «𝄞» (U + 1D11E, МУЗЫКАЛЬНЫЙ СИМВОЛ G CLEF). Наиболее распространенным (используемым C ++ , C # , D и некоторыми другими языками) является использование заглавной буквы «U» с 8 шестнадцатеричными цифрами, например "\U0001D11E". В регулярных выражениях Java 7, ICU и Perl "\x{1D11E}"необходимо использовать синтаксис ; аналогично, в ECMAScript 2015 (JavaScript) escape-формат равен "\u{1D11E}". Во многих других случаях (например, в Java вне регулярных выражений) единственный способ получить символы, отличные от BMP, — это ввести суррогатные половинки индивидуально, например: "\uD834\uDD1E"для U + 1D11E.
Реализации строк, основанные на UTF-16, обычно определяют длину строки и позволяют индексацию в терминах этих 16-битных кодовых единиц , а не в терминах кодовых точек. Ни кодовые точки, ни кодовые единицы не соответствуют чему-либо, что конечный пользователь мог бы распознать как «символ»; то, что пользователи идентифицируют как символы, обычно может состоять из базовой кодовой точки и последовательности комбинируемых символов (или может быть последовательностью кодовых точек какого-либо другого типа, например, хангыль, соединяющий джамос) — Unicode называет эту конструкцию графемой cluster — и поэтому приложения, работающие со строками Unicode, независимо от кодировки, должны справляться с тем фактом, что это ограничивает их способность произвольно разбивать и комбинировать строки.
UCS-2 также поддерживается языком PHP и MySQL.
Swift версии 5, предпочтительный язык приложений Apple, переключился с UTF-16 на UTF-8 в качестве предпочтительной кодировки.
Смотрите также
Примечания
Ссылки
внешние ссылки
Уникод — это… Что такое Уникод?
Методы ввода
Поскольку ни одна раскладка клавиатуры не может позволить вводить все символы Юникода одновременно, от операционных систем и прикладных программ требуется поддержка альтернативных методов ввода произвольных символов Юникода.
Microsoft Windows
Начиная с Windows 2000, служебная программа «Таблица символов» показывает все символы в ОС и позволяет копировать их в буфер обмена. Похожая таблица есть, например, в Word-е.
Иногда можно набрать шестнадцатеричный код, нажать Alt+X и код будет заменён на соответствующий символ, например, в
Для ввода в десятеричном виде можно с нажатым Alt-ом набрать код на цифровой клавиатуре, в шестнадцатеричном виде — можно выставить (по умолчанию отсутствующее) строковое значение реестра HKEY_Current_User\Control Panel\Input Method\EnableHexNumpad в «1», перезагрузиться, а затем, зажав Alt и нажав «+» справа, набрать код. В разных местах Windows комбинации с Alt-ом работают по-разному, например в блокноте Alt-937 даст «й» (в CP866 это символ с кодом 169=937 mod 256), Alt-0937 даст «©» (169 в Latin-1), а уже Alt-Plus-3a9 даст «Ω» из Юникода (3a916=937). В WordPad-е и Word-е по-любому будет «Ω». А в консоли сюрприз.
В разных местах Windows комбинации с Alt-ом работают по-разному, например в блокноте Alt-937 даст «й» (в CP866 это символ с кодом 169=937 mod 256), Alt-0937 даст «©» (169 в Latin-1), а уже Alt-Plus-3a9 даст «Ω» из Юникода (3a916=937). В WordPad-е и Word-е по-любому будет «Ω». А в консоли сюрприз.
Mac OS 8.5 и более поздних версиях поддерживается метод ввода, называемый «Unicode Hex Input». При зажатой клавише Option требуется набрать четырёхзначный шестнадцатеричный код требуемого символа. Этот метод позволяет вводить символы с кодами, большими U+FFFF, используя пары суррогатов; такие пары операционной системой будут автоматически заменены на одиночные символы. Этот метод ввода перед использованием нужно активизировать в соответствующем разделе системных настроек, и затем выбрать как текущий метод ввода в меню клавиатуры.
Начиная с Mac OS X 10.2, существует также приложение «Character Palette», позволяющее выбирать символы из таблицы, в которой можно выделять символы определённого блока или символы, поддерживаемые конкретным шрифтом.
GNU/Linux
В ISO 14755: при зажатых клавишах Ctrl и Shift ввести шестнадцатеричный код (в GNOME версии 2.15 или более поздней ввод кода нужно предварить нажатием клавиши «U»). Вводимый шестнадцатеричный код может иметь до 32 бит в длину, позволяя вводить любые символы Юникода без использования суррогатных пар.
Все приложения X Window, включая GNOME и Compose, для этой цели можно назначить любую клавишу — например, Caps Lock.
Консоль GNU/Linux также допускает ввод символа Юникода по его коду — для этого десятичный код символа нужно ввести цифрами расширенного блока клавиатуры при зажатой клавише Alt. Можно вводить символы и по их шестнадцатеричному коду: для этого нужно зажать клавишу AltGr, и для ввода цифр A—F использовать клавиши расширенного блока клавиатуры от NumLock до Enter (по часовой стрелке). Поддерживается также и ввод в соответствии с ISO 14755. Для того, чтобы перечисленные способы могли работать, нужно включить юникодный режим консоли вызовом unicode_start(1) и выбрать подходящий шрифт вызовом setfont(8).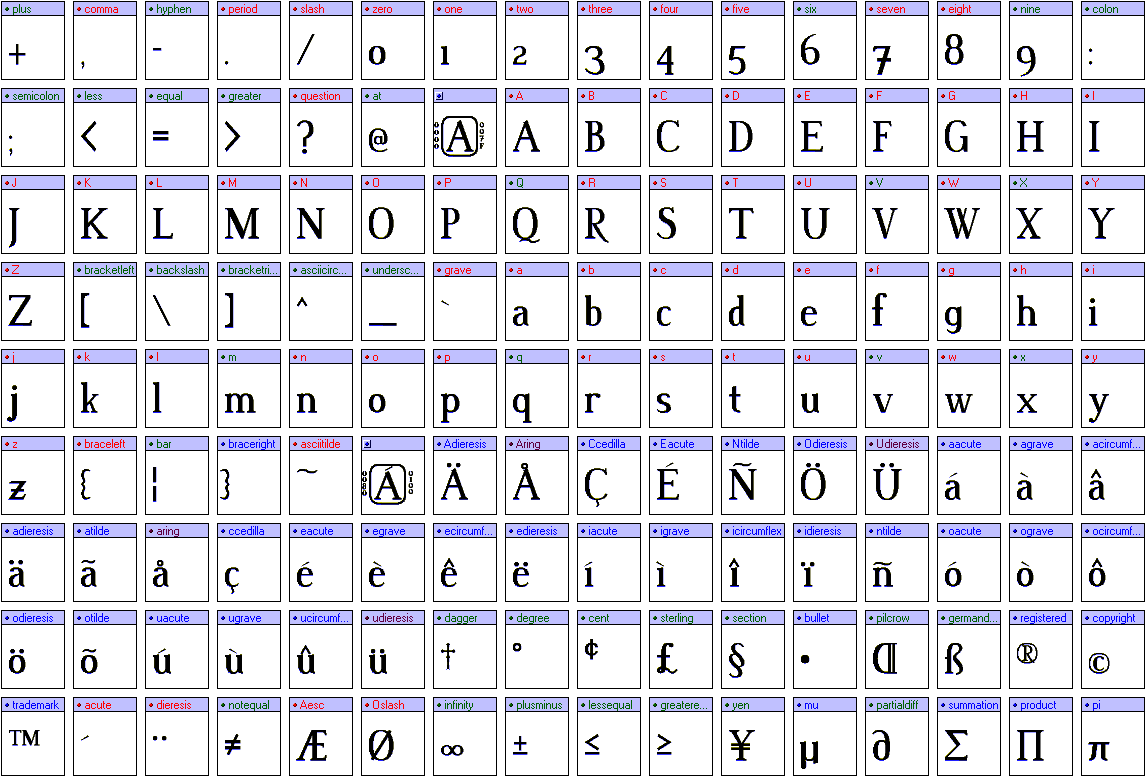
Mozilla Firefox для GNU/Linux поддерживает ввод символов по ISO 14755.
Проблемы Юникода
Как любая изобретённая человеком система, Юникод не лишён недостатков (хотя, в основном, они связаны с возможностями обработчиков текста, а не непосредственно с принципом кодирования).
- Некоторые системы письма всё ещё не представлены должным образом в Юникоде. Изображение «длинных» надстрочных символов, простирающихся над несколькими буквами, как например, в церковнославянском языке, пока не реализовано.
- Тексты на китайском, корейском и японском языке имеют традиционное написание сверху вниз, начиная с правого верхнего угла. Переключение горизонтального и вертикального написания для этих языков не предусмотрено в Юникоде — это должно осуществляться средствами языков разметки или внутренними механизмами текстовых процессоров.
- Первоначальная версия Юникода предполагала наличие большого количества готовых символов, в последующем было отдано предпочтение сочетанию букв с диакритическими модифицирующими знаками (Combining diacritics). Например, русские буквы Ё (U+0401) и Й (U+0419) существуют в виде монолитных символов, хотя могут быть представлены и набором базового символа с последующим диакритическим знаком, то есть в составной форме (Decomposed): Е+ ̈ (U+0415 U+0308), И+ ̆ (U+0418 U+0306). В то же время множество символов из языков с алфавитами на основе кириллицы не имеют монолитных форм.
- Юникод предусматривает возможность разных начертаний одного и того же символа в зависимости от языка. Так, китайские иероглифы могут иметь разные начертания в китайском, японском (кандзи) и корейском (ханчча), но при этом в Юникоде обозначаться одним и тем же символом (так называемая CJK-унификация), хотя упрощённые и полные иероглифы всё же имеют разные коды. Часто возникают накладки, когда, например, японский текст выглядит «по-китайски». Аналогично, русский и сербский языки используют разное начертание курсивных букв п и т (в сербском они выглядят как и и ш, см. сербский курсив). Поэтому нужно следить, чтобы текст всегда был правильно помечен как относящийся к тому или другому языку.
- Даже перевод из строчных букв в заглавные зависит от языка. Например: в турецком существуют буквы İi и Iı — таким образом, турецкие правила конвертации регистра конфликтуют с английскими, которые предписывают «i» переводить в «I».
- Файлы с текстом в Юникоде занимают больше места в памяти, так как один символ кодируется не одним байтом, как в различных национальных кодировках, а последовательностью байтов (исключение составляет UTF-8 для языков, алфавит которых укладывается в ASCII).[2] Однако с увеличением мощности компьютерных систем и удешевлением памяти и дискового пространства эта проблема становится всё менее существенной.
- Хотя поддержка Юникода реализована в наиболее распространённых операционных системах, не всё прикладное программное обеспечение поддерживает корректную работу с ним. В частности, не всегда обрабатываются метки BOM и плохо поддерживаются диакритические символы. Проблема является временной и есть следствие сравнительной новизны стандартов Юникода (в сравнении с однобайтовыми национальными кодировками).
 Например, русские буквы Ё (U+0401) и Й (U+0419) существуют в виде монолитных символов, хотя могут быть представлены и набором базового символа с последующим диакритическим знаком, то есть в составной форме (Decomposed): Е+ ̈ (U+0415 U+0308), И+ ̆ (U+0418 U+0306). В то же время множество символов из языков с алфавитами на основе кириллицы не имеют монолитных форм.
Например, русские буквы Ё (U+0401) и Й (U+0419) существуют в виде монолитных символов, хотя могут быть представлены и набором базового символа с последующим диакритическим знаком, то есть в составной форме (Decomposed): Е+ ̈ (U+0415 U+0308), И+ ̆ (U+0418 U+0306). В то же время множество символов из языков с алфавитами на основе кириллицы не имеют монолитных форм.«Юникод» или «Уникод»?
«Unicode» — одновременно и имя собственное (или часть имени, например Unicode Consortium), и имя нарицательное, происходящее из английского языка.
На первый взгляд предпочтительнее использовать написание «Уникод». В русском языке уже есть морфемы «уни-» (слова с латинским элементом «uni-» традиционно переводились и писались через «уни-»: универсальный, униполярный, унификация, униформа) и «код». Напротив, торговые марки, заимствованные из английского языка, обычно передаются посредством практической транскрипции, в которой деэтимологизированное сочетание букв «uni-» записывается в виде «юни-» («Юнилевер», «Юникс» и т. п.), то есть точно так же, как в случае с побуквенными сокращениями, вроде UNICEF «United Nations International Children’s Emergency Fund» — ЮНИСЕФ.
В качестве перевода имени нарицательного, слово «уникод» можно было бы рассматривать как сложносокращённое — например, от выражения «универсальная кодировка». Однако это привело бы к появлению двух слов с похожим звучанием и колебанию значений. Поэтому при локализации операционной системы Windows 95 компания «Майкрософт» ввела написание русского слова «Юникод» по форме имени собственного.
Написание «Юникод» уже твёрдо вошло в русскоязычные тексты. Согласно «Яндексу», частота использования этого слова в 33 раза превышает «Уникод». В Википедии используется более распространённый вариант.
На сайте консорциума есть специальная страница, где рассматриваются проблемы передачи слова «Unicode» в различных языках и системах письма. Для русской кириллицы указан вариант «Юникод».
Формы, принятые иностранными организациями для русской передачи слова «Unicode», являются рекомендательными.
Примечания
- ↑ http://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt(англ.)
- ↑ Однако в некоторых случаях текст в Юникоде может занимать существенно меньше места, чем текст в однобайтовой кодировке. Например, если некая веб-страница содержит примерно поровну русского и греческого текста, то в однобайтовой кодировке придётся либо русские, либо греческие буквы записывать в виде кодов с амперсэндом, которые занимают 6—7 байт на символ (при использовании десятичных кодов), т. е. в среднем на букву придётся 3,5—4 байта, в то время как UTF-8 занимает только 2 байта на греческую или русскую букву.
См. также
Ссылки
Wikimedia Foundation.
2010.
УНИКОД — это… Что такое УНИКОД?
Методы ввода
Поскольку ни одна раскладка клавиатуры не может позволить вводить все символы Юникода одновременно, от операционных систем и прикладных программ требуется поддержка альтернативных методов ввода произвольных символов Юникода.
Microsoft Windows
Начиная с Windows 2000, служебная программа «Таблица символов» показывает все символы в ОС и позволяет копировать их в буфер обмена. Похожая таблица есть, например, в Word-е.
Иногда можно набрать шестнадцатеричный код, нажать Alt+X и код будет заменён на соответствующий символ, например, в
Для ввода в десятеричном виде можно с нажатым Alt-ом набрать код на цифровой клавиатуре, в шестнадцатеричном виде — можно выставить (по умолчанию отсутствующее) строковое значение реестра HKEY_Current_User\Control Panel\Input Method\EnableHexNumpad в «1», перезагрузиться, а затем, зажав Alt и нажав «+» справа, набрать код. В разных местах Windows комбинации с Alt-ом работают по-разному, например в блокноте Alt-937 даст «й» (в CP866 это символ с кодом 169=937 mod 256), Alt-0937 даст «©» (169 в Latin-1), а уже Alt-Plus-3a9 даст «Ω» из Юникода (3a916=937). В WordPad-е и Word-е по-любому будет «Ω». А в консоли сюрприз.
Mac OS 8.5 и более поздних версиях поддерживается метод ввода, называемый «Unicode Hex Input». При зажатой клавише Option требуется набрать четырёхзначный шестнадцатеричный код требуемого символа. Этот метод позволяет вводить символы с кодами, большими U+FFFF, используя пары суррогатов; такие пары операционной системой будут автоматически заменены на одиночные символы. Этот метод ввода перед использованием нужно активизировать в соответствующем разделе системных настроек, и затем выбрать как текущий метод ввода в меню клавиатуры.
Начиная с Mac OS X 10.2, существует также приложение «Character Palette», позволяющее выбирать символы из таблицы, в которой можно выделять символы определённого блока или символы, поддерживаемые конкретным шрифтом.
GNU/Linux
В ISO 14755: при зажатых клавишах Ctrl и Shift ввести шестнадцатеричный код (в GNOME версии 2.15 или более поздней ввод кода нужно предварить нажатием клавиши «U»). Вводимый шестнадцатеричный код может иметь до 32 бит в длину, позволяя вводить любые символы Юникода без использования суррогатных пар.
Все приложения X Window, включая GNOME и Compose, для этой цели можно назначить любую клавишу — например, Caps Lock.
Консоль GNU/Linux также допускает ввод символа Юникода по его коду — для этого десятичный код символа нужно ввести цифрами расширенного блока клавиатуры при зажатой клавише Alt. Можно вводить символы и по их шестнадцатеричному коду: для этого нужно зажать клавишу AltGr, и для ввода цифр A—F использовать клавиши расширенного блока клавиатуры от NumLock до Enter (по часовой стрелке). Поддерживается также и ввод в соответствии с ISO 14755. Для того, чтобы перечисленные способы могли работать, нужно включить юникодный режим консоли вызовом unicode_start(1) и выбрать подходящий шрифт вызовом setfont(8).
Mozilla Firefox для GNU/Linux поддерживает ввод символов по ISO 14755.
Проблемы Юникода
Как любая изобретённая человеком система, Юникод не лишён недостатков (хотя, в основном, они связаны с возможностями обработчиков текста, а не непосредственно с принципом кодирования).
- Некоторые системы письма всё ещё не представлены должным образом в Юникоде. Изображение «длинных» надстрочных символов, простирающихся над несколькими буквами, как например, в церковнославянском языке, пока не реализовано.
- Тексты на китайском, корейском и японском языке имеют традиционное написание сверху вниз, начиная с правого верхнего угла. Переключение горизонтального и вертикального написания для этих языков не предусмотрено в Юникоде — это должно осуществляться средствами языков разметки или внутренними механизмами текстовых процессоров.
- Первоначальная версия Юникода предполагала наличие большого количества готовых символов, в последующем было отдано предпочтение сочетанию букв с диакритическими модифицирующими знаками (Combining diacritics). Например, русские буквы Ё (U+0401) и Й (U+0419) существуют в виде монолитных символов, хотя могут быть представлены и набором базового символа с последующим диакритическим знаком, то есть в составной форме (Decomposed): Е+ ̈ (U+0415 U+0308), И+ ̆ (U+0418 U+0306). В то же время множество символов из языков с алфавитами на основе кириллицы не имеют монолитных форм.
- Юникод предусматривает возможность разных начертаний одного и того же символа в зависимости от языка. Так, китайские иероглифы могут иметь разные начертания в китайском, японском (кандзи) и корейском (ханчча), но при этом в Юникоде обозначаться одним и тем же символом (так называемая CJK-унификация), хотя упрощённые и полные иероглифы всё же имеют разные коды. Часто возникают накладки, когда, например, японский текст выглядит «по-китайски». Аналогично, русский и сербский языки используют разное начертание курсивных букв п и т (в сербском они выглядят как и и ш, см. сербский курсив). Поэтому нужно следить, чтобы текст всегда был правильно помечен как относящийся к тому или другому языку.
- Даже перевод из строчных букв в заглавные зависит от языка. Например: в турецком существуют буквы İi и Iı — таким образом, турецкие правила конвертации регистра конфликтуют с английскими, которые предписывают «i» переводить в «I».
- Файлы с текстом в Юникоде занимают больше места в памяти, так как один символ кодируется не одним байтом, как в различных национальных кодировках, а последовательностью байтов (исключение составляет UTF-8 для языков, алфавит которых укладывается в ASCII).[2] Однако с увеличением мощности компьютерных систем и удешевлением памяти и дискового пространства эта проблема становится всё менее существенной.
- Хотя поддержка Юникода реализована в наиболее распространённых операционных системах, не всё прикладное программное обеспечение поддерживает корректную работу с ним. В частности, не всегда обрабатываются метки BOM и плохо поддерживаются диакритические символы. Проблема является временной и есть следствие сравнительной новизны стандартов Юникода (в сравнении с однобайтовыми национальными кодировками).
«Юникод» или «Уникод»?
«Unicode» — одновременно и имя собственное (или часть имени, например Unicode Consortium), и имя нарицательное, происходящее из английского языка.
На первый взгляд предпочтительнее использовать написание «Уникод». В русском языке уже есть морфемы «уни-» (слова с латинским элементом «uni-» традиционно переводились и писались через «уни-»: универсальный, униполярный, унификация, униформа) и «код». Напротив, торговые марки, заимствованные из английского языка, обычно передаются посредством практической транскрипции, в которой деэтимологизированное сочетание букв «uni-» записывается в виде «юни-» («Юнилевер», «Юникс» и т. п.), то есть точно так же, как в случае с побуквенными сокращениями, вроде UNICEF «United Nations International Children’s Emergency Fund» — ЮНИСЕФ.
В качестве перевода имени нарицательного, слово «уникод» можно было бы рассматривать как сложносокращённое — например, от выражения «универсальная кодировка». Однако это привело бы к появлению двух слов с похожим звучанием и колебанию значений. Поэтому при локализации операционной системы Windows 95 компания «Майкрософт» ввела написание русского слова «Юникод» по форме имени собственного.
Написание «Юникод» уже твёрдо вошло в русскоязычные тексты. Согласно «Яндексу», частота использования этого слова в 33 раза превышает «Уникод». В Википедии используется более распространённый вариант.
На сайте консорциума есть специальная страница, где рассматриваются проблемы передачи слова «Unicode» в различных языках и системах письма. Для русской кириллицы указан вариант «Юникод».
Формы, принятые иностранными организациями для русской передачи слова «Unicode», являются рекомендательными.
Примечания
- ↑ http://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt(англ.)
- ↑ Однако в некоторых случаях текст в Юникоде может занимать существенно меньше места, чем текст в однобайтовой кодировке. Например, если некая веб-страница содержит примерно поровну русского и греческого текста, то в однобайтовой кодировке придётся либо русские, либо греческие буквы записывать в виде кодов с амперсэндом, которые занимают 6—7 байт на символ (при использовании десятичных кодов), т.7 (=128) различных комбинаций * . Это означает, что мы можем представить максимум 128 символов.
Подожди, 7 бит? Но почему не 1 байт (8 бит)?
Последний бит (8-й) используется для избежания ошибок в качестве бита четности .
Это было актуально много лет назад.Большинство символов ASCII являются печатными символами алфавита, такими как abc, ABC, 123,?&!, прием. Другие-это управляющие символы , такие как возврат каретки , подача строки, вкладка и т. д.
Смотрите ниже двоичное представление нескольких символов в ASCII:
0100101 -> % (Percent Sign - 37) 1000001 -> A (Capital letter A - 65) 1000010 -> B (Capital letter B - 66) 1000011 -> C (Capital letter C - 67) 0001101 -> Carriage Return (13)Смотрите полную таблицу ASCII здесь .
ASCII предназначалось только для английского языка.
Что? Почему только английский? Там так много языков!
Потому что в то время центр компьютерной индустрии находился в USA году
время.7, как раньше (128).10000010 -> é (e with acute accent - 130) 10100000 -> á (a with acute accent - 160)Имя для этого «ASCII extended to 8 bits and not 7 bits as before» может быть просто указано как «extended ASCII» или «8-bit ASCII».
Как указал @Tom в своем комментарии ниже, нет такого понятия, как «расширенный ASCII», но это простой способ сослаться на этот 8-битный трюк. Существует много вариантов 8-битной таблицы ASCII, например, ISO 8859-1, также называемой ISO Latin-1 .
Unicode, Подъем
ASCII Extended решает эту проблему для языков, основанных на латинском алфавите… а как насчет других, которым нужен совершенно другой алфавит? Греческий? Русский? Китайцы и им подобные?
Нам бы понадобился совершенно новый набор символов… это и есть рациональное начало Unicode. Unicode не содержит все символы из каждого языка, но он уверен, что содержит огромное количество символов ( см. эту таблицу ).
Вы не можете сохранить текст на жесткий диск как «Unicode». Unicode-это абстрактное представление текста. Вам нужно «encode» это абстрактное представление. Вот где кодировка вступает в игру.
Кодировки: UTF-8 vs UTF-16 vs UTF-32
Этот ответ делает довольно хорошую работу по объяснению основ:
- UTF-8 и UTF-16 являются кодировками переменной длины.
- В UTF-8 символ может занимать не менее 8 бит.
- В UTF-16 длина символа начинается с 16 бит.
- UTF-32-это кодировка фиксированной длины в 32 бита.
UTF-8 использует набор ASCII для первых 128 символов. Это удобно, потому что означает, что текст ASCII также действителен в UTF-8.
Мнемоника:
- UTF-8: минимум 8 бит.
- UTF-16: минимум 16 бит.
- UTF — 32 : минимальную и максимальную 32 бита.
Примечание:
Почему 2^7?
Для некоторых это очевидно, но на всякий случай.7 = 128 комбинации. Подумайте об этом как о кодовом замке с семью колесами, каждое колесо имеет только два номера.
Источник: Википедия и этот замечательный пост в блоге .
encoding — Начало работы с кодировкой
замечания
Что такое кодировка и как она работает?
Компьютер не может хранить буквы или что-то еще — он хранит бит. Бит может быть 0 или 1 («да» / «нет», «истина» / «ложь» — эти форматы называются двоичными, поэтому). Чтобы использовать эти биты, необходимы некоторые правила, чтобы преобразовать биты в некоторый контент. Там правила называются кодировками , где последовательности из 1/0 бит обозначают определенные символы. Последовательность из 8 бит называется байтом .
Кодировки работают как таблицы, где каждый символ связан с конкретным байтом. Чтобы закодировать что-то в кодировке ASCII, следует следовать за строками справа налево, ища биты, относящиеся к символам. Чтобы декодировать строку бит в символы, один заменяет биты для букв слева направо.
Байты могут быть представлены в разных форматах: например,
10011111в двоичном формате —237в восьмеричном,159в десятичной и9Fв шестнадцатеричных форматах.В чем разница между разными кодировками?
Кодировка первого символа, такая как ASCII с пред-8-разрядной эры, использовала только 7 бит из 8. ASCII использовался для кодирования английского языка со всеми 26 буквами в форме нижнего и верхнего регистра, цифрами и множеством знаков препинания. ASCII не мог охватить другие европейские языки всеми буквами
ö-ß-é-å— поэтому были разработаны кодировки, которые использовали 8-й бит байта для охвата еще 128 символов.Но одного байта недостаточно, чтобы представлять языки с более чем 256 символами — например, китайцами. Использование двух байтов (16 бит) позволяет кодировать 65 536 различных значений. Такие кодировки, как BIG-5, разделяют строку бит на блоки из 16 бит (2 байта) для кодирования символов. Многобайтовые кодировки имеют преимущество в отношении пространства, но недостаток этих операций, таких как поиск подстрок, сравнений и т. Д., Должен декодировать символы в кодах Юникода, прежде чем такие операции могут быть выполнены (есть некоторые ярлыки, хотя ).
Другим типом кодирования являются такие переменные количества байтов на символ, как, например, стандарты UTF. Эти стандарты имеют некоторый размер блока, который для UTF-8 составляет 8 бит, для UTF-16 — 16 бит, а для UTF-32 — 32 бита. И тогда стандарт определяет некоторые биты как флаги: если они установлены, то следующий блок в последовательности единиц должен считаться частью одного и того же символа. Если они не установлены, это устройство полностью отображает только один символ (например, английский занимает только один байт, и поэтому кодировка ASCII полностью соответствует UTF-8).
Что такое Юникод?
Unicode, если огромный набор символов (говоря более понятным образом — таблица) с 1,114,112 кодовыми точками, каждый из них обозначает конкретную букву, символ или другой символ. Используя Unicode, вы можете написать документ, содержащий теоретически любой язык, используемый людьми.
Unicode не является кодировкой — это набор кодовых точек. И есть несколько способов кодирования кодовых точек Unicode в биты — например, UTF-8, -16 и -32.
Как определить кодировку текстового файла с помощью Python?
В Python-chardet есть полезный пакет, который помогает обнаружить кодировку, используемую в вашем файле. На самом деле нет никакой программы, которая может сказать со 100% уверенностью, какая кодировка была использована — вот почему chardet дает кодировку с наивысшей вероятностью, в которой был закодирован файл. Chardet может обнаруживать следующие кодировки:
- ASCII, UTF-8, UTF-16 (2 варианта), UTF-32 (4 варианта)
- Big5, GB2312, EUC-TW, HZ-GB-2312, ISO-2022-CN (традиционный и упрощенный китайский)
- EUC-JP, SHIFT_JIS, CP932, ISO-2022-JP (японский)
- EUC-KR, ISO-2022-KR (корейский)
- KOI8-R, MacCyrillic, IBM855, IBM866, ISO-8859-5, windows-1251 (кириллица)
- ISO-8859-2, windows-1250 (венгерский)
- ISO-8859-5, windows-1251 (болгарский)
- windows-1252 (английский)
- ISO-8859-7, windows-1253 (греческий)
- ISO-8859-8, windows-1255 (визуальный и логический иврит)
- TIS-620 (тайский)
Вы можете установить chardet с командой pip :
pip install chardetПосле этого вы можете использовать символ в командной строке:
% chardetect somefile someotherfile somefile: windows-1252 with confidence 0.5 someotherfile: ascii with confidence 1.0или в python:
import chardet rawdata = open(file, "r").read() result = chardet.detect(rawdata) charenc = result['encoding']Установка или настройка
Подробные инструкции по настройке или установке кодировки.
HTML Кодировки
Чтобы правильно отобразить html-документ, браузер должен знать какая кодировка символов использовалась при создании документа.
ASCII — одна из самых старых компьютерных кодировок, в которой каждому символу соответствует строго определенное число. Например, символу «a» соответствует число 97, а символу «A» — число 65.
Эта аббревиатура расшифровывается как American Standard Code for Information Interchange (американская стандартная кодировочная таблица для печатных символов и некоторых специальных кодов).
ASCII — это однобайтовая кодировка, в которую изначально заложено всего 128 символов: буквы латинского алфавита, арабские цифры и т.д.
Вы можете посмотреть на полный комплект Печатаемых символов ASCII.Позже ASCII была расширена (изначально она не использовала все 8 бит), поэтому появилась возможность использовать уже не 128, а 256 (2 в 8 степени) различных символов, которые можно закодировать в одном байте информации.
Такое усовершенствование позволило добавлять в кодировку ASCII символы национальных языков разных стран, помимо уже существующей латиницы.
Вариантов расширенной кодировки ASCII существует очень много по причине того, что языков в мире тоже немало. Думаю, что многие из вас слышали о такой кодировке, как KOI8 (Код Обмена Информацией, 8 бит) — это тоже расширенная кодировка ASCII. KOI8 включала в себя цифры, буквы латинского и русского алфавита, а также знаки пунктуации, спецсимволы и псевдографику.Кодировка ISO
Организация Международных стандартов (International Standards Organization) создала диапазон кодировок для различных алфавитов/языков.
Кодировки серии ISO 8859
Кодировка Описание ISO 8859-1 (Latin-1) Расширенная латиница, включающая символы большинства западноевропейских языков (английский, датский, ирландский, исландский, испанский, итальянский, немецкий, норвежский, португальский, ретороманский, фарерский, шведский, шотландский (гэльский) и частично голландский, финский, французский), а также некоторых восточноевропейских (албанский) и африканских языков (африкаанс, суахили). В Latin-1 отсутствуют знак евро и заглавная буква Ÿ. Эта кодовая страница считается кодировкой по умолчанию для HTML-документов и сообщений электронной почты. Также этой кодовой странице соответствуют первые 256 символов Юникода. ISO 8859-2 (Latin-2) Расширенная латиница, включающая символы центральноевропейских и восточноевропейских языков (боснийский, венгерский, польский, словацкий, словенский, хорватский, чешский). В Latin-2, как и в Latin-1, отсутствуют знак евро. ISO 8859-3 (Latin-3) Расширенная латиница, включающая символы южноевропейских языков (мальтийский, турецкий и эсперанто). ISO 8859-4 (Latin-4) Расширенная латиница, включающая символы североевропейских языков (гренландский, эстонский, латышский, литовский и саамские языки). ISO 8859-5 (Latin/Cyrillic) Кириллица, включающая символы славянских языков (белорусский, болгарский, македонский, русский, сербский и частично украинский). ISO 8859-6 (Latin/Arabic) Символы, используемые в арабском языке. Символы других языков с письмом на основе арабского не поддерживаются. Для корректного отображения текста в кодировке ISO 8859-6 требуется поддержка двунаправленного письма и контекстно-зависимых форм символов. ISO 8859-7 (Latin/Greek) Символы современного греческого языка. Может использоваться также для записи древнегреческих текстов в монотонической орфографии. ISO 8859-8 (Latin/Hebrew) Символы современного иврита. Используется в двух вариантах: с логическим порядком следования символов (требует поддержки двунаправленного письма) и с визуальным порядком следования символов. ISO 8859-9 (Latin-5) Вариант Latin-1, в котором редко используемые символы исландского языка заменены на турецкие. Используется для турецкого и курдского языков. ISO 8859-10 (Latin-6) Вариант Latin-4, более удобный для скандинавских языков. ISO 8859-11 (Latin/Thai) Символы тайского языка. ISO 8859-13 (Latin-7) Вариант Latin-4, более удобный для балтийских языков. ISO 8859-14 (Latin-8) Расширенная латиница, включающая символы кельтских языков, таких как шотландский (гэльский) и бретонский. ISO 8859-15 (Latin-9) Вариант Latin-1, в котором редко используемые символы заменены на необходимые для полной поддержки финского, французского и эстонского языков. Кроме того, в Latin-9 был добавлен знак евро. ISO 8859-16 (Latin-10) Расширенная латиница, включающая символы южноевропейских и восточноевропейских (албанский, венгерский, итальянский, польский, румынский, словенский, хорватский), а также некоторых западноевропейских языков (ирландский в новой орфографии, немецкий, финский, французский). Как и в Latin-9, в Latin-10 был добавлен знак евро. Для документов на английском и большинстве других западноевропейских языков, широко поддерживается кодирование ISO-8859-1.
Таблица кодов символов ISO-8859-1
В HTML ISO-8859-1 является кодировкой по умолчанию (в XHTML и в HTML5 кодировкой по умолчанию является UTF-8).
При использовании кодировки страницы, отличной от ISO-8859-1, вам необходимо указать это в теге <meta>.Для HTML4:
<meta http-equiv="Content-Type" content="text/html;charset=ISO-8859-1">Для HTML5:
<meta charset="UTF-8">Примером ANSI-кодировки является всем известная Windows-1251.
Windows-1251 выгодно отличается от других 8 битных кириллических кодировок (таких как CP866 и ISO 8859-5) наличием практически всех символов, использующихся в русской типографике для обычного текста (отсутствует только знак ударения). Она также содержит все символы для других славянских языков: украинского, белорусского, сербского, македонского и болгарского.
Ниже приведены десятичные значения символов кодировки Windows-1251.Для отображения символов таблицы в HTML-документе воспользуйтесь следующим синтаксисом:
&# + код + ;Кодировка Windows-1251 (CP1251)
.0 .1 .2 .3 .4 .5 .6 .7 .8 .9 .A .B .C .D .E .F
8.
Ђ
402Ѓ
403‚
201Aѓ
453„
201E…
2026†
2020‡
2021€
20AC‰
2030Љ
409‹
2039Њ
40AЌ
40CЋ
40BЏ
40F
9.
ђ
452‘
2018’
2019“
201C”
201D•
2022–
2013—
2014™
2122љ
459›
203Aњ
45Aќ
45Cћ
45Bџ
45F
A.
A0Ў
40Eў
45EЈ
408¤
A4Ґ
490¦
A6§
A7Ё
401©
A9Є
404«
AB¬
AC
AD®
AEЇ
407
B.
°
B0±
B1І
406і
456ґ
491µ
B5¶
B6·
B7ё
451№
2116є
454»
BBј
458Ѕ
405ѕ
455ї
457
C.
А
410Б
411В
412Г
413Д
414Е
415Ж
416З
417И
418Й
419К
41AЛ
41BМ
41CН
41DО
41EП
41F
D.
Р
420С
421Т
422У
423Ф
424Х
425Ц
426Ч
427Ш
428Щ
429Ъ
42AЫ
42BЬ
42CЭ
42DЮ
42EЯ
42F
E.
а
430б
431в
432г
433д
434е
435ж
436з
437и
438й
439к
43Aл
43Bм
43Cн
43Dо
43Eп
43F
F.
р
440с
441т
442у
443ф
444х
445ц
446ч
447ш
448щ
449ъ
44Aы
44Bь
44Cэ
44Dю
44Eя
44FТаблица кодов символов Windows-1251
Кодировки стандарта UNICODE
Юникод (англ. Unicode) — стандарт кодирования символов, позволяющий представить знаки почти всех письменностей мира, и специальных символов. Представляемые в юникоде символы кодируются целыми числами без знака. Юникод имеет несколько форм представления символов в компьютере: UTF-8, UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). (Англ. Unicode transformation format — UTF).
UTF-8 — это в настоящее время распространённая кодировка, которая нашла широкое применение в операционных системах и веб-пространстве. Текст, состоящий из символов Unicode с номерами меньше 128 (область с кодами от U+0000 до U+007F), содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F.Кодировка UTF-8 является универсальной и имеет внушительный резерв на будущее. Это делает ее наиболее удобной кодировкой для использования в интернете.
Таблица кодов символов UTF-8 кирилица
Unicode HOWTO — документация Python 3.3.7
История кодов персонажей
В 1968 году Американский стандартный код обмена информацией, более известный
его аббревиатура ASCII была стандартизирована. Цифровые коды ASCII для различных
символов с числовыми значениями от 0 до 127. Например,
строчной букве «а» присвоено 97 как ее кодовое значение.ASCII был стандартом, разработанным в Америке, поэтому он определял только безударные
символы. Там было «е», но не было «é» или «».Это означало, что языки
для которых требовались символы с диакритическими знаками, которые не могли быть точно представлены в ASCII.
(На самом деле отсутствующие акценты имеют значение и для английского языка, который содержит такие слова
как «наивный» и «кафе», а в некоторых публикациях есть домашние стили, требующие
варианты написания, такие как «coöperate».)Какое-то время люди просто писали программы, в которых не было акцентов.
В середине 1980-х годов программа Apple II BASIC, написанная французом.
могут быть такие строки:ПРИНТ «FICHIER EST COMPLETE." ПЕЧАТЬ «КАРАКТЕР НЕ ПРИНИМАЕТСЯ».
Эти сообщения должны содержать акценты (complete, caractère, accepté),
и они просто не подходят тому, кто умеет читать по-французски.В 1980-х почти все персональные компьютеры были 8-битными, а это означало, что байты могли
содержат значения от 0 до 255. Коды ASCII увеличились только до 127, поэтому некоторые
машины присвоили акцентированным символам значения от 128 до 255. Разные
однако машины имели разные коды, что приводило к проблемам при обмене файлами.Со временем появились различные обычно используемые наборы значений для диапазона 128–255.
Некоторые из них были настоящими стандартами, определенными Международной организацией по стандартизации,
а некоторые были де-факто конвенций, которые были изобретены одной компанией или
другой и удалось завоевать популярность.255 символов — это немного. Например, вы не можете разместить оба акцентированных
символы, используемые в Западной Европе, и кириллица, используемая для русского языка
в диапазон 128–255, потому что таких символов больше 127.16 = доступно 65 536 различных значений, что делает возможным
для представления множества разных символов из разных алфавитов; начальный
цель заключалась в том, чтобы Unicode содержал alUTF-8 Encoding
Сводка
UTF-8 — это компромиссная кодировка символов, которая может быть столь же компактной
как ASCII (если файл представляет собой обычный текст на английском языке), но также может содержать
любые символы юникода (с некоторым увеличением размера файла).UTF — это формат преобразования Unicode.’8′ означает, что он использует 8-битные блоки для
представляют собой персонажа. Количество блоков, необходимых для представления персонажа, варьируется от
От 1 до 4.Одной из действительно хороших особенностей UTF-8 является то, что он совместим со строками с завершающим нулем.
При кодировании ни один символ не будет иметь нулевой (0) байт. Это означает, что код C, имеющий дело с
char [] будет «просто работать».Вы можете попробовать тестовую страницу UTF-8, чтобы увидеть, насколько хорошо
ваш браузер (и шрифт по умолчанию) поддерживает UTF-8.Если вы разработчик приложений, то эта статья Joel On Software о Unicode
— довольно хорошее резюме всего, что вам нужно знать.Дополнительные ссылки:
Деталь
Для любого символа, равного или меньше 127 (шестнадцатеричный 0x7F), представление UTF-8
это один байт. Это всего лишь младшие 7 бит полного значения Unicode.
Это также то же самое, что и значение ASCII.Для символов, равных или меньше 2047 (шестнадцатеричный 0x07FF), представление UTF-8
распространяется на два байта. В первом байте будут установлены два старших бита и
третий бит очищен (т.е. от 0xC2 до 0xDF). Второй байт будет иметь
установлен верхний бит, а второй бит очищен (т.е.е. От 0x80 до 0xBF).Для всех символов, равных или больше 2048, но меньше 65535 (0xFFFF), представление UTF-8
распространяется на три байта.В следующей таблице показан формат таких байтовых последовательностей UTF-8 (где
«свободные биты», обозначенные в таблице значками x, объединяются в
порядок показан и интерпретируется от наиболее значимого до наименее значимого).Двоичный формат байтов в последовательности
1-й байт 2-й байт 3-й байт 4-й байт Количество свободных битов Максимальное выражаемое значение Unicode 0xxxxxxx 7 007F шестигранник (127) 110xxxxx 10xxxxxx (5 + 6) = 11 07FF шестигранник (2047) 1110xxxx 10xxxxxx 10xxxxxx (4 + 6 + 6) = 16 FFFF шестигранник (65535) 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx (3 + 6 + 6 + 6) = 21 10FFFF шестигранник (1,114,111) Значение каждого отдельного байта указывает его UTF-8
— RIN.RU
кодировка HTML-кодировка XML-.
, MIME, Windows.
Юникод (UTF-7) utf-7 csUnicode11UTF7, unicode-utf_7, unicode-1-1-utf-7, unicode-2- 0-utf-7, x-unicode-2-0-utf-7 65000 Unicode (UTF-8) utf-8 unicode-utf_8, unicode-utf_8-1_1, unicode-1 -1-utf-8, unicode-2-0-utf-8, x-unicode-2-0-utf-8 65001 Unicode (UTF-16) unicode-utf_16 csUnicode11, csUnicodeASCII, csUnicodeLatin1, ISO-10646-UCS-2, ISO-10646-UCS-BASIC, ISO-10646-Unicode-Latin1, ISO-10646, ISO-10646-J-1, unicode-utf_16-1.1 Unicode (UTF-32) unicode-utf_32 ISO-10646-UCS-4 (ASMO 708) ASMO-708 708 (DOS) DOS-720 720 (ISO) iso-8859-6 csISOLatinArabic, iso-ir-127, ISO_8859-6, ISO_8859-6: 1987, iso- 8859_6-1999, ECMA-114, арабский 28596 (Windows) windows-1256 cp1256, windows-1256-2000 1256 (Latin-4) iso-8859 -4 csISOLatin4, iso-ir-110, ISO_8859-4, ISO_8859-4: 1988, iso-8859_4-1988, l4, latin4 28594 (Windows) windows-1257 windows- 1257-2000 1257 (Windows) окна-1258 окна-1258-2 000 1258 (ISO) iso-8859-7 csISOLatinGreek, iso-ir-126, ISO_8859-7, ISO_8859-7: 1987, iso-8859_7-1987, ECMA-118, ELOT_928, греческий, греческий8 28597 (Windows) windows-1253 windows-1253-2000, x-cp1253 1253 (Latin-3) iso-8859-3 iso-8859_3-1999 28593 (Latin-6) iso-8859-10 iso-8859_10-1999 (Latin-7) iso-8859-13 iso-8859_13-1999 (Latin-9) iso-8859-15 iso-8859_15-1999 28605 (ASCII) us-ascii ANSI_X3.4-1968, ANSI_X3.4-1986, cp367, csASCII, IBM367, iso-ir-6, ISO646-US, ISO_646.irv: 1991, ascii, us, us-ascii-1968, x-ansi 20127 (Latin-1) iso-8859-1 cp819, ibm819, iso-ir-100, iso8859-1, iso_8859-1, iso_8859-1: 1987, iso-8859_1-1998, ISO-8859- 1-Windows-3.0-Latin-1, ISO-8859-1-Windows-3.1-Latin-1, latin1, l1 29591 (Mac) мак-роман-2000 x-mac-roman 10000 (Windows) окна-1252 1252 (ДОС) ДОС-862 862 (ISO-) iso-8859-8 csISOLatinHebrew, iso-ir-138, ISO_8859-8, iso-8859_8-1999, ISO-8859-8 Visual, visual, иврит 28598 (ISO-) iso-8859-8-i 38598 (Windows) окна-1255 ISO_8859-8: 1988, iso-ir-138, логический, windows-1255-2000 1255 (латиница-8) iso-8859-14 iso-8859_14-1999 (ДОС) cp866 ibm866 866 (ISO) iso-8859-5 csISOLatinCyrillic, iso-ir-144, ISO_8859-5, ISO_8859-5: 1988, iso-8859_5-1999, кириллица 28595 (Mac) mac-кириллица-2000 x-mac-кириллица 10007 (Windows) окна-1251 csWindows31Latin5, iso-8859-5-windows-latin-5, windows-1251-2000, x-cp1251 1251 (8-) кои8-р csKOI8R, koi, ru-koi8_r-2000 20866 — (EUC) x-euc-tw osf-euc_tw-2000 51950 — (Windows) большой5 csBig5, CN-Big5, windows-950, windows-950-2000, x-x-big5 950 — (ГБ2312) гб2312 csGB2312, csISO58GB23128, iso-ir-58, GB2312, GBK, GB_2312-80, GB-3212-2000, китайский, CN-GB, CN-GB-ISOIR165 936 — (Гц) гц-гб-2312 52936 (EUC) евро csEUCKR, ks_c_5601, kcs5601, osf-euc_kr-2000 51949 (ISO) iso-2022-kr csISO2022KR, posix-2022_kr 50225 (Windows) ks_c_5601-1987 csKSC56011987, корейский, windows-949, windows-949-2000 949 (Windows) iso-8859-11 окна-874, окна-874-2000 874 (ISO) iso-8859-9 csISOLatin5, iso-ir-148, l5, ISO_8859-9, ISO_8859-9: 1989, iso-8859_9-1999, latin5 28599 Редактировать текст и файлы Unicode UTF-16 и UTF-8 в UltraEdit
Участков в этом наконечнике:
Хотя UltraEdit и UEStudio включают обработку файлов и символов Unicode, вам необходимо убедиться, что редактор правильно настроен для обработки отображения данных Unicode.В этом руководстве мы рассмотрим некоторые основы данных в кодировке Unicode, а также способы их просмотра и управления в UltraEdit.
Краткий обзор Unicode
Чтобы понять, как работает Unicode, вам нужно сначала понять, как работает кодировка . Любой текстовый файл, содержащий данные, которые вы открываете и редактируете в UltraEdit, отображается с использованием кодировки. Проще говоря, кодирование — это то, как необработанные двоичные данные файла (нули и единицы, составляющие файл на диске) интерпретируются и отображаются в редакторе как разборчивый текст, которым можно управлять с помощью клавиатуры.Вы можете думать о кодировании как о типе «кольца декодера» для языка кода. Поскольку мы знаем, что все на нашем компьютере состоит из нулей и единиц (вспомните The Matrix ), вы можете визуализировать, как работает кодирование, просмотрев следующую диаграмму.
Unicode — это кодировка, разработанная много лет назад некоторыми умными разработчиками с целью сопоставить большинство письменных символов мира с одним набором кодировок. Практическая выгода от этой цели заключается в том, что любой пользователь в любом месте может просматривать китайские сценарии, английские буквенно-цифровые символы, русский и арабский текст — все в одном файле и без необходимости вручную изменять кодировку (кодовую страницу) для каждого конкретного текста. .До Unicode вам, вероятно, пришлось бы выбирать другую кодовую страницу для просмотра каждого сценария, если бы сценарий даже имел кодовую страницу и шрифт, который ее поддерживал, и вы не могли бы просматривать несколько языков / сценариев в одном файле вообще.
Тим Брей в своей статье «О достоинствах Unicode» объясняет Unicode простыми словами:
На самом деле основы Unicode довольно просты. Он определяет большое (и постоянно растущее) количество символов — чуть более 100000, когда я проверял в последний раз.Каждый символ получает имя и кодовую точку , например, ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A — это 0041, а ТИБЕТСКИЙ СИЛЛАБНЫЙ OM — 0F00. Unicode включает в себя таблицу полезных свойств символов, таких как «это строчные буквы», «это число» или «это знак препинания».
(Примечание : На момент обновления этой полезной подсказки 2 ноября 2018 г. в Юникоде содержится ровно 137 374 символа.)
Итак, с учетом этих знаний, обновленная диаграмма того, как работает кодирование Unicode, показана ниже:
Каждая кодировка работает так же, как показано на диаграмме выше, но каждая кодировка (обычно) дает разные результаты по сравнению с тем, что отображается в редакторе.Unicode — это очень надежная кодировка, которая отображает большинство доступных для записи языков в мире сегодня.
Разница между UTF-8, UTF-16 и т. Д.
Поскольку Unicode включает в себя сотни тысяч символов, для каждого символа требуется несколько байтов. Зачем? Как вы, наверное, уже знаете, в мире компьютеров один байт состоит из 8 бит. Бит — это самая основная и самая маленькая часть электронных данных, которая может принимать значение 0 или 1 (или «выключено» / «включено»). Это означает, что один байт может быть одной из 256 возможных комбинаций битов.Это означает, что вы можете поддерживать только до 256 символов с кодировкой, которая использует один байт для каждого из этих символов. Очевидно, вам понадобится экспоненциально больше комбинаций, чем 256 для поддержки всех символов в мире.
Чтобы удовлетворить это требование, разработчики Unicode внедрили двухбайтовую систему символов, но даже это не обеспечило достаточного количества возможных комбинаций для всех символов мира! Но решить эту проблему было не так просто, как просто увеличить ее до трех или четырех байтов на символ из-за соображений памяти и пространства — если каждый символ в текстовом файле требует 4 байта дискового пространства (или пространства памяти, если он загружен в память), вы, по сути, в увеличите в четыре раза объема пространства, необходимого для хранения данных! Это совсем не эффективно.
UTF-16 был разработан в качестве альтернативы, используя 16 бит (или 2 байта) на символ. Если вы занимаетесь математикой, вы уже поняли, что расчеты пространства по-прежнему невелики, и все еще существует вероятность большого количества потраченного впустую пространства с данными в кодировке UTF-16, особенно если вы когда-либо используете только символы, которые используйте всего 8 бит (или 1 байт). Кроме того, поскольку UTF-16 полагается на 16-битный символ, многие существующие программы и приложения должны были добавить специальную отдельную поддержку (по сути, дублируя весь их код обработки текста) для UTF-16, поскольку они были разработаны для поддержки 8-битных символов.Если текст поступал в программу в какой-либо другой кодировке, он обрабатывался бы обычным кодом обработки текста, который разработчик написал для 8-битных символов. Если бы он вошел как UTF-16, он прошел бы через специальный код UTF-16 — если бы разработчик даже написал для него код! Как вы понимаете, написание кода для обработки этих двух разных типов байтовых архитектур для кодирования символов может привести к довольно запутанному коду.
К счастью, версия Unicode под названием UTF-8 была разработана для экономии места и оптимизации размера данных символов Unicode (и, следовательно, размера файла), не требуя жесткого выделения 16 бит на символ.UTF-8 означает «Формат преобразования Unicode в 8-битном формате». Да, как вы уже догадались — большая разница между UTF-16 и UTF-8 в том, что UTF-8 возвращается к стандарту 8-битных символов вместо 16. Это означает, что он (в основном) совместим с существующими системами и программами, которые разработаны для обработки байта как 8 бит.
Кроме того, UTF-8 по-прежнему включает набор символов Unicode, но его система хранения символов отличается и улучшена по сравнению с моделью UTF-16 «каждый символ получает 16 бит».UTF-8 назначает разное количество байтов разным символам — один символ может использовать только один байт (8 бит), а другой — четыре. Наиболее часто используемым символам были присвоены одно- и двухбайтовые комбинации, что означает, что для большинства людей размер данных не становится слишком большим с UTF-8.
Единственным недостатком этого является то, что системе требуется больше вычислительной мощности, интерпретирующей данные , закодированные в UTF-8, поскольку не каждый символ представлен одинаковым количеством байтов.Но эта дополнительная обработка незначительна для общей производительности.
Существуют и другие кодировки Unicode, такие как UTF-32 и UTF-7, но UTF-8 — самый популярный и широко используемый сегодня формат Unicode. Большинство баз данных SQL и веб-сайтов, которые вы видите, закодированы в UTF-8, и, фактически, в 2008 году Google заявил, что UTF-8 стала наиболее распространенной кодировкой для файлов HTML. Поэтому, если вы спросите нас, мы также рекомендуем формат кодировки UTF-8 при работе с Unicode в UltraEdit и UEStudio!
Для получения дополнительной информации о Unicode прочтите следующие статьи:
И, конечно же, не забудьте посетить официальный сайт Unicode для получения более подробной информации и обновлений Unicode.
Настроить UltraEdit для правильного открытия файлов Unicode
Уф! Теперь, когда мы разобрались с историей и основами Unicode, как нам настроить UltraEdit для обработки текстовых файлов Unicode?
Если у вас есть файлы Unicode, которые вы хотите открыть в UltraEdit, вам необходимо убедиться, что вы настроили UltraEdit на обнаружение и отображение Unicode. Все это можно настроить в Advanced » Settings » File Handling » Encoding .Здесь есть 2 настройки, которые важны для обработки Unicode в UltraEdit.
Кодировка по умолчанию (для новых файлов и открытия файла при сбое автоопределения)
Этот параметр позволяет вам установить кодировку по умолчанию для новых файлов и кодировку, которую UltraEdit должен выбрать, когда он не может автоматически определить кодировку, изначально использованную для создания файла. Другими словами, что UltraEdit должен «предположить» за файл, если иначе он не сможет это понять? Если вы много работаете с данными Unicode, мы рекомендуем установить для него значение UTF-8.Помните, что стандартом de facto для Unicode является UTF-8, и все больше и больше компьютерного мира движется в этом направлении.
Самое замечательное в UTF-8 заключается в том, что его первые 256 символов побайтно совпадают с 256 символами самого популярного набора символов ASCII (ANSI 1252). Поэтому, если у вас есть файл, не поддерживающий Unicode, с обычными символами ASCII, который интерпретируется UltraEdit (или любым другим приложением) как UTF-8, вы, вероятно, даже не заметите разницы.
Автоматически определять кодировку
Убедитесь, что этот параметр отмечен, иначе UltraEdit не будет делать ничего , чтобы попытаться автоматически определить кодировку файлов, которые вы открываете. Это означает, что файлы, которые явно относятся к UTF-8 или UTF-16, будут выглядеть как зашифрованный неразборчивый текст с отключенной опцией.
Копирование и вставка данных Unicode в UltraEdit
Вы можете скопировать и вставить данные Unicode из внешнего источника в новый файл в UltraEdit.Во многих более ранних версиях UltraEdit, если вы пробовали это, вы, возможно, видели, что символы были вставлены в UltraEdit как символы мусора, маленькие прямоугольники, вопросительные знаки или что-то совершенно отличное от того, что вы ожидали. Это произошло потому, что новые файлы в UltraEdit по умолчанию создаются в кодировке ASCII, а не в Unicode / UTF-8. Обратитесь к нашей диаграмме выше; шестнадцатеричные данные верны для символов Юникода, но из-за неправильной установки кодировки результат неверен.
Хорошая новость заключается в том, что, начиная с UltraEdit v24.00 / UEStudio 17.00, UltraEdit теперь определяет, вставляются ли символы Unicode в файл, отличный от Unicode, и предлагает вам преобразовать файл перед выполнением вставки.
В предыдущих версиях вам нужно было установить правильную кодировку для нового файла, перед фактической вставкой в данные Unicode. Это можно сделать, перейдя в Файл » Преобразования и выбрав ASCII в UTF-8 .
Общие сведения о спецификациях (маркеры порядка байтов)
Маркер порядка байтов (для краткости BOM) — это последовательность байтов в самом начале файла, которая используется как «флаг» или «подпись» для кодирования и / или шестнадцатеричного порядка байтов, который следует использовать для файл. Для данных в кодировке UTF-8 это обычно три байта (представленные в шестнадцатеричном формате)
EF BB BF. Спецификация также сообщает редактору, имеют ли данные Unicode прямой или прямой порядок байтов. с прямым порядком байтов Данные Unicode просто означают, что старший байт в шестнадцатеричном формате сначала сохраняется в памяти вашего компьютера, а с прямым порядком байтов сохраняет его в памяти последним. Спецификации не всегда необходимы для отображения данных Unicode, но они могут избавить разработчиков от головной боли при написании и создании приложений. Спецификация — это одна из первых вещей, которую UltraEdit ищет при попытке определить, какую кодировку использует файл при его открытии.Если файл содержит спецификацию UTF-8, но приложение, обрабатывающее файл, не построено для обнаружения или соблюдения спецификации, тогда спецификация будет фактически отображаться как часть содержимого файла — обычно это ненужные символы, такие как «ï» ¿ «или» ÿ «(эквивалент ASCII невидимой в противном случае BOM.Вот почему так важно иметь текстовый редактор, такой как UltraEdit, который может правильно обнаруживать и обрабатывать спецификации.
Если вы открываете файлы в UltraEdit и видите эти «ненужные» символы в начале файла, это означает, что вы неправильно установили вышеупомянутые параметры обнаружения Unicode. И наоборот, если вы сохраняете файлы Unicode, которые открывают другие, с другими программами, которые показывают эти ненужные символы, то другие программы либо не могут, либо не настроены для правильной обработки спецификаций и данных Unicode.
Дополнительная информация о спецификациях и различных форматах байтов / UTF доступна на официальном сайте Unicode.
Настройка UltraEdit для сохранения данных Unicode / UTF-8 с BOM
Если вы хотите глобально настроить UltraEdit для сохранения всех файлов UTF-8 с BOM, вы можете установить это, перейдя в Advanced » Settings » File Handling » Save . Первые два параметра здесь: « Записать заголовок спецификации UTF-8 во все файлы UTF-8 при сохранении » и « Записать спецификацию UTF-8 в новые файлы, созданные в этой программе (если выше не задано) » должны быть проверил .И наоборот, если вы делаете , а не , вам нужны спецификации, убедитесь, что это , а не .
Вы также можете сохранять файлы UTF-8 со спецификациями для отдельных файлов. В диалоговом окне « File » Save As »в раскрывающемся списке« Format »есть несколько параметров для форматирования Unicode со спецификациями и без них.
Преобразование файлов Unicode / UTF-8 в файлы ASCII
Вы можете столкнуться с ситуацией, когда вам нужно преобразовать файл, закодированный в формате Unicode, в обычный ASCII.Возможно, у вас есть старая программа или приложение, не предназначенное для обработки кодировок Unicode. Хорошей новостью является то, что UltraEdit позволяет легко конвертировать файлы на основе Unicode в обычные файлы ASCII. Это очень простой процесс. Все, что вам нужно сделать, это перейти на вкладку Advanced и щелкнуть раскрывающийся список Conversions , затем выбрать вариант преобразования, который соответствует тому, что вы хотите сделать.
Например, если у вас есть файл UTF-8, содержащий японские символы, которые вы хотите преобразовать в ASCII, выберите в этом раскрывающемся списке «UTF-8 to ASCII».
После выбора этого параметра вы, вероятно, увидите запрос на выбор кодовой страницы для нового формата ASCII. Убедитесь, что вы назначили правильную кодовую страницу, соответствующую типу символов в вашем файле! Если вы этого не сделаете, вы можете повредить свои данные. В этом примере, поскольку мы работаем с японским языком, мы могли бы выбрать кодовую страницу 932, которая является одной из наиболее распространенных кодовых страниц японского языка.
После того, как мы нажмем OK , чтобы установить кодовую страницу, мы должны увидеть, что на вкладке файла указаны несохраненные изменения в файле, но мы не должны заметить никакой разницы в отображении файла.Базовая кодировка японских символов изменилась с UTF-8 на ASCII (с использованием кодовой страницы 932 для интерпретации байтовых последовательностей), но символы по-прежнему выглядят точно так же! Мы можем проверить это, также проверив кодировку в строке состояния.
Вы также можете преобразовать в другой путь ; например, из ASCII в UTF-8. В этом случае вам не нужно выбирать кодовую страницу, поскольку Unicode устраняет необходимость в кодовых страницах, поскольку он содержит все возможные символы.
Подводя итог …
Unicode — очень сложная система с тысячами символов, но она была усовершенствована и доработана, чтобы любой мог легко получить к ней доступ и использовать.