Презентация нейронные сети: Презентация по биологии на тему «Нейронные сети»
Нейронные сети и их применение»
Слайды и текст этой презентации
Слайд 1
Описание слайда:
«Нейронные сети и их применение»
Слайд 2
Описание слайда:
Что же такое нейронные сети?
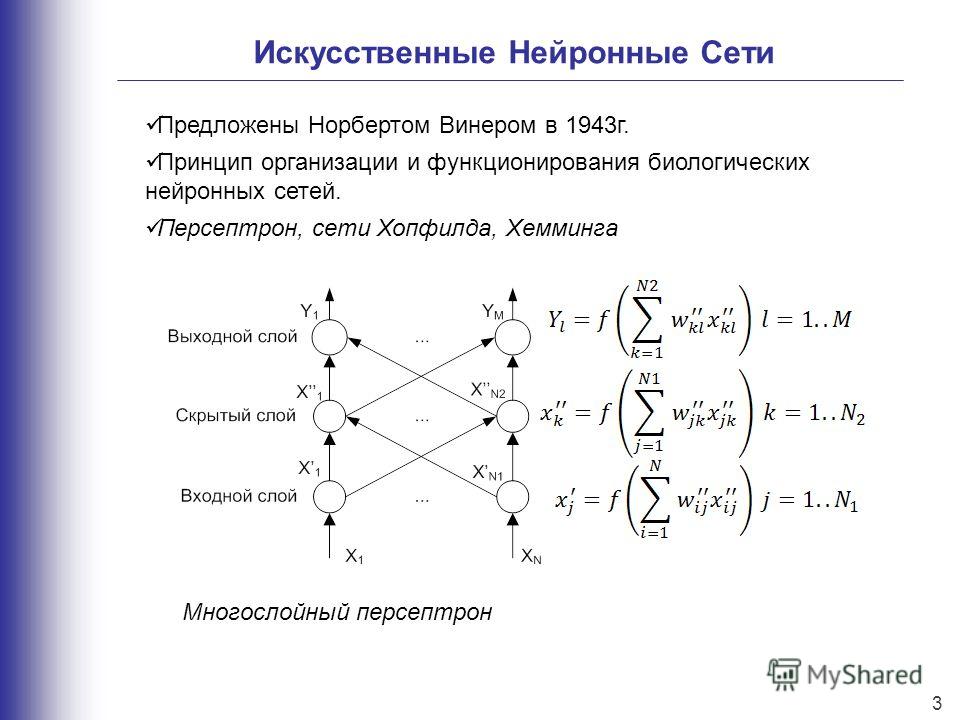
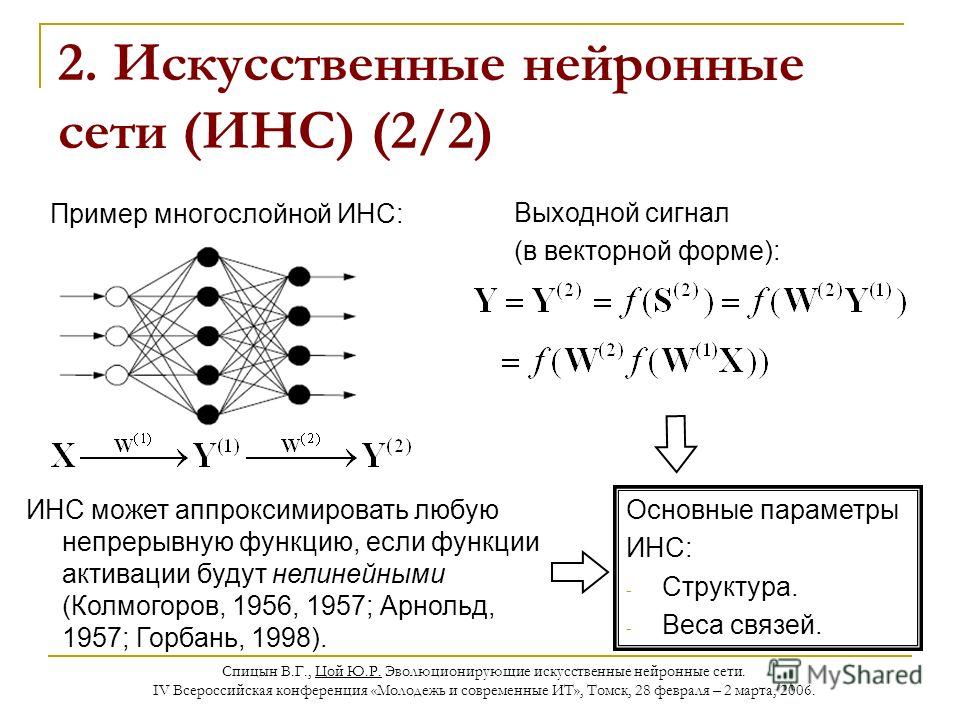
Искусственная нейронная сеть — математическая модель, а также ее программное и аппаратное воплощение, построенная по принципу организации и функционирования биологический нейронных сетей – сетей нервных клеток животного организма.
Слайд 3
Описание слайда:
Сама нейросеть представляет собой систему из множества нейронов (процессоров). По отдельности эти процессоры достаточно просты (намного проще, чем процессор персонального компьютера), но будучи соединенными в большую систему нейроны способны выполнять очень сложные задачи.
Сама нейросеть представляет собой систему из множества нейронов (процессоров). По отдельности эти процессоры достаточно просты (намного проще, чем процессор персонального компьютера), но будучи соединенными в большую систему нейроны способны выполнять очень сложные задачи.
По отдельности эти процессоры достаточно просты (намного проще, чем процессор персонального компьютера), но будучи соединенными в большую систему нейроны способны выполнять очень сложные задачи.
Слайд 4
Описание слайда:
Особенности нейронных сетей
Основным преимуществом нейросетей над обычными алгоритмами вычисления является их возможность обучения. Это обучение заключается в нахождении верных коэффициентов связи между нейронами, а также в обобщении данных и выявлении сложных зависимостей между входными и выходными сигналами.
Слайд 5
Описание слайда:
Удачное обучение нейросети означает, что система будет способна выявить верный результат на основании определенных данных.
Удачное обучение нейросети означает, что система будет способна выявить верный результат на основании определенных данных.
Слайд 6
Описание слайда:
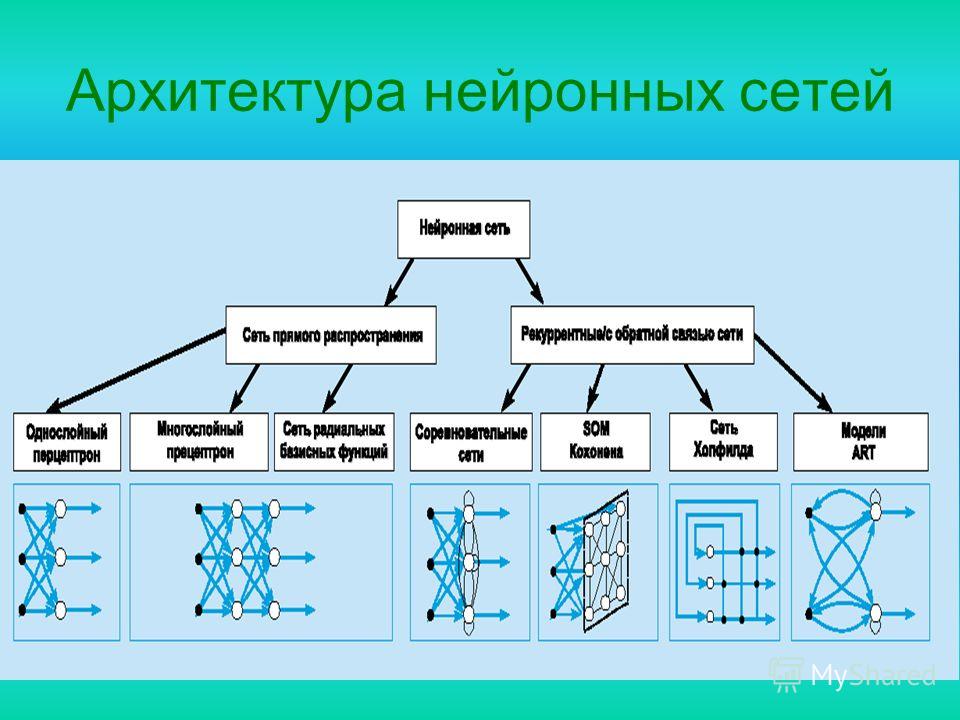
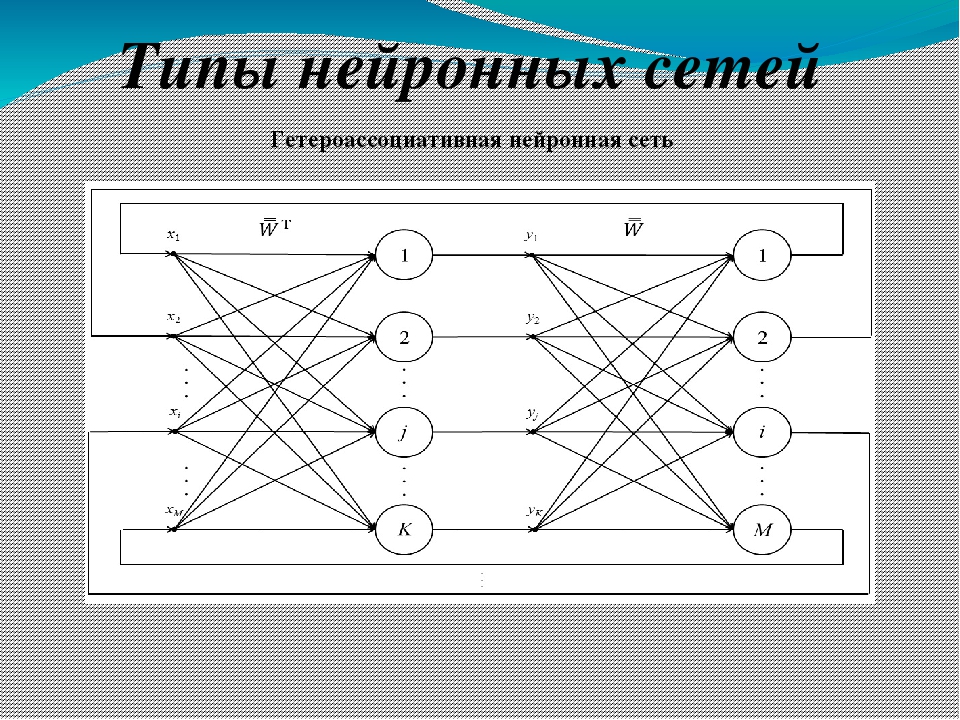
Типы нейросетей
Слайд 7
Описание слайда:
Где используются нейронные сети?
Нейронные сети используются для решения разнообразных задач. Если рассмотреть операции по степени сложности, то для решения простейших задач подойдёт обычная компьютерная программа. А вот задачи более сложного уровня требуют совсем иного подхода. В частности, это относится к распознаванию образов, речи или сложному прогнозированию. В голове человека подобные процессы происходят неосознанно, то есть, распознавая и запоминая образы, человек не осознаёт, как происходит этот процесс, а соответственно не может его контролировать. Именно такие задачи помогают решить нейронные сети, то есть то есть они созданы чтобы выполнять процессы, алгоритмы которых неизвестны.
Если рассмотреть операции по степени сложности, то для решения простейших задач подойдёт обычная компьютерная программа. А вот задачи более сложного уровня требуют совсем иного подхода. В частности, это относится к распознаванию образов, речи или сложному прогнозированию. В голове человека подобные процессы происходят неосознанно, то есть, распознавая и запоминая образы, человек не осознаёт, как происходит этот процесс, а соответственно не может его контролировать. Именно такие задачи помогают решить нейронные сети, то есть то есть они созданы чтобы выполнять процессы, алгоритмы которых неизвестны.
Слайд 8
Описание слайда:
Таким образом, нейронные сети находят широкое применение в следующих областях: распознавание, причём это направление в настоящее время самое широкое; предсказание следующего шага, эта особенность применима на торгах и фондовых рынках; классификация входных данных по параметрам, такую функцию выполняют кредитные роботы, которые способны принять решение в одобрении займа человеку, полагаясь на входной набор разных параметров.
Таким образом, нейронные сети находят широкое применение в следующих областях: распознавание, причём это направление в настоящее время самое широкое; предсказание следующего шага, эта особенность применима на торгах и фондовых рынках; классификация входных данных по параметрам, такую функцию выполняют кредитные роботы, которые способны принять решение в одобрении займа человеку, полагаясь на входной набор разных параметров.
Слайд 9
Описание слайда:
Способности нейросетей делают их очень популярными. Их можно научить многому, например, играть в игры, узнавать определённый голос и так далее. Исходя из того, что искусственные сети строятся по принципу биологических сетей, их можно обучить всем процессам, которые человек выполняет неосознанно.
Способности нейросетей делают их очень популярными. Их можно научить многому, например, играть в игры, узнавать определённый голос и так далее. Исходя из того, что искусственные сети строятся по принципу биологических сетей, их можно обучить всем процессам, которые человек выполняет неосознанно.
Слайд 10
Описание слайда:
Нейронные сети — презентация, доклад, проект
Вы можете изучить и скачать доклад-презентацию на
тему Нейронные сети.
Презентация на заданную тему содержит 77 слайдов. Для просмотра воспользуйтесь
проигрывателем,
если материал оказался полезным для Вас — поделитесь им с друзьями с
помощью социальных кнопок и добавьте наш сайт презентаций в закладки!
Слайды и текст этой презентации
Слайд 1
Описание слайда:
Слайд 2
Описание слайда:
Слайд 3
Описание слайда:
Слайд 4
Описание слайда:
Слайд 5
Описание слайда:
Слайд 6
Описание слайда:
Слайд 7
Описание слайда:
Слайд 8
Описание слайда:
Слайд 9
Описание слайда:
Слайд 10
Описание слайда:
Слайд 11
Описание слайда:
Слайд 12
Описание слайда:
Слайд 13
Описание слайда:
Слайд 14
Описание слайда:
Слайд 15
Описание слайда:
Слайд 16
Описание слайда:
Слайд 17
Описание слайда:
Слайд 18
Описание слайда:
Слайд 19
Описание слайда:
Слайд 20
Описание слайда:
Слайд 21
Описание слайда:
Слайд 22
Описание слайда:
Слайд 23
Описание слайда:
Слайд 24
Описание слайда:
Слайд 25
Описание слайда:
Слайд 26
Описание слайда:
Слайд 27
Описание слайда:
Слайд 28
Описание слайда:
Слайд 29
Описание слайда:
Слайд 30
Описание слайда:
Слайд 31
Описание слайда:
Слайд 32
Описание слайда:
Слайд 33
Описание слайда:
Слайд 34
Описание слайда:
Слайд 35
Описание слайда:
Слайд 36
Описание слайда:
Слайд 37
Описание слайда:
Слайд 38
Описание слайда:
Слайд 39
Описание слайда:
Слайд 40
Описание слайда:
Слайд 41
Описание слайда:
Слайд 42
Описание слайда:
Слайд 43
Описание слайда:
Слайд 44
Описание слайда:
Слайд 45
Описание слайда:
Слайд 46
Описание слайда:
Слайд 47
Описание слайда:
Слайд 48
Описание слайда:
Слайд 49
Описание слайда:
Слайд 50
Описание слайда:
Слайд 51
Описание слайда:
Слайд 52
Описание слайда:
Слайд 53
Описание слайда:
Слайд 54
Описание слайда:
Слайд 55
Описание слайда:
Слайд 56
Описание слайда:
Слайд 57
Описание слайда:
Слайд 58
Описание слайда:
Слайд 59
Описание слайда:
Слайд 60
Описание слайда:
Слайд 61
Описание слайда:
Слайд 62
Описание слайда:
Слайд 63
Описание слайда:
Слайд 64
Описание слайда:
Слайд 65
Описание слайда:
Слайд 66
Описание слайда:
Слайд 67
Описание слайда:
Слайд 68
Описание слайда:
Слайд 69
Описание слайда:
Задачи сегментации изображения с помощью нейронной сети Unet
Сегментация изображений с U-Net на практике
В этом блог посте мы посмотрим как Unet работает, как реализовать его, и какие данные нужны для его обучения. Для этого мы будем рассматривать:
Для этого мы будем рассматривать:
- Оригинальную статью Unet как источник для вдохновения.
- Pytorch как инструмент для реализации нашей задумки.
- Kaggle соревнования как место где мы можем опробовать наши гипотезы на реальных данных.
Мы не будем следовать на 100% за статьей, но мы постараемся реализовать ее суть, адаптировать под наши нужды.
Презентация проблемы
В этой задаче нам дано изображение машины и его бинарная маска(локализующая положение машины на изображении). Мы хотим создать модель, которая будет будет способна отделять изображение машины от фона с попиксельной точностью более 99%.
Для понимания того что мы хотим, gif изображение ниже:
Изображение слева — это исходное изображение, справа — маска, которая будет применяться на изображение. Мы будем использовать Unet нейронную сеть, которая будет учиться автоматически создавать маску.
- Подавая в нейронную сеть изображения автомобилей.

- Используя функцию потерь, сравнивая вывод нейронной сети с соответствующими масками и возвращающую ошибку для сети, чтобы узнать в каких местах сеть ошибается.

Структура кода
Код был максимально упрощен для понимания как это работает. Основной код находится в этом файле main.py, разберем его построчно.
Мы будем итеративно проходить через код в main.py и через статью. Не волнуйтесь о деталях, спрятанных в других файлах проекта: нужные мы продемонстрируем по мере необходимости.
Давайте начнем с начала:
def main():
# Hyperparameters
input_img_resize = (572, 572) # The resize size of the input images of the neural net
output_img_resize = (388, 388) # The resize size of the output images of the neural net
batch_size =3
epochs =50
threshold =0.5
validation_size =0.2
sample_size = None
# -- Optional parameters
threads = cpu_count()
use_cuda = torch.cuda.is_available()
script_dir = os.path.dirname(os. path.abspath(__file__))
# Training callbacks
tb_viz_cb = TensorboardVisualizerCallback(os.path.join(script_dir,'../logs/tb_viz'))
tb_logs_cb = TensorboardLoggerCallback(os.path.join(script_dir,'../logs/tb_logs'))
model_saver_cb = ModelSaverCallback(os.path.join(script_dir,'../output/models/model_' + helpers.get_model_timestamp()), verbose=True)
 path.abspath(__file__))
# Training callbacks
tb_viz_cb = TensorboardVisualizerCallback(os.path.join(script_dir,'../logs/tb_viz'))
tb_logs_cb = TensorboardLoggerCallback(os.path.join(script_dir,'../logs/tb_logs'))
model_saver_cb = ModelSaverCallback(os.path.join(script_dir,'../output/models/model_' + helpers.get_model_timestamp()), verbose=True)
path.abspath(__file__))
# Training callbacks
tb_viz_cb = TensorboardVisualizerCallback(os.path.join(script_dir,'../logs/tb_viz'))
tb_logs_cb = TensorboardLoggerCallback(os.path.join(script_dir,'../logs/tb_logs'))
model_saver_cb = ModelSaverCallback(os.path.join(script_dir,'../output/models/model_' + helpers.get_model_timestamp()), verbose=True)
В первом разделе вы определяете свои гиперпараметры, их можете настроить по своему усмотрению, например в зависимости от вашей памяти GPU. Optimal parametes определяют некоторые полезные параметры и callbacks. TensorboardVisualizerCallback — это класс, который будет сохранять предсказания в tensorboard в каждую эпоху тренировочного процесса, TensorboardLoggerCallback сохранит значения функций потерь и попиксельную «точность» в tensorboard. И наконец ModelSaverCallback сохранит вашу модель после завершения обучения.
# Download the datasets ds_fetcher = DatasetFetcher() ds_fetcher.
 download_dataset()
download_dataset()
Этот раздел автоматически загружает и извлекает набор данных из Kaggle. Обратите внимание, что для успешной работы этого участка кода вам необходимо иметь учетную запись Kaggle с логином и паролем, которые должны быть помещены в переменные окружения KAGGLE_USER и KAGGLE_PASSWD перед запуском скрипта. Также требуется принять правила конкурса, перед загрузкой данных. Это можно сделать на вкладке загрузки данных конкурса
# Get the path to the files for the neural net X_train, y_train, X_valid, y_valid = ds_fetcher.get_train_files(sample_size=sample_size, validation_size=validation_size) full_x_test = ds_fetcher.get_test_files(sample_size)
Тут мы просто разделили train set на тренировочную и валидационную выборку, далее загрузили тестовый датасет (у которого мы не имеем масок, и на котором нужно предсказывать маски для проверки на public и private leaderboard на kaggle).
# Testing callbacks pred_saver_cb = PredictionsSaverCallback(os.
 path.join(script_dir,'../output/submit.csv.gz'), origin_img_size, threshold)
path.join(script_dir,'../output/submit.csv.gz'), origin_img_size, threshold)
Эта строка определяет callback функцию для теста (или предсказания). Она будет сохранять предсказания в файле gzip каждый раз, когда будет произведена новая партия предсказания. Таким образом, предсказания не будут сохранятся в памяти, так как они очень большие по размеру.
После окончания процесса предсказания вы можете отправить полученный файл submit.csv.gz из выходной папки в Kaggle.
# -- Define our neural net architecture
# The original paper has 1 input channel, in our case we have 3 (RGB)
net = unet_origin.UNetOriginal((3, *img_resize))
classifier = nn.classifier.CarvanaClassifier(net, epochs)
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.99)
train_ds = TrainImageDataset(X_train, y_train, input_img_resize, output_img_resize, X_transform=aug.augment_img)
train_loader = DataLoader(train_ds, batch_size,
sampler=RandomSampler(train_ds),
num_workers=threads,
pin_memory=use_cuda)
valid_ds = TrainImageDataset(X_valid, y_valid, input_img_resize, output_img_resize, threshold=threshold)
valid_loader = DataLoader(valid_ds, batch_size,
sampler=SequentialSampler(valid_ds),
num_workers=threads,
pin_memory=use_cuda)
Здесь мы определяем нашу сеть net и оптимизатор optimizer (подробнее об этом позже), затем создали загрузчик, как для train set, так и для validation set, который будет загружать данные в виде batches.
print("Training on {} samples and validating on {} samples "
.format(len(train_loader.dataset), len(valid_loader.dataset)))
# Train the classifier
classifier.train(train_loader, valid_loader, epochs, callbacks=[tb_viz_cb, tb_logs_cb, model_saver_cb])
Теперь мы запускаем тренировку модели, запуская train и validation loader и callback, который мы определили. Ниже мы рассмотрим некоторые детали реализации этого метода.
test_ds = TestImageDataset(full_x_test, img_resize)
test_loader = DataLoader(test_ds, batch_size,
sampler=SequentialSampler(test_ds),
num_workers=threads,
pin_memory=use_cuda)
# Predict & save
classifier.predict(test_loader, callbacks=[pred_saver_cb])
pred_saver_cb.close_saver()Наконец, мы делаем то же самое, что и выше, но для прогона предсказания. Мы вызываем наш pred_saver_cb.close_saver(), чтобы очистить и закрыть файл, который содержит предсказания.
Реализация архитектуры нейронной сети
Статья Unet представляет подход для сегментации медицинских изображений. Однако оказывается этот подход также можно использовать и для других задач сегментации. В том числе и для той, над которой мы сейчас будем работать.
Перед тем, как идти вперед, вы должны прочитать статью полностью хотя бы один раз. Не волнуйтесь, если вы не получили полного понимания математического аппарата, вы можете пропустить этот раздел, также как главу «Эксперименты». Наша цель заключается в получении общей картины.
Задача оригинальной статьи отличается от нашей, нам нужно будет адаптировать некоторые части соответственно нашим потребностям.
В то время, когда была написана работа, были пропущены 2 вещи, которые сейчас необходимы для ускорения сходимости нейронной сети:
- BatchNorm.
- Мощные GPU.
Первое был изобретено всего за 3 месяца до Unet, и вероятно слишком рано, чтобы авторы Unet добавили его в свою статью.
На сегодняшний день BatchNorm используется практически везде. Вы можете избавиться от него в коде, если хотите оценить статью на 100%, но вы можете не дожить до момента, когда сеть сойдется.
Что касается графических процессоров, в статье говорится:
To minimize the overhead and make maximum use of the GPU memory, we favor large input tiles over a large batch size and hence reduce the batch to a single image
Они использовали GPU с 6 ГБ RAM, но в настоящее время у GPU больше памяти, для размещения изображений в одном batch’e. Текущий batch равный трем, работает для графического процессора в GPU с 8 гб RAM. Если у вас нет такой видеокарты, попробуйте уменьшить batch до 2 или 1.
Что касается методов augmentations(то есть искажения исходного изображения по какому либо паттерну), рассматриваемых в статье, мы будем использовать отличные от описываемых в статье, поскольку наши изображения сильно отличаются от биомедицинских изображений.
Теперь давайте начнем с самого начала, проектируя архитектуру нейронной сети:
Вот как выглядит Unet. Вы можете найти эквивалентную реализацию Pytorch в модуле nn.unet_origin.py.
Вы можете найти эквивалентную реализацию Pytorch в модуле nn.unet_origin.py.
Все классы в этом файле имеют как минимум 2 метода:
- __init__() где мы будем инициализировать наши уровни нейронной сети;
- forward() который является методом, называемым, когда нейронная сеть получает вход.
Давайте рассмотрим детали реализации:
- ConvBnRelu — это блок, содержащий операции Conv2D, BatchNorm и Relu. Вместо того, чтобы набирать их 3 для каждого стека кодировщика (группа операций вниз) и стеков декодера (группа операций вверх), мы группируем их в этот объект и повторно используем его по мере необходимости.
- StackEncoder инкапсулирует весь «стек» операций вниз, включая операции ConvBnRelu и MaxPool, как показано ниже:
Мы отслеживаем вывод последней операции ConvBnRelu в x_trace и возвращаем ее, потому что мы будем конкатенировать этот вывод с помощью стеков декодера.
- StackDecoder — это то же самое, что и StackEncoder, но для операций декодирования, окруженных ниже красным:
Обратите внимание, что он учитывает операцию обрезки / конкатенации (окруженную оранжевым), передавая в down_tensor, который является не чем иным, как тензором x_trace, возвращаемым нашим StackEncoder.
- UNetOriginal — это место, где происходит волшебство. Это наша нейронная сеть, которая будет собирать все маленькие кирпичики, представленные выше. Методы init и forward действительно сложны, они добавляют кучу StackEncoder, центральной части и под конец несколько StackDecoder. Затем мы получаем вывод StackDecoder, добавляем к нему свертку 1×1 в соответствии со статьей, но вместо того, чтобы определять два фильтра в качестве вывода, мы определяем только 1, который фактически будет нашим прогнозом маски в оттенках серого. Далее мы «сжимаем» наш вывод, чтобы удалить размер канала (всего 1, поэтому нам не нужно его хранить).

Если вы хотите понять больше деталей каждого блока, поместите контрольную точку отладки в метод forward каждого класса, чтобы подробно просмотреть объекты. Вы также можете распечатать форму ваших тензоров вывода между слоями, выполнив печать (x.size()).
Тренировка нейронной сети
- Функция потерь
Теперь к реальному миру. Согласно статье:
The energy function is computed by a pixel-wise soft-max over the final feature map combined with the cross-entropy loss function.
Дело в том, что в нашем случае мы хотим использовать dice coefficient как функцию потерь вместо того, что они называют «энергетической функцией», так как это показатель, используемый в соревновании Kaggle, который определяется:
X является нашим предсказанием и Y — правильно размеченной маской на текущем объекте. |X| означает мощность множества X (количество элементов в этом множестве) и ∩ для пересечения между X и Y.
Код для dice coefficient можно найти в nn.losses.SoftDiceLoss.
class SoftDiceLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(SoftDiceLoss, self).__init__()
def forward(self, logits, targets):
smooth =1
num = targets.size(0)
probs = F.sigmoid(logits)
m1 = probs.view(num, -1)
m2 = targets.view(num, -1)
intersection = (m1 * m2)
score =2. * (intersection.sum(1) + smooth) / (m1.sum(1) + m2.sum(1) + smooth)
score =1 - score.sum() / num
return scoreПричина, по которой пересечение реализуется как умножение, и мощность в виде sum() по axis 1 (сумма из трех каналов) заключается в том, что предсказания и цель являются one-hot encoded векторами.
Например, предположим, что предсказание на пикселе (0, 0) равно 0,567, а цель равна 1, получаем 0,567 * 1 = 0,567. Если цель равна 0, мы получаем 0 в этой позиции пикселя.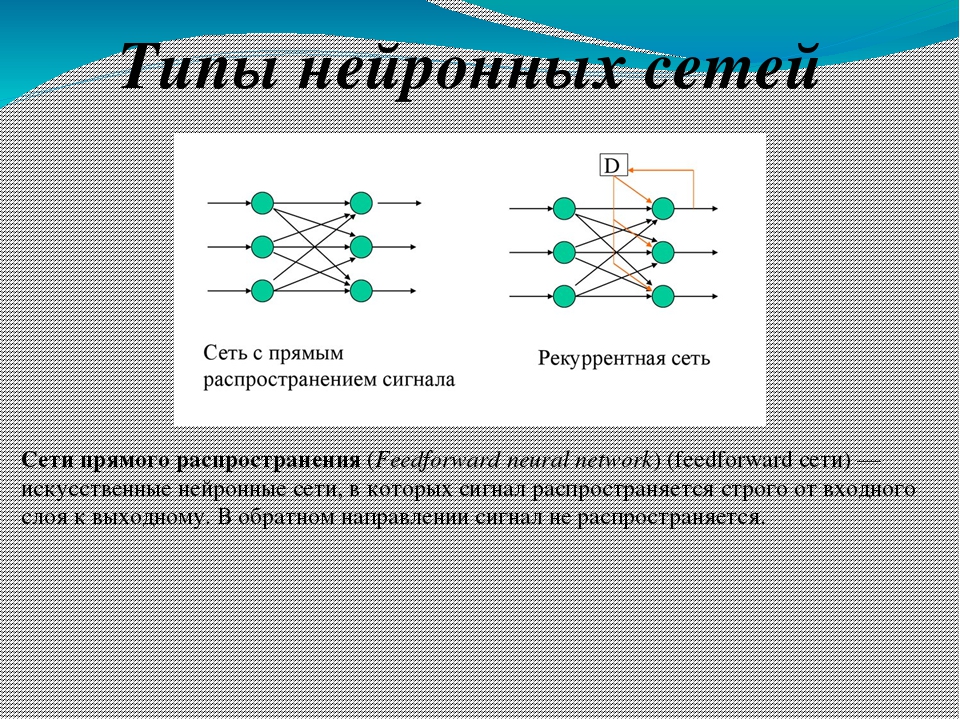
Мы также использовали плавный коэффициент 1 для обратного распространения. Если предсказание является жестким порогом, равным 0 и 1, трудно обратно распространять dice loss.
Затем мы сравним dice loss с кросс-энтропией, чтобы получить нашу функцию полной потери, которую вы можете найти в методе _criterion из nn.Classifier.CarvanaClassifier. Согласно оригинальной статье они также используют weight map в функции потери кросс-энтропии, чтобы придать некоторым пикселям большее ошибки во время тренировки. В нашем случае нам не нужна такая вещь, поэтому мы просто используем кросс-энтропию без какого-либо weight map.
2. Оптимизатор
Здесь мы попытаемся отдать дань уважения оригинальной статье, используя оптимизатор SGD и momentum 0,99. Оптимизатор можно найти в основном методе:
optimizer = optim.SGD(self.net.parameters(), lr=0.01, momentum=0.99)
Это все, что нам нужно сделать для оптимизатора.
Нейронные сети — что это такое и как они работают? Виды нейросетей
Нейронная сеть – одно из направлений искусственного интеллекта, цель которого смоделировать аналитические механизмы, осуществляемые человеческим мозгом.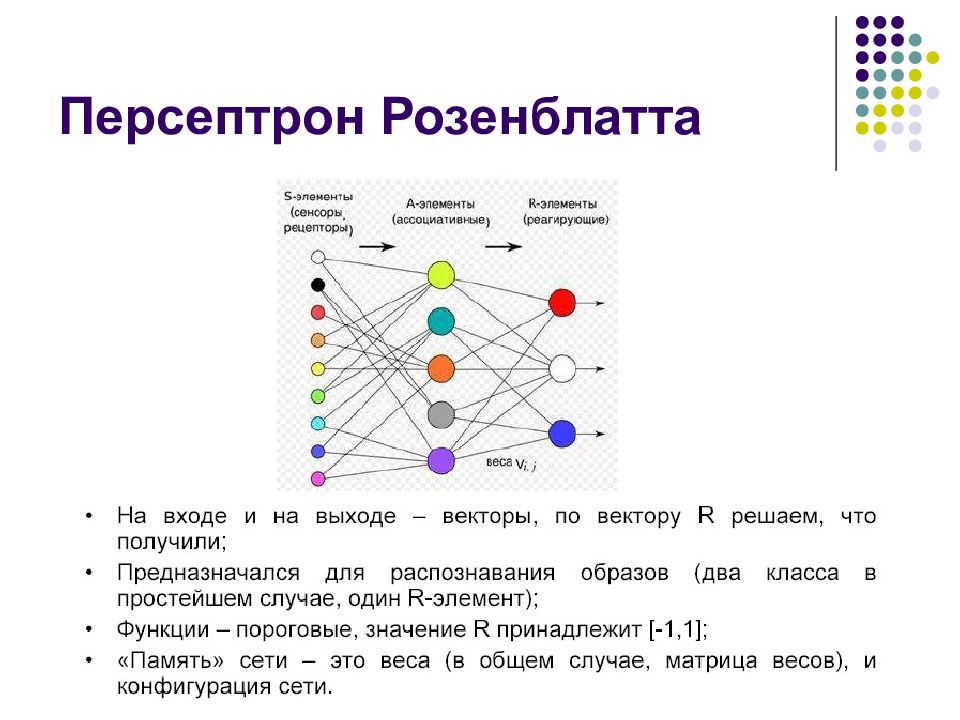 Задачи, которые решает типичная нейросеть – классификация, предсказание и распознавание. Нейросети способны самостоятельно обучаться и развиваться, строя свой опыт на совершенных ошибках.
Задачи, которые решает типичная нейросеть – классификация, предсказание и распознавание. Нейросети способны самостоятельно обучаться и развиваться, строя свой опыт на совершенных ошибках.
Нейросети — это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Также нейронные сети способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти.
Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Навигация по материалу:
История создания нейронных сетей
Какова же история развития нейронных сетей в науке и технике? Она берет свое начало с появлением первых компьютеров или ЭВМ (электронно-вычислительная машина) как их называли в те времена. Так еще в конце 1940-х годов некто Дональд Хебб разработал механизм нейронной сети, чем заложил правила обучения ЭВМ, этих «протокомпьютеров».
Так еще в конце 1940-х годов некто Дональд Хебб разработал механизм нейронной сети, чем заложил правила обучения ЭВМ, этих «протокомпьютеров».
Дальнейшая хронология событий была следующей:
- В 1954 году происходит первое практическое использование нейронных сетей в работе ЭВМ.
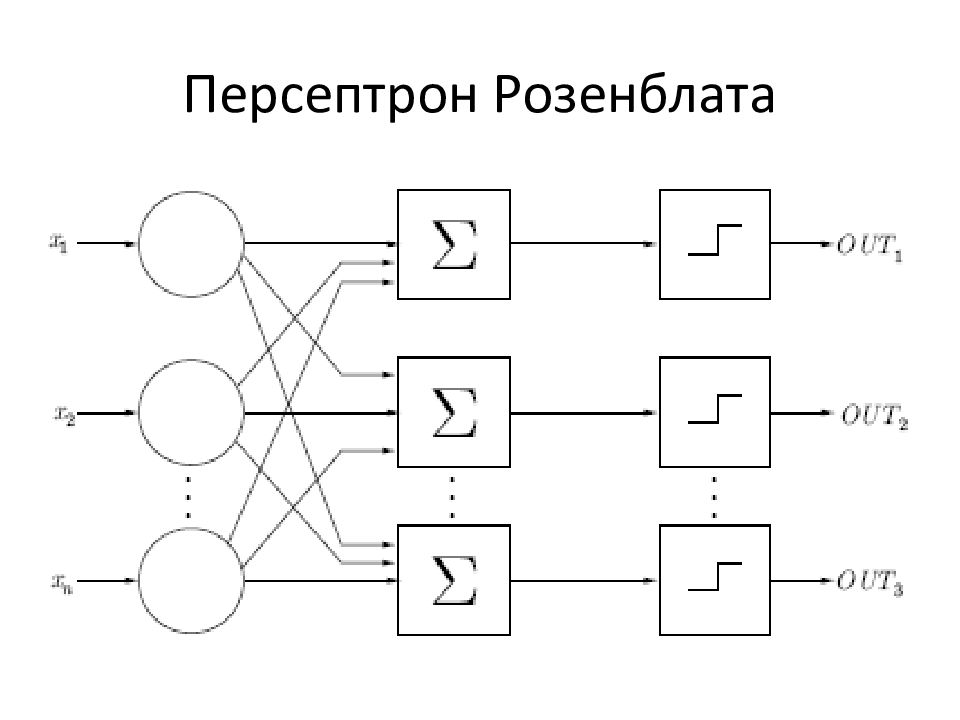
- В 1958 году Франком Розенблатом разработан алгоритм распознавания образов и математическая аннотация к нему.
- В 1960-х годах интерес к разработке нейронных сетей несколько угас из-за слабых мощностей компьютеров того времени.
- И снова возродился уже в 1980-х годах, именно в этот период появляется система с механизмом обратной связи, разрабатываются алгоритмы самообучения.
- К 2000 году мощности компьютеров выросли настолько, что смогли воплотить самые смелые мечты ученых прошлого. В это время появляются программы распознавания голоса, компьютерного зрения и многое другое.
GeekUniversity совместно с Mail.ru Group открыли первый в России факультет Искусственного интеллекта преподающий нейронные сети.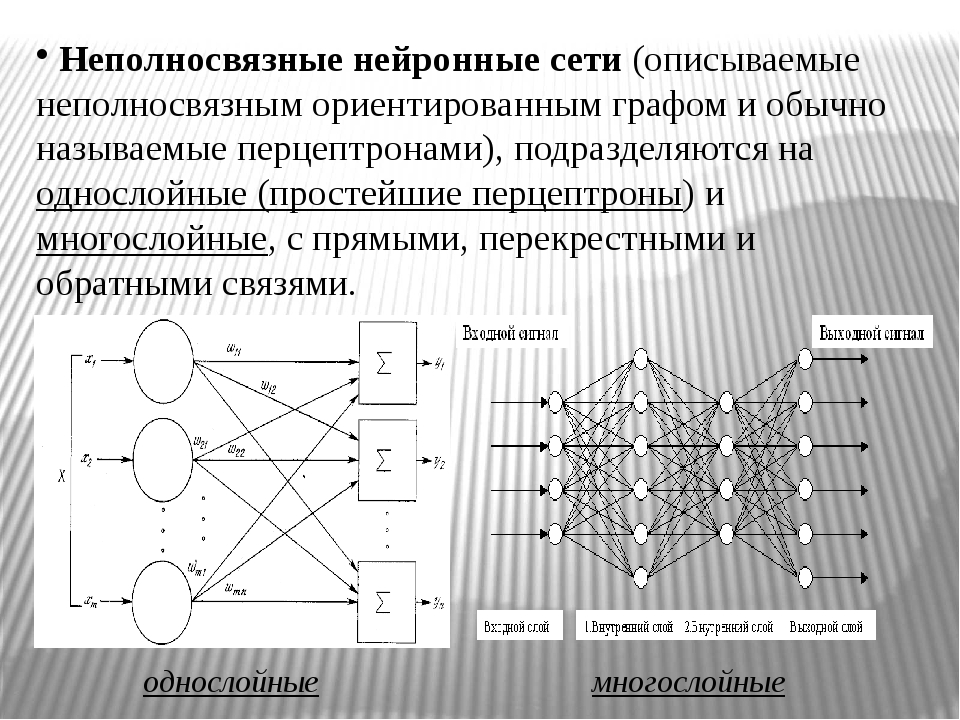 Для учебы достаточно школьных знаний. Программа включает в себя все необходимые ресурсы и инструменты + целая программа по высшей математике. Не абстрактная, как в обычных вузах, а построенная на практике. Обучение познакомит вас с технологиями машинного обучения и нейронными сетями, научит решать настоящие бизнес-задачи.
Для учебы достаточно школьных знаний. Программа включает в себя все необходимые ресурсы и инструменты + целая программа по высшей математике. Не абстрактная, как в обычных вузах, а построенная на практике. Обучение познакомит вас с технологиями машинного обучения и нейронными сетями, научит решать настоящие бизнес-задачи.
Как работают нейронные сети?
Искусственная нейронная сеть — совокупность нейронов, взаимодействующих друг с другом. Они способны принимать, обрабатывать и создавать данные. Это настолько же сложно представить, как и работу человеческого мозга. Нейронная сеть в нашем мозгу работает для того, чтобы вы сейчас могли это прочитать: наши нейроны распознают буквы и складывают их в слова.
Год искусственного интеллекта: топ-5 нейросетей, изменивших мир
Искусственная нейронная сеть — это шаг в то будущее, которое на протяжении последних трех десятилетий служит основным сюжетом фантастических фильмов. Пришествие искусственного интеллекта началось, а мы даже не заметили, как программы на основании аналога человеческого разума вошли в нашу жизнь и изменили ее. Телеканал «360» собрал топ-5 самых передовых технологий и узнал перспективы у разработчиков.
Телеканал «360» собрал топ-5 самых передовых технологий и узнал перспективы у разработчиков.
Как работает искусственная нейронная сеть?
Для начала немного вводной информации. Нейронная сеть в отличие от обычной программы действует не только в соответствии с заданными алгоритмами и формулами, но и на базе прошлого опыта.
«Если объяснять „на пальцах“, то нейронными сетями стали называть тип алгоритмов, который изначально появился с целью как-то моделировать работу реального мозга. Если мозг состоит из огромного количества связанных нервных клеток, то нейронная сеть состоит из простых элементов (иногда их называют процессорами или нейронами). Каждый такой элемент связан с другими. Связи могут усиливаться или ослабляться в процессе обучения», — пытается простыми словами описать принцип устройства работы нейронных сетей Иван Ямщиков, ведущий аналитик и руководитель группы исследований новых продуктов «Яндекса».
Простой пример: нейросеть играет в компьютерную игру, и ей поставили единственную задачу — набрать максимальное количество баллов.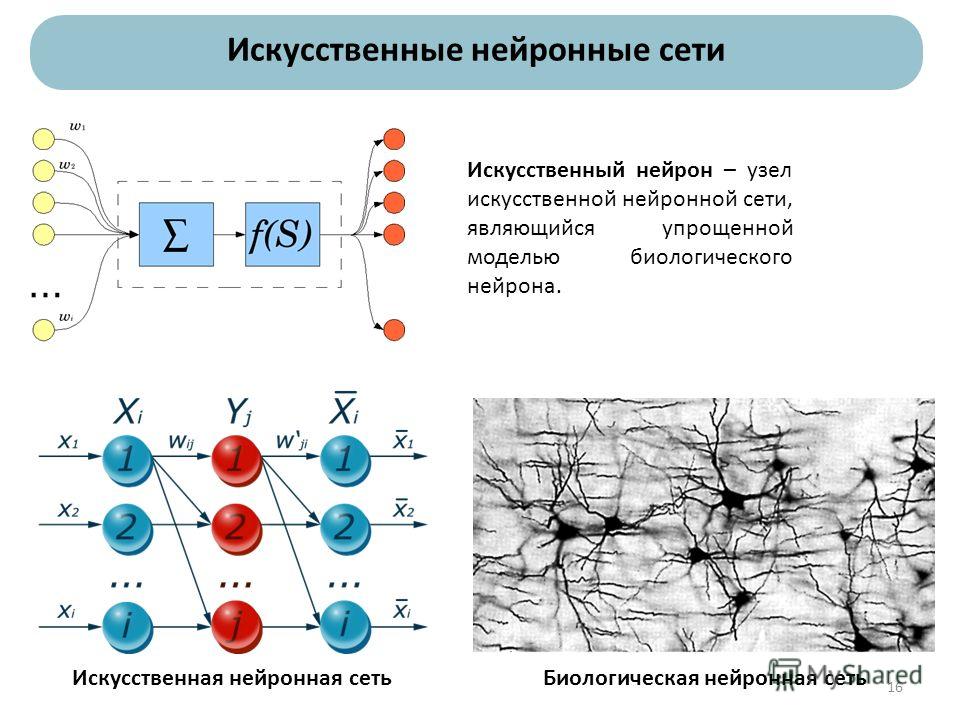 Но правила не объяснили. На сотой попытке она понимает, что баллы набираются, если не пропускать шар. На 600-й попытке она уже знает в какой угол бить, чтобы наиболее быстро набрать очки за минимальное количество ударов.
Но правила не объяснили. На сотой попытке она понимает, что баллы набираются, если не пропускать шар. На 600-й попытке она уже знает в какой угол бить, чтобы наиболее быстро набрать очки за минимальное количество ударов.
Топ-5 революционных нейросетей
1. Автопилот Tesla
Самый громкий проект этого года, который кардинально изменит нашу жизнь в будущем, — Tesla. Автопилоты в них работают на основе нейросетей, а все машины этой марки в мире — огромная школа.
«Все машины они сделали инструментом для обучения нейронных сетей. Нейросеть не может сама обучаться, ей обязательно нужен тренер. В данном случае в его роли выступает водитель, который объезжает препятствия. Когда ты выполняешь маневр, машина обучается. И другие люди, когда они утром получают апдейт — новую версию программного обеспечения, она каждый день обновляется, то их машина уже тоже умеет объезжать это препятствие.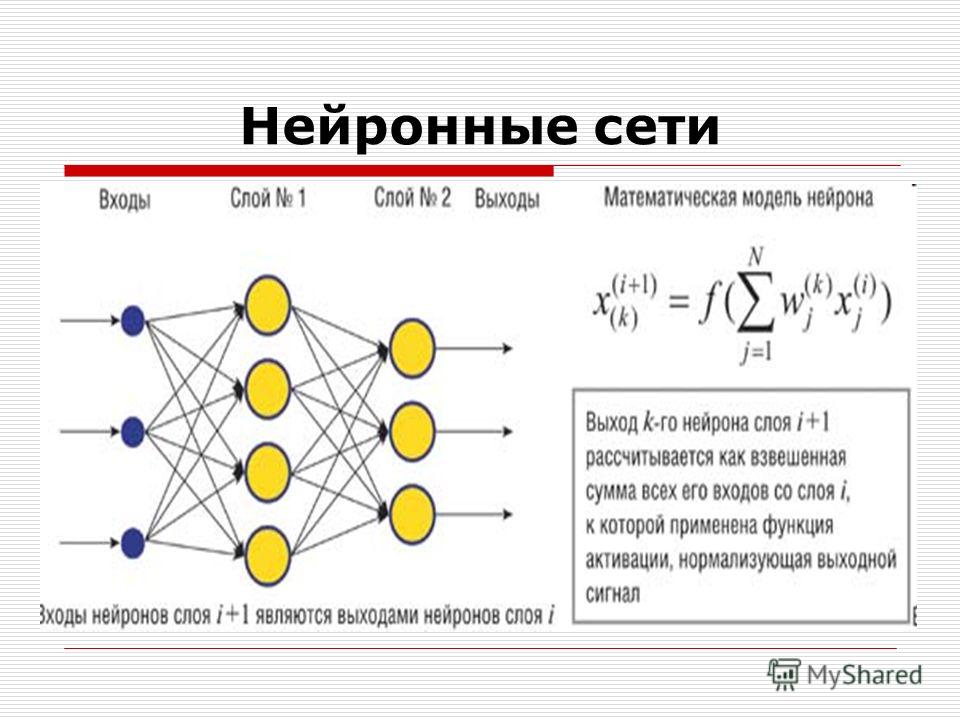 Уникальность решения в том, что если они сумеют распространить автомобили по всему миру, то уже через несколько лет будет хороший, близкий к совершенному автопилот», — считает Ашот Габрелянов, разработчик приложений на основе нейросетей.
Уникальность решения в том, что если они сумеют распространить автомобили по всему миру, то уже через несколько лет будет хороший, близкий к совершенному автопилот», — считает Ашот Габрелянов, разработчик приложений на основе нейросетей.
Недалек тот день, когда автопилот войдет в нашу жизнь так же плотно, как коробка-автомат. Эксперты называют срок в пять лет.
2. Системы безопасности
Все мы в этом году баловались новыми приложениями типа PRISMA и MSQRD, превращались в единорогов на видеороликах, создавали картины в стиле Шагала из фотографий. Все эти шалости основаны на технологии распознавания лиц и предметов, на которое способна лишь нейросеть.
Ее основное направление использования — системы безопасности. Вспомните любой шпионский фильм или историю Эдварда Сноудена. Эти программы могут искать преступников по голосу среди миллионов разговоров, по лицу в толпах людей на улице, по ключевым словосочетаниям в миллиардах сообщений.
«Любая возможность быстро распознать твое лицо минимизирует желание совершать преступление. Самый яркий пример — террорист из Великобритании, которого нашли, используя именно эти системы. Сейчас это работает постфактум, в дальнейшем обработка будет происходить моментально в реальном времени. Также у нейросетей большой потенциал в отражении кибератак», — рассказывает о возможных применениях разработчик Magic App Ашот Габрелянов.
Самый яркий пример — террорист из Великобритании, которого нашли, используя именно эти системы. Сейчас это работает постфактум, в дальнейшем обработка будет происходить моментально в реальном времени. Также у нейросетей большой потенциал в отражении кибератак», — рассказывает о возможных применениях разработчик Magic App Ашот Габрелянов.
Он и сам использует в своих приложениях схожую технологию, но в развлекательных целях.
«Мы сейчас работаем над технологией распознавания эмоций. Это новое направление. Например, Google и Facebook сейчас работают над созданием решения для виртуальной, дополненной реальности. В ближайшем будущем, когда люди начнут общаться в новой реальности, им нужно будет выражать эмоции. Для этого необходимо научить компьютер их считывать с человеческого лица, чем мы и занимаемся», — отметил он.
3. Нейросети в медицине
В России, да и во всем мире идет работа над проектом внедрения нейросетей в медицину. Касается это тех болезней, которые можно выявить по снимкам. Врачам для постановки диагноза требуется большой опыт и время, а верное заключение дается не всегда с первого раза.
Врачам для постановки диагноза требуется большой опыт и время, а верное заключение дается не всегда с первого раза.
Нейросеть проанализировала базу рентгеновских снимков с точными заключениями за последние 10 лет. На основе этих данных программа ставит диагноз за несколько минут с точностью 98%.
4. Анализ данных в социальных сетях
Но нейросети широко используются и в простых вещах, которые мы уже воспринимаем, как обыденность. Их заложили в основу Яндекс. Погоды: сервис делает прогноз с точностью до минуты и до метра, анализируя объем информации, который не сможет обработать ни один метеоролог.
«Мы используем алгоритмы такого типа в целом ряде наших сервисов и проектов. Яндекс улучшает качество поиска с помощью Палеха, Auto.ru помогает выбрать оптимальный ракурс для фото автомобиля. Мы с коллегами использовали открытый код перенесения стиля, который написал наш коллега Дима Ульянов, и с его помощью сняли ролик о Кандинском. Кроме того, наш поиск по картинкам умеет искать их не по набору „тегов“, а по описанию того, что изображено на картинке. Применений много, планов тоже хватает, но мы о планах будем говорить по мере их реализации», — рассказывает о разработках Иван Ямщиков, ведущий аналитик и руководитель группы исследований новых продуктов «Яндекса».
Применений много, планов тоже хватает, но мы о планах будем говорить по мере их реализации», — рассказывает о разработках Иван Ямщиков, ведущий аналитик и руководитель группы исследований новых продуктов «Яндекса».
Поисковые машины в интернете, поиск музыки по звуковому оттиску Shazam, навигаторы, социальные сети, компьютерные игры — все это удивительные нейросети.
«Со временем программы типа Siri смогут самостоятельно бронировать билеты на самолет для владельца, заказывать продукты на дом и так далее», — считает разработчик Ашот Габрелянов.
5. Нейросети и творчество
Нейронные сети учатся и творить. «Яндекс» создал ролик к 150-летию Василия Кандинского, который раскрасила нейросеть в стиле художника. Она изучила все его работы и сделала то, на что человек не способен — вывела точный набор форм и цветов.
Точно так же сейчас программы учатся у людей писать стихи и не только. Например, нейросети дали проанализировать базу из 100 часов поп-музыки и предложили создать песню на заданную тему: ей показали фотографию елки. На основе основного набора слов (их оказалось всего три тысячи) она создала композицию с довольно складным текстом: «Я могу слышать музыку, идущую из зала, сказка, елка и много цветов».
Например, нейросети дали проанализировать базу из 100 часов поп-музыки и предложили создать песню на заданную тему: ей показали фотографию елки. На основе основного набора слов (их оказалось всего три тысячи) она создала композицию с довольно складным текстом: «Я могу слышать музыку, идущую из зала, сказка, елка и много цветов».
Neural Story Singing Christmas from Hang Chu on Vimeo.
«Пробу пера» судить строго не следует. Какую музыку и картины способен создать достаточно обученный искусственный интеллект — сложно представить.
Дарья Дементьева
% PDF-1.3
%
2904 0 объект
>
endobj
xref
2904 462
0000000016 00000 н.
0000009596 00000 п.
0000011435 00000 п.
0000011666 00000 п.
0000018188 00000 п.
0000018242 00000 п.
0000018296 00000 п.
0000018351 00000 п.
0000018405 00000 п.
0000018459 00000 п.
0000018513 00000 п.
0000018567 00000 п.
0000018621 00000 п.
0000018675 00000 п.
0000018729 00000 п.
0000018783 00000 п.
0000018837 00000 п.
0000018891 00000 п.
0000018945 00000 п.
0000018999 00000 н.
0000019053 00000 п.
0000019107 00000 п.
0000019161 00000 п.
0000019215 00000 п.
0000019269 00000 п.
0000019323 00000 п.
0000019377 00000 п.
0000019431 00000 п.
0000019485 00000 п.
0000019528 00000 п.
0000019582 00000 п.
0000019636 00000 п.
0000019690 00000 н.
0000019744 00000 п.
0000019799 00000 п.
0000019854 00000 п.
0000019908 00000 п.
0000019962 00000 п.
0000020016 00000 н.
0000020039 00000 н.
0000020654 00000 п.
0000020677 00000 п.
0000021181 00000 п.
0000021204 00000 п.
0000021709 00000 п.
0000021732 00000 п.
0000022263 00000 п.
0000022286 00000 п.
0000022814 00000 п.
0000022837 00000 п.
0000023350 00000 п.
0000023576 00000 п.
0000023780 00000 п.
0000024369 00000 п.
0000024858 00000 п.
0000024881 00000 п.
0000025424 00000 п.
0000029415 00000 п.
0000048708 00000 п.
0000048731 00000 п.
0000049729 00000 п.
0000076679 00000 п.
0000076797 00000 п.
0000076918 00000 п.
0000077089 00000 п.
0000077213 00000 п.
0000077337 00000 п.
0000077458 00000 п.
0000078015 00000 п.
0000078181 00000 п.
0000080860 00000 п.
0000081031 00000 п.
0000081233 00000 п.
0000081438 00000 п.
0000081646 00000 п.
0000081827 00000 п.
0000082008 00000 п.
0000082202 00000 п.
0000082428 00000 п.
0000082861 00000 п.
0000082941 00000 п.
0000083134 00000 п.
0000083345 00000 п.
0000083533 00000 п.
0000083648 00000 н.
0000083856 00000 п.
0000084064 00000 п.
0000084263 00000 п.
0000084444 00000 п.
0000084634 00000 п.
0000084761 00000 п.
0000084879 00000 п.
0000084994 00000 п.
0000085127 00000 п.
0000085623 00000 п.
0000085885 00000 п.
0000086129 00000 п.
0000086637 00000 п.
0000086838 00000 п.
0000087035 00000 п.
0000087250 00000 п.
0000087448 00000 п.
0000087646 00000 п.
0000087861 00000 п.
0000088049 00000 п.
0000088234 00000 п.
0000088447 00000 п.
0000088635 00000 п.
0000088820 00000 п.
0000089012 00000 п.
0000089204 00000 п.
0000089401 00000 п.
0000089598 00000 п.
0000089790 00000 н.
0000089996 00000 н.
00000
00000 00000 п.
00000 00000 п.
0000090806 00000 п.
0000091003 00000 п.
0000091195 00000 п.
0000091411 00000 п.
0000091599 00000 п.
0000091784 00000 п.
0000091978 00000 п.
0000092169 00000 п.
0000092363 00000 п.
0000092557 00000 п.
0000092748 00000 н.
0000092954 00000 п.
0000093160 00000 п.
0000093358 00000 п.
0000093556 00000 п.
0000093769 00000 п.
0000093963 00000 п.
0000094154 00000 п.
0000094374 00000 п.
0000094562 00000 п.
0000094747 00000 п.
0000094938 00000 п.
0000095123 00000 п.
0000095308 00000 п.
0000095496 00000 п.
0000095681 00000 п.
0000095869 00000 п.
0000096054 00000 п.
0000096238 00000 п.
0000096426 00000 п.
0000096614 00000 п.
0000096799 00000 н.
0000096983 00000 п.
0000097168 00000 п.

0000097353 00000 п.
0000097538 00000 п.
0000097726 00000 п.
0000097911 00000 п.
0000098131 00000 п.
0000098319 00000 п.
0000098504 00000 п.
0000098695 00000 п.
0000098880 00000 п.
0000099065 00000 н.
0000099253 00000 п.
0000099438 00000 п.
0000099626 00000 п.
0000099811 00000 н.
0000099995 00000 н.
0000100183 00000 н.
0000100371 00000 н.
0000100553 00000 н.
0000100737 00000 н.
0000100925 00000 н.
0000101107 00000 п.
0000101295 00000 н.
0000101483 00000 н.
0000101700 00000 н.
0000101888 00000 н.
0000102073 00000 н.
0000102268 00000 н.
0000102453 00000 п.
0000102638 00000 п.
0000102826 00000 н.
0000103011 00000 н.
0000103199 00000 п.
0000103384 00000 н.
0000103568 00000 н.
0000103756 00000 п.
0000103950 00000 н.
0000104134 00000 п.
0000104322 00000 н.
0000104517 00000 н.
0000104733 00000 н.
0000104921 00000 н.
0000105106 00000 п.
0000105291 00000 п.
0000105479 00000 п.
0000105664 00000 н.
0000105852 00000 п.
0000106036 00000 н.
0000106234 00000 н.

0000106431 00000 н.
0000106625 00000 н.
0000106809 00000 п.
0000106997 00000 н.
0000107185 00000 п.
0000107400 00000 н.
0000107588 00000 п.
0000107773 00000 н.
0000107958 00000 п.
0000108152 00000 п.
0000108352 00000 п.
0000108547 00000 н.
0000108741 00000 н.
0000108932 00000 н.
0000109116 00000 п.
0000109333 00000 п.
0000109521 00000 н.
0000109712 00000 н.
0000109900 00000 н.
0000110085 00000 н.
0000110279 00000 н.
0000110464 00000 н.
0000110659 00000 н.
0000110847 00000 н.
0000111029 00000 н.
0000111213 00000 н.
0000111401 00000 н.
0000111583 00000 н.
0000111771 00000 н.
0000111955 00000 н.
0000112174 00000 н.
0000112362 00000 н.
0000112550 00000 н.
0000112735 00000 н.
0000112920 00000 н.
0000113111 00000 п.
0000113296 00000 н.
0000113484 00000 н.
0000113672 00000 н.
0000113857 00000 н.
0000114041 00000 н.
0000114232 00000 н.
0000114417 00000 н.
0000114601 00000 н.
0000114785 00000 н.
0000114970 00000 н.
0000115158 00000 н.
0000115378 00000 п.

0000115585 00000 н.
0000115769 00000 н.
0000115957 00000 н.
0000116145 00000 н.
0000116333 00000 п.
0000116539 00000 н.
0000116727 00000 н.
0000116918 00000 п.
0000117106 00000 н.
0000117294 00000 н.
0000117482 00000 н.
0000117670 00000 н.
0000117858 00000 н.
0000118078 00000 н.
0000118278 00000 н.
0000118472 00000 н.
0000118657 00000 н.
0000118851 00000 н.
0000119039 00000 н.
0000119243 00000 н.
0000119441 00000 н.
0000119632 00000 н.
0000119830 00000 н.
0000120028 00000 н.
0000120226 00000 н.
0000120420 00000 н.
0000120640 00000 н.
0000120825 00000 н.
0000121007 00000 н.
0000121189 00000 н.
0000121377 00000 н.
0000121559 00000 н.
0000121741 00000 н.
0000121961 00000 н.
0000122146 00000 н.
0000122485 00000 н.
0000122739 00000 н.
0000122987 00000 н.
0000123184 00000 н.
0000123376 00000 н.
0000123585 00000 н.
0000123779 00000 н.
0000123970 00000 н.
0000124177 00000 н.
0000124368 00000 н.
0000124559 00000 н.
0000124765 00000 н.
0000124957 00000 н.
0000125154 00000 н.
0000125345 00000 н.
0000125536 00000 н.
0000125721 00000 н.
0000125913 00000 н.
0000126110 00000 н.
0000126307 00000 н.
0000126516 00000 н.
0000126716 00000 н.
0000126919 00000 н.
0000127104 00000 н.
0000127311 00000 н.
0000127511 00000 н.
0000127711 00000 н.
0000127902 00000 н.
0000128096 00000 н.
0000128284 00000 н.
0000128478 00000 н.
0000128669 00000 н.
0000128864 00000 н.
0000129077 00000 н.
0000129283 00000 н.
0000129489 00000 н.
0000129677 00000 н.
0000129897 00000 н.
0000130082 00000 н.
0000130270 00000 н.
0000130458 00000 п.
0000130643 00000 п.
0000130838 00000 п.
0000131033 00000 п.
0000131221 00000 н.
0000131409 00000 н.
0000131594 00000 н.
0000131782 00000 н.
0000131967 00000 н.
0000132151 00000 н.
0000132336 00000 н.
0000132524 00000 н.
0000132712 00000 н.
0000132900 00000 н.
0000133088 00000 н.
0000133276 00000 н.
0000133502 00000 н.
0000133690 00000 н.
0000133875 00000 п.
0000134070 00000 н.
0000134264 00000 н.

0000134462 00000 н.
0000134653 00000 п.
0000134844 00000 н.
0000135029 00000 н.
0000135217 00000 н.
0000135401 00000 н.
0000135586 00000 н.
0000135774 00000 н.
0000135962 00000 н.
0000136150 00000 н.
0000136345 00000 н.
0000136566 00000 н.
0000136754 00000 н.
0000136939 00000 н.
0000137134 00000 н.
0000137319 00000 н.
0000137507 00000 н.
0000137692 00000 н.
0000137880 00000 н.
0000138075 00000 н.
0000138270 00000 н.
0000138455 00000 н.
0000138643 00000 н.
0000138831 00000 н.
0000139015 00000 н.
0000139213 00000 н.
0000139398 00000 н.
0000139583 00000 н.
0000139807 00000 н.
0000139992 00000 н.
0000140180 00000 н.
0000140368 00000 н.
0000140553 00000 п.
0000140750 00000 н.
0000140938 00000 п.
0000141132 00000 н.
0000141317 00000 н.
0000141512 00000 н.
0000141700 00000 н.
0000141884 00000 н.
0000142068 00000 н.
0000142256 00000 н.
0000142457 00000 н.
0000142651 00000 н.
0000142877 00000 н.
0000143077 00000 н.
0000143268 00000 н.
0000143453 00000 н.

0000143644 00000 н.
0000143832 00000 н.
0000144029 00000 н.
0000144214 00000 н.
0000144405 00000 н.
0000144593 00000 п.
0000144781 00000 н.
0000144969 00000 н.
0000145157 00000 н.
0000145341 00000 п.
0000145544 00000 н.
0000145772 00000 н.
0000145964 00000 н.
0000146156 00000 н.
0000146341 00000 п.
0000146532 00000 н.
0000146720 00000 н.
0000146905 00000 н.
0000147093 00000 п.
0000147278 00000 н.
0000147466 00000 н.
0000147654 00000 н.
0000147838 00000 п.
0000148026 00000 н.
0000148214 00000 н.
0000148402 00000 н.
0000148586 00000 н.
0000148771 00000 н.
0000148956 00000 н.
0000149180 00000 н.
0000149362 00000 н.
0000149546 00000 н.
0000149737 00000 н.
0000149931 00000 н.
0000150122 00000 н.
0000150313 00000 н.
0000150504 00000 н.
0000150692 00000 н.
0000150880 00000 н.
0000151071 00000 н.
0000151259 00000 н.
0000151447 00000 н.
0000151653 00000 н.
0000151841 00000 н.
0000152029 00000 н.
0000152243 00000 н.
0000152441 00000 н.
0000152638 00000 н.
0000152823 00000 н.
0000153020 00000 н.
0000153211 00000 н.
0000153402 00000 н.
0000153593 00000 н.
0000153778 00000 н.
0000153973 00000 н.
0000154171 00000 н.
0000154371 00000 н.
0000154574 00000 н.
0000154769 00000 н.
0000154960 00000 н.
0000155174 00000 н.
0000155362 00000 н.
0000155553 00000 н.
0000155738 00000 н.
0000156058 00000 н.
0000156278 00000 н.
0000156497 00000 н.
0000156703 00000 н.
0000009697 00000 п.
0000011411 00000 п.
трейлер
]
>>
startxref
0
%% EOF
2905 0 объект
>
endobj
3364 0 объект
>
ручей
HU} Lg \ ~ x9 * ӂ3NAtl
utΏ`I2t1Ą, ̸Yc9ЕiW, h * X1fv) Iy {
% PDF-1.7
%
723 0 объект
>
endobj
xref
723 118
0000000016 00000 н.
0000003917 00000 н.
0000004214 00000 н.
0000004241 00000 п.
0000004294 00000 н.
0000004330 00000 н.
0000005025 00000 н.
0000005195 00000 н.
0000005353 00000 п.
0000005515 00000 н.
0000005647 00000 н.
0000005779 00000 н.
0000005912 00000 н.
0000006045 00000 н.
0000006178 00000 н.
0000006311 00000 н.
0000006436 00000 н.
0000006577 00000 н.
0000006725 00000 н.
0000006851 00000 н.
0000006991 00000 п.
0000007133 00000 п.
0000007286 00000 н.
0000007442 00000 н.
0000007596 00000 н.
0000007764 00000 н.
0000007899 00000 н.
0000007978 00000 н.
0000008055 00000 н.
0000008135 00000 н.
0000008214 00000 н.
0000008293 00000 п.
0000008372 00000 п.
0000008451 00000 п.
0000008530 00000 н.
0000008609 00000 н.
0000008687 00000 н.
0000008765 00000 н.
0000008843 00000 н.
0000008921 00000 н.
0000008999 00000 н.
0000009077 00000 н.
0000010236 00000 п.
0000010578 00000 п.
0000010928 00000 п.
0000011170 00000 п.
0000011628 00000 п.
0000011731 00000 п.
0000019265 00000 п.
0000019844 00000 п.
0000020240 00000 п.
0000020347 00000 п.
0000023726 00000 п.
0000027460 00000 п.
0000027861 00000 п.
0000028877 00000 п.
0000029125 00000 п.
0000032054 00000 п.
0000032426 00000 п.
0000032808 00000 п.
0000033561 00000 п.
0000033847 00000 п.
0000040529 00000 п.
0000040963 00000 п.
0000041337 00000 п.
0000041687 00000 п.
0000043582 00000 п.
0000044043 00000 п.
0000044446 00000 п.
0000044662 00000 п.
0000047413 00000 п.
0000049751 00000 п.
0000049913 00000 н.
0000050385 00000 п.
0000050586 00000 п.
0000054762 00000 п.
0000055110 00000 п.
0000055478 00000 п.
0000057680 00000 п.
0000059774 00000 п.
0000061975 00000 п.
0000064389 00000 п.
0000065422 00000 п.
0000067392 00000 п.
0000067663 00000 п.
0000067759 00000 п.
0000069254 00000 п.
0000069501 00000 п.
0000069835 00000 п.
0000069901 00000 н.
0000070334 00000 п.
0000070549 00000 п.
0000070835 00000 п.
0000071371 00000 п.
0000071493 00000 п.
0000119529 00000 н.
0000152408 00000 н.
0000152520 00000 н.
0000152578 00000 н.
0000152813 00000 н.
0000152929 00000 н.
0000153038 00000 н.
0000153172 00000 н.
0000153298 00000 н.
0000153463 00000 н.
0000153665 00000 н.
0000153827 00000 н.
0000153947 00000 н.
0000154183 00000 н.
0000154322 00000 н.
0000154464 00000 н.
0000154652 00000 н.
0000154785 00000 н.
0000154926 00000 н.
0000155094 00000 н.
0000155264 00000 н.
0000003729 00000 н.
0000002712 00000 н.
трейлер
] / Назад 3468512 / XRefStm 3729 >>
startxref
0
%% EOF
840 0 объект
> поток
hb«d`e`g`P ʀ
Neural Network Ppt Presentation
NEURAL NETWORKBY SIDDHARTH PATEL CLASS: IT-B (SEM: V) ENR.NO: 100530116032
СОДЕРЖАНИЕ Введение
:
Архитектура Человек
и искусственные нейроны Приложения Преимущества Недостатки Нейронная сеть в будущем Заключение
1. ВВЕДЕНИЕ.
1.1 ЧТО ТАКОЕ НЕЙРОННАЯ СЕТЬ? NN — это парадигма обработки информации. Ключевым элементом этой парадигмы является новая структура.
1.2 ПОЧЕМУ НЕЙРОСЕТИ? Адаптивное обучение. Самоорганизация. Операция в реальном времени.
2.АРХИТЕКТУРА.
2.1 СЕТЬ ПЕРЕДАЧИ ВПЕРЕД (АССОЦИАТИВНАЯ) Разрешить сигналы двигаться только в одну сторону; от входа к выходу. Отзывов нет. Обычно это прямые сети.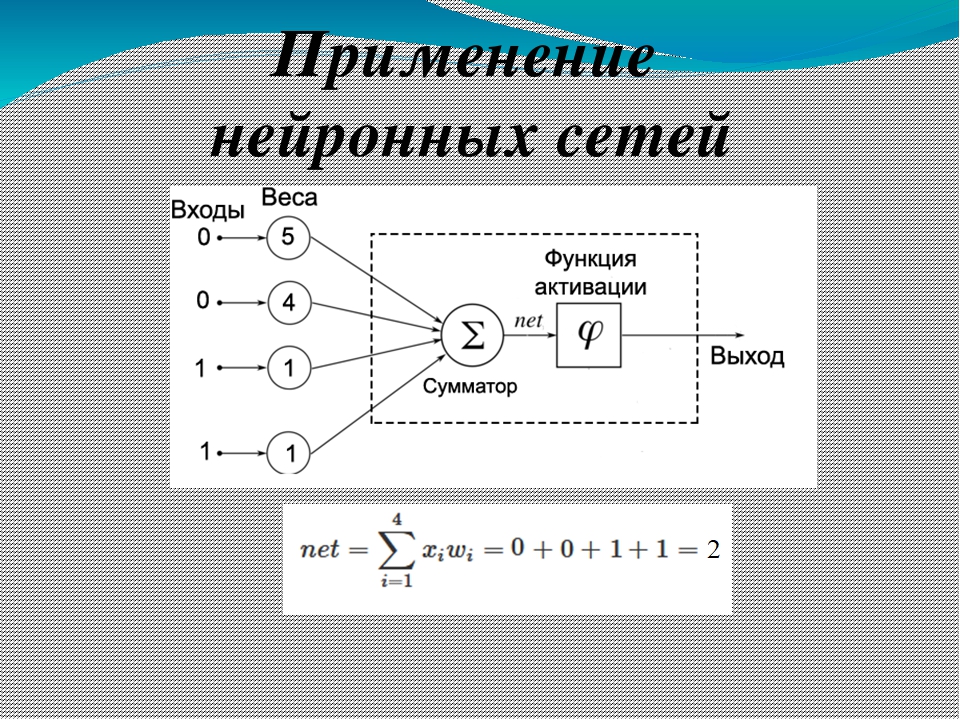
2.2 ОБРАТНАЯ СВЯЗЬ (АВТОМАТИЧЕСКАЯ АССОЦИАЦИЯ) СЕТЬ Сигналы, передающиеся в обоих направлениях. Это динамично. Их «состояние» постоянно меняется. Это очень мощно.
2.3 СЕТЕВЫЕ СЛОИ I.
II.
III.
Ввод: представляет необработанную информацию. Скрытый: определяется активностью входных единиц.Вывод: зависит от активности скрытых юнитов.
3. ЧЕЛОВЕЧЕСКИЕ И ИСКУССТВЕННЫЕ НЕЙРОНЫ
3.1 КАК ОБУЧАЕТ ЧЕЛОВЕЧЕСКИЙ МОЗГ Нейрон собирает сигналы от других через хост, называемый дендритами. Нейрон посылает импульсы электрической активности через длинную тонкую стойку, известную как аксон. Синапс преобразует активность аксона в электрические эффекты, которые возбуждают активность аксона в связанных нейронах.
Компоненты нейрона
Синапс
4.ПРИЛОЖЕНИЯ
4.1 НЕЙРОННЫЕ СЕТИ В БИЗНЕСЕ
Прогнозирование продаж Управление производственными процессами Исследование клиентов Проверка данных Управление рисками Целевой маркетинг
4. 2 НЕЙРОННЫЕ СЕТИ В МЕДИЦИНЕ
2 НЕЙРОННЫЕ СЕТИ В МЕДИЦИНЕ
кардиограммы CAT сканирует ультразвуковое сканирование и т. Д.
4.3 NEURAL BUSINESS NETWORKS Кредитование
ДРУГИЕ ПРИМЕНЕНИЯ Сжатие изображений с распознаванием символов Обработка пищевых продуктов Мониторинг сигнатур
5.ПРЕИМУЩЕСТВА: Адаптация к незнакомой ситуации. Автономное обучение и обобщение. Надежность: отказоустойчивость за счет резервирования сети. Шумостойкость Простота обслуживания
6. НЕДОСТАТКИ: Нет точных. Большая сложность сетевой структуры. NN необходимо обучение для работы. Требуется много времени на обработку для больших NN. NN иногда становятся нестабильными.
7.NEURAL NETWORK
В БУДУЩЕМ
Роботы, которые могут видеть, чувствовать и предсказывать мир вокруг себя. Составление музыки.Рукописные документы для автоматического преобразования в форматированные текстовые документы. Самостоятельная диагностика медицинских проблем с помощью нейронных сетей.
8. ЗАКЛЮЧЕНИЕ:
Их способность учиться на примере делает их очень гибкими и мощными.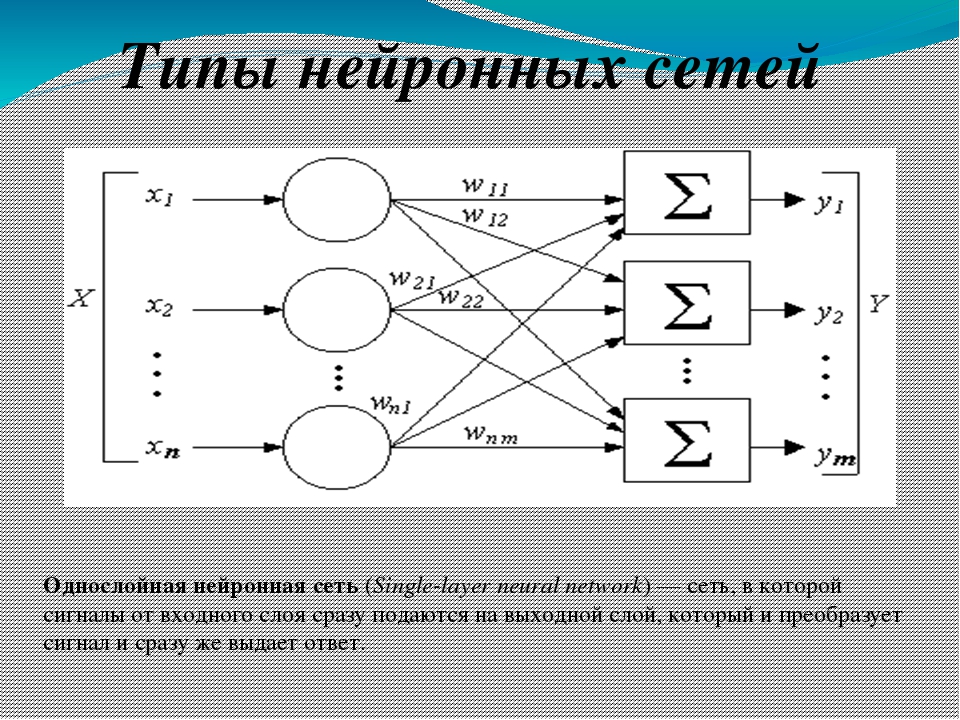 Нет необходимости разрабатывать алгоритм для выполнения конкретной задачи. Нет необходимости разбираться во внутренних механизмах этой задачи. Они также очень хорошо подходят для систем реального времени.
Нет необходимости разрабатывать алгоритм для выполнения конкретной задачи. Нет необходимости разбираться во внутренних механизмах этой задачи. Они также очень хорошо подходят для систем реального времени.
СПАСИБО
Распознавание объектов с использованием сверточных нейронных сетей
1.Введение
С компьютерным зрением связаны интересные проблемы, такие как классификация изображений и обнаружение объектов, которые являются частью области, называемой распознаванием объектов. В отношении этих типов проблем в последние годы наблюдается серьезная научная разработка, в основном из-за достижений сверточных нейронных сетей, методов глубокого обучения и увеличения вычислительной мощности параллелизма, предлагаемой графическими процессорами (ГП). Проблема классификации изображений — это задача присвоения входному изображению одной метки из фиксированного набора категорий.Эта проблема классификации является центральной в компьютерном зрении, потому что, несмотря на ее простоту, существует множество практических применений и множество применений, таких как маркировка изображений рака кожи [1], использование изображений с высоким разрешением для обнаружения стихийных бедствий, таких как наводнения.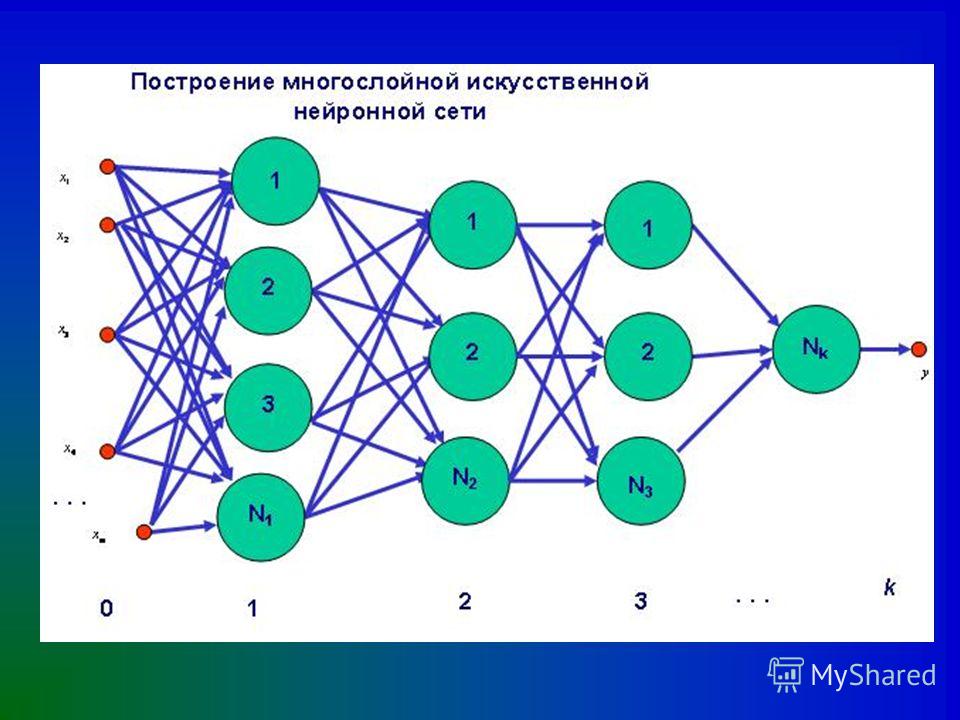 , вулканы и сильные засухи, отмечая воздействия и нанесенный ущерб [2, 3, 4].
, вулканы и сильные засухи, отмечая воздействия и нанесенный ущерб [2, 3, 4].
Эффективность алгоритмов классификации изображений в значительной степени зависит от функций, используемых для их подачи [5]. Это означает, что развитие методов классификации изображений с использованием машинного обучения в значительной степени зависело от инженерного подхода к выбору основных характеристик изображений, составляющих базу данных.Таким образом, получение этих ресурсов стало сложной задачей, что привело к увеличению сложности и вычислительных затрат. Обычно для классификации изображений, извлечения признаков и выбора алгоритма обучения требуются два независимых шага, которые были широко разработаны и усовершенствованы с использованием машин поддержки векторов (SVM).
Алгоритм SVM, рассматриваемый как часть подхода к обучению с учителем, часто используется для таких задач, как классификация, регрессия и обнаружение выбросов [6].Наиболее привлекательной особенностью этого алгоритма является то, что его механизм обучения для множества объектов проще поддается математическому анализу, чем традиционная архитектура нейронной сети, что позволяет вносить сложные изменения с известными эффектами на основные функции алгоритма [7]. По сути, SVM отображает обучающие данные в пространство признаков более высокого измерения и создает гиперплоскость разделения с максимальным запасом, создавая нелинейную границу разделения во входном пространстве [8].
По сути, SVM отображает обучающие данные в пространство признаков более высокого измерения и создает гиперплоскость разделения с максимальным запасом, создавая нелинейную границу разделения во входном пространстве [8].
Сегодня самые надежные алгоритмы классификации и обнаружения объектов используют архитектуры глубокого обучения со множеством специализированных уровней для автоматизации процесса фильтрации и извлечения признаков.Алгоритмы машинного обучения, такие как линейная регрессия, опорные векторные машины и деревья решений, имеют свои особенности в процессе обучения, но по сути все они применяют одинаковые шаги: сделать прогноз, получить корректировку и настроить механизм прогнозирования на основе исправления, на высоком уровне, что делает его очень похожим на то, как учится человек. Появилось глубокое обучение, приносящее новый подход к проблеме, который пытался преодолеть предыдущие недостатки путем изучения абстракции в данных в соответствии с парадигмой стратифицированного описания, основанной на нелинейном преобразовании [9]. Ключевым преимуществом глубокого обучения является его способность выполнять полууправляемое или неконтролируемое извлечение функций из массивных наборов данных.
Ключевым преимуществом глубокого обучения является его способность выполнять полууправляемое или неконтролируемое извлечение функций из массивных наборов данных.
Способность изучать этап извлечения признаков, присутствующий в алгоритмах на основе глубокого обучения, достигается благодаря широкому использованию сверточных нейронных сетей (ConvNet или CNN). В этом контексте свертка является специализированным типом линейной операции и может рассматриваться как простое применение фильтра к определенному входу [10]. Повторное применение одного и того же фильтра к входу приводит к созданию карты активаций, называемой картой характеристик, которая указывает расположение и силу обнаруженного элемента на входе путем настройки параметров свертки.Сеть может настраиваться, чтобы уменьшить ошибку и, следовательно, изучить лучшие параметры для извлечения соответствующей информации в базе данных.
В последние несколько лет было предложено много детекторов объектов на основе глубоких нейронных сетей (DNN) [11, 12]. Это исследование исследует производительность современных моделей DNN SSD и Faster RCNN, примененных к классической задаче обнаружения, когда алгоритмы были обучены идентифицировать несколько животных на изображениях; Кроме того, чтобы проиллюстрировать применение в научных исследованиях, сеть YOLO была обучена решать проблему слежения за мышами.Текущие разделы описывают модели DNN, упомянутые ранее, более подробно [13, 14, 15].
Это исследование исследует производительность современных моделей DNN SSD и Faster RCNN, примененных к классической задаче обнаружения, когда алгоритмы были обучены идентифицировать несколько животных на изображениях; Кроме того, чтобы проиллюстрировать применение в научных исследованиях, сеть YOLO была обучена решать проблему слежения за мышами.Текущие разделы описывают модели DNN, упомянутые ранее, более подробно [13, 14, 15].
2. Методы обнаружения объектов
2.1 Одноразовый многоблочный детектор
Одноканальный многоканальный детектор [13] — один из лучших детекторов с точки зрения скорости и точности, состоящий из двух основных этапов: извлечения карты признаков и приложений сверточного фильтра. обнаруживать объекты.
Архитектура SSD построена на сети VGG-16 [16], и этот выбор был сделан на основе высокой производительности в задачах классификации изображений высокого качества и популярности сети в задачах, где задействовано трансферное обучение.Вместо исходных полносвязных слоев VGG, набор вспомогательных сверточных слоев изменяет модель, что позволяет извлекать элементы в нескольких масштабах и постепенно уменьшать размер входных данных для каждого последующего слоя.
Генерация ограничивающей рамки рассматривает применение сопоставления предварительно вычисленных ограничивающих прямоугольников фиксированного размера, называемых априори , с исходным распределением наземных блоков истинности. Эти априорные числа выбраны для сохранения отношения пересечения к объединению (IoU) равным или большим 0.5.
Общая функция потерь, определенная в формуле. (1) представляет собой линейную комбинацию потери уверенности, которая измеряет, насколько сеть уверена в вычисленном ограничивающем прямоугольнике с использованием категориальной кросс-энтропии и потери местоположения, которая измеряет, насколько далеко предсказанные сетью ограничивающие прямоугольники находятся от наземных ограничивающих прямоугольников с использованием L2 норма.
Lxclg = 1NLconfxc + αLlocxlgE1
, где N — количество согласованных блоков по умолчанию, а Lconfand Lloc — достоверность и потеря местоположения, соответственно, как определено в [13]. На рисунке 1 показано, как применить сверточные ядра к входному изображению в архитектуре SSD.
На рисунке 1 показано, как применить сверточные ядра к входному изображению в архитектуре SSD.
Рисунок 1.
Сеть SSD имеет несколько слоев объектов до конца базовой сети, которые прогнозируют смещения к стандартным прямоугольникам с различными масштабами, соотношениями сторон и их соответствующими достоверностями. Рисунок основан на [13].
2.2 Вы смотрите только один раз
Вы смотрите только один раз [14] — это современный алгоритм обнаружения объектов, предназначенный для приложений реального времени, и, в отличие от некоторых конкурентов, это не традиционный классификатор, предназначенный для детектор объекта.
YOLO работает, разделяя входное изображение на сетку ячеек S × S, где каждая из этих ячеек отвечает за пять предсказаний ограничивающих прямоугольников, которые описывают прямоугольник вокруг объекта. Он также выводит показатель достоверности, который является мерой уверенности в том, что объект был заключен. Следовательно, оценка не имеет никакого отношения к типу объекта, присутствующему в коробке, только к форме коробки.
Для каждого прогнозируемого ограничивающего прямоугольника прогнозируемый класс работает точно так же, как обычный классификатор, давая в результате распределение вероятностей по всем возможным классам.Оценка достоверности для ограничивающего прямоугольника и предсказания класса объединяется в одну окончательную оценку, которая указывает вероятность того, что каждый прямоугольник включает определенный тип объекта. При таком выборе дизайна большинство блоков будут иметь низкие оценки достоверности, поэтому сохраняются только блоки, окончательная оценка которых превышает пороговое значение.
Ур. (2) устанавливает функцию потерь, минимизированную на этапе обучения в алгоритме YOLO.
λcoord∑i = 0s2∑j = 0B1ijobjxi − x̂i2 + yi − ŷi2 + λcoord∑i = 0s2∑j = 0B1ijobjwi − ŵi2 + hi − ĥi2
+ ∑i = 0s2∑j = 0B1ordiiC = 0s2∑j = 0B1ijobjCi − Ĉi2 + ∑i = 0s2∑c∈classespic − p̂ic2E2
, где 1iobj указывает, появляется ли объект в ячейке i, а 1ijobj обозначает предиктор j-го ограничивающего прямоугольника в ячейке, ответственной за этот прогноз; x, y, w, h и C обозначают координаты, которые представляют центр прямоугольника относительно границ ячейки сетки. Прогнозы ширины и высоты относятся ко всему изображению. Наконец, C обозначает предсказание достоверности, то есть IoU между предсказанным блоком и любым наземным блоком истинности.
Прогнозы ширины и высоты относятся ко всему изображению. Наконец, C обозначает предсказание достоверности, то есть IoU между предсказанным блоком и любым наземным блоком истинности.
Рисунок 2 описывает процесс обработки сети YOLO в виде образа. Первоначально входные данные проходят через CNN, создавая ограничивающие прямоугольники с ее оценками уверенности перспектив и генерируя карту вероятностей классов. Наконец, результаты предыдущих шагов объединяются для формирования окончательных прогнозов.
Рисунок 2.
Обнаружение модели YOLO как проблема регрессии [17]. Таким образом, входное изображение делится на сетку S × S, и для каждой ячейки сетки прогнозируются ограничивающие прямоугольники B, достоверность для этих полей и вероятности класса C. Эти закодированные прогнозы представляют собой тензор S × S × B ∗ 5 + C. Рисунок основан на [17].
2.3 Сверточная нейронная сеть с более быстрой областью
Сверточная нейронная сеть с более быстрой областью [15] — это еще один современный подход к обнаружению объектов глубокого обучения на основе CNN. В этой архитектуре сеть переносит предоставленное входное изображение в сверточную сеть, которая обеспечивает сверточную карту признаков. Вместо использования алгоритма выборочного поиска для идентификации предложений по регионам, сделанных в предыдущих итерациях [18, 19], используется отдельная сеть для изучения и прогнозирования этих регионов. Затем предложения прогнозируемой области изменяются с использованием слоя объединения интересующей области (ROI), который затем используется для классификации изображения в предложенной области и прогнозирования значений смещения для ограничивающих прямоугольников.
В этой архитектуре сеть переносит предоставленное входное изображение в сверточную сеть, которая обеспечивает сверточную карту признаков. Вместо использования алгоритма выборочного поиска для идентификации предложений по регионам, сделанных в предыдущих итерациях [18, 19], используется отдельная сеть для изучения и прогнозирования этих регионов. Затем предложения прогнозируемой области изменяются с использованием слоя объединения интересующей области (ROI), который затем используется для классификации изображения в предложенной области и прогнозирования значений смещения для ограничивающих прямоугольников.
Стратегия, лежащая в основе обучения сети предложения региона (RPN), заключается в использовании двоичной метки для каждого якоря, так что цифра один будет представлять присутствие объекта, а цифра ноль — отсутствие; с этой стратегией любое значение IoU больше 0,7 определяет присутствие объекта, а значение меньше 0,3 указывает на его отсутствие.
Таким образом, функция потери многозадачности, показанная в формуле. (3) сводится к минимуму на этапе обучения.
(3) сводится к минимуму на этапе обучения.
Lpiti = 1Ncls∑iLclspipi ∗ + λ1Nreg∑ipi ∗ Lregtiti ∗ E3
, где i — индекс якоря в пакете, pi — прогнозируемая вероятность того, что он является объектом, pi ∗ — истинная вероятность якоря, tiis прогнозируемая координата ограничивающего прямоугольника, ti ∗ — координата ограничивающего прямоугольника на основании истинных данных, а Lcls и Lreg — потери классификации и регрессии соответственно.
На рисунке 3 изображена объединенная сеть для обнаружения объектов, реализованная в архитектуре Faster RCNN. Используя популярную в последнее время терминологию нейронных сетей с механизмами «внимания» [20], сетевой модуль предложения региона сообщает модулю Fast RCNN, где искать [15].
Рисунок 3.
Faster RCNN действует как единая унифицированная сеть для обнаружения объектов [15]. Сетевой модуль регионального предложения служит «вниманием» этой объединенной сети. Рисунок основан на [15].
3. Наборы данных
Образец набора данных PASCAL VOC [21] используется для иллюстрации использования алгоритмов обнаружения объектов SSD и RCNN. Были отобраны 6 классов из 20 имеющихся. Таблица 1 описывает размер выборки, выбранный для каждого класса.
Были отобраны 6 классов из 20 имеющихся. Таблица 1 описывает размер выборки, выбранный для каждого класса.
| Класс | Количество изображений | |
|---|---|---|
| Птица | 811 | |
| Кот | 1128 | |
| Овцы | 357 | |
| Итого | 4163 |
Таблица 1.
Описание набора сетевых данных SSD и RCNN.
Изображения, представленные в наборе данных, были случайным образом разделены следующим образом: 1911 для обучения, соответствующего 50%, 1126 для проверки, соответствующего 25%, и теста, также соответствующего 25%.
Чтобы дополнительно проиллюстрировать применение таких алгоритмов в научных исследованиях, был также проанализирован набор данных, используемый для сети YOLO, представленный в [22].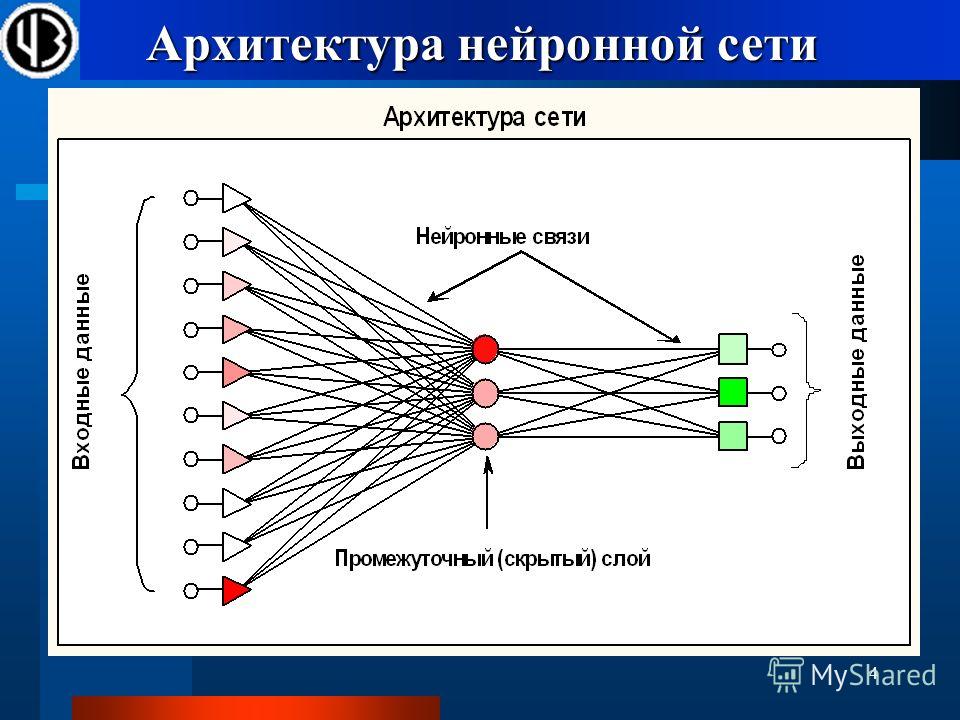 Как описано в [22], набор данных состоит из изображений трех исследований, включающих поведенческие эксперименты с мышами:
Как описано в [22], набор данных состоит из изображений трех исследований, включающих поведенческие эксперименты с мышами:
Этологическая оценка [23]: в этом исследовании представлены новые показатели для моделей хронического стресса социального поражения у мышей.
Автоматизированная домашняя клетка [24]: В этом исследовании представлена обучаемая система компьютерного зрения, которая позволяет автоматически анализировать сложное поведение мыши; они едят, пьют, ухаживают, вешают, микродвижение, спина, отдых и ходят.
Набор данных Caltech Resident-Intruder Mouse (CRIM13) [25]: он содержит видео, записанные с превосходной и синхронизированной боковой визуализацией пар мышей, участвующих в социальном поведении в 13 различных действиях.
Таблица 2 описывает размер выборки, выбранный из каждого из наборов данных, используемых в этом документе.Для этологической оценки [23] было использовано 3707 рамок, снятых на виде сверху арены экспериментов по социальному взаимодействию среди мышей. Для автоматизированной домашней клетки [24] выборка из 3073 рамок была выбрана из бокового обзора поведенческих экспериментов. Для CRIM13 [25] было выбрано 6842 кадра, из которых 3492 — вид сбоку и 3350 — вид сверху.
Для автоматизированной домашней клетки [24] выборка из 3073 рамок была выбрана из бокового обзора поведенческих экспериментов. Для CRIM13 [25] было выбрано 6842 кадра, из которых 3492 — вид сбоку и 3350 — вид сверху.
| Набор данных | Количество изображений | Разрешение | |
|---|---|---|---|
| Этологическая оценка [23] | 3707 | 640 × 480 | 320 × 240 |
| CRIM13 [25] | 6842 | 656 × 490 | |
| Всего | 13,622 |
Таблица 2.
Описание набора данных для использования с сетью YOLO, как ранее использовалось в [22].
Было воспроизведено то же разделение набора данных, что и в [22], что дало 6811 изображений для обучения, 3405 для проверки и 3406 для теста.
4. Материал и методы обнаружения объектов
В этой работе сравниваются ранее описанные сети SDD и Faster RCNN в задаче локализации и отслеживания шести видов животных в разнообразных средах. Наличие точной, подробной и актуальной информации о местонахождении и поведении животных в дикой природе улучшило бы нашу способность изучать и сохранять экосистемы [26].Кроме того, результаты сети YOLO, воспроизведенные из [22], для обнаружения и отслеживания мышей в видео записываются во время экспериментов по поведенческой нейробиологии. Задача обнаружения мышей состоит в определении места на изображении, где присутствуют животные, для каждого полученного кадра.
Представленная здесь вычислительная разработка была выполнена на компьютере с процессором AMD Athlon II X2 B22 с тактовой частотой 2,8 ГГц, 8 ГБ ОЗУ, графическим процессором NVIDIA GeForce GTX 10708 ГБ, ОС Ubuntu 18.04LTS, CUDA 9 и CuDNN 7.В нашем подходе использовались сверточные сети, описанные в разделе 2.
5. Результаты и вывод
 Результаты и вывод
Результаты и вывод Результаты, полученные для сетей SSD и Faster RCNN в экспериментах, были основаны на анализе 4163 изображений, организованных в соответствии с набором данных, описанным в разделе 3.
На рисунке 4 (а) показано возрастающее развитие средних значений средней точности в эпохи обучения. Обе архитектуры достигли высокой средней точности (mAP), успешно минимизировав значения соответствующих функций потерь.Сеть Faster RCNN показала более высокую и лучшую стабильность в точности, о чем можно судить по плавности ее кривой. Рисунок 4 (b) представляет собой прямоугольную диаграмму времени, затраченного каждой сетью на классификацию одного изображения, в то время как SSD опередил 17 ± 2 мс в качестве среднего и стандартного отклонения, а Faster RCNN перевел его более высокую вычислительную сложность. во время выполнения со средними значениями 30 ± 2 мсек и стандартным отклонением соответственно.
Рис. 4.
(a) Сравнение моделей mAP во время фазы обучения. (b) Время, затраченное на выполнение каждой архитектуры на одном изображении.
(b) Время, затраченное на выполнение каждой архитектуры на одном изображении.
В таблице 3 представлены дополнительные результаты, связанные с производительностью обнаружения объектов. Во-первых, он показывает среднюю среднюю точность, которая представляет собой среднее значение средней точности для каждого класса, где средняя точность — это среднее значение 11 точек на кривой точности-отзыва для каждого возможного порога, то есть вся вероятность обнаружение для того же класса (оценка точности-отзыва в соответствии с условиями, описанными в PASCAL VOC [21]).
| Сеть | Framework | Средняя точность (%) | |||
|---|---|---|---|---|---|
| Fast RCNN | GluonCV [27] | 96.07 | GluonCV [27] | 96.07 | GluonCV [27] 84,35 |
Таблица 3.
Средние результаты средней точности после 100 эпох обучения.
На рисунке 5 показаны некоторые избранные примеры результатов обнаружения объектов в используемом наборе данных.Каждое окно вывода связано с меткой категории и оценкой softmax в 01. Пороговое значение оценки 0,5 используется для отображения этих изображений.
Рисунок 5.
Примеры выходных сетей. (a) — (d) относятся к SSD и (e) — (i) к более быстрому RCNN.
Наш подход, как и в [22], также использовал две версии сети YOLO для обнаружения мышей в трех различных экспериментальных установках. Полученные результаты были основаны на анализе 13 622 изображений, организованных в соответствии с набором данных, описанным в разделе 3.
Первой обучаемой версией YOLO была сеть YOLO Full, в которой использовалась сверточная архитектура Darknet-53 [14], включающая 53 сверточных слоя. Такая модель была обучена, как описано в [17], начиная с предварительно обученной модели ImageNet [28]. Для каждой модели требуется 235 МБ дискового пространства. Мы использовали пакет из восьми изображений, импульс 0,9 и уменьшение веса 5 × 10–4. На обучение модели ушло 140 часов.
Для каждой модели требуется 235 МБ дискового пространства. Мы использовали пакет из восьми изображений, импульс 0,9 и уменьшение веса 5 × 10–4. На обучение модели ушло 140 часов.
Также была обучена меньшая и более быстрая альтернатива YOLO, получившая название YOLO Tiny.Чтобы ускорить процесс, эта «крошечная» версия содержит только часть ресурсов Darknet-53 [14]: 23 сверточных слоя. Для каждой модели требуется всего 34 МБ дискового пространства. Обучение сети происходит так, как описано в [17], при тонкой настройке предварительно обученной модели ImageNet [28]. Мы использовали пакет из 64 изображений, импульс 0,9 и уменьшение веса 5 × 10–4. На обучение модели ушло 18 часов.
На рисунке 6 показано сравнение двух использованных моделей YOLO, YOLO Full и Tiny. Рисунок 6 (а) демонстрирует высокую точность полной архитектуры с небольшими колебаниями кривой точности во время обучения.На рис. 6 (б) высокая точность сохраняется с самых ранних времен и остается практически неизменной до предельного числа эпох. Обе архитектуры достигли высоких значений средней средней точности, при этом успешно минимизировали значения их функции потерь. Крошечная версия сети YOLO показала лучшую стабильность в точности, о чем можно судить по плавности ее кривой. Результаты показывают, что средняя средняя точность, достигнутая этой повторной реализацией, составила 90,79 и 90,75% для полной и миниатюрной версий YOLO соответственно.Использование версии Tiny — хорошая альтернатива для экспериментальных проектов, требующих отклика в реальном времени.
Обе архитектуры достигли высоких значений средней средней точности, при этом успешно минимизировали значения их функции потерь. Крошечная версия сети YOLO показала лучшую стабильность в точности, о чем можно судить по плавности ее кривой. Результаты показывают, что средняя средняя точность, достигнутая этой повторной реализацией, составила 90,79 и 90,75% для полной и миниатюрной версий YOLO соответственно.Использование версии Tiny — хорошая альтернатива для экспериментальных проектов, требующих отклика в реальном времени.
Рисунок 6.
(a) и (b) Эволюция архитектуры YOLO с точки зрения средней средней точности и минимизация функции потерь на этапе обучения. (c) Время GPU, необходимое для получения классификации изображения в каждой из сетей.
Рисунок 6 (c) представляет собой гистограмму, показывающую среднее время, затраченное на классификацию одного изображения в обеих архитектурах. Меньший размер версии Tiny получает прямой перевод во время выполнения, имея 0. 08 ± 0,06 с в качестве значений среднего и стандартного отклонения, тогда как полная версия имеет 0,36 ± 0,16 с в качестве значений среднего и стандартного отклонения соответственно.
08 ± 0,06 с в качестве значений среднего и стандартного отклонения, тогда как полная версия имеет 0,36 ± 0,16 с в качестве значений среднего и стандартного отклонения соответственно.
Учитывая вышеупомянутую небольшую разницу между двумя версиями детектора объектов YOLO, возможность разработки систем реального времени для экспериментов с отслеживанием животных становится ближе к реальности с архитектурой Tiny. Благодаря меньшему спросу на вычислительную мощность системы, в которых выполняются действия во время эксперимента, могут быть спроектированы без вмешательства человека.
На рисунке 7 показаны некоторые примеры, полученные в результате отслеживания мышей, выполненного с использованием трех различных наборов данных. Таким образом, можно проверить работу отслеживания мыши в разных сценариях. В (a) — (c) черная мышь появляется на белом фоне, видео записывается с камеры вида сверху в типичной конфигурации в поведенческих экспериментах. На рисунках (d) — (f) камера была расположена сбоку от экспериментального бокса; алгоритм правильно выполнил трекинг для разных положений животного. Наконец, на рисунках (g) — (i) изображения были записаны камерой вида сверху, и можно проверить большой объем информации помимо отслеживаемого объекта. Однако алгоритм работал очень хорошо даже для двух животных на одной арене.
Наконец, на рисунках (g) — (i) изображения были записаны камерой вида сверху, и можно проверить большой объем информации помимо отслеживаемого объекта. Однако алгоритм работал очень хорошо даже для двух животных на одной арене.
Рис. 7.
Примеры вывода сети YOLO. (a) — (c) относятся к этологической оценке [23], (d) — (f) относятся к автоматизированной домашней клетке [24], и (g) — (i) относятся к CRIM13 [25].
В этой главе представлен обзор методов машинного обучения с использованием сверточных нейронных сетей для обнаружения объектов изображения.Были представлены основные алгоритмы решения данного типа задач: Faster RCNN, YOLO и SSD. Чтобы проиллюстрировать работу алгоритмов, были выбраны наборы данных, признанные в научной литературе и в области компьютерного зрения, были проведены тесты и представлены результаты, показывающие преимущества и различия каждого из методов. Ожидается, что это содержание послужит справочным материалом для исследователей и тех, кто интересуется этой широко развивающейся областью знаний.
В настоящий момент мы переживаем эру приложений машинного обучения, и в ближайшие годы многое предстоит разработать на основе использования и улучшения этих методов.Вскоре ожидаются дальнейшие улучшения в разработке еще более специфического оборудования и фундаментальные изменения в соответствующей математической теории, что сделает искусственный интеллект все более актуальным и важным в современном мире.
9 Нейронные сети: Вычислительная нейронаука: окно в понимание того, как работает мозг | Наука на рубеже
эээ, сказал Кох. «Если вы откроете книгу о восприятии, вы увидите такие вещи, как« буфер ввода »,« ЦП »и тому подобное, и они используют язык, который предлагает вам увидеть объект в реальном мире и открыть компьютерный файл в мозгу, чтобы идентифицировать Это.«
Нейрофизиологи, в частности, предпочитали уделять внимание деталям и сложностям, а не цепляться за теории и закономерности, которые иногда, кажется, уходят в страну чудес. «Как нейробиолог я должен спросить, — сказал Кох, — где этот входной буфер? Что означает« открыть файл в мозгу »?»
«Как нейробиолог я должен спросить, — сказал Кох, — где этот входной буфер? Что означает« открыть файл в мозгу »?»
Биологические системы в сущности динамичны в парадигме неодарвиновской эволюции. Эволюция создавала мозг, так сказать, шаг за шагом.При каждом случайном морфологическом изменении испытанию на выживание отвечал не общий план, подвергнутый сознательному самоанализу, а скорее организм, который развил определенный набор черт. «Эволюция не может начаться с нуля», — писали Черчленд и др. (1990), «даже тогда, когда оптимальный дизайн потребует этого курса. Как заметил Якоб [1982], эволюция — это мелочь, и она создает свои модификации из доступных материалов, ограниченных более ранними решениями. Более того, любой заданной способностью.. . может выглядеть прекрасно продуманным дизайном, но на самом деле он может совсем не интегрироваться с более широкой системой и может быть несовместим с общим устройством нервной системы »(стр. 47). Таким образом, они заключают, в согласии с Адамсом , «нейробиологические ограничения стали признаны важными для проекта» (стр.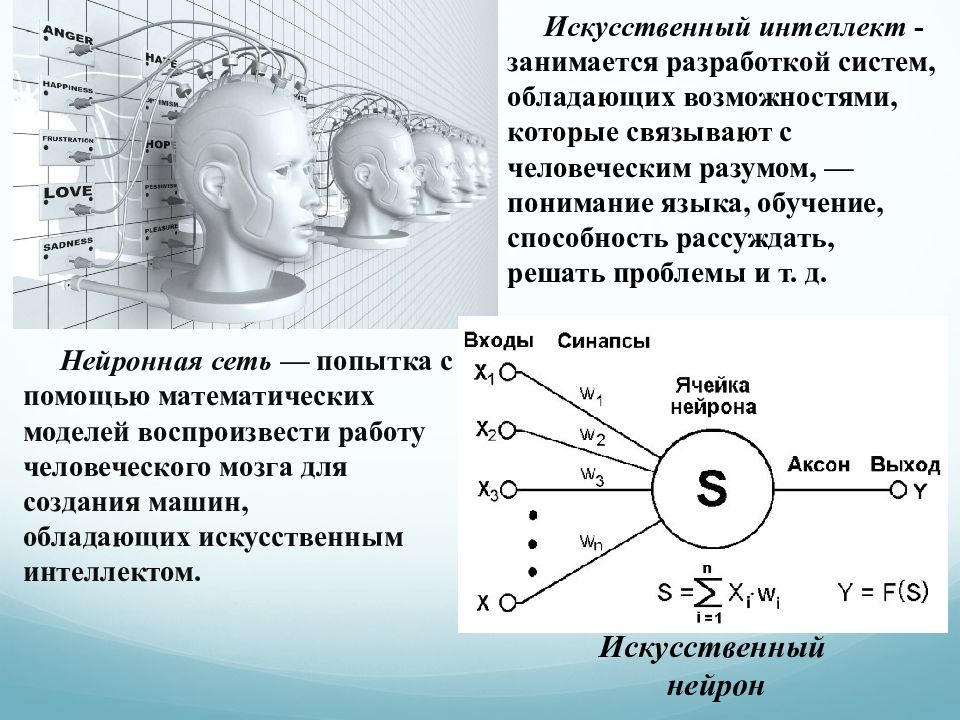 47).
47).
Если мозг действительно обладает чем-то аналогичным компьютерным программам, они явно встроены в схему связей и в миллиарды ячеек, из которых состоит этот мозг, то же самое место, где должна храниться его память.Это место — местность, которую Адамс исследовал в молекулярных деталях. «Я действительно не верю, что мы имеем дело с отношениями между программным и аппаратным обеспечением, когда мозг обладает прозрачной программой, которая будет одинаково хорошо работать на любом типе компьютера. Между существует такая интимная связь, — подчеркнул он. как, , мозг выполняет вычисления и вычисления, которые он делает, что вы не можете понять одно без другого ». С этим согласны почти все современные нейробиологи.
Параллельный распределенный путь к новым открытиям
К моменту смерти Марра в 1981 году искусственный интеллект не смог предоставить очень убедительные модели глобальной функции мозга (в целом и памяти в частности), и стали очевидны два важных вывода.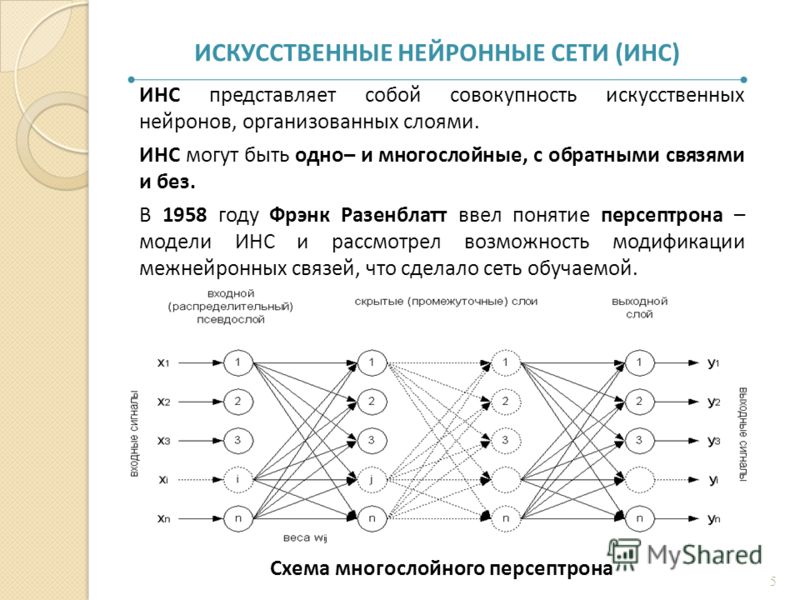 Во-первых, мозг ни по структуре, ни по функциям не похож на последовательный компьютер. Во-вторых, поскольку памяти не могло быть как
Во-первых, мозг ни по структуре, ни по функциям не похож на последовательный компьютер. Во-вторых, поскольку памяти не могло быть как
Введение в нейронные сети в приложении к играм
Исходная статья опубликована Intel Game Dev на VentureBeat *: введение в нейронные сети с приложением для игр. Узнайте больше новостей разработчиков игр и связанных тем от Intel на VentureBeat.
От: Дин Макри
Введение
Распознавание речи, распознавание рукописного ввода, распознавание лиц : это лишь некоторые из многих задач, которые мы, люди, можем быстро решить, но которые представляют собой все возрастающую проблему для компьютерных программ.Кажется, мы можем без особых усилий выполнять задачи, которые в некоторых случаях невозможно решить даже самыми сложными компьютерными программами. Возникает очевидный вопрос: «В чем разница между компьютерами и нами?» .
Мы не собираемся полностью отвечать на этот вопрос, но мы собираемся вводно взглянуть на один из его аспектов. Короче говоря, биологическая структура человеческого мозга образует массивную параллельную сеть простых вычислительных блоков, которые были обучены быстро решать эти проблемы.Эта сеть при моделировании на компьютере называется искусственной нейронной сетью или для краткости нейронной сетью.
Короче говоря, биологическая структура человеческого мозга образует массивную параллельную сеть простых вычислительных блоков, которые были обучены быстро решать эти проблемы.Эта сеть при моделировании на компьютере называется искусственной нейронной сетью или для краткости нейронной сетью.
На рис. 1 показан снимок экрана из простой игры, которую я собрал для исследования концепции. Идея проста: есть два игрока, у каждого из которых есть ракетка, и мяч, который подпрыгивает между ними. Каждый игрок пытается поставить ракетку так, чтобы мяч отскочил назад к другому игроку. Я использовал нейронную сеть для управления движением лопастей и с помощью обучения (мы рассмотрим это позже) научил нейронные сети хорошо играть в игру (если быть точным, то точно).
Рисунок 1: Простая игра в пинг-понг для экспериментов
В этой статье я расскажу о теории, лежащей в основе одного подмножества обширной области нейронных сетей: сетей обратного распространения.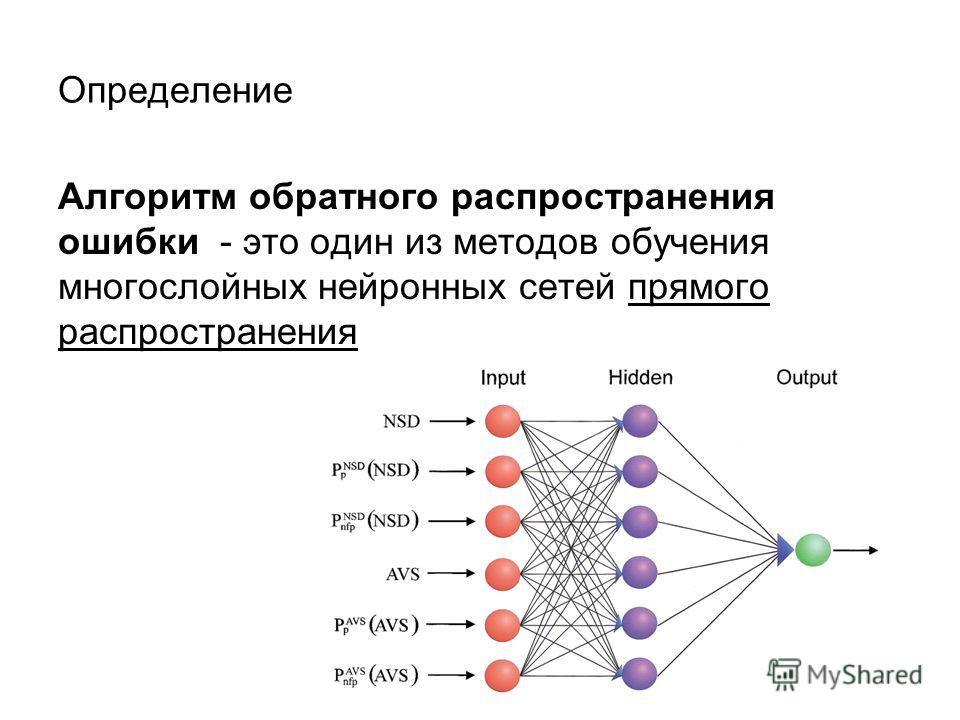 Я расскажу об основах и реализации только что описанной игры. Наконец, я опишу некоторые другие области, в которых нейронные сети могут использоваться для решения сложных задач. Мы начнем с упрощенного взгляда на то, как нейроны работают в вашем и моем мозге.
Я расскажу об основах и реализации только что описанной игры. Наконец, я опишу некоторые другие области, в которых нейронные сети могут использоваться для решения сложных задач. Мы начнем с упрощенного взгляда на то, как нейроны работают в вашем и моем мозге.
Основы нейронной сети
Нейроны в мозге
Вскоре после начала 20-го века испанский анатом Рамон-и-Кахаль представил идею нейронов как компонентов, составляющих работу человеческого мозга.Позже в работе других были добавлены подробности о аксонах или выходных связях между нейронами и о дендритах , которые являются рецептивными входами для нейрона, как показано на рисунке 2.
Рисунок 2: Упрощенное представление реального нейрона
Говоря упрощенно, нейрон функционально принимает множество входных сигналов и объединяет их, чтобы произвести либо возбуждающий, либо тормозящий выход в виде небольшого импульса напряжения. Затем выходной сигнал передается по аксону на множество входов (потенциально десятков тысяч) других нейронов.Имея примерно 1010 нейронов и 6 × 1013 соединений в человеческом мозге, неудивительно, что мы можем выполнять сложные процессы, которые выполняем. В нервных системах массивная параллельная обработка компенсирует медленную (миллисекунду +) скорость обрабатывающих элементов (нейронов).
Затем выходной сигнал передается по аксону на множество входов (потенциально десятков тысяч) других нейронов.Имея примерно 1010 нейронов и 6 × 1013 соединений в человеческом мозге, неудивительно, что мы можем выполнять сложные процессы, которые выполняем. В нервных системах массивная параллельная обработка компенсирует медленную (миллисекунду +) скорость обрабатывающих элементов (нейронов).
В оставшейся части этой статьи мы рассмотрим, как искусственные нейроны, основанные на только что описанной модели, можно использовать для имитации поведения, общего для людей и других животных. Хотя мы не можем смоделировать 10 миллиардов нейронов с 60 триллионами соединений, мы можем дать вам простого достойного противника, который обогатит вашу игру.
Искусственные нейроны
Используя только что обсужденную простую модель, исследователи в середине 20-го века разработали математические модели для моделирования работы нейронов в головном мозге. Они предпочли проигнорировать некоторые аспекты реальных нейронов, такие как снижение частоты пульса, и придумали простую для понимания модель.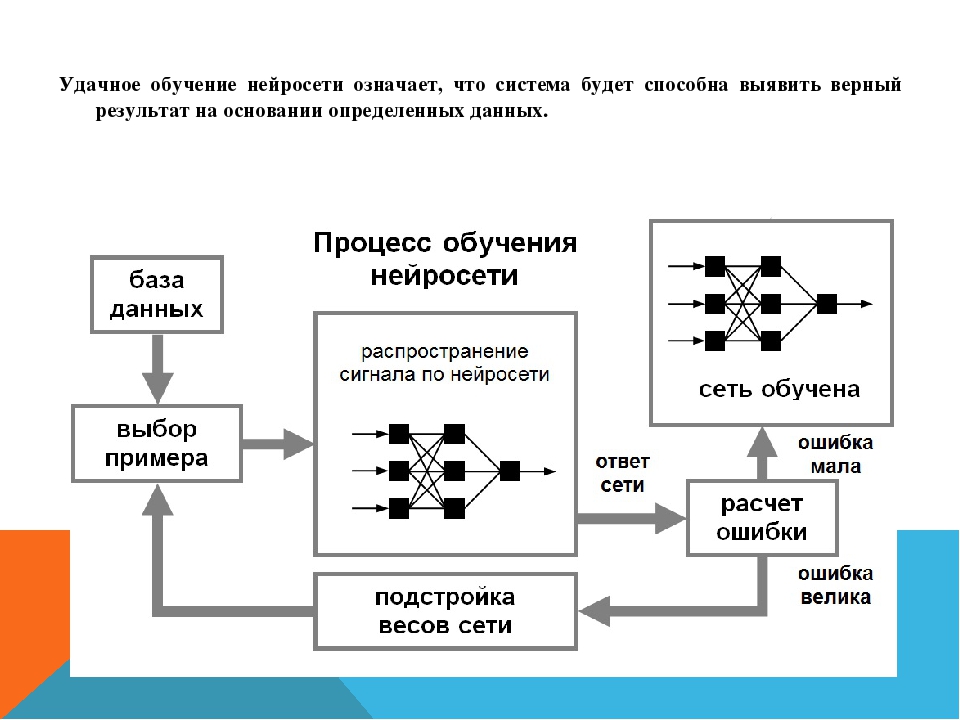 Как показано на рисунке 3, нейрон изображен как вычислительный блок, который принимает входные данные (X0, X1Xn) и веса (W0, W1 Wn), умножает их и суммирует результаты для создания индуцированного локального поля v, которое затем проходит через функция принятия решения φ (v) для получения окончательного результата y.
Как показано на рисунке 3, нейрон изображен как вычислительный блок, который принимает входные данные (X0, X1Xn) и веса (W0, W1 Wn), умножает их и суммирует результаты для создания индуцированного локального поля v, которое затем проходит через функция принятия решения φ (v) для получения окончательного результата y.
Рисунок 3: Математическая модель нейрона
В виде математического уравнения это сводится к:
Я ввел два новых термина, индуцированное локальное поле и решающая функция , при описании компонентов этой модели, поэтому давайте посмотрим, что они означают. Индуцированное локальное поле нейрона является выходом блока суммирования, как показано на диаграмме. Если мы знаем, что входные данные и веса могут иметь значения в диапазоне от -? до +?, то диапазон индуцированного локального поля такой же.Если бы на другие нейроны распространялось только индуцированное локальное поле, то нейронная сеть могла бы выполнять только простые линейные вычисления.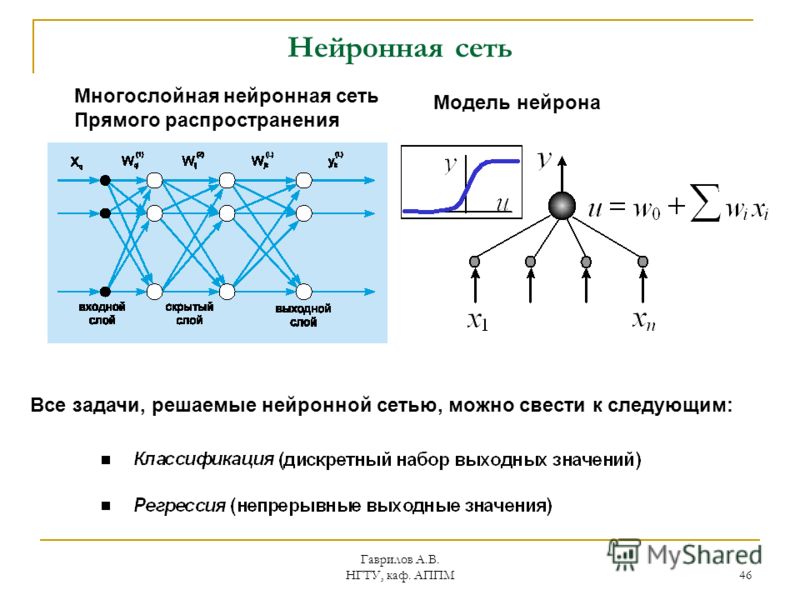 Для обеспечения более сложных вычислений была введена идея решающей функции . Маккалок и Питтс ввели одну из простейших решающих функций в 1943 году. Их функция — это просто пороговая функция, которая выдает единицу, если индуцированное локальное поле больше или равно нулю, и выдает ноль в противном случае. В то время как некоторые простые проблемы могут быть решены с помощью модели Маккаллоха-Питтса, более сложные проблемы требуют более сложной функции решения.Возможно, наиболее широко используемой функцией принятия решения является сигмоидальная функция , заданная по формуле:
Для обеспечения более сложных вычислений была введена идея решающей функции . Маккалок и Питтс ввели одну из простейших решающих функций в 1943 году. Их функция — это просто пороговая функция, которая выдает единицу, если индуцированное локальное поле больше или равно нулю, и выдает ноль в противном случае. В то время как некоторые простые проблемы могут быть решены с помощью модели Маккаллоха-Питтса, более сложные проблемы требуют более сложной функции решения.Возможно, наиболее широко используемой функцией принятия решения является сигмоидальная функция , заданная по формуле:
У сигмоидной функции есть два важных свойства, которые делают ее хорошо подходящей для использования в качестве функции принятия решения:
- Она дифференцируема везде (в отличие от пороговой функции), что позволяет легко обучать сети, как мы увидим позже.
- Его выходные данные включают диапазоны, которые демонстрируют как нелинейное, так и линейное поведение.

Иногда используются и другие решающие функции, такие как гиперболический тангенс? (V) = tanh (v).В примерах, которые мы рассмотрим, мы будем использовать сигмовидную функцию решения, если не указано иное.
Подключение нейронов
Мы рассмотрели основные строительные блоки нейронных сетей, рассмотрев математическую модель искусственного нейрона. Отдельный нейрон можно использовать для решения некоторых относительно простых задач, но для более сложных задач мы должны исследовать сеть из нейронов, , отсюда и термин: нейронная сеть.
Нейронная сеть состоит из одного или нескольких нейронов, соединенных в один или несколько слоев .Для большинства сетей слой содержит нейроны, которые не связаны друг с другом каким-либо образом. В то время как схема взаимосвязей между уровнями сети (ее «топология») может быть регулярной, веса, связанные с различными межнейронными связями, могут сильно различаться. На рисунке 4 показана трехуровневая сеть с двумя узлами на первом уровне, тремя узлами на втором уровне и одним узлом на третьем уровне. Узлы первого уровня называются входными узлами , узел третьего уровня называется выходным узлом , а узлы в слоях между входными и выходными уровнями называются скрытыми узлами .
Узлы первого уровня называются входными узлами , узел третьего уровня называется выходным узлом , а узлы в слоях между входными и выходными уровнями называются скрытыми узлами .
Рисунок 4: Трехуровневая нейронная сеть
Обратите внимание на вход, помеченный как x6, на первом узле скрытого слоя. Фиксированный вход (x6) не управляется другими нейронами, но помечен как постоянное значение, равное единице. Это называется смещением и используется для регулировки характеристик возбуждения нейрона. С ним связан вес (не показан), но входное значение никогда не изменится. Для любого нейрона можно добавить смещение, установив для одного из его входов постоянное значение, равное единице.Мы еще не рассмотрели обучение сети, но когда мы это сделаем, мы увидим, что вес, влияющий на смещение, может быть обучен так же, как веса любого другого входа.
Нейронные сети, с которыми мы будем иметь дело, будут структурно аналогичны той, что представлена на рисунке 4. Несколько ключевых особенностей этого типа сети:
Несколько ключевых особенностей этого типа сети:
- Сеть состоит из нескольких слоев. Есть один входной слой и один выходной слой с нулевым или более скрытыми слоями
- Сеть является , а не рекуррентной, что означает, что выходы из любого узла только служат входами следующего уровня, а не того же или любого предыдущего уровня.
- Хотя сеть, показанная на рисунке 4, полностью подключена, необязательно, чтобы каждый нейрон в одном слое питал каждый нейрон в следующем слое.
Нейронные сети для вычислений
Теперь, когда мы вкратце рассмотрели структуру нейронной сети, давайте кратко рассмотрим, как можно выполнять вычисления с помощью нейронной сети. Позже в этой статье мы узнаем, как настраивать веса или обучать сеть для выполнения желаемых вычислений.
На простейшем уровне один нейрон производит один выход для данного набора входов, и выход всегда один и тот же для этого набора входов. В математике это называется функцией или отображением .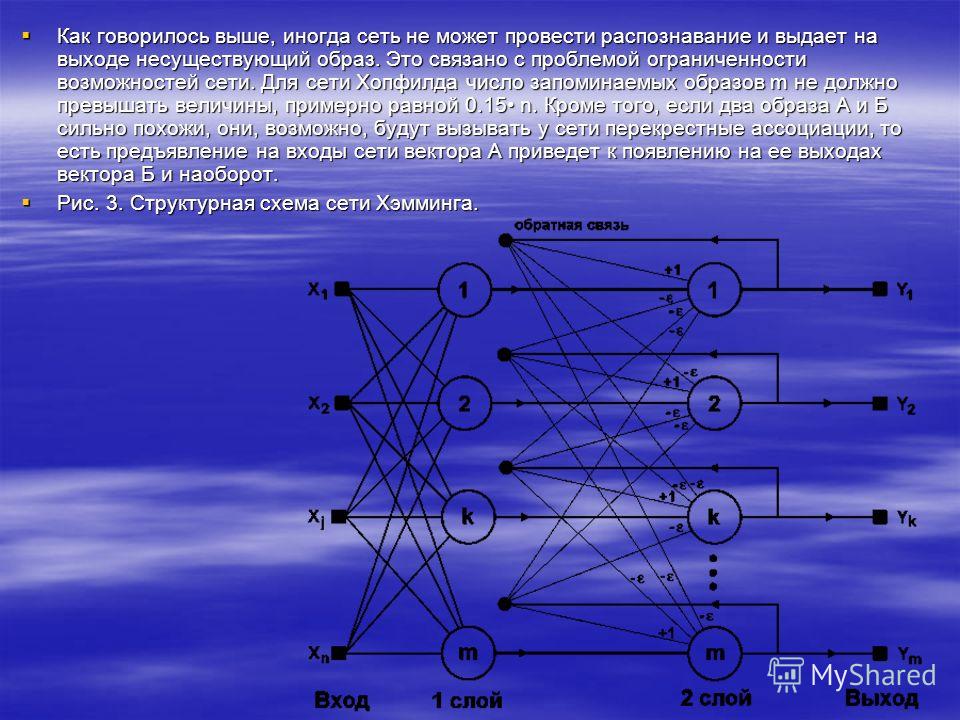 Для этого нейрона точное соотношение между входами и выходами задается весами, влияющими на входы, и конкретной функцией принятия решения, используемой нейроном.
Для этого нейрона точное соотношение между входами и выходами задается весами, влияющими на входы, и конкретной функцией принятия решения, используемой нейроном.
Давайте посмотрим на простой пример, который обычно используется для иллюстрации вычислительной мощности нейронных сетей.В этом примере мы предположим, что используемая решающая функция — это пороговая функция Маккаллоха-Питтса. Мы хотим изучить, как нейронную сеть можно использовать для вычисления таблицы истинности для логического элемента И. Напомним, что выход логического элемента И равен единице, если оба входа равны единице, и нулю в противном случае. На рисунке 5 показана таблица истинности для оператора AND.
Рисунок 5: Таблица истинности для оператора AND
Мы хотим построить нейронную сеть, которая имеет два входа, один выход и вычисляет таблицу истинности, представленную на рисунке 5.
Рисунок 6: Нейрон для вычисления операции И
На рис.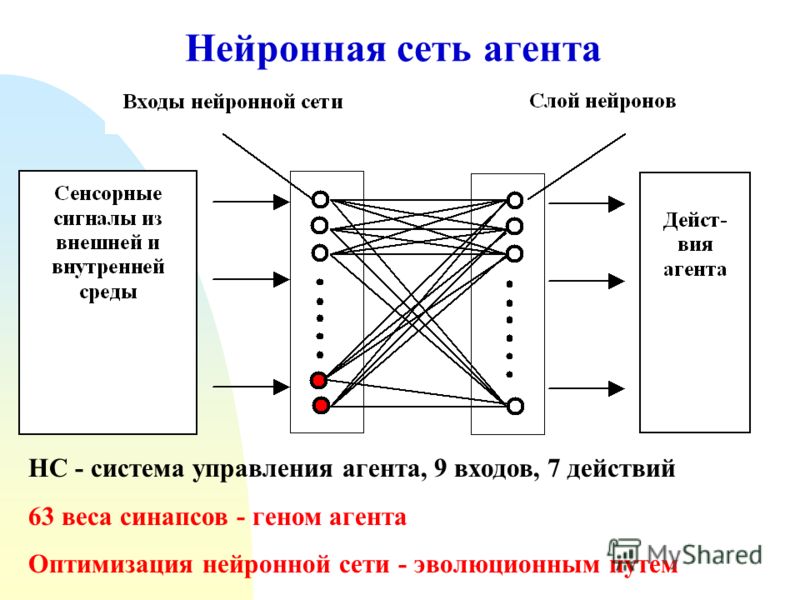 6 показана возможная конфигурация нейрона, который делает то, что мы хотим. Решающей функцией является упомянутая ранее пороговая функция Мак-Каллока-Питтса. Обратите внимание, что вес смещения (w0) равен -0,6. Это означает, что если и X1, и X2 равны нулю, то индуцированное локальное поле v будет равно -0,6, что приведет к 0 для выхода. Если либо X1, либо X2 равно единице, то индуцированное локальное поле будет равно 0.5 + (- 0,6) = -0,1, что все еще является отрицательным, что приводит к нулевому выходному сигналу решающей функции. Только когда оба входа равны единице, индуцированное локальное поле станет неотрицательным (0,4), что приведет к одному выходу из решающей функции.
6 показана возможная конфигурация нейрона, который делает то, что мы хотим. Решающей функцией является упомянутая ранее пороговая функция Мак-Каллока-Питтса. Обратите внимание, что вес смещения (w0) равен -0,6. Это означает, что если и X1, и X2 равны нулю, то индуцированное локальное поле v будет равно -0,6, что приведет к 0 для выхода. Если либо X1, либо X2 равно единице, то индуцированное локальное поле будет равно 0.5 + (- 0,6) = -0,1, что все еще является отрицательным, что приводит к нулевому выходному сигналу решающей функции. Только когда оба входа равны единице, индуцированное локальное поле станет неотрицательным (0,4), что приведет к одному выходу из решающей функции.
Хотя такое использование нейронной сети является излишним для проблемы и имеет довольно тривиальное решение, это начало иллюстрации важного момента, касающегося вычислительных возможностей отдельного нейрона. Мы собираемся изучить эту и еще одну проблему, чтобы понять концепцию линейно разделяемых задач .
Посмотрите на «график» на рисунке 7. Здесь ось x соответствует входу 0, а ось y соответствует входу 1. Выходные данные записаны в график и соответствуют таблице истинности из рисунка 5. Серый цвет заштрихованная область представляет собой область значений, которые производят единицу в качестве вывода (если мы предположим, что входные данные действительны вдоль реальной линии от нуля до единицы).
Рисунок 7: График функции И
Ключевой момент, на который следует обратить внимание, это наличие линии (нижний левый наклон серого треугольника), которая отделяет входные значения, которые дают на выходе единицу, от входных значений, которые дают нулевой результат.Проблемы, для которых может быть проведена такая «разделительная линия» (например, задача И), классифицируются как линейно разделяемые задачи .
Теперь давайте посмотрим на другую логическую операцию, операцию исключающее ИЛИ (XOR), как показано на рисунке 8.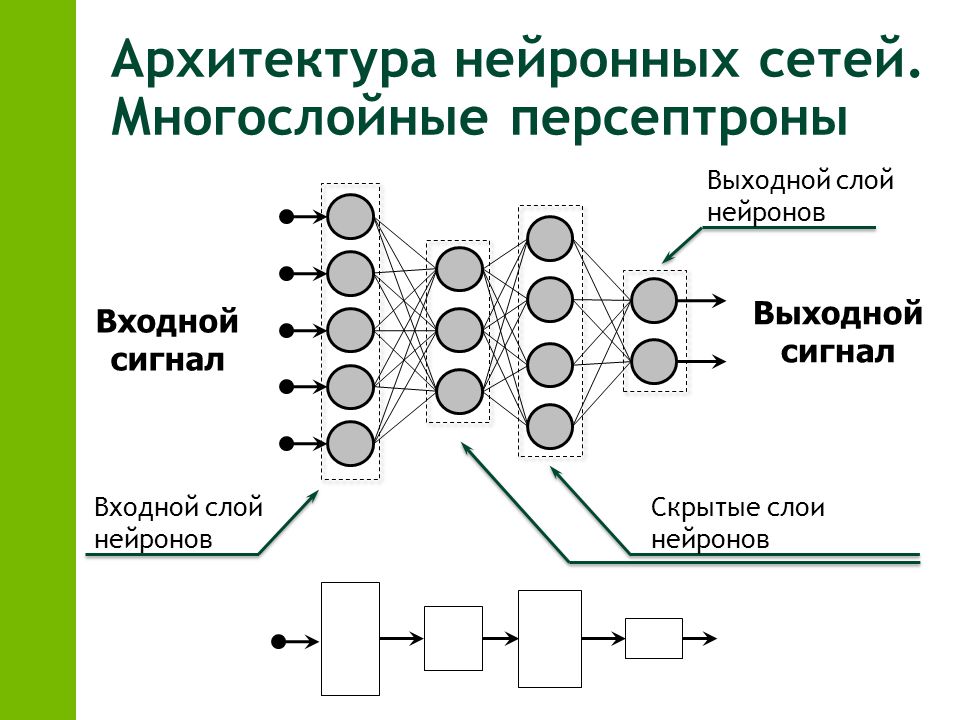
Рисунок 8: Таблица истинности для оператора XOR
Здесь выход равен единице, только если один, но не оба входа равны одному. «График» этого оператора показан на рисунке 9.
Рисунок 9: График функции XOR
Обратите внимание, что серая область, окружающая «единичные» выходы, отделена от нулевых выходов не одной линией, а двумя линиями (нижняя и верхняя наклонные линии серой области).Эта задача не является линейно разделимой на . Если мы попытаемся построить единственный нейрон, который сможет вычислить эту функцию, у нас ничего не получится.
Ранние исследователи считали, что это ограничение для всех вычислений с использованием искусственных нейронов. Только с добавлением нескольких уровней стало понятно, что нейроны с линейным поведением могут быть объединены для решения задач, которые нельзя разделить линейно. На рисунке 10 показана простая сеть из трех нейронов, которая может решить проблему XOR.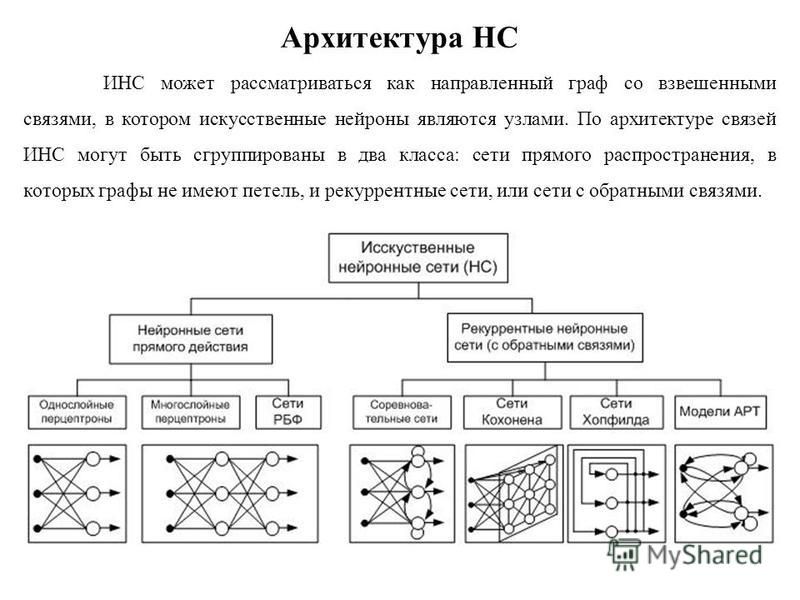 Мы по-прежнему предполагаем, что решающей функцией является пороговая функция Маккаллоха-Питтса.
Мы по-прежнему предполагаем, что решающей функцией является пороговая функция Маккаллоха-Питтса.
Рисунок 10: Сеть для вычисления функции XOR
Все веса установлены на 1,0, за исключением веса, обозначенного как w = -2. Для полноты картины давайте быстро пройдемся по выходам для четырех различных комбинаций входов.
- Если оба входа равны 0, то нейроны 0 и 1 выводят 0 (из-за их отрицательных смещений).Таким образом, выход нейрона 2 также равен 0 из-за его отрицательного смещения и нулевых входов.
- Если X0 равно 1, а X1 равно 0, тогда нейрон 0 выводит 0, нейрон 1 выводит 1 (поскольку 1.0 + (- 0.5) = 0.5 больше 0), а нейрон 2 также выводит 1.
- Если X0 равно 0, а X1 равно 1, то нейрон 0 выводит 0, нейрон 1 выводит 1, а нейрон 2 выводит 1.
- Наконец, если оба входа равны 1, то нейрон 0 выдает 1, которая становится входом -2 для нейрона 2 (из-за отрицательного веса). Нейрон 1 выводит 1, которая объединяется с -2 и -0. 5, чтобы на выходе нейрона 2 был 0.
 5, чтобы на выходе нейрона 2 был 0.
5, чтобы на выходе нейрона 2 был 0.Вывод из этого простого примера состоит в том, что для решения нелинейно разделимых задач необходимы многоуровневые сети. Кроме того, в то время как пороговая функция Мак-Каллока-Питтса отлично работает для этих простых для решения задач, для решения большинства реальных проблем требуется более удобная с математической точки зрения (т.е. дифференцируемая) функция принятия решений. Теперь мы рассмотрим способ, которым нейронная сеть может быть обучена (а не запрограммирована или структурирована) для решения конкретной проблемы.
Учебные процессы
Давайте вернемся к определению вывода отдельного нейрона (мы добавили параметр для определенного набора данных, k ):
Уравнение 1
Обратите внимание, что x = y , выход из нейрона i , если нейрон j не является входным нейроном. Кроме того, w — это весовой выход, соединяющий выход нейрона i в качестве входа в нейрон j .
Мы хотим определить, как изменить значения различных весов, w (k) , когда результат, y (k) , не соответствует результату, который мы ожидаем или требуем от данного набора. входов, x (k) . Формально, пусть d (k) будет желаемым выходом для данного набора входов, k . Затем мы можем посмотреть на функцию ошибок, e (k) = d (k) -y (k) . Мы хотим изменить веса, чтобы уменьшить ошибку (в идеале до нуля). Мы можем посмотреть на энергию ошибки как функцию ошибки:
Уравнение 2
Регулировка весов теперь становится проблемой минимизации ? (K) .Мы хотим взглянуть на градиент энергии ошибки относительно различных весов,
. Комбинируя уравнение 1 и уравнение 2 и используя правило цепочки (и вспоминая, что y (k) =? (V (k)) и v (k) =? W (n) y (n) ), мы можем расширить эту производную до чего-то более управляемого:
Уравнение 3
Каждое из членов уравнения 3 можно уменьшить, так что мы получаем:
Уравнение 4
Где ? ‘() означает дифференциацию по аргументу.